[논문리뷰]poseformer
PoseFormer는 Pure Transformer Based 3D HPE 모델이며
Spatial-temporal structure를 이용해 Joint간 관계, Frame간 관계를 모델링했다는 특징을 갖고 있습니다.
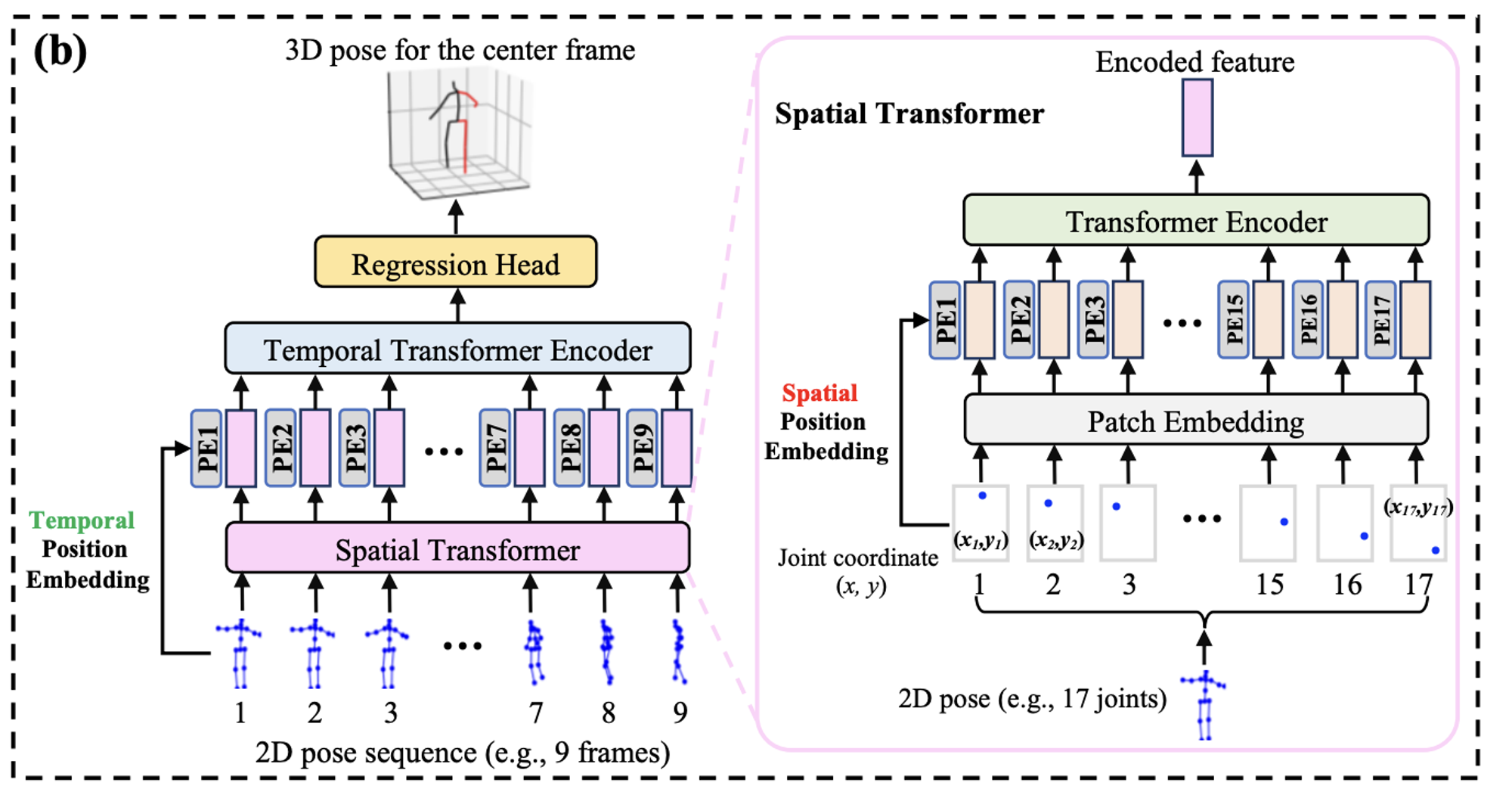
figure에서 볼 수 있듯이 1.
2D Pose Sequence를 Spatial Attention해서 Feature로 만들고
2.
Feature를 Temporal Attention해서 CenterFrame을 Regression하는 흐름을 갖고 있습니다.
그리고 Pose Estimation Approaches에는 2가지가 있는데
논문에서는 1.
Direct Estimation : 2D Image에서 2D Pose 안거치고 바로 3D Pose를 뽑는것과
2.
2D-3D Lifting : 2D Image에서 2D Pose 뽑고 거기서 3D Pose 뽑는것이 있습니다.
그리고 Poseformer는 2D-3D Lifting에 직접적으로 Transformer을 활용하는 첫 Pure Transformer 모델로서
1.
Off-the-Shelf 2D Estimator로 2D Joint Sequence를 추출하고
2.
Spatial Encoder로 각 Joint간의 Local Relation을 모델링한다.
3.
Temporal Encoder가 각 Spatial Feature의 Temporal Global Dependency를 모델링한다.
4.
정확한 3D Pose를 만들어낸다.
출처)https://jhtobigs.oopy.io/2ac130a2-aa83-4a9b-bd51-89cb23ddb1bd
