Accepted: ICCV
Created time: March 17, 2022 5:20 AM
Date: 2021
Last edited time: March 30, 2022 12:35 PM
Tags: Computer Vision, transformer
url: click
0. ABSTRACT
transformer model이 이미지 분류 태스크를 처리할 때, multi-scale feature representation을 어떻게 학습하는지에 대해 연구한 논문입니다.
다양한 사이즈의 이미지들(토큰들)로 하여금 더 강한 이미지 특성들을 뽑아내기 위해 dual-branch transformer를 제안하는데요. 조금 더 자세히 설명해보자면, 작은 사이즈의 패치와 큰 사이즈의 패치를 두 개의 분리된 branch(가지)로 하여금 처리하도록 하는데, 이 때 각 가지의 계산 복잡도도 다르다고 합니다. 다른 가지에서 처리된 토큰들은 attention에서 서로를 보완해주기 위해 fused(아마 concatenated인듯..?) 됩니다.
계산량을 줄이기 위해, cross attention에 기반하여 토큰 fusion module을 개발하였, 서로 다른 가지들 간의 정보 공유를 위해서 각 가지마다 하나의 토큰을 query로써 사용하는 원리입니다. 이는 계산 복잡도와 메모리 복잡도에서 선형성을 갖도록 하여 그 효율을 높여주는 역할을 합니다.
제안된 모델은 현재 나와있는 Vision transformer, efficient CNN model들 중에서 더 나은 성능을 보입니다.
1. Introduction
Vision transformer와 Convolution을 결합하려는 시도가 활발하게 이루어 지고 있죠. 그러한 결합 시도는 어느 정도의 성능 향상이 보장되어 있다고 말할 수 있지만, 계산하는데 있어서 제한된 확장성을 갖게 됩니다. (limited scalability)
ViT는 최초로 convolution 모듈을 사용하지 않고, 온전히 tranformer 모듈로만 구성되어 있는 모델이며, 기존의 CNN 모델들과 비등한 결과를 보입니다. 그러나 매우 큰 학습 데이터 셋을 필요로 하죠. DeiT은 data augmentation과 model regularization을 통해 더 적은 데이터로도 ViT를 더 잘 학습 가능하다는 사실을 밝혔습니다. 이 이후로는 ViT를 좀 더 ‘효율적'으로 만들고자 하는 여러 시도들이 있게 되는데요. [35, 45, 14, 38, 19].
해당 연구진은 ViT를 더 발전시켜보자는 연구 흐름과 결을 같이 합니다. 그 중에서도 Transformer 모델이 이미지 분류 태스크를 처리할 때, 다양한 scale에서의 특성값들을 어떻게 학습하는지에 초점을 두고 있습니다.
Multi-Scale Feature Representation은 기존의 vision task들에 대해 성능 향상을 불러왔습니다. 그러나 이러한 요소가 transformer에서 어떻게 적용되고 어떤 성능 변화를 불러올지는 증명되지 않은 상황이었습니다.
해당 연구진은 Big-Little Net, Octave convolution과 같은 multi-branch CNN 구조의 ‘Effectiveness’에 영감을 받았습니다. 이에, dual branch를 갖는 transformer를 만들어, 다양한 사이즈의 image patch들 간 더 강한 visual feature들을 생성할 수 있도록 연구하였습니다.
작은 패치와 큰 패치를 각각의 branch가 처리하도록 하고, 추후 그들을 여러번 fused 하여 서로간의 보완을 할 수 있도록 해주었습니다. 해당 연구에서 가장 주요한 부분은 efficient cross-attention module 기반으로, vision tranformer에 적합한 fusion module를 개발하는 일이 되겠습니다.
각 트랜스포머의 branch가 non-patch token을 각각 생성하고, attention을 통해 서로간의 정보를 교환할 수 있게 해주었습니다. 추가적인 아키텍처의 변동으로 적은 양의 파라미터를 추가하면서도, DeiT보다 2%의 정확도 향상이 있었습니다.
