[논문리뷰]Cross-stitch Networks for Multi-task Learning
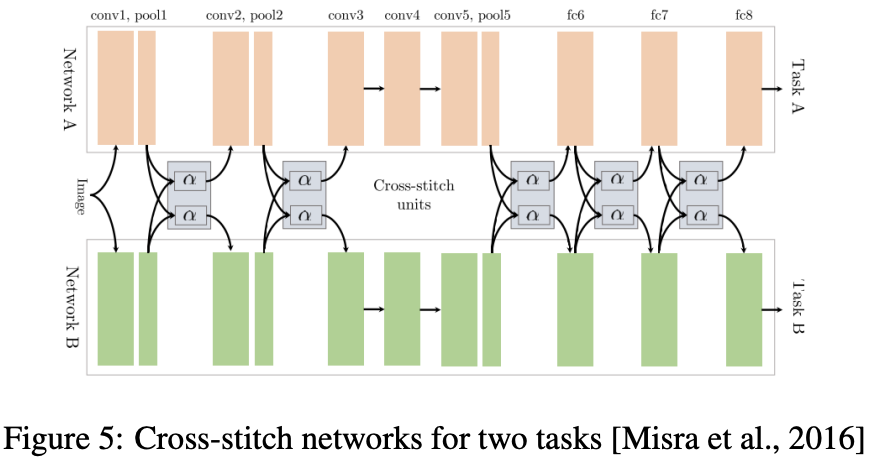
soft parameter sharing과 같은 두 개의 분리된 모델
pooling과 fully-connected layer 이후에 cross-stitch units를 배치
주요 내용 요약
문제 정의:
다중 작업 학습(Multi-task Learning, MTL)은 여러 관련 작업을 동시에 학습함으로써 단일 작업 학습보다 더 나은 일반화 성능을 목표로 합니다.
작업 간의 피처 공유는 중요한 이점이 있지만, 어떤 피처를 공유할지, 어느 정도까지 공유할지 결정하는 것이 어렵습니다.
Cross-stitch Networks:
Cross-stitch unit을 통해 서로 다른 작업의 피처 맵을 결합합니다.
이 유닛은 학습 과정에서 각 작업의 피처 맵을 적절하게 가중치화하여 결합합니다.
이 방법을 통해 네트워크는 각 작업에 대해 최적의 피처 조합을 학습할 수 있습니다.
구조 및 학습:
네트워크의 초기 레이어는 모든 작업에 대해 공유되며, 이후 Cross-stitch unit을 통해 각 작업별로 분리된 경로를 따라 피처를 학습합니다.
Cross-stitch unit의 가중치는 학습 중에 동적으로 조정되어 각 작업에 가장 적합한 피처 조합을 찾습니다.
주요 기여(Contributions)
Cross-stitch unit 도입:
다중 작업 학습에서 피처 공유의 문제를 해결하기 위해 Cross-stitch unit을 도입했습니다.
이 유닛은 각 작업 간의 피처를 동적으로 결합하여 최적의 정보를 제공하는 역할을 합니다.
유연한 피처 공유:
Cross-stitch Networks는 각 작업의 요구에 맞게 피처를 유연하게 공유할 수 있어 기존의 고정된 피처 공유 방식보다 효율적입니다.
다양한 작업에서 공유되는 피처의 정도를 학습을 통해 조절함으로써 성능을 향상시켰습니다.
실험 결과:
다양한 데이터셋에서 실험을 통해 Cross-stitch Networks의 성능을 검증했습니다.
다중 작업 학습에서 기존 방법들보다 우수한 성능을 보였습니다.
Method에 대한 정리
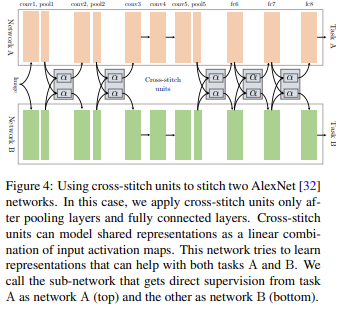
MTL에서 soft parameter sharing과 같은 두 개의 분리된 모델을 두고 pooling과 fully-connected layer 이후에 cross-stitch units를 배치한 모습의 구조를 갖추었으며 그림에서 나와있는 구조는 AlexNet의 기본구조를 따릅니다.
task A로부터 direct supervision을 받고, task B로부터 undirect supervision을 받는 네트워크를 network A라고 정의 할 수 있고, 그와 같은 방식으로 아래 네트워크를 network B라고 정의 할 수 있다. 논문에서 예시로 나온 taskA와 taskB는 각각 semantic segmentation과 Surface Normal Prediction.(input은 image). 그리고 이때 Cross-stitch units은 shared representations를 학습하고 시행함으로써 두 작업을 정규화 하는데 도움을 줍니다. 따라서 한 작업이 다른 작업보다 레이블이 적은 경우 cross-stitch units을 이용한 정규화가 "데이터 부족"한 작업에 도움이 될 것임을 기대할 수 있습니다. 그러면 cross-stitch unit의 식을 보면 알 수 있듯이
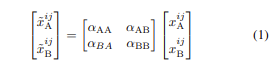
xA xB는 activation map
Tasks 사이의 얼마나 많은 sharing이 필요한지를 supervise하는 unit으로 αAB, αBA가 0이라면 특정 layer를 작업하도록 설정할 수 있고, 이 두개의 term을 각각 올리고 내림으로써 더 shared된 representation을 선택할 수 있도록 하였습니다.
