Accepted: ICCV
Created time: March 23, 2022 5:50 AM
Date: 2021
Last edited time: April 1, 2022 5:45 AM
url: click
0. ABSTRACT
NAS (Neural Architecture Search)를 처음으로 vision tranformer에 적용한 논문. 최근 transformer 모듈만으로 비전 태스크에서 괄목할만한 성과를 보여준 바 있으나, 아무래도 tranformer가 자연어처리를 위한 논문이다 보니 적절하지 않은 부분이 있겠습니다.
새로운 search space와 searching algorithm을 제안합니다. 구체적으로는, 이미지의 local correlation을 모델링 할 수 있는 locality module을 제안합니다.
이를 통해 search 알고리즘은 global, local 정보를 trade off 할 수 있을 뿐만 아니라, 각 모듈에서의 low level 디자인 또한 최적화할 수 있게 됩니다. 거대한 search space로부터 비롯되는 문제들은, hierarchical neural architecture search method 제안하여 해결할 수 있도록 하였습니다. 이를 통해 ResNet 종류의 모델들보다 좋은 성능을 내는 것을 확인했습니다.
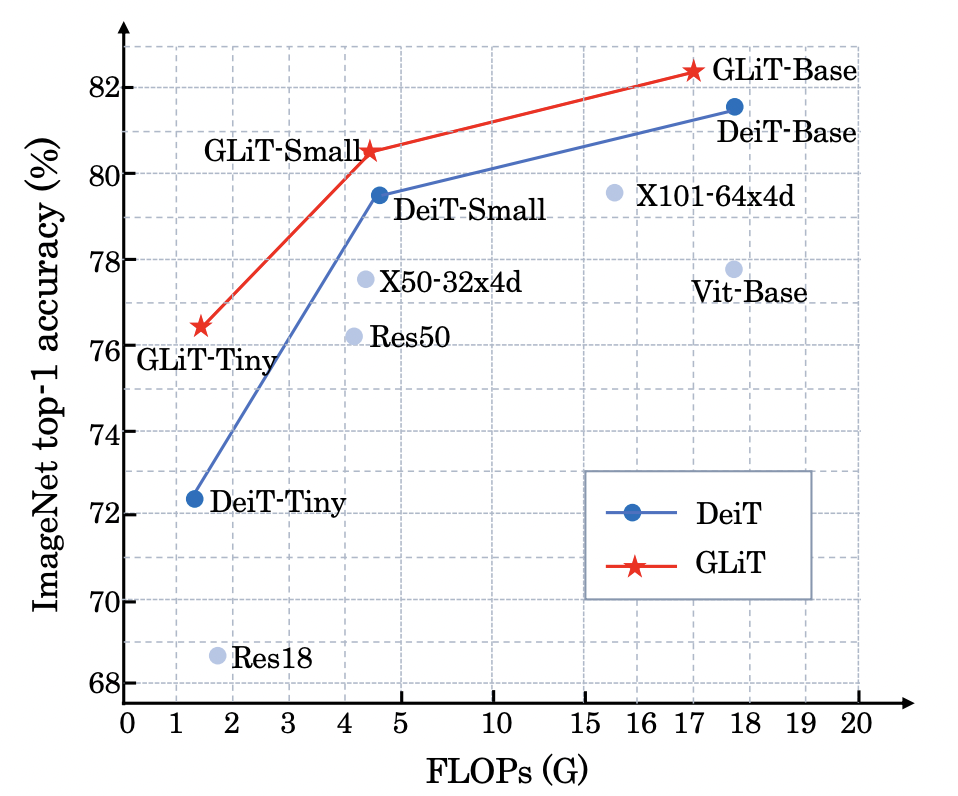
Top-1 accuracy (y-axis) and FLOPs (x-aixs) for different
backbones on ImageNet. GLiT is our method.
1. Introduction
CNN 기반 모델들은 큰 receptive field를 통해 더 많은 정보를 받아들이지만, 그 과정에서 효율성이 부족합니다. 이를 발전시키기 위해 tranformer를 도입하였는데, 이는 global한 상관 관계를 잘 뽑아낸다는 특징이 있었습니다. 하지만 해당 모델은 기존에 자연어 처리를 위해 사용되던 모델이었기에 이미지를 다루는데 있어서 최적화되지 못한다는 단점 또한 있었죠.
해당 연구팀은 “자연어 처리에 최적화된 모델 구조와 이미지에 최적화된 모델 구조가 따로 존재할 것이다.”를 가정합니다. 모델 구조를 손으로 짜는 것은 비효율적이니, Neural Architecture Search (NAS)를 제안하죠. 이는 매뉴얼한 try-and-error를 없애고, 자동으로 최적화된 네트워크를 짜줍니다.
naive search는 트랜스포머 구조에서 파라미터들을 바꾸는데, 예를 들어 q,v,k에 대한 feature dim, MHA에서의 attention head 개수, MHA 블록들의 개수가 있겠습니다. 하지만, 트랜스포머에서의 self-attention 메카니즘이 입력 토큰의 개수와 quadratic하게 비례하는 메모리, 계산량 burden이 있다는 점은 바꾸지 못합니다. 둘째로는 인간 시각체계의 ‘recurrence’를 구현하지 못한다는 점입니다. 이는 CNN 성공의 근거가 되는 부분입니다. vanilla self-attention 메카니즘은 sparse한 로컬 상관관계를 잘 잡아내지 못합니다.