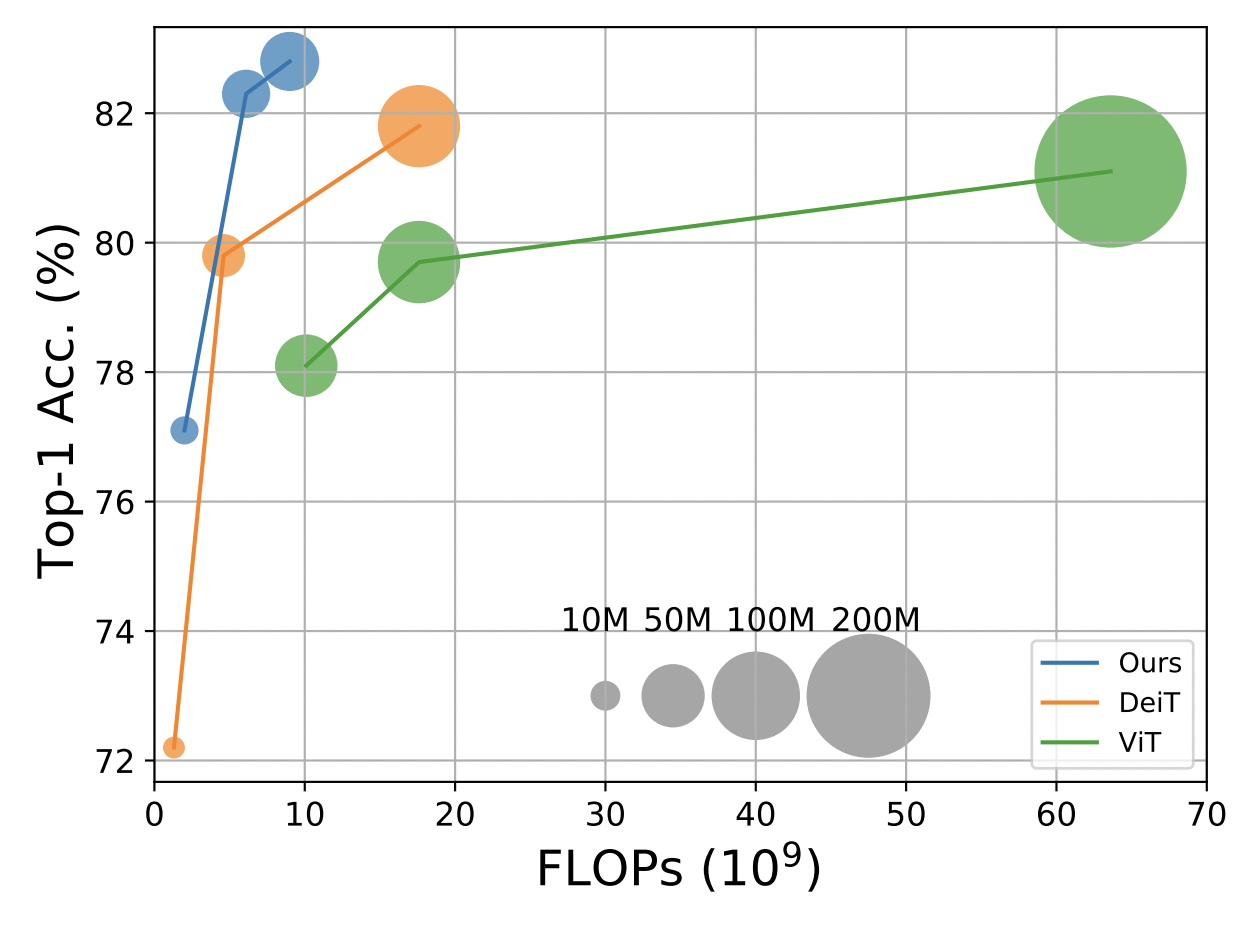
Improvement of our proposed approach over DeiT [35] and ViT [11].
정리하자면,
- dual-branch의 새로운 비전 트랜스포머를 제안하여 multi scale의 feature representation을 추출해 내도록 하였고, cross-attention을 기반으로 하여 토큰을 fusion하였습니다. 선형적인 계산 복잡도와 메모리 복잡도를 갖게 됩니다.
- 기존의 ViT 기반 연구들에 비해 괄목할만한 성능을 보여주며, EfficientNet과도 그 성능이 비견됩니다.
2. Method
2.1. Overview of ViT
→ 이 부분은 이미 알고 있는 파트라서 생략~
2.2. Proposed Multi-Scale Vision Transformer
ViT에서 patch size는 중요한 역할을 한다. 패치를 16x16으로 할 때와, 32 x 32로 할 때는, 전자의 경우가 6% 가량 높은 정확도를 보이지만, 4배 더 많은 FLOPs를 필요로 합니다. 해당 연구는 연산량은 어느정도 균형을 맞추면서, 더 작은 패치로 진행할 때의 장점을 극대화 하기 위해 노력하죠.
