[논문리뷰] PackNet: Adding Multiple Tasks to a Single Network by Iterative Pruning (CVPR 2018)
method에 대해서 본논문에서는 training, prunning,inference로 나누어서 설명해주는데 먼저 training과정을 보면 다음과 같습니다.
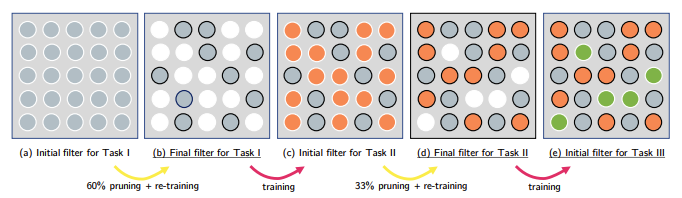
먼저, 첫 번째 과제를 수행할 수 있도록 모델을 학습시킵니다. 이 단계에서 신경망은 전체 파라미터를 사용하여 최적의 성능을 달성하려고 합니다.
(가지치기)
첫 번째 과제를 학습한 후, 모델의 파라미터 중 중요도가 낮은(즉, 성능에 크게 기여하지 않는) 파라미터를 가지치기합니다. 가지치기는 모델에서 불필요한 연결을 제거하여 파라미터 수를 줄이는 과정입니다.
가지치기 후, 남은 파라미터들은 첫 번째 과제의 성능을 유지하는 데 충분한 정보를 담고 있는 것을 알 수 있습니다.
가지치기 후 남은 파라미터들은 고정한 채, 새로운 과제를 학습하기 위해 모델의 비어 있는 파라미터를 사용합니다. 이렇게 하면, 새로운 과제를 학습하면서도 이전 과제에 대한 성능이 유지됩니다.
즉,(Train -> Pruning -> Re-Train)과정을 반복함으로써 모델은 점점 더 많은 과제를 학습하게 되고, 각 과제를 처리하기 위해 필요한 최소한의 파라미터만 남기게 됩니다.
training이후에 inference과정도 간단한데 추가적인 runtime overhead없이 Pruning을 하며 Masking 된 파라미터에대해 masking. 즉,switched off한 상태로 Matrix Multiplication 연산을 수행합니다.
그리고 이렇게 pruning을 거치는 이유는 먼저 파라미터 효율성,즉,가지치기를 통해 모델의 파라미터 중에서 불필요하거나 덜 중요한 파라미터를 제거함으로써, 남은 파라미터들이 새로운 과제를 처리하기 위한 공간을 확보할 수 있습니다.
그리고 메모리와 연산자원을 절역하면서 다양한과제를 한 모델에 통합할 수 있게됩니다.
그리고 forgetting문제에 대해서도 가지치기를 통해 모델이 각 과제에 대한 정보를 개별적으로 유지할 수 있도록 하여, 새로운 과제를 학습할 때 기존 과제에 대한 성능 저하(망각)를 최소화합니다.
이후에 experiments에서도 보면 LwF보다 좋은 성능을 보이면서 단순 Distillation Loss 보다는 Pruning 방식이 기존 지식을 더 유지하며 학습할 수 있음을 보여줍니다.
