Accepted: ICCV
Date: 2021
url:click
1. Abstract & Introduction
abstract.
CNN이 압도적으로 사용되던, 대용량 데이터셋에서의 이미지 분류 태스크에 'transformer'가 도입되었습니다.
vision transformer를 최적화하는 것에 대한 연구는 아직 많이 진척되지 않은 상황. 따라서, 연구팀은 deeper transformer를 제작하고 최적화하는 것을 목표로 해당 논문을 작성합니다.
크게 두가지 아키텍쳐의 변화를 도입하였으며, 이를 통해 더 깊은 모델을 이른 시기의 포화(saturation)없이도 학습할 수 있게 되었고, 그 결과 외부 데이터 없이 imageNet만으로도 86.5%의 top-1 accuracy를 내었다고 합니다.
intro.
ResNet의 등장 이후로 residual architecture는 아주 유망한 구조가 되었죠.
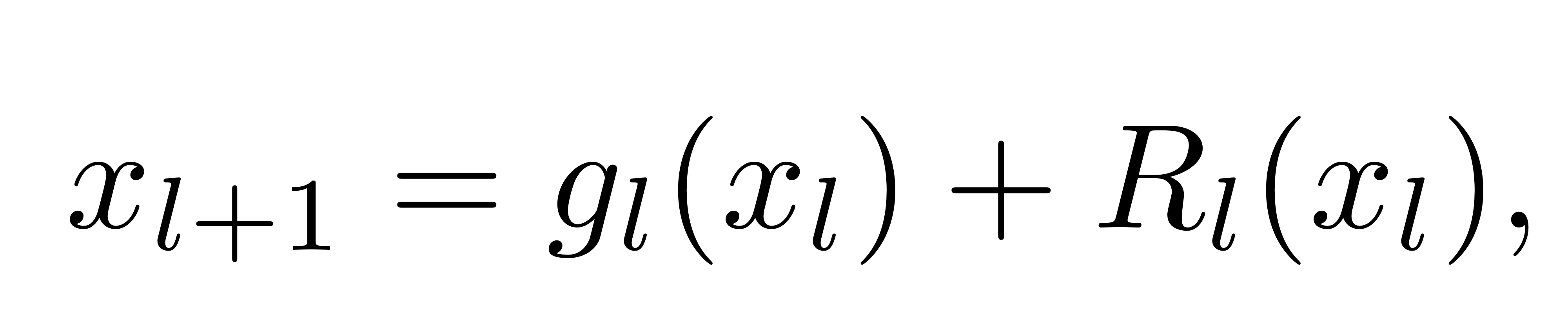
더 좋은 결과를 내는 이유는, 해당 구조가 더 나은 representation power를 제공하기 때문이 아니라, 단순히 그들이 학습하는데 용이하기 때문이라는 연구가 있었습니다.