위에서 언급한 두가지를 고려해서 MHA에 ‘locality module’를 삽입하여 search space를 확장시켰습니다. 이는 오직 근접한 토큰들 사이에서 작동하며, 더 적은 파라미터와 계산량을 갖는다는 장점이 있습니다. locality module과 self-attention module은 서로 번갈아 가면서 사용할 수 있는데, NAS를 통해 어떤 것을 사용하는 것이 좋은지 결정할 수 있었습니다. 이렇게 확장된 버전의 MHA 블록을 global-local block이라고 명명하였는데, 이는 해당 구조를 통해 입력 토큰들의 global, local 정보를 모두 잡아낼 수 있기 때문입니다. 이는 추후 실험에서 증명하겠지만, transformer의 성능에 있어서 매우 중요한 요소가 됩니다.
global-local block은 유용할 것이 틀림없지만, 가장 최적화된 block을 만들기 위해서는 탐색 알고리즘을 잘 짜는 것이 중요합니다. 다음은 NAS algorithm의 조건들을 정리했습니다.
- global-local block에서 locality module & self-attention module 분배 최적화
- locality module과 self-attention module에서 디테일한 setting들을 탐색
Search space의 크기는 상상을 초월할 정도로 큰 크기를 자랑합니다. 개 정도이며, 이러한 문제를 해결하고 최적화된 네트워크를 만들기 위해서 Hierarchical Neural Architecture Search method를 제안합니다.
구체적으로는, locality module과 self attention module을 포함하는 supernet을 먼저 학습시키고 그 다음으로는 high-level global and local sub-module 분배를 결정한다. 기존의 search algorithm에 비해 더 안정적이고 향상된 탐색 성능을 보여준다.
Contribution은 다음과 같다.
- NAS를 통해 더 나은 transformer 모델을 만들어 냈다. 추가적인 데이터로 사전학습하지 않고서도 ResNet 보다 더 좋은 성능.
- local correlation을 모델링할 수 있는 locality module을 도입했다.
- Hierarchical Neural Architectur Search strategy를 도입하여 큰 search space를 효율적으로 탐색할 수 있게 되었다.
2. Related Works
Neural Architecture Search (NAS)
Darts [22] proposes a differentiable method to jointly optimize the network parameters and architecture parameters.
SPOS [13] proposes a single-path one-shot method, which trains only one subnet from the supernet in each training iteration. After supernet training, the optimal architecture is found through Evolutionary Algorithm (EA). However, due to the memory restriction (Darts [22]) or low correlation problems (SPOS [13]),
하지만 Darts의 경우에는 memory restriction, SPOS의 경우에는 low correlation 문제가 있었고, 이는 많은 수의 candidate architecture를 처리하지 못했다. 따라서 Hierarchical Neural Architecture Search를 만든 것.
NAS has been used to search an optimal architecture for NLP models. AutoTrans [36] designs a special parameter sharing mechanism for RL-based NAS to reduce the searching cost. [29] proposes a sampling-based one-shot architecture search method to get a faster model. NAS-BERT [32] constructs a big supernet including multiple architectures and find optimal compressed models with different sizes in the supernet
3. Method
GLiT은 여러개의 global-local block을 포함하며, 이는 기존의 global block들에 locality module을 추가한 것이다. hierarchical neural architecture search method를 통해, 첫째로는 고차원에서의 global-local 분배, 둘째로는 모든 모듈들에 대한 구체적인 구조를 제안할 수 있게 됩니다.
하나의 이미지에서, 의 차원을 갖는 1D의 입력을 받게 된다. (w: width, h: height, c: channels). 이때 입력을 m x m 사이즈의 패치로 나누게 되고 다시 한번 flatten 해준다면, 이때의 입력 차원은 가 된다. 입력 토큰들을 학습 가능한 class token들과 결합하여 개의 토큰을 GLiT에 추가로 넣어주게 된다. 이를 통해 image classification에서 마지막 prediction을 진행할 수 있게 된다.
3.1. Global-local block
global local block은 global-local module과 FFN(feed forward module)로 구성되어 있습니다.
3.1.1. Global-local module
Self-Attention as the Global Sub-module
모든 개의 입력 토큰들은 선형적으로 변형됩니다. 각각 query들의 차원은 가 됩니다.
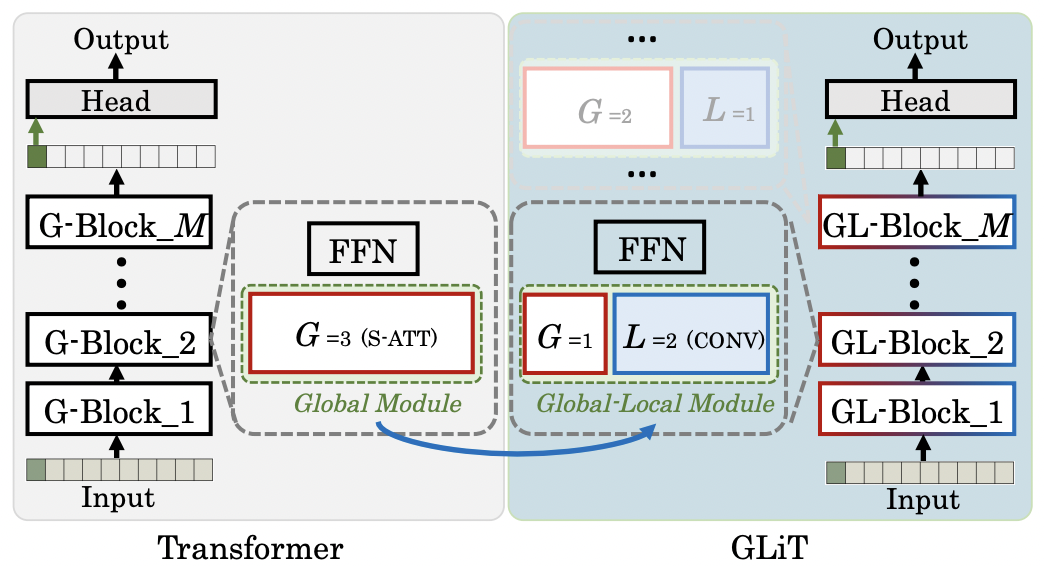
The construction of GLiT.