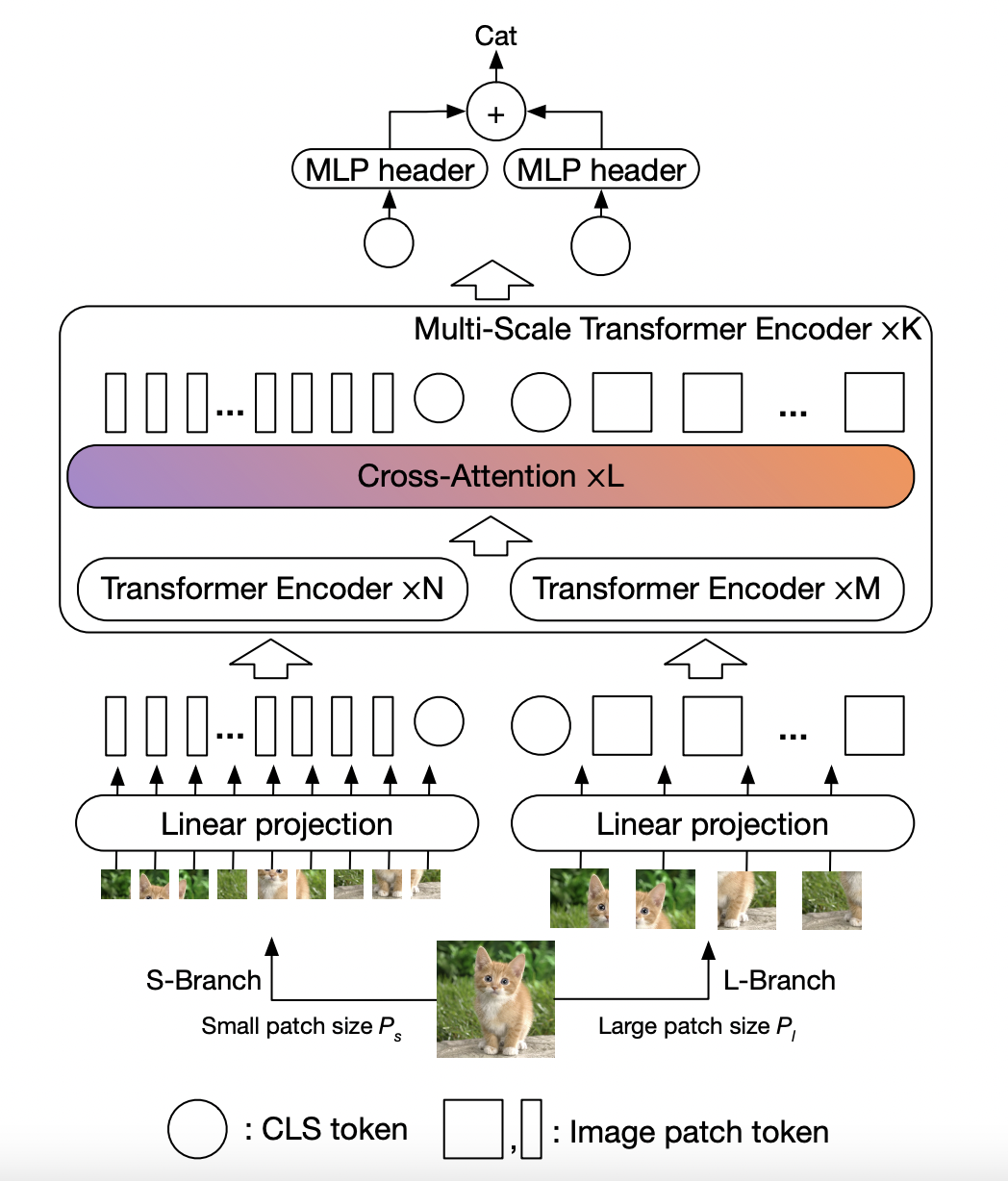
An illustration of our proposed transformer
architecture for learning multi-scale features with crossattention (CrossViT).다른 사이즈(로 패치를 나누어, 이미지 토큰들로 만들어 준 다음에 efficient module 기반으로 만들어진 cross attention에서 이들을 fusion(결합) 해준다.
위 모델은 다음과 같은 요소들로 구성됩니다.
L-Branch: coarse-grained patch size(을 다루는 큰 가지.
더 많은 트랜스포머 인코더와 더 넓은 엠베딩 차원.S-Branch: fine-grained patch size(를 다루는 작은 가지.
더 적은 트랜스포머 인코더와 더 작은 엠베딩 차원.
이 두 가지들은 L번 결합하게 되고, 두 br의 끝에서 CLS 토큰이 예측에 사용됩니다. 두 가지의 각 토큰들에는 학습 가능한 position embedding을 추가하여 multi-scale transformer 이전에 위치 정보에 대해 학습할 수 있게 해주었습니다.
효율적인 feature 결합은 multi-scale feature representation을 학습하는데 키 역할을 하는데요. 다음은 4가지 결합 방식에 대한 소개인데, 3가지는 휴리스틱한 전략이며 (d)가 해당 논문에서 제안하는 방식이 되겠습니다.

Figure 3: Multi-scale fusion.
(a) All-attention fusion where all tokens are bundled together without considering any characteristic of tokens.
(b) Class token fusion, where only CLS tokens are fused as it can be considered as global representation of one branch.
(c) Pairwise fusion, where tokens at the corresponding spatial locations are fused together and CLS are fused separately.
(d) Cross-attention, where CLS token from one branch and patch tokens from another branch are fused together.