“importance of having a clear path both forward and backward, and advocate setting gl to the identity function.”
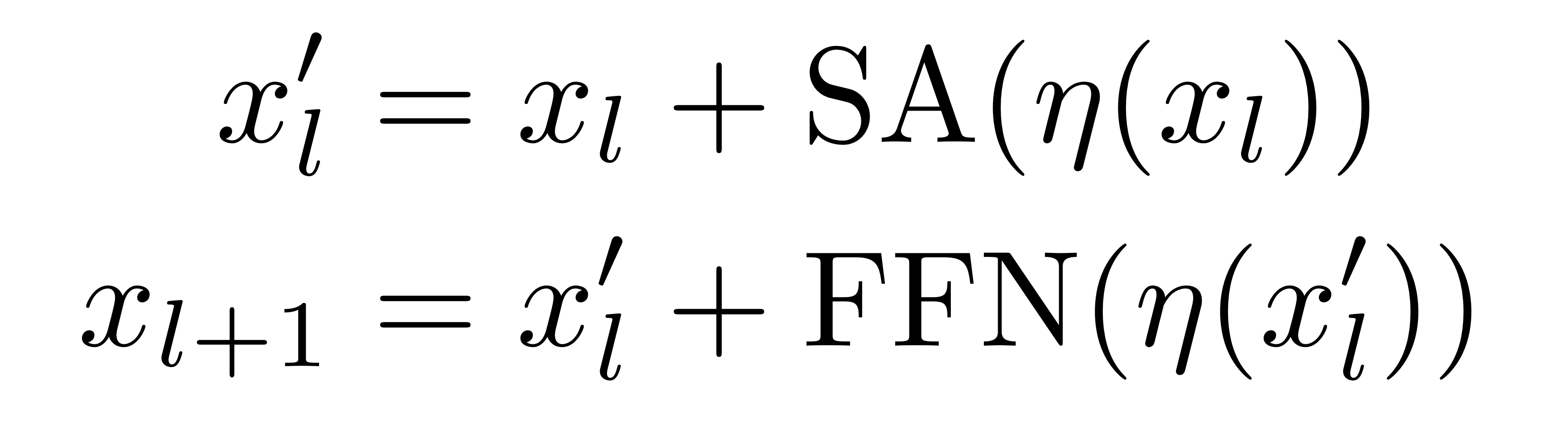
Layer Scale
Formally, we add a learnable diagonal matrix on the output of each residual block, initialized close to (but not at) 0. Adding this simple layer after each residual block improves the training dynamic, allowing us to train deeper high-capacity image transformers that benefit from depth
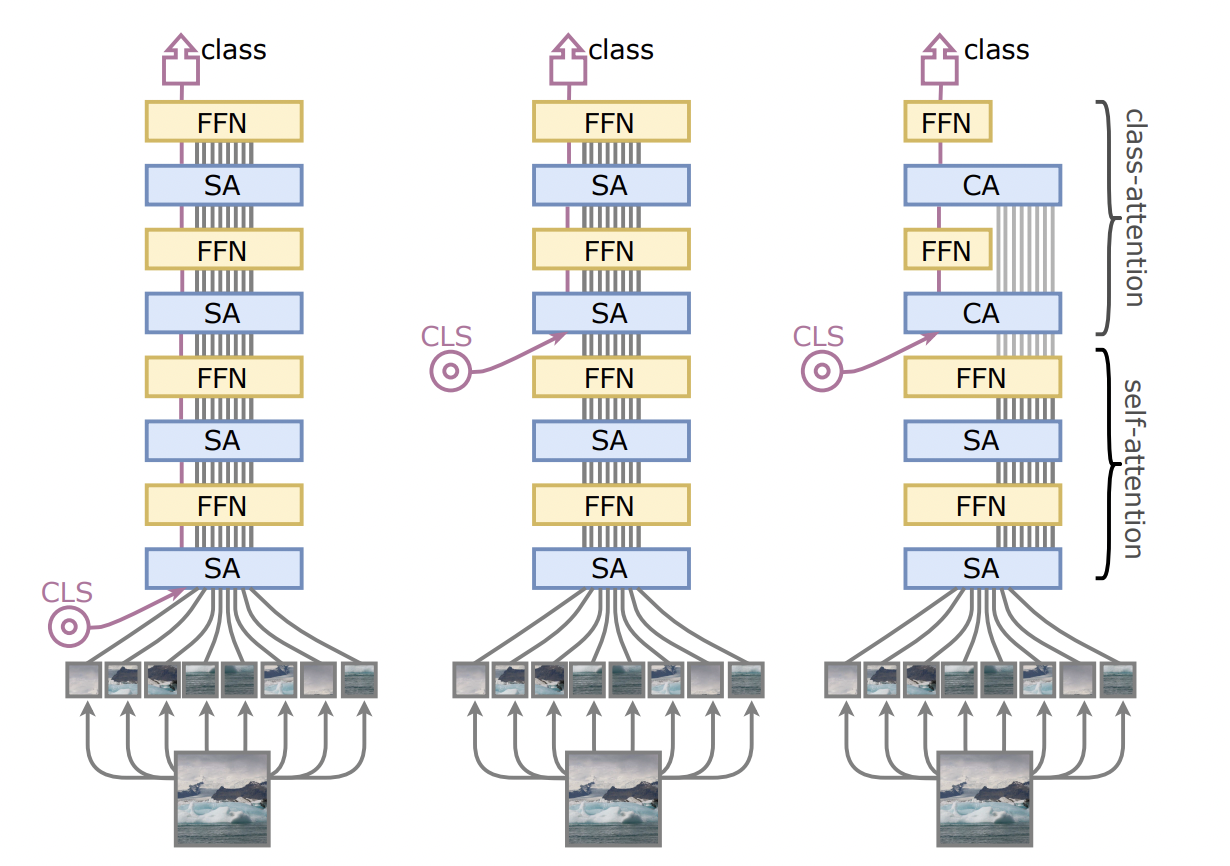
Class-attention layers
encoder/decoder와 비슷한 아키텍쳐.