‘S-ATT’ is self-attention head, ‘CONV’ denotes convolution head, G and L are the numbers of self-attention and convolution heads.
The original transformer consists of only global module and Feed Forward module, i.e. the ’FFN’ in the figure. We further introduce local sub-module to the global module and get the Global-Local module. GLiT is constructed by M GL blocks. The distribution of global and local sub-modules may be different in different GL blocks. For example, GL-Block 2 in this figure has G = 1 global sub-module and L = 2 local sub-modules.
이를 바탕으로 self-attention 계산은 다음 식으로 진행이 됩니다.
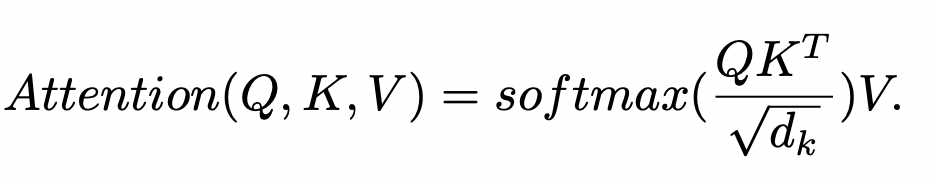
이를 MHA(multi head attention)으로 변형하면, 다음과 같습니다.
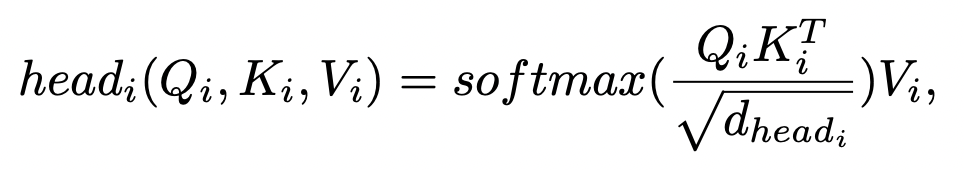
는 i번째의 head의 차원 수가 되겠습니다.
Convolution heads as Local Sub-module
1D Convolution은 NLP 태스크에서 local information을 모델링하기 위해 사용되었습니다. 이는 Conformer 논문에서 영감을 받아 해당 논문에 적용되었다고 합니다.
해당 논문에서도 local connection을 모델링하기 위해 1D convolution을 도입하였으며, 이를 local sub-module이라고 명명합니다.
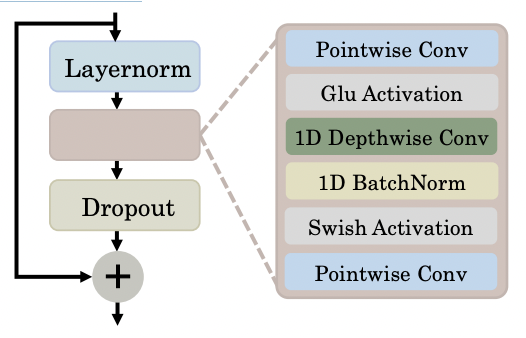
Convolution layers in the local sub-module
하나의 모듈은 세가지 convolution 계산으로 구성됩니다. point-wise convolutional layer 두개의 층과 그 사이에 존재하는 1D depth-wise convolutional layer로 구성됩니다.
Constrcting Multi-head Global-Local Module
Global sub module과 local sub module에 대해 알아보았습니다. 전자는 단순히 self-attention module, 후자는 convolutional block이었죠. 이제 이를 적절하게 배합하여 하나의 Global-Local Module을 제작하는 과정입니다.
이는 실험적으로 적절한 배합을 보여주는데, Local Module 2개, Global Module 1개일 때 가장 높은 정확도를 보여준다고 합니다.
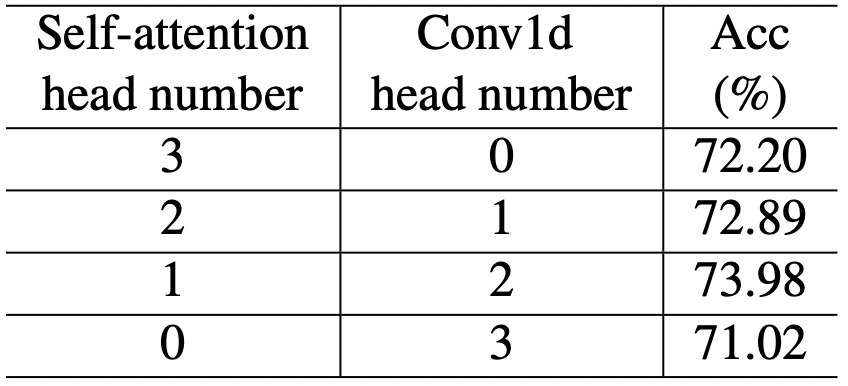
Table 1. Performance comparisons of different head distributions
in DeiT-Tiny model [28] on ImageNet dataset
ViT를 기준으로 첫번째 열이 base line이 되겠고, 점진적으로 local sub module(convolutional block)을 추가하며 성능을 비교하였다고 합니다.
3.1.2. Feed Forward Module
Layer Normalization과 two fully-connected layer with Swish Activation으로 구성합니다.
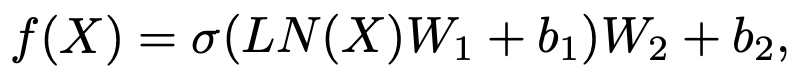
3.2. Search Space of the Global-local block
지금까지 제안한 global-local block에서 search space는 고차원적인 측면과 저차원적인 측면으로 구분됩니다.