2.3. Multi-Scale Feature Fusion
i 브랜치에서 시퀀스 데이터는 으로 표현하고,
는 각각 i 브랜치에서의 CLS, patch token을 의미합니다.
2.3.1. All-Attention Fusion
(a)에 해당하는 방법. 토큰의 성질을 신경쓰지 않고, self-attention block으로 결합해준다.
는 각각 projection과 back-projection 함수를 의미한다.
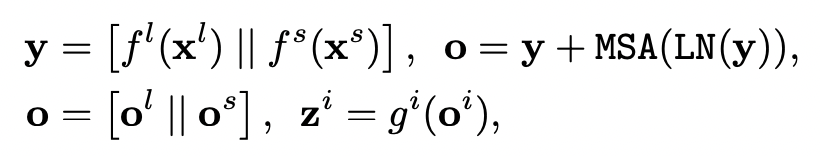
식 설명: y는 우리가, L branch와 S branch에서 각각 output을 구했다는 말이 된다. 이를 self-attention 식에 넣어 o를 얻어낸다.
2.3.2. Class Token Fusion
해당 결합 방식은, 하나의 토큰, CLS 토큰만을 더해서 결합하는 방식이다. CLS 토큰은 prediction 단계에서 사용되는 토큰인만큼, abstract global feature representation을 가지고 있다.
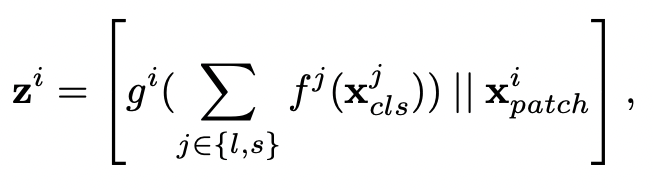
2.3.3. Pairwise Fusion
patch 토큰들을 각각의 공간적으로 corresponding한 토큰들끼리 결합되고, cls token은 각각 결합시켜준다. patch 토큰을 결합할 때의 문제점으로는 서로 다른 patch size를 사용하기에 patch의 개수가 다를 수도 있다는 점인데, spatial size를 맞춰주기 위해 interpolation을 수행해주고, pair-wise한 방식으로 결합해준다.
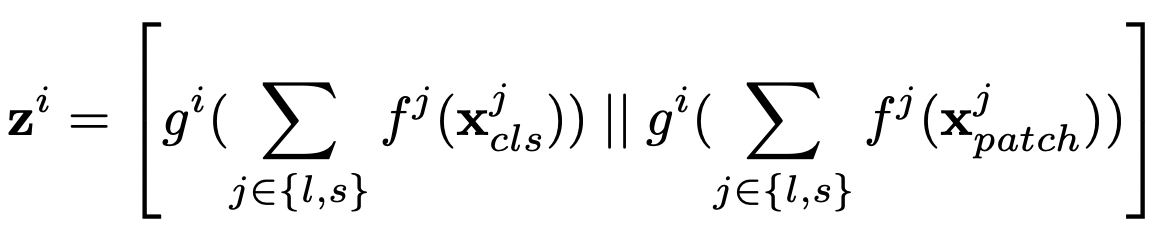
2.3.4. Cross-Attention Fusion
해당 결합 방식은 이번 논문에서 제안한 핵심적인 파트이다. CLS 토큰을 서로의 브랜치로 보내준다. 이때, agent라는 표현을 사용하는데, 상대 브랜치로 가서 그곳의 patch들의 feature들을 대략적으로 학습하고 돌아온다는 것이다.
back project는 다시 본래의 브랜치로 돌아와 수행한다. 즉, cls 토큰의 교환을 통해, 서로간의 patch token들의 정보를 교환할 수 있게 되는 것이다. 이는 다른 이미지 크기에서의 정보들을 각각의 브랜치가 학습할 수 있도록 해준다.
아래 Figure 4의 과정으로 Cross Attention이 수행된다.