패치들 간의 셀프 어텐션을 포함한 트랜스포머 레이어를 외적으로 분리한 인코더/디코더 모델입니다.
encoder/decoder architecture, in which we explicitly separate the transformer layers involving self-attention between patches, from class-attention layers that are devoted to extract the content of the processed patches into a single vector so that it can be fed to a linear classifier. This explicit separation avoids the contradictory objective of guiding the attention process while processing the class embedding. We refer to this new architecture as CaiT
Effectiveness of this Model
- LayerScale은 모델의 수렴 과정을 쉽게 만들어주어, 이미지 트랜스포머의 정확도를 향상시킵니다. 수천개의 파라미터 (전체 가중치들의 수에 비해 매우 적은) 을 활용하여 얻은 성과라는 점이 주목할만 하네요.
- class attention에 좀 더 specific한 모델을 만들어내어, class embedding 과정을 효율적으로 변환해주었습니다.
- 추가적인 데이터의 사용 없이도 Imagenet-Real, Imagenet V2에서 SOTA와 비슷한 성능을 보여주었습니다. 더 적은 FLOPs(329B vs 377B)와 더 적은 파라미터(356M vs 438M)를 사용하여, ImageNet1k-val에서는 SOTA(86.5%)를 달성했죠.
- Transfer learning에서도 좋은 성과를 거뒀습니다.
2. Deeper image transformers with LayerScale
학습 과정에서, 특히 depth를 깊게 할 때, optimization의 안정성을 향상 시키는 것은 매우 중요합니다.
ViT와 DeiT의 연구 결과를 통해, ImageNet만을 학습할 때에는, depth가 어떠한 이점도 갖지 못한다는 사실을 확인하였는데, 이는 Deeper ViT는 더 낮은 성능을 보였기 때문입니다. (DeIT은 12block을 갖는 트랜스포머를 사용)
ViT와 Deit은 (a)에 해당되는, prenorm 아키텍쳐입니다. layer-normalisation이 residual branch 전에 처리됩니다. 논문에서는, 효과적으로 모델이 converge하지 못함을 추후 실험에서 보여줍니다.
Fixup, ReZero, SkipInit은 residual block의 출력값에 사용되는, 학습 가능한 스칼라 가중치를 제안하는데, 이를 통해 pre-normalization과 warm-up을 없앨 수 있습니다.
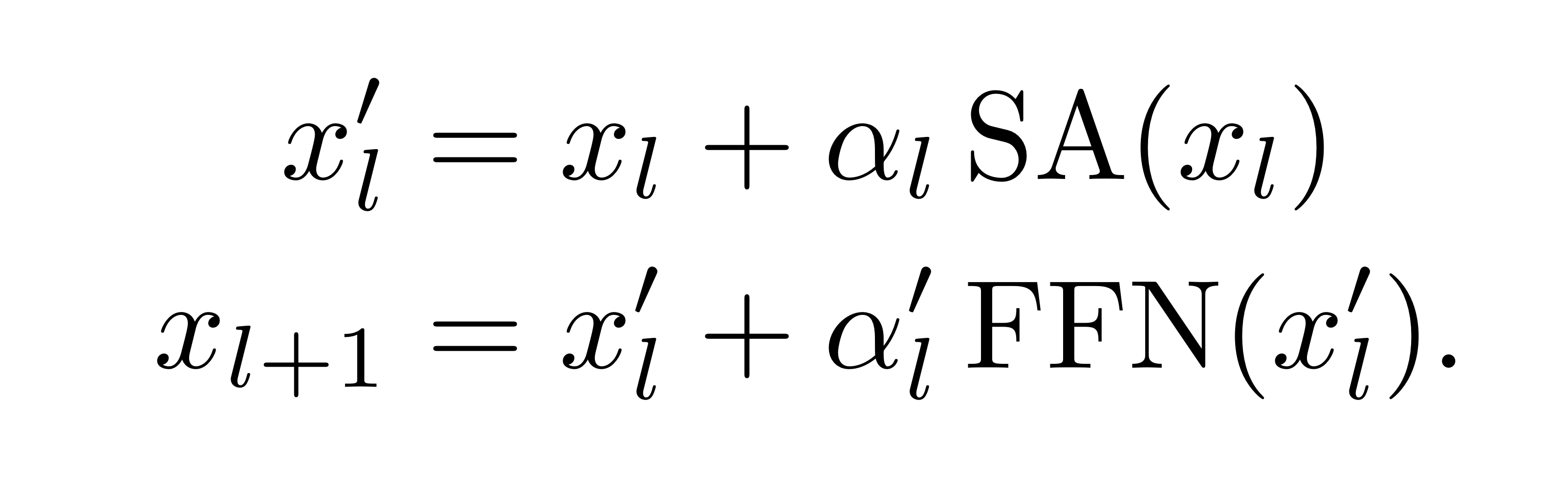
ReZero a를 0으로 초기화 하고, Fixup은 1로 초기화한다. 다른 차이점들도 있지만 해당 발표에서는 생략.
