Visformer
Accepted: ICCV
Date: 2021
Last edited time: March 16, 2022 6:15 AM
Tags: Computer Vision, transformer
url: click
0. ABSTRACT
비전 트랜스포머의 경우, 학습 데이터가 제한적일 때 오버피팅 되는 문제점이 있었죠. 이를 해결하기 위해, 해당 논문은 Transformer-based model을 Convolution-based model로 점진적으로 바꾸어가며, 실험적으로 연구한 결과를 보여줍니다. 점진적으로 바꾸어가는 과정에서, 비전 태스크에 최적화된 모델을 발견해낼 수 있었는데, 이를 Vision-friendly model로 Visformer라고 명명하게 됩니다.
계산 복잡도는 이전과 유사하게 유지하면서, Visformer는 transformer-based model과 convolution based model의, ImageNet classificatinon 정확도보다 높은 정확도를 보이며, 그 성능을 상회하는 결과를 보여주는데요. 이러한 장점은 학습 데이터셋이 작을수록 더욱 빛을 발한다고 합니다.
1. Introduction
이미지 분야에서의 중심점은 단연 convolution 이었으나, 최근 자연어 처리 분야에서 사용되던 transformer가 비전에 도입되면서 이러한 상황이 바뀌기 시작하였습니다. 입지적인 모델은 ‘ViT’로써, 이미지를 패치로 나누어 이를 마치 visual word로써 다루는 원리인데요. 크기가 작은 데이터셋 바탕으로 학습할 때 오버피팅 되는 문제가 계속해서 제기되어 왔습니다. 후속 연구들이 계속 되어오면서 어느정도 해결되는 문제들도 있었으나, 제한된 학습 데이터셋과 적당한 (moderate)한 augmentation을 거친 데이터들로는 여전히 convolutional based model보다 좋지 않은 성과를 보여왔습니다.
반면에 아주 대량의 데이터셋 기반으로는 Transformer based model이 월등하게 좋은 성능을 냅니다. 즉, Transformer는 더 높은 “upper-bound”를 가지고 있고, Convolution based model은 더 나은 “lower-bound”를 가지고 있다고 할 수 있겠죠. 쉽게 말해, Convolutional based model은 공부를 별로 안해도 성적이 어지간히 나오지만, 공부를 아주 많이해도 최상위권에 쉬이 도달하지 못하는 학생이라면, transformer based model은 공부를 적당히 하면 성적이 처참하지만, 아주 많이 공부할 때 최상위권에 오를 수 있는 학생인 것이죠.
해당 논문이 실험적으로 가설을 검증하는 논문인만큼, 실험 세팅에 대한 언급부터 나오는데요. training schedule의 길이와 augmentation의 종류에 따라, base performance/elite performance로 구분하여 실험을 진행합니다.
-
base performance의 경우)
the training schedule is shorter and the data augmentation only contains basic
operators such as random-size cropping [32] and flipping.
-
elite performance의 경우)
the training schedule is longer and the data augmentation is stronger (e.g., RandAugment [11], CutMix [41], etc., have been added)
Convolutional based model ; ResNet-50
Transformer based model ; DeiT-S
Convolutional based model은 base setting, elite setting간의 성능 차이가 1.3% 정도였다면, Transformer based model은 그 두 세팅간의 차이가 10% 내외로, 큰 차이를 보였습니다.