고차원적인 측면이라 함은, global-local sub module의 분포이며, 저차원 측면으로는 각 sub-module들의 구체적인 구조가 되겠습니다.
다음은 High-level과 low-level에서 실험한 실험 set이다.

High Level Global-local distribution
m번째 transformer block에 개의 head가 있다고 가정하자.
이라 할 때, 개의 self-attention block은 그대로 유지하고, 개의 self-attention을 Convolution으로 바꾼다고 하면, 가 된다. 즉, m번째 블록에서 발생 가능한 경우의 수는 개가 되는 셈.
에서 는 self-attention heads의 개수이며, 는 convolution heads의 개수가 된다.
Low-level Detailed architecture
high level에서 global-local 모듈의 분포를 살펴봤다면, low level에서는 구체적인 모델 아키텍쳐의 구성 요소들을 결정한다. 주로 4가지 요소에 집중하였는데, 이는 다음과 같다.
1) query(keys, values)들의 feature dimension
2) FFN의 expansion ratio,
3) first point-wise convolution layer에서의 expansion ratio,
4) 1D depth-wise convolutional layer에서의 kernel size, K
하나의 블록에 들어있는 모든 convolution head는 같은 구조를 공유한다는 점을 확인하자.
에서 각각 후보군의 개수는 로 표현한다. 이때 후보군을들 집합으로 표현하면 으로 표현할 수 있다.
Search Space Size
high level과 low level 모두를 고려할 때, 총 고려해야 되는 경우의 수는 가 된다. 해당 연구에서는 블록마다 high level과 low level을 전부 다르게 하여 실험했기 때문에, transformer가 M개의 block 있다면, 마지막 search space는 개가 된다. M=12개 블록이라고 하면, 가지의 경우의 수가 발생하는데 이는 정말로 큰 수이다. 기존의 fast Neural Architecture Search methods (differential, one-shot method)는 그정도의 큰 경우의 수를 다루는데 적합하지 않았다.
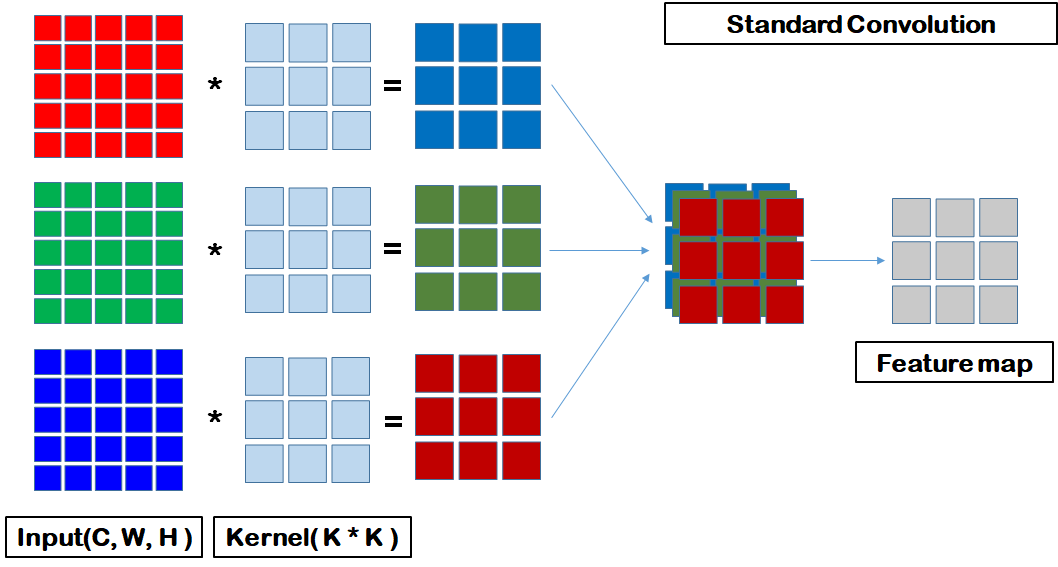
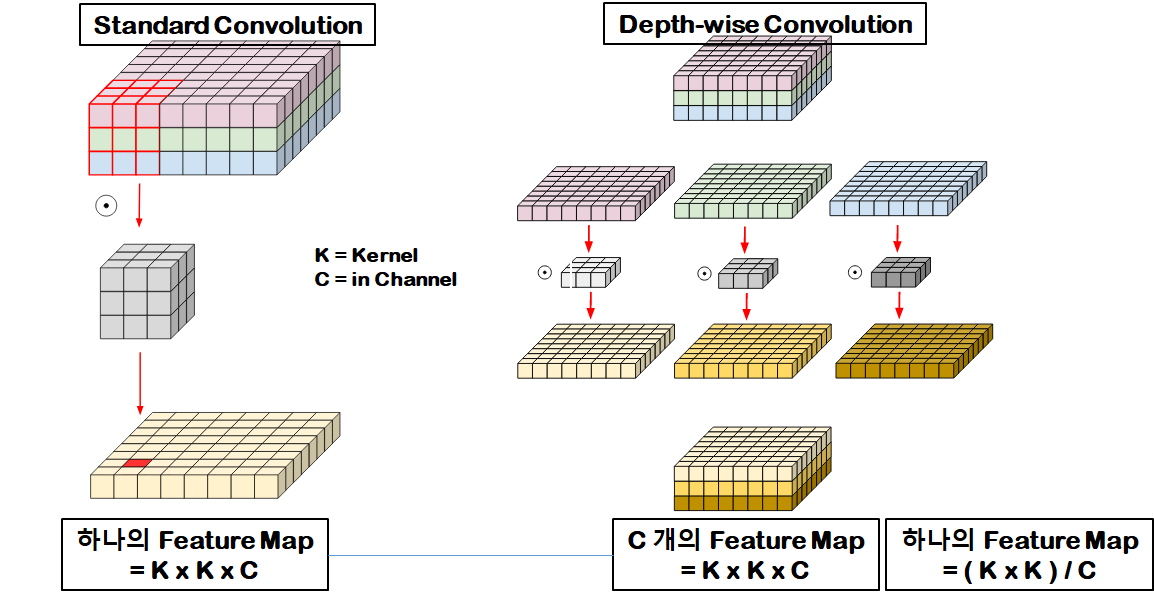
참고) standard CNN vs. depth-wise CNN vs. point-wise CNN
standard cnn
depth-wise cnn
depth-wise convolutional layer는 입력의 channel dim과 커널의 channel dim이 대응되도록 convolutional 계산이 발생한다.