두가지 방법론을 hyper-parameter를 적절히 바꿔가면서 사용해도 모델이 converge하지 못했는데, 이러한 이유를 warmp-up과 layer normalization의 제거에 있다고 보았고, Fixup에 위 두가지를 도입하여 DeIT이 수렴하는 것을 확인합니다.
주요한 기여 요소는 학습가능한 파라미터가 있다는 점입니다. 이를 통해 depth를 크게 하여도 모델을 수렴할 수 있게 되었습니다.
Normalization Strategies for transformer block.
(a) Prenormalization
(b) ReZero/Skipinit and Fixup remove normalization and warmup and add a learnable scalar initialized to a=0 and a=1, respectively.
(c) Adapt them by reintroducing the prenorm and the warmup
(d) Main proposal, introduces a per-channel weighting (multiplication with a diagonal matrix diag where we initialize each weight with a small value)
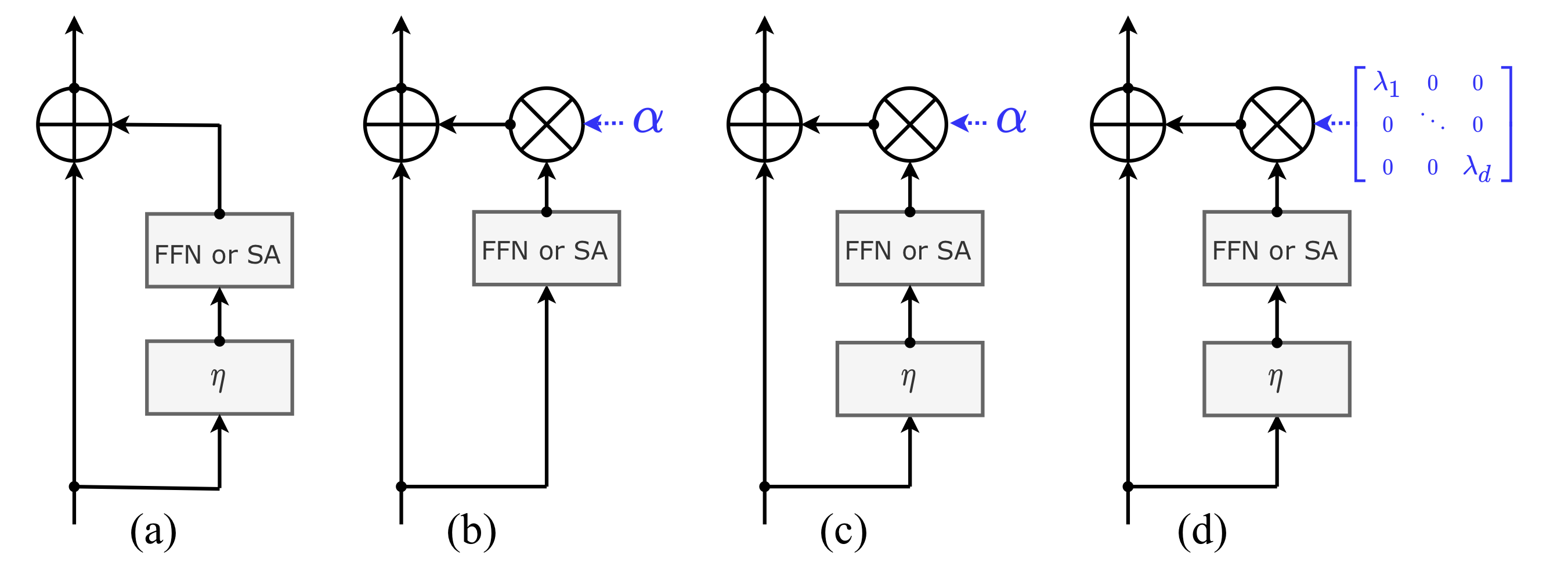
Our Proposal LayerScale
각각의 residual block에서 생성된 벡터를, per-channel multiplication 해주는 것입니다. 하나의 스칼라 값을 곱해주는게 아니라는거죠!