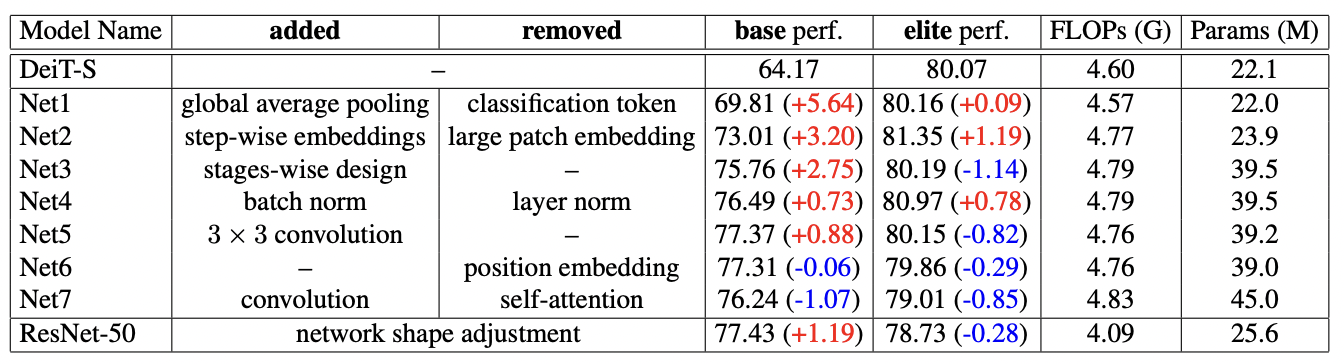
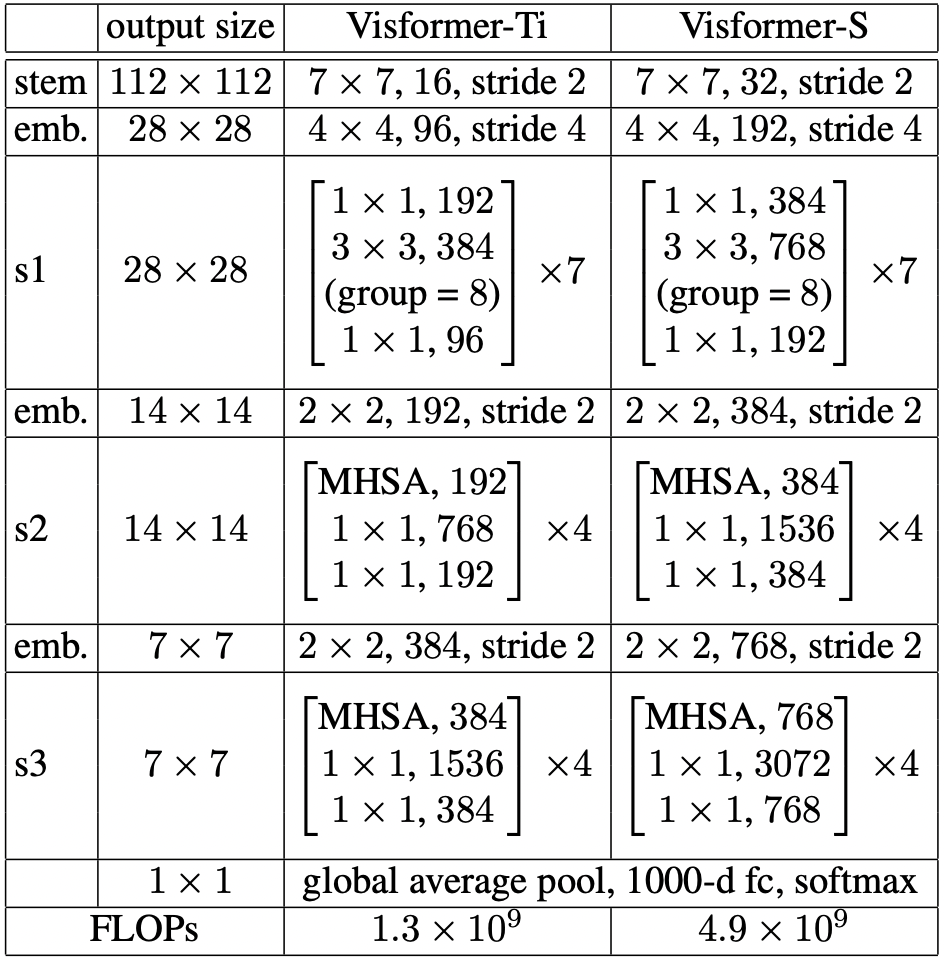
Transition은 다음의 총 8개의 단계로 진행됩니다. 각 성질 중 Vision task에 크게 도움이 되는 성질을 선별적으로 선택하여 Visformer를 구성합니다.
(i) use global average pooling (not the classification token)
(ii) introduce step-wise patch embeddings (not large patch flattening)
(iii) adopt the stage-wise backbone design
(iv) use batch normalization (not layer normalization)
(v) leverage 3 × 3 convolutions
(vi) discard the position embedding scheme
(vii) replace self-attention with convolution
(viii) adjust the network shape (e.g., depth, width, etc.).
위의 결과로 만들어 낸 Visformer는 elite setting에서는 DeiT-S, ResNet-50을 각각 2.12%, 3.46% 앞서는 성능을 보입니다. 또한, 10%의 라벨과 10%의 클래스만으로 구성된 데이터셋 바탕으로도, ResNet-50을 능가하는 성능을 보였습니다. 이로써 Visformer-S 또한 우수한 lower-bound를 가진다는 것이 확인된 것이죠.
2. Method
2.1. Transformer-based and convolution-based visual recognition models
“인지"는 컴퓨터 비전 분야에 있어서 주요한 태스크입니다. 이는 주로 이미지 분류 태스크로 여겨지는데요. 입력 이미지가 deep network를 지나 출력으로 해당 클래스 라벨이 도출되는 식입니다. 해당 태스크를 수행하기 위해 우리는 대표적으로 ‘convolution’과 ‘transformer’를 사용합니다.