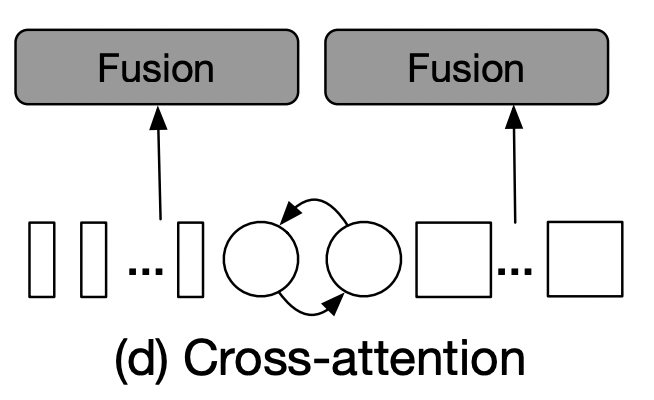
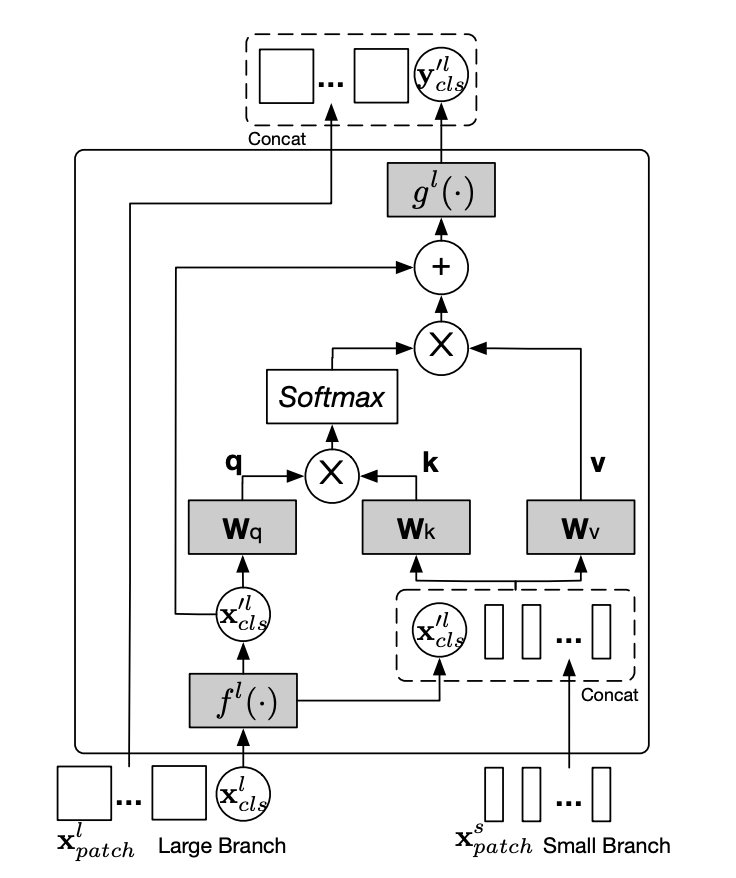
Figure4: Cross-attention module for Large branch,
CLS 토큰은, attention 과정에서, 상대 브랜치의 patch 토큰들과 상호작용하는 ‘query token’의 역할을 한다.
그림 자체가 선이 꽤 많아서 복잡하게 보이지만, 하나하나 그 과정을 따라가면 어려울 것이 없다.
은 small 브랜치의 패치와 large 브랜치의 cls 토큰을 projection하여 concat 한 것.
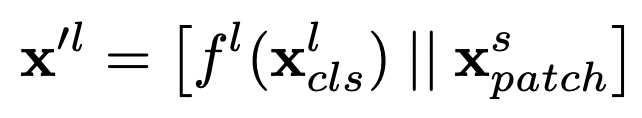
은 dimension alignment를 위해 사용하는 projection 함수이다. 그 다음 를 Cross Attention에 넣어준다. 계산은 다음과 같다. 쿼리를 오직 cls 만으로 계산했고 계산 복잡도나 메모리 복잡도를 선형으로 유지할 수 있었다.
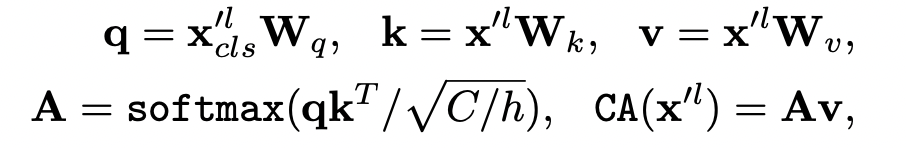
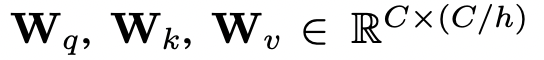
C: embedding dimension, h: num of heads
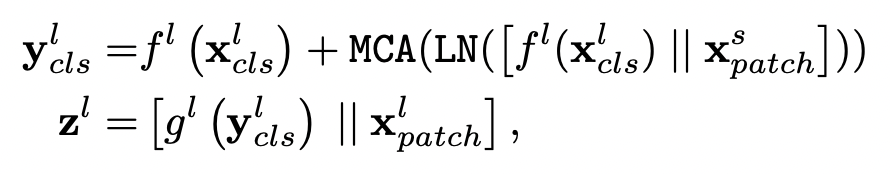
여기서 f, g는 각각 projection, back-projection 함수이다.
3. Experiments
DeiT를 베이스 라인으로 해서 제안된 모델이 어떤 이점을 갖는지 확인하였고, 현재 나와있는 다양한 ViT variants, CNN-based models들과 비교를 진행했다.
3.1. Comparisons with DeiT
가장 눈에 띄는 변화는 CrossViT-9에서 발생했다. Transformer의 인코더가 많을수록 convolution layer의 영향력이 하락하는 경향이 있었는데, CrossViT-18+는 Cross-ViT18보다 괜찮은 성능을 냈다.