목표는, 연관된 출력 채널끼리 가중치를 업데이트 해주는 것인데, 즉, updates of weights를 그룹화하여 진행하는 것입니다.
이를 위해서 각 residual block의 출력값에 diagonal matrix를 곱해줍니다.
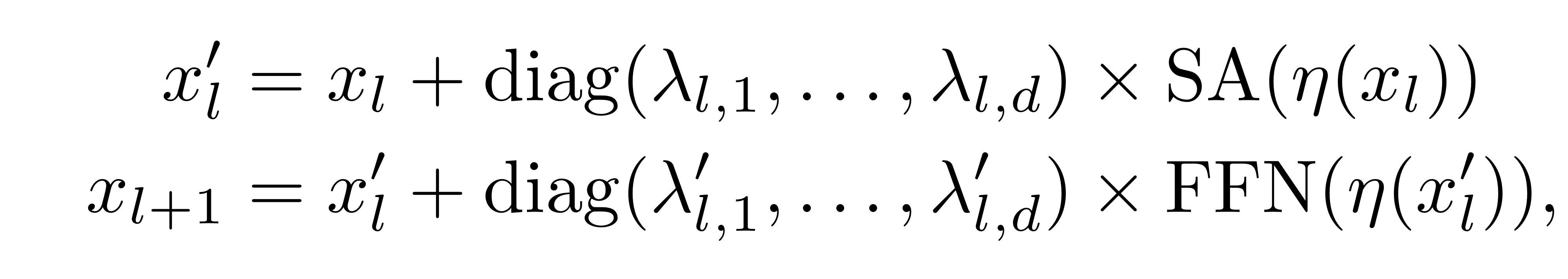
식에서 보이는 감마값들은 모두 학습 가능한 가중치들이며, diagonal의 값들은 전부 작은 하나의 스칼라 값으로 초기화 됩니다. (depth 18까지는 0.1, depth 24까지는 0.00001, 더 깊은 모델은 10**-6)
이러한 변화를 통해 모델의 expressive power까지 향상시키지는 못하였는데, 이는 SA와 FFN layer, 즉 이전 레이어에 통합되기 때문입니다.
3. Specializing layers for class attention
기존 ViT 모델에서 class token을 삽입하는 시점에 문제가 있는데요. 이로 인해 학습되는 weight는 두가지 상반되는 목적에 대해 최적화 되어야 하는 입장이 되는거죠.
- Guiding the self-attention between patches
- Summarizing the information useful to the linear classifier.
이 두가지 목적을 explicitly하게 분리시키는 것이 해당 연구의 목적이 됩니다.
(left)는 전형적인 ViT 아키텍쳐. class embedding이 패치 엠베딩과 함께 입력으로 들어간다.
(middle) class token을 중간에 넣었을 때 성능향상이 이뤄진다는 점에서, left와 같은 구조가 문제를 갖는다는 사실을 증명함
(right) 해당 연구에서 제안된 CaiT 아키텍쳐. 마지막 두개의 레이어가 FFN에 입력으로 들어가는 vector를 잘 summarizing 되도록 한다. 이를 class attention이라 명명.