‘convolution’은 로컬한 패턴이 글로벌 패턴보다는 반복된다는 특성을 지니고 있다는 점에서 이미지에 잘 적용됩니다. 학습 가능한 kernel들이 중요한 역할을 합니다.
반면에, ‘transformer’는 자연어 처리라는 기원을 가지고 있기에, sequence를 또 다른 sequence로 변환하는데 장점이 있습니다. 서로간의 관계를 파악한느데 능하다는 것이죠. 이를 위해 token으로 부터, key, query, value라는 세가지 feature들을 뽑아내 weighted sum한 값을 사용합니다. similarity를 계산하는데 query와 key간의 correspondence를 본다고 생각하시면 됩니다.
2.2. The transition from DeiT-S to ResNet-50
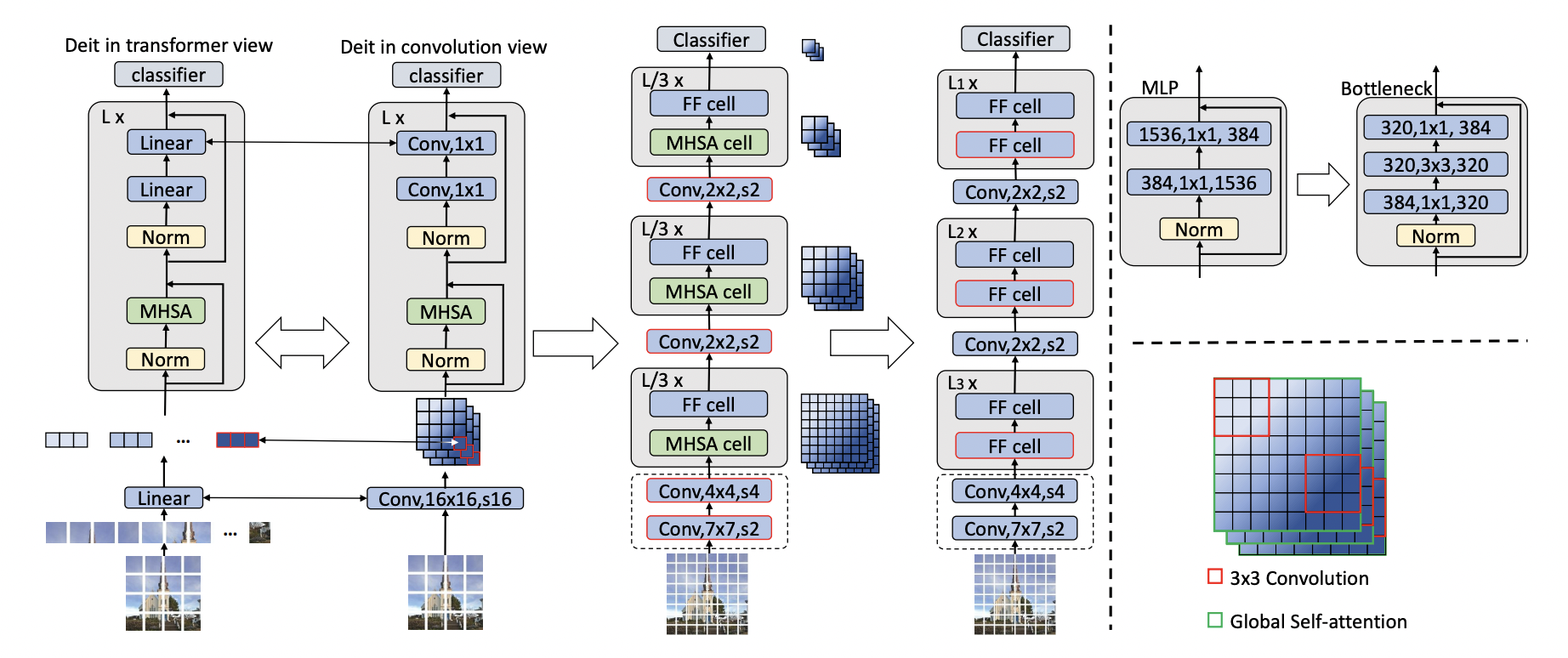
Figure1. 주요한 transition 위주로 정리해둔 피규어입니다. 시작은 DeiT-S이고, 끝은 ResNet-50이 됩니다. 첫번째 변환은 transformer를 convolution으로 바꾼 것이며, 두번째 변환은 patch flattening module을 step-wise patch embedding으로 바꾸어 주고 stage-wise design을 도입한 것입니다. 마지막 변환은 self-attention 모듈을 convolution 모듈로 바꾸어 준 것을 의미하구요.