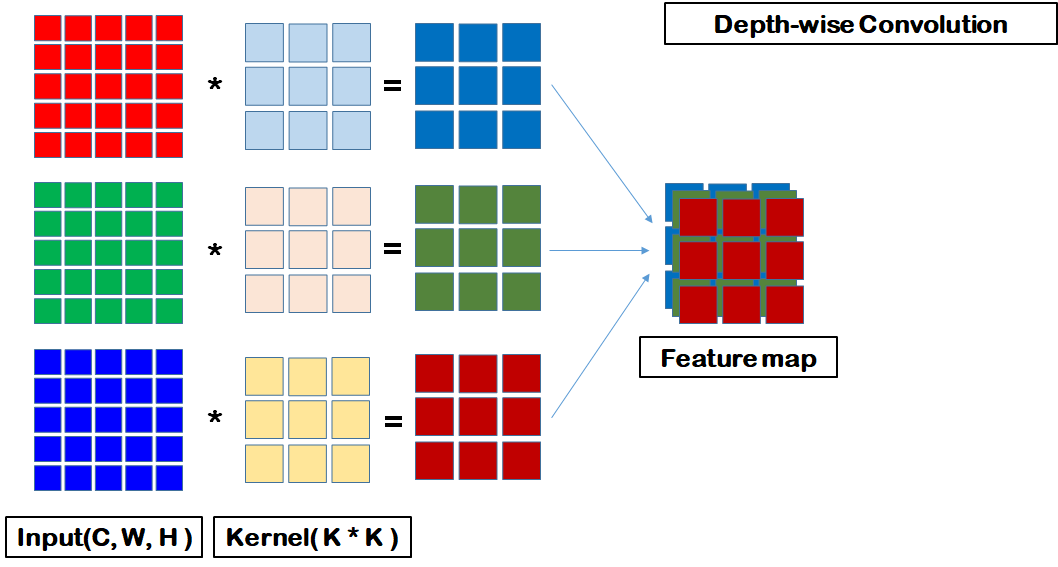
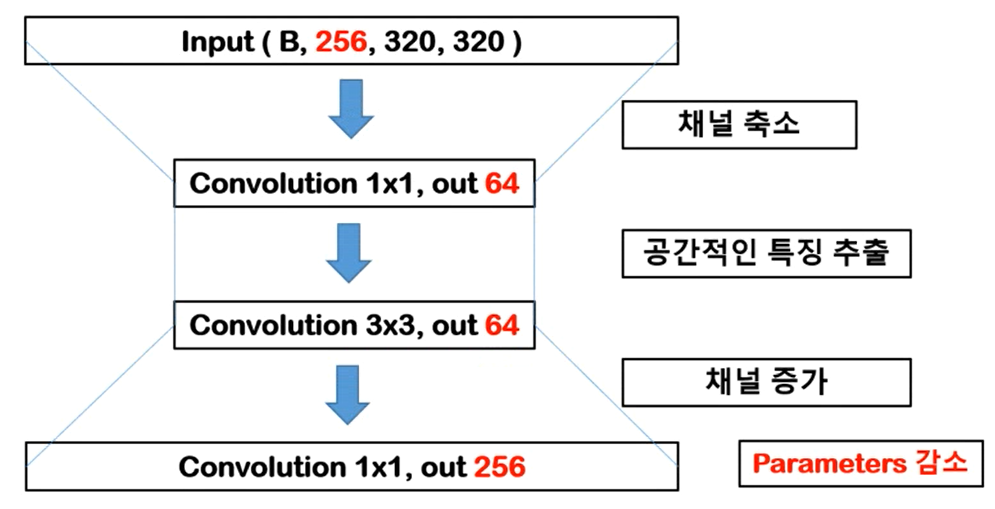
point-wise CNN
1x1 Convolution. convolution 연산이 공간적인 특성을 뽑아내기 위해서는 Kernel이 최소 2 이상이어야 한다. 따라서 해당 연산은 공간적인 특징을 가지고 있지 않다. 채널을 축소하는 방법으로 사용된다.