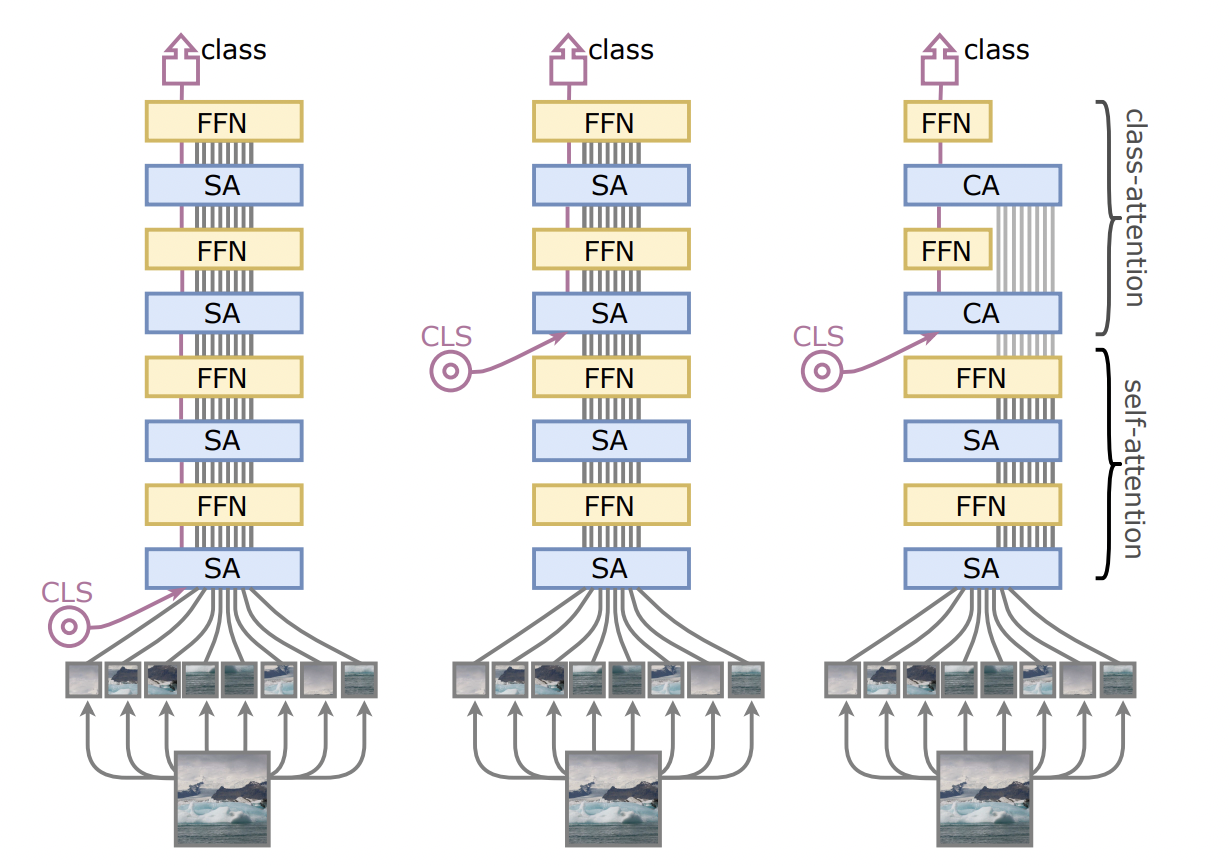
Later class token
class token을 트랜스포머의 후반부에 삽입함으로써, 트랜스포머의 첫번째 레이어에서 발생했던 불일치 (discrepancy)를 제거할 수 있었습니다. 이를 통해 패치들 간의 self-attention만을 안정적으로 수행하도록 합니다.
아키텍쳐를 정리해보자면,
- self-attention layer는 기존의 ViT와 동일하나, class embedding이 없다.
- class attention stage는 patch embedding을 class embedding으로 컴파일하도록 하여, 결과적으로는 linear classifier의 입력으로 들어갈 수 있도록 하는 set of layers. 해당 스테이지에서는 class embedding만 업데이트 된다.
Only the class embedding is updated by residual in the CA and FFN processing of the summarize stage.
Multi-heads class attention
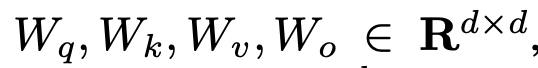
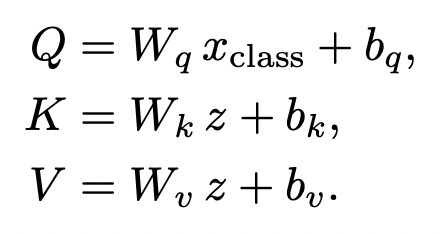
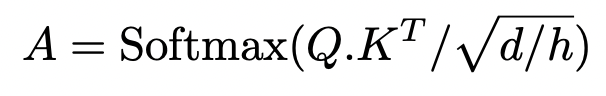
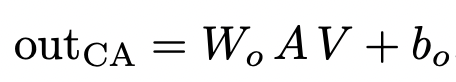
This attention is involved in the weighted sum A × V to produce the residual output vector which is in turn added to xclass for subsequent processing.
즉, CA layer는 patch embedding으로부터 의미있는 feature를 추출하여, class embedding으로 전달하는 과정인 것.
실험 과정에서, first CA & FFN의 도입으로부터 유의미한 정확도 향상을 확인하였고, 2개의 블럭 (2CA, 2FFN)으로 performance를 향상시키는데 충분하다는 것을 실험적으로 확인했습니다.
실험에 사용된 아키텍쳐는 12 blocks of SA+FFN layers & 2blocks of CA+FFN layer로 구성됩니다.