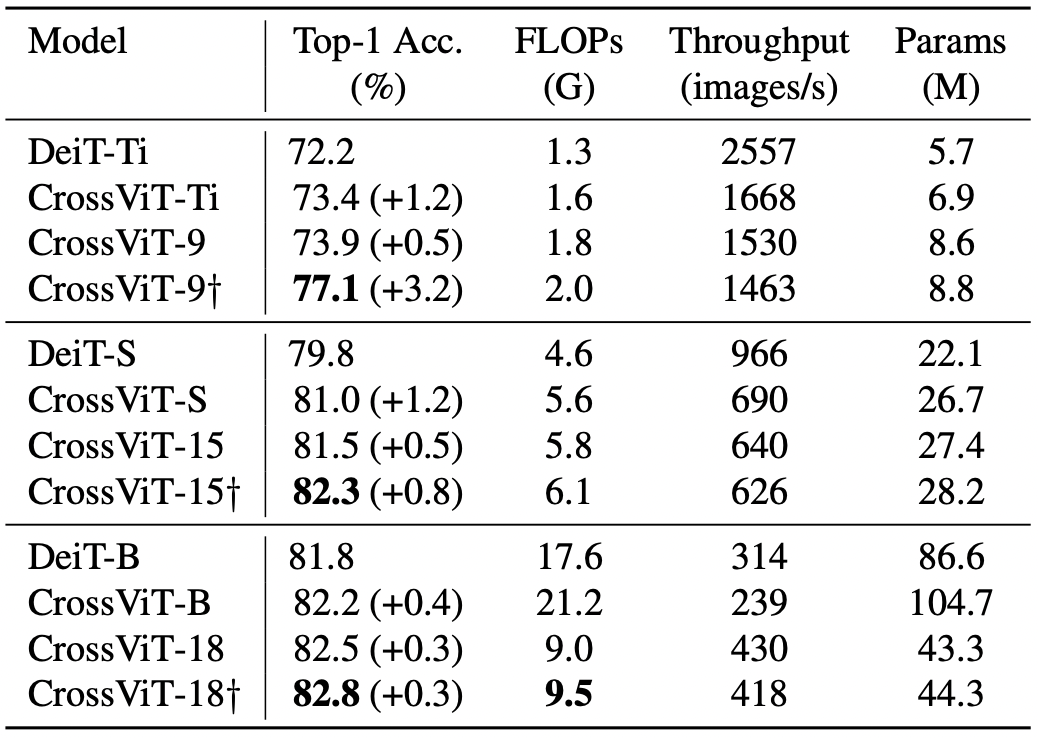
Comparisons with DeiT baseline on ImageNet1K.
3.2. Comparisons with SOTA Transformers & CNN-based Models
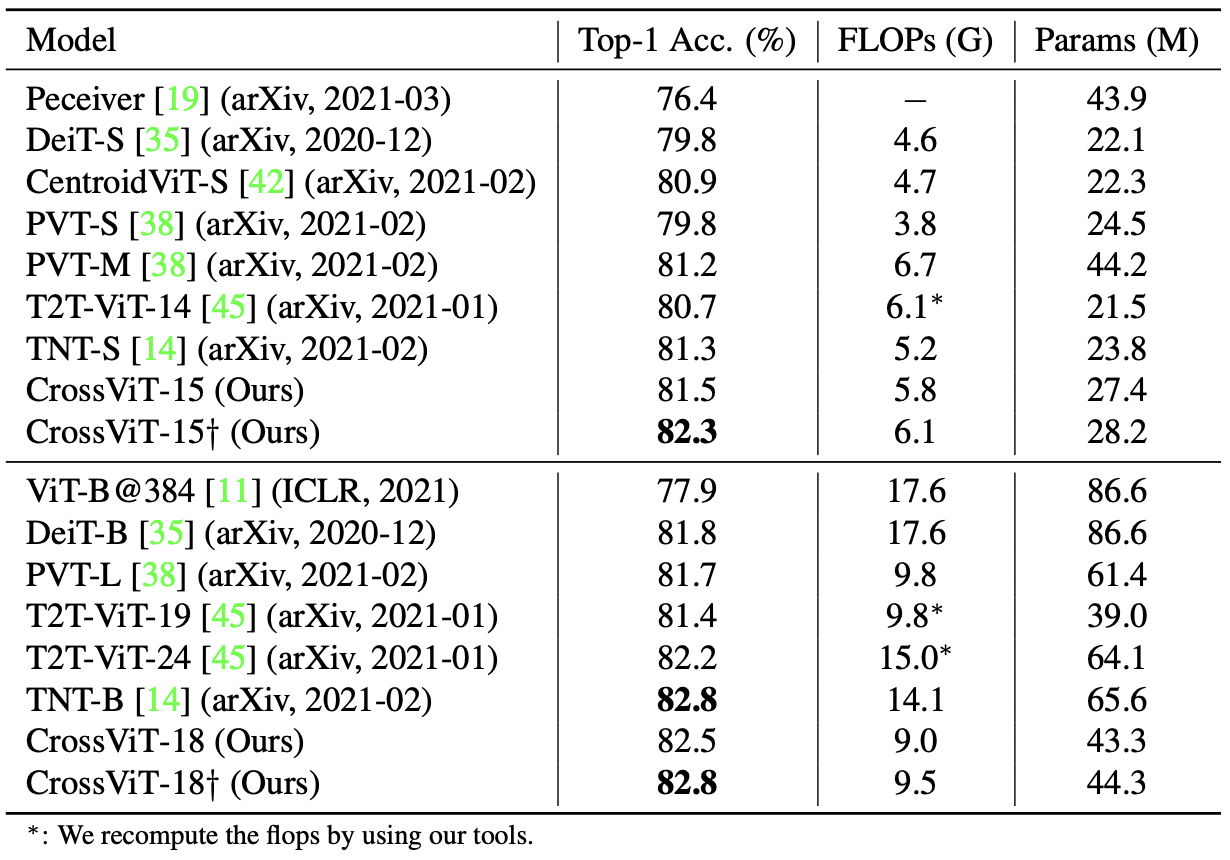
Comparisons with recent transformer based models on ImageNet1K