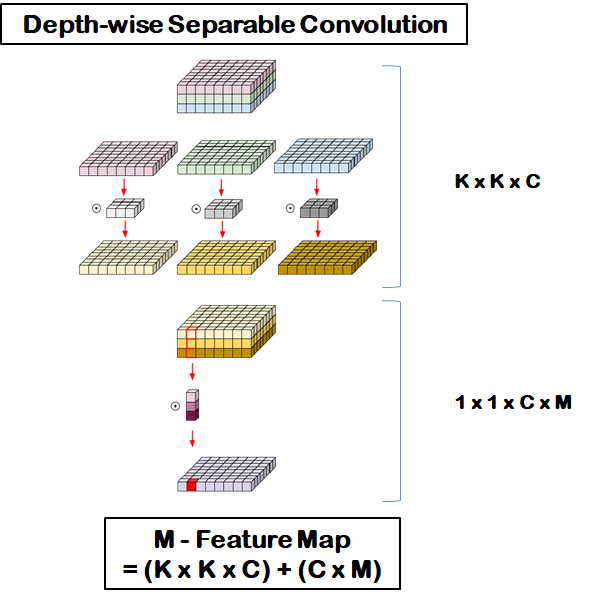
depth-wise separable Convolution
3.3. Hierarchical Neural Architecture Search
이는 두가지 main stage가 있는데, 첫번째는 global-local 모듈간의 최적의 비율 를 찾아내는 것이고, 그 다음으로는 해당 비율을 고정하고 detailed architecture 을 찾아내는 것이다.
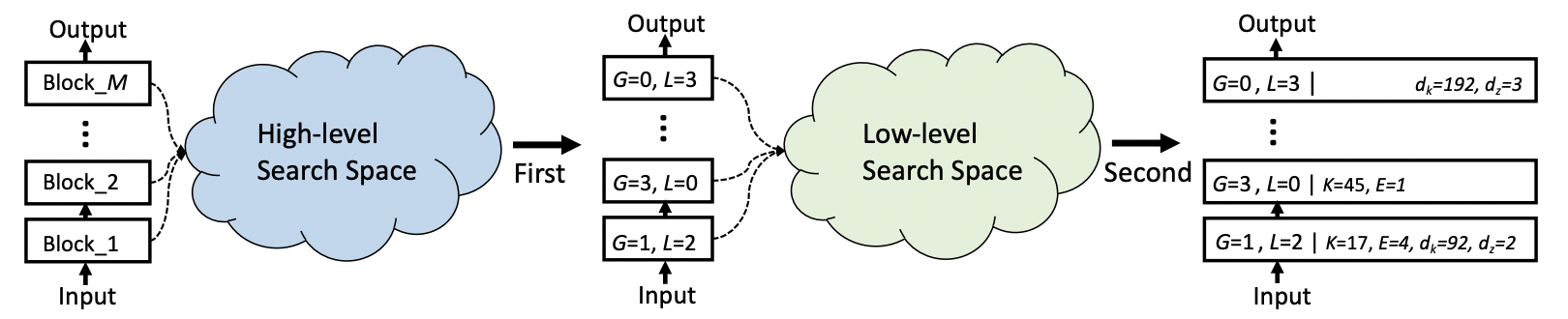
Figure 4. The framework of Hierarchical Neural Architecture Search.
First, we find the optimal distribution of local (L) and global (G)
sub-modules in the high-level search space. For example, L = 1, G = 2 means 1 local sub-module and 2 global sub-modules in the
global-local module.
Then, the detailed architecture for all sub-modules is searched in the low-level search space
First Stage
low level에서의 detailed architecture parameter를 다음과 같이 가정하자, . one-shot NAS method SPOS은 최적의 N(global, local submodule의 최적 비율)을 찾아내는데 사용된다. SPOS가 적용되는 세가지 main step은 다음고 같다.
1) supernet training, 2) subnet training, 3) subnet retraining.
supernet을 학습하면서 램덤하게 을 뽑아낸다. 해당 indices들을 supernet에서 subnet을 뽑아내는데 사용한다. M개의 block들에서 global, local sub-module의 개수는 로 정의된다.
step2 과정인, subnet을 학습시켜 준다. 이후 Evolutionary Algorithm을 사용하여, validation accuracy 기준으로 top-5인 최적의 구조들을 찾아내면 되겠다.
마지막으로 subnet을 다시 학습 시키는 과정이 있다. 해당 과정에서는 우리가 얻은 5가지 네트워크를 다시 학습시키고, 가장 높은 validation accuracy를 갖는 모델을 선택한다.
Second Stage
global local submodule의 적절한 비율을 찾아냈다면, 이를 고정하고 detail architecture를 탐색해야 핟나. 이 또한 first stage에서와 유사하게 SPOS를 사용하여 적절한 를 search space에서 찾아냈다. first stage와 second stage가 다른 점은 우선 search space가 바뀌었다는 점이고, 이에 따른 random index가 single number 에서 4개의 원자를 가지는 array인 이 되며 각각 와 대치된다.
해당 논문에서 제안하는 이러한 탐색법은 기존의 탐색법과 비교할 때, 몇가지 장점을 갖는다. 첫째는 매우 큰 search space를 좀 더 작은 search space로 쪼개었다는 점이다.
의 search space size가 로 바뀌었다. 이는 배 정도의 감소.
둘째는 Second stage의 search space의 크기를 global-local distribution을 고정함으로써 에서 더 줄일 수 있다는 점이다.

Figure 5. The architecture of GLiT-Tiny in Table 3.
Each box represents a global-local block. The darker the color denotes the more local sub-modules in the block.
L is the number of local sub-modules in each block. G is the number of global sub-modules.
Figure5에서 확인할 수 있듯이, 탐색된 architecture에서 대부분의 block들은 global sub-module, local-submodule 하나씩으로만 이루어져 있다. 오직 2개의 block만 global, local sub-module들을 모두 가지고 있다. 즉, 대부분의 block에서 low-level search space는 가 아니라, 또는 가 된다.
To fix the size of search space for each block, we reduce the search space for the blocks with both global and local sub-modules, by only searching dz and E for these blocks.
마지막 search space는 초반보다 매우 작아져서, 현재 존재하는 effective search space가 다룰 수 있는 범위로 들어온다. 이를 통해 SPOS를 활용하여 더 나은 모델을 습득하는 것이 수월해진 것이다.