4. Experiments
4.1. Preliminary analysis with deeper architectures
Table 1. Improving convergence at depth on ImageNet-1k
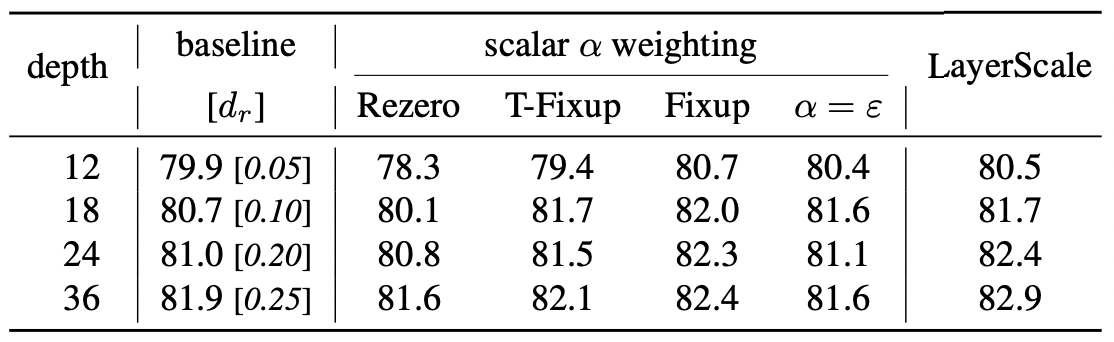
베이스라인 모델은 DeiT-S. depth에 따른 정확도 차이를 확인할 수 있는데, LayerScale이 가장 결과가 좋네요.
4.2. Class Attention Layers
class embedding을 삽입하는 위치를 바꿔가면서 실험한 결과.
ViT와 DeiT에서는 layer0에서 projected pathes들과 함께 jointly하게 입력으로 들어가는 것을 확인할 수 있습니다.
Table 2. Variations on CLS with Deit-Small (no LayerScale)
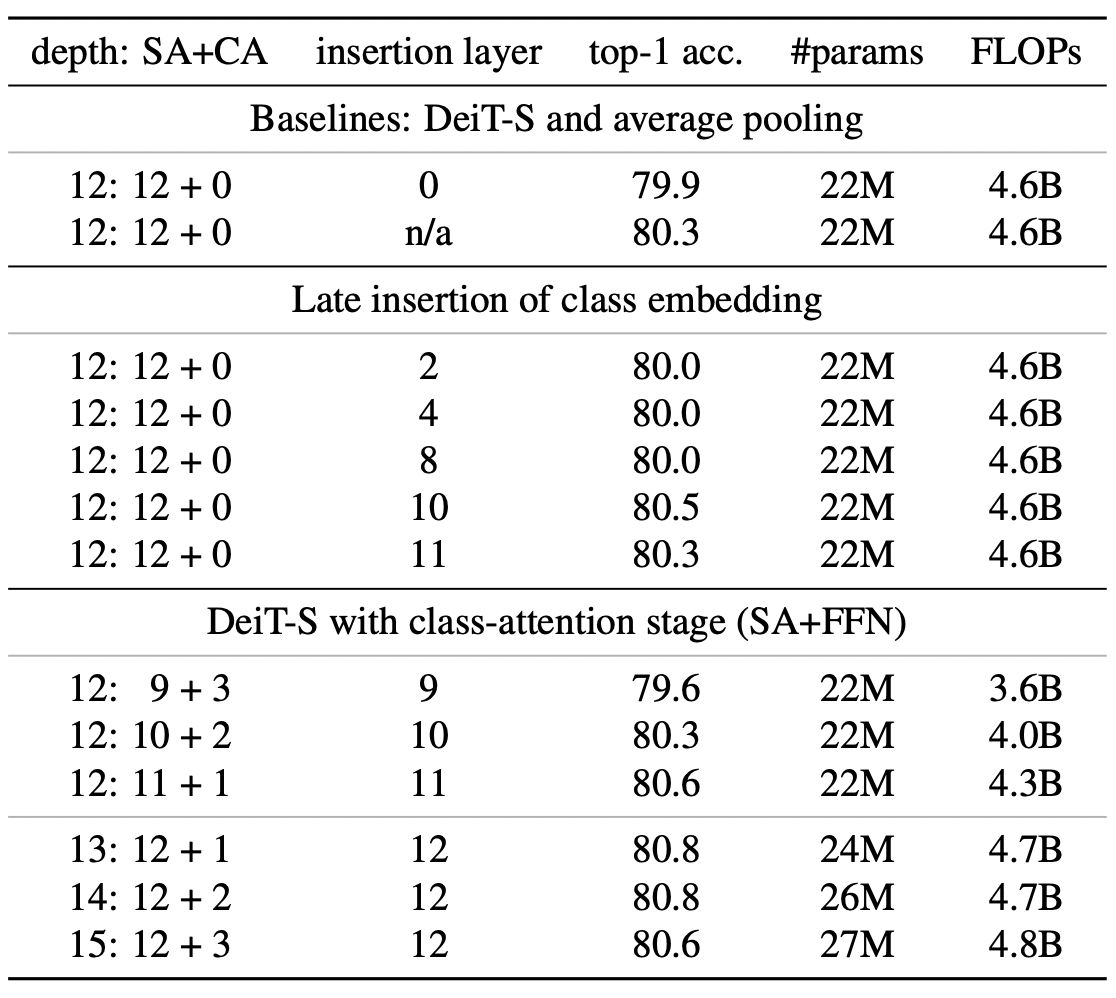
근데 솔직히... ㅎㅎ.... 정말 나아졌나요..? 해당 논문에서 말하길, 기존의 12개의 Self-attention 블록에다가 2개의 Class attention을 붙일 때, 성능 향상이 있다고 합니다. 79.9%에서 80.8%로의 성능 향상을 눈여겨 봐주시면 되겠습니다.
