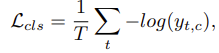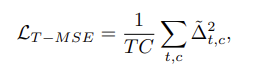[논문리뷰]MS-TCN++: Multi-Stage Temporal Convolutional Network for Action Segmentation
정리)
비디오에서의 Action recognition 은 짧은 trimmed videos에 집중되어 발전되어서 long videos에는 비교적 발전하지 못한 경향을 띄었는데 이때 나온 network가 TCNs으로 좋은 성능을 보였는데 그러나 많은 세분화된 정보에 대해서 잃는다는 단점 등 여러 단점들이 생겨 이런 단점들을 보완하여 고안된것이 MS-TCN++입니다.
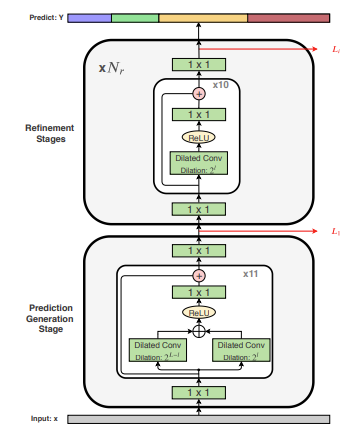
MS-TCN++은 MS-TCN의 일부를 수정한 구조의 network로 MS-TCN의 개선점들을 보면 첫번째는 MS-TCN의 상위 레이어에 대해 수용필드가 매우 크지만 하위레이어는 작은 수용 필드로 인해 어려움을 겪는다는점과 둘째로 MS-TCN의 첫번째 단계는 초기 예측을 generate하고 나머지 단계는 이예측을 refinemenet하는 구조로 되어있습니다. 그런데 이 두 작업의 차이점에도 불구하고 모든 단계는 동일한 아키텍처를 공유합니다. 따라서 각각의 개선점들의 해결방안으로 첫번째 개선점의 해결방안으로는 각레이어에서 크고 작은 수용 필드를 모두 결합한 이중 확장 레이어 DLL를 제안합니다. 이 DLL은 서로 다른 dilation factor를 가진 두 개의 컨볼루션을 결합한 것으로 첫번째 컨볼루션은 lower layers에서 low dilation factor를 가지고(exponentially increases as we increases the number
of layers) 두번째 컨볼루션은 lower layers에서 large dilation factor를 갖습니다(exponentially
decrease it with increasing the number of layers). 두번째 개선점의 해결방안은 전체 아키텍처를 두부분으로 나누고 첫번째 단계인 prediction generate단계와 두번째 단계인 prediction refinement단계를 나누고 각 부분의 아키텍처를 별도로 customize하고 모든 단계가 동일한 architecture를 갖도록 강요하지 않습니다. 이렇게 함으로써 MS-TCN을 발전시켰습니다.
이를 구조적인 측면에서 보면 MS-TCN과 MS-TCN++은 둘다 4개의 stage로 구성되어 있는데 MS-TCN은 모든 stage가 동일한 stage로 구성되는 것과 다르게 MS-TCN++은 1개의 generation stage와 3개의 refinement stafe로 구성되어 있으며 첫번째 prediction generation단계에서 DLL을 거치는 11개의 dilated convolution layers로 구성되어있으며 2,3,4stage에서는 각각 10개의 dilated convolution layers로 구성되어있는 것을 확인 할 수 있었습니다.
그리고 loss function은 classification loss와 smoothing loss의 조합으로 되어있습니다.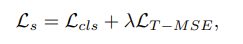
그리고 classification loss로는 cross entropy loss를 사용하고 있으며 smoothing loss로는 truncated mean squared error로 구성되어 있습니다.