4. Experiments
image classification task에 GLiT을 사용하였고, 이를 DeiT과 비교하는 실험과 이외에도 제안한 search space, search method가 갖는 중요성을 증명할만한 실험을 진행하였다.
4.2. Overall Results on ImageNet
비슷한 FLOPS를 갖는 네트워크 중에서는 더 나은 정확도를 기록하였다.
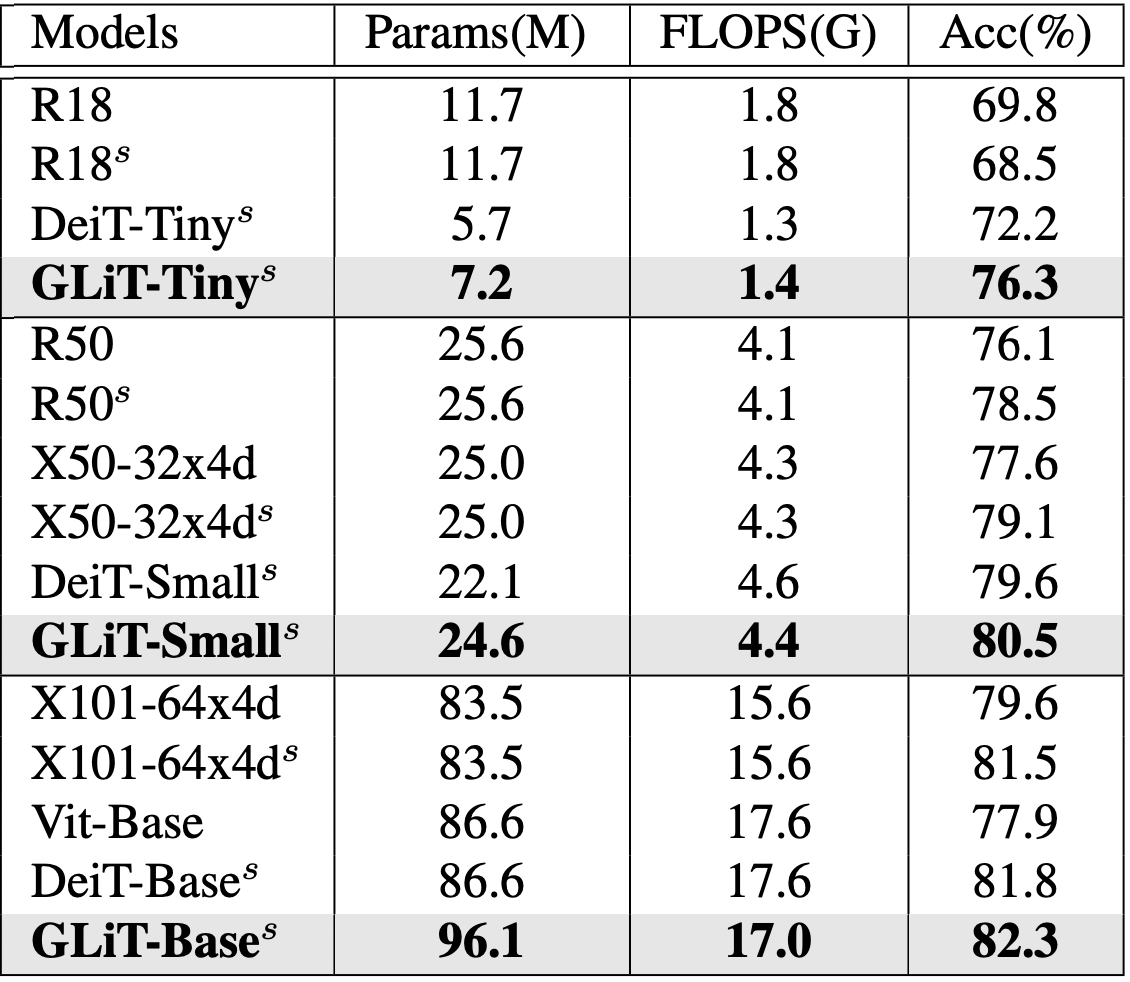
Table 3. Classification accuracy of different models on ImageNet
4.3. Ablation Study
GLiT-tiny 모델 기준으로 진행
Searching Space
global-local distribution, detailed architecture를 결정하는 순으로 진행된다. 두 단계 모두에서의 효율성을 증명하기 위해 global-local distribution만 진행한 결과와, DeiT를 비교해보았을 때, 전자의 성능이 월등하였다. 또한 NLP-NAS의 연구결과와도 비교해 보았을 때, (해당 method는 expansion ratio(query, key, value)와 MLP ratio를 포함한다.) 73.4%의 결과가 나왔고, 해당 논문의 결과는 76.3%로 월등한 결과를 보였다.
NLP-NAS에서와 같이, 직접적으로 search space를 사용하는 방식은 성능 향상을 제한한다. 이런 면에서 더 효율적인 search space, search method를 제안하였다는 점이 이 논문의 contribution이라고 볼 수 있겠다.