4.3. Our CaiT models

4.4. Results
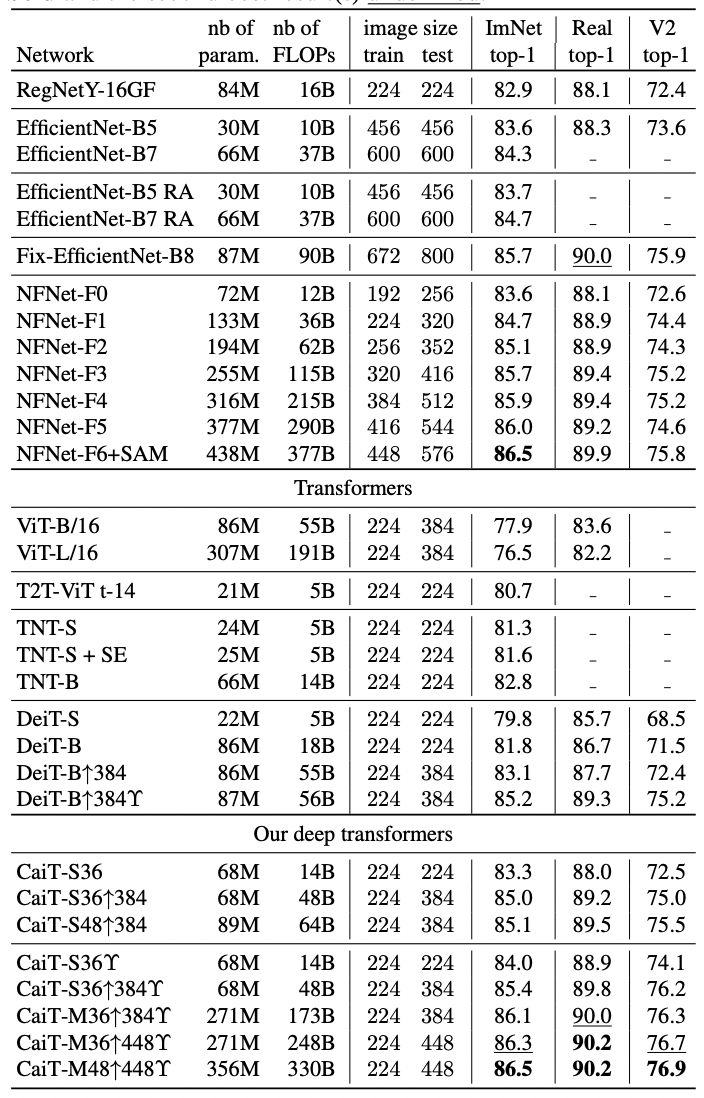
6. Conclusion
- show how train deeper transformer-based image classfication neural networks when training on Imagenet only.
- Introduced the simple yet effective CaiT architecture designed in the spirit of encoder/decoder architectures.
- Demonstrates that transformer models offer a competitive alternative to the best convolutional neural networks when consdiering trade-offs between accuracy and complexity.