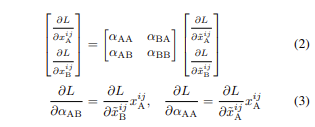
그리고 위의 식은 cross-stitch unit을 통한 back propagation인데 αAB αBA는 αD :different-task values로 다른작업의 활정화를 weigh(측정), 그리고 αAA αBB는 αS으로 같은 작업의 활성화를 측정할 수 있도록 식이 구성되었습니다.그리고 이러한 αD,αS 값을 변경함으로써 Unit은 shared 그리고 task-specific representation사이를 이동하며 필요한 경우 중간지점을 선택할 수도 있습니다.
정리
overview에서 설명한 최근 Multi-Task-Learning의 method로 soft parameter sharing과 같은 두 개의 분리된 모델로서 pooling과 fully-connected layer 이후에 cross-stitch units를 배치된 구조입니다.
task A로부터 direct supervision을 받고, task B로부터 undirect supervision을 받는 네트워크를 network A라고 정의 할 수 있고, 그와 같은 방식으로 아래 네트워크를 network B라고 정의 할 수 있습니다.
Cross-stitch units은 shared representations를 학습하고 시행함으로써 두 작업을 정규화 하는데 도움을 줍니다. 따라서 한 작업이 다른 작업보다 레이블이 적은 경우 cross-stitch units을 이용한 정규화가 "데이터 부족"한 작업에 도움이 될 것임을 기대할 수 있습니다.
그러면 이 cross-stitch units을 더 자세히 알아보면 xA xB는 activation map이고,αAB, αBA가 0이라면 특정 layer를 작업하도록 설정할 수 있고, 이 두개의 term을 각각 올리고 내림으로써 더 shared된 representation을 선택할 수 있도록 하였습니다.
또한,위의 식은 cross-stitch unit을 통한 back propagation으로 αAB αBA는 αD :different-task values로,αAA αBB는 αS으로 각각 다른작업과 같은 작업의 활성화를 weigh할 수 있도록 식이 구성되어 있습니다. 그리고 이러한 αD,αS 값을 변경함으로써 Unit은 shared 그리고 task-specific representation사이를 이동하며 상황에 맞게 이를 조절할 수 있게 하였습니다.
Q.shared 혹은 task-specific representation이 많이 필요한 상황?
1. Shared Representation이 많이 필요한 상황:
Shared representation이 많이 필요한 상황은 여러 작업이 공통된 특성을 많이 공유할 때입니다. 예를 들어, 비슷한 유형의 작업들, 예를 들어 비슷한 유형의 이미지를 분류하는 작업들이 있을 때, 이들은 대부분의 중간 특성을 공유할 수 있습니다. 이러한 경우, 서로 다른 작업이 동일한 특징 추출기(feature extractor) 또는 모델의 초기 계층을 공유함으로써 더 나은 성능을 얻을 수 있습니다. 이 방식은 데이터의 공통된 패턴을 효과적으로 학습하고, 각 작업에서 성능을 향상시키는 데 기여할 수 있습니다. 예를 들어, 얼굴 인식과 감정 인식 같은 작업들은 모두 얼굴의 시각적 특징을 학습하는데 공통적인 요소가 많기 때문에 shared representation이 유용할 수 있습니다.
- Task-specific Representation이 많이 필요한 상황:
반대로 task-specific representation이 많이 필요한 상황은 각 작업이 서로 매우 다른 특성을 요구할 때입니다. 예를 들어, 자연어 처리 작업에서 텍스트 분류와 기계 번역은 매우 다른 작업입니다. 텍스트 분류는 주로 문장의 특정 패턴을 학습하는 반면, 기계 번역은 문장을 다른 언어로 변환하기 위해 복잡한 언어 모델링을 요구합니다. 이러한 경우 각 작업에 특화된 표현을 학습하는 것이 더 효과적입니다. 각 작업에 고유한 표현을 학습함으로써, 한 작업에서 필요하지 않은 정보가 다른 작업에 방해되지 않도록 할 수 있습니다.
Q.main contribution?
αD,αS 값을 변경함으로써 Unit은 shared 그리고 task-specific representation의 정도를 조정하여서 각 상황에 맞는 정도를 맞추어 최적의 공유 수준을 결정하는 과제를 해결하여 다양한 작업에서 향상된 성능을 이끌어냅니다.