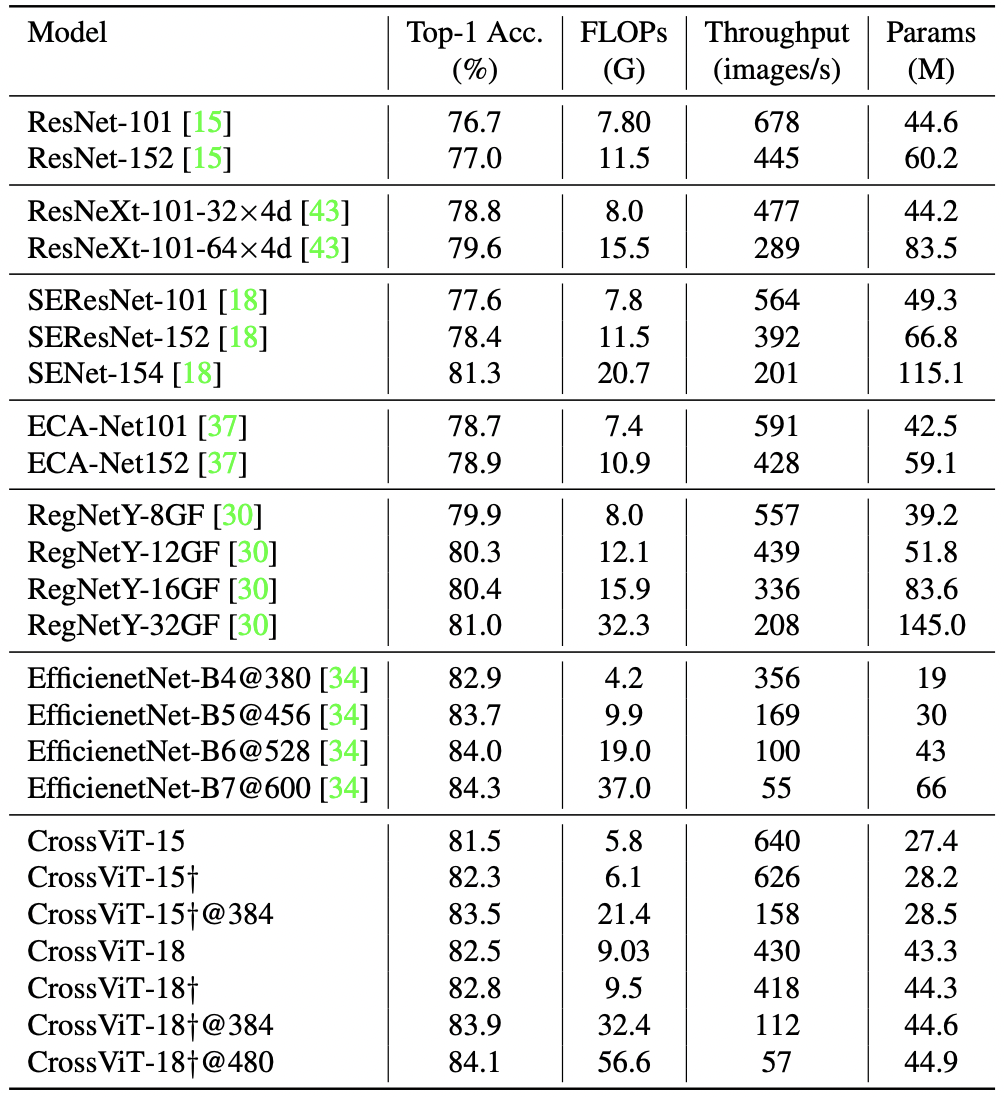
Comparisons with CNN models on ImageNet1K
3.3. Transfer Learning
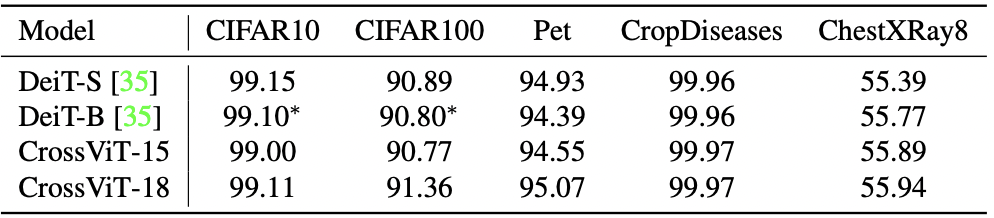
Transfer learning performance
3.4. Ablation Studies
Comparison of Different Fusion Schemes.