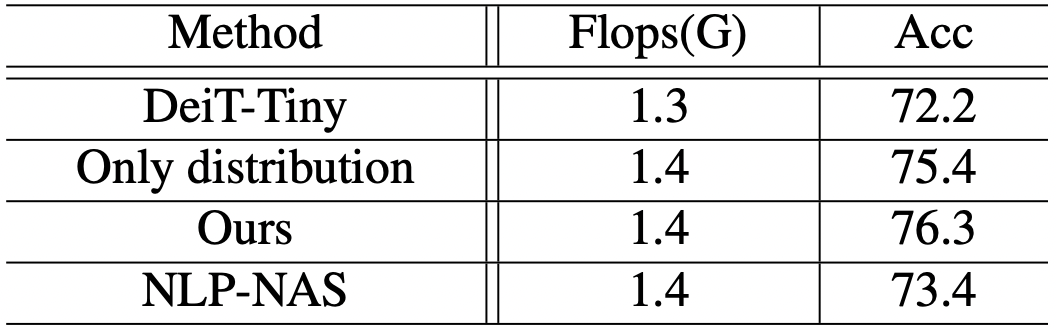
Table 4. Performance comparisons of models from different searching spaces on ImageNet.
‘DeiT-Tiny’ is the baseline model which totally relies on hand-designing. ‘Only distribution’ is the model searched only on global-local distribution. ‘Ours’ is the model searched from the complete searching space.
Neural architecture search - Wikipedia
Searching Method
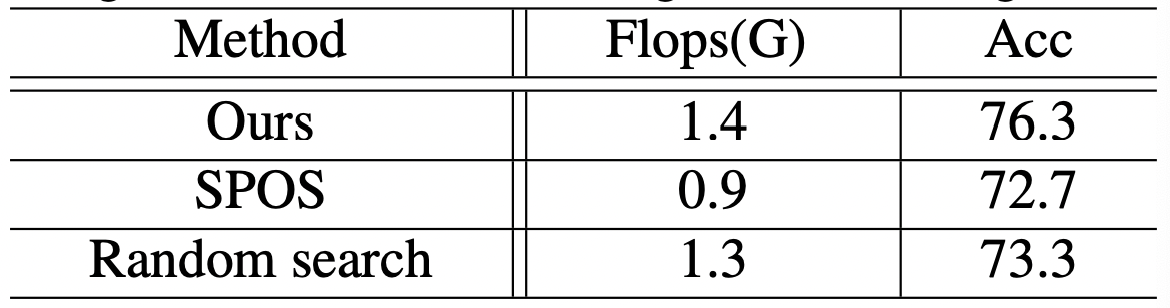
Table 5. Performance comparisons between SPOS, Random searching baseline, and our searching method on ImageNet
Methods to introduce locality
해당 연구에서는 Conv1D를 도입하면서 Vision Transformer에 locality를 부여하였다. 그러나, 다른 방법도 존재한다. 가령, local area로 self-attention의 범위를 제한하거나, Conv2D를 쓰는 방법들이 있다.
세가지 방법들 모두 비교한 결과가 다음과 같다.
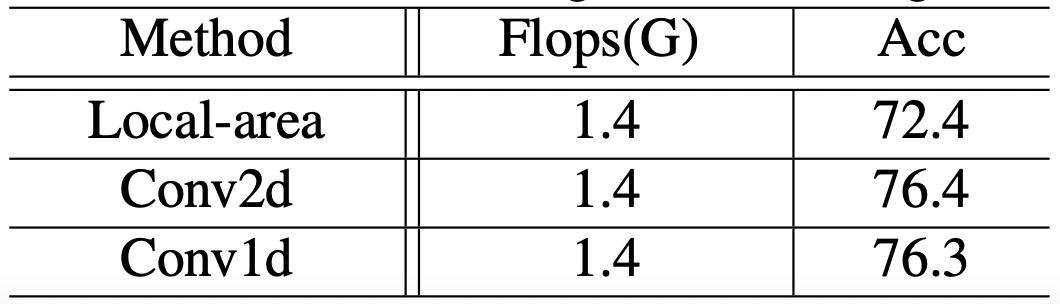
Table 6. Performance comparisons between Self-attention in a local area, Conv2D and our searching method on ImageNet
Local-area는 (14, 28, 49)로 제한해주었는데, 그럼에도 불구하고 local area들 간의 소통이 잘 이뤄지지 않은 것을 확인할 수 있다. Conv2D를 사용해주기 위해서는, CLS token을 없애주고, 마지막 layer를 Global average pooling으로 바꿔주었다. kernel size는 으로 해주었다. 이는 Conv1d를 넣어준 결과와 유사하다.
4.4. Discussion
Searched architecture

Figure 5. The architecture of GLiT-Tiny in Table 3.
각각의 박스는 global-local block을 의미하여, 어두운 색의 박스일수록 Local module이 더 많음을 뜻한다.
L is the number of local sub-modules in each block. G is the number of global sub-modules.
위의 figure를 보면, 25%의 블록만이 local-global module을 모두 포함하며, 이외의 블록들은 global, local에 대해 하나씩만 가지고 있다. Sub-module들 간의 Sequential connection은 parallel connection보다 더 필수적인듯 하다.
또한, kernel size를 17로 갖는 1D convolution layer가 searched architecture에는 없다. 17은 search space에서는 가장 작은 크기의 kernel size가 되는데, 너무 작은 사이즈의 kernel은 vision transformer의 locality module로 사용하기 적합하지 않기 때문.
searched architecture는 all-local → local-global mixtrure → all-local의 순서로 진행된다. 이러한 진행은 transformer block들로 하여금 local & global feature들을 상호적으로 적용할 수 있게 한다.
Visualization
local global feature가 적절하게 구성되었기 때문에 heat map 또한 적절하게 표시된 것을 확인할 수 있다. DeiT보다 object region에 더 집중하고 있음을 확인 가능하다.

Figure 6. Visualization of features for DeiT [28] (second row) and our GLiT (third row). Images in the first row are from ImageNet
5. Conclusion
local information과 hierarchical searching method를 새롭게 도입하여, searching space를 디자인하였고, 이를 통해 더 나은 구조의 vision transformer를 만드는데 성공했다.