(I)no fusion, (II) all-attention, (III) class token fusion, (IV) pairwise fusion, and (V) the proposed cross-attention fusion
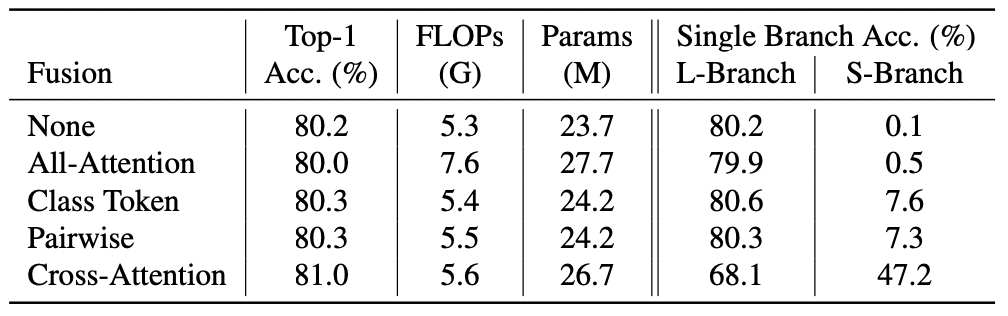
Ablation study with different fusions on ImageNet1K
Comparison of Different architecture parameters.
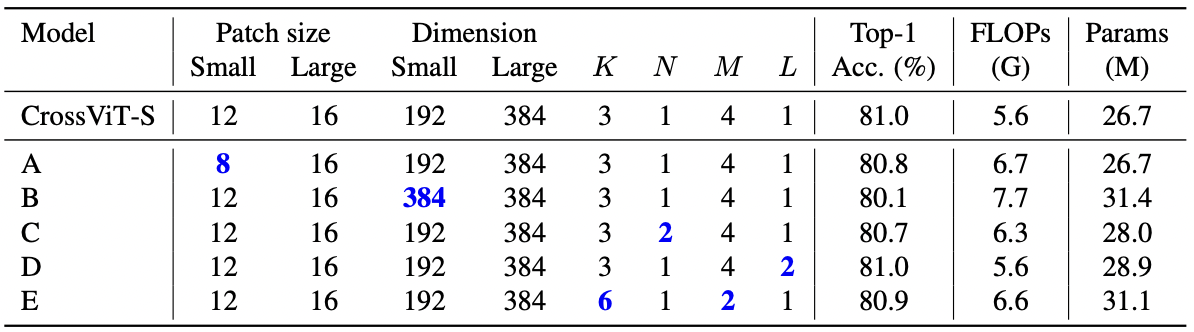
Ablation study with different architecture parameters on ImageNet1K
4. Conclusion
두 개의 브랜치를 갖는 vision transformer 모델이며, 이를 통해 다양한 크기의 이미지 feature를 뽑아내는 것을 목표로 한다. 서로 다른 크기의 이미지 토큰을 적절하게 ‘결합'하기 위해 Cross-attention을 고안해 내었다. -끝-
Summary
transformer 기반 변형모델.
ViT가 나오고, 후속 논문들을 대체로 비슷한 목표를 공유한다. 계층적인 요소를 더해 성능을 향상시키는 것. 계층적인 요소를 ‘어떻게' 첨부하는냐가 논문의 주요골자가 된다.
해당 논문에서는 서로 다른 크기를 다루는 branch를 2개 만들어, 각각 브랜치마다의 cls token, patch tokens들을 마련한다. 이 둘을 적절하게 상호 작용 할 수 있도록 해주어, 다양한 크기의 패치에서 feature를 뽑아낼 수 있다는 것.
상호작용 과정을 논문 팀에서 제안한 것 또한 의미있는 부분이다. 서로간의 CLS 토큰만 바꾸어서 모델에 넣어준다.