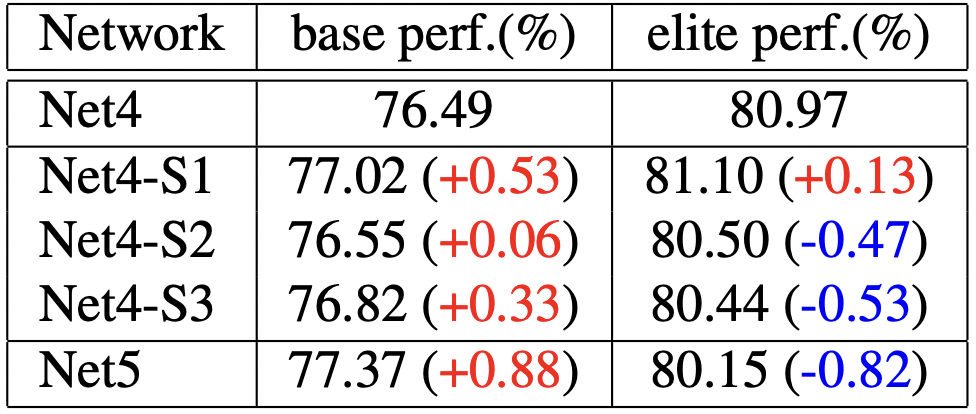
2.2.1. Using Global Average pooling to replace the classification token
첫번째 변환은 Transformer 기반 모델에서 classification token을 제거하고 global average pooling을 추가한 것입니다. NLP task에서 주로, transformer 모델은 입력에 classification token + MLP linear classfier 을 추가하여 받게 됩니다. 구체적으로 patch embedding이라 함은, path size(=s)의 kernel sized(=sxs)와 stride(=s)를 갖는 convolution 계산입니다. 일련의 토큰들은 channel dimension에서 벡터가 됩니다.
이러한 변환은 base setting에서는 큰 성능 향상을, elite setting에서는 비교적 적은 성능 향상을 보여줍니다.
2.2.2. Replacing patch flattening with step-wise patch embedding
DeiT와 ViT 모델은 이미지 픽셀들을 patch embedding layer를 통해 인코딩 되는데, 이는 16 사이즈의 kernel과 stride로 convolution 연산을 해주는 과정입니다. 이를 통해 image patch를 일련의 토큰들로 flatten해 줄 수 있고, 트랜스포머의 입력으로 넣을 수 있게 합니다.
해당 논문에서는 large patch embedding을 step-wise small patch embedding으로 바꾸어 줬고, ResNet의 stem layer를 Transformer에 더해 구현합니다. 7x7 convolution layer를 stride 2로 계산해주는 과정은 patch embedding으로 보자면, stride 2로 pixel overlapping을 허용하는, patch embedding 작업을 해준 것과 동일하게 진행되죠.
DeiT 모델의 patch size가 16이기 때문에, 여전히 8x8 patch embedding을 해줘야할 필요성이 있었고, 8 x 8 patch embedding을 4 x 4 embedding(4x4 convolution with stride 4) + 2 x 2 embedding(2x2 convolution with stride 2)으로 바꾸어 주었습니다.
step-wise embedding을 적용해줌으로써 patch들 간의 position들 또한 feature로써 인코딩할 수 있게 되었다. 이를 통해 패턴들을 더 잘 학습할 수 있게 되었고, 결과를 보자면, base setting과 elite setting 모두에서 양호한 성능 향상을 보여주네요.
2.2.3. Stage-wise design
네트워크를 ResNet과 같이, stage로 쪼개줍니다. 같은 블록에 들어있는 stage는 same resolution을 처리하게 되네요.
2.2.2.에서의 stage-wise 처리는 네트워크를 여러 스테이지들로 쪼개준 것이라고 한다면, 해당 세션에서는 블록을 여러 stage들로 재지정 해주는 과정이라 생각하면 됩니다.
224 x 224 인풋을 기준으로, 8x8(feature resolution: 28x28) 16x16(feature resolution: 14x14) 32x32(feature resolution: 7x7) patch embedding stage에 블록을 추가 해줍니다.
결과는 흥미로웠는데, base setting에서는 성능이 크게 향상했으나, elite setting에서는 성능이 눈에 띄게 하락하죠. 이는 self-attention이 매우 큰 해상도에서는 잘 작동하지 않는다는 점에서 기인하는데, 이는 그들간의 관계를 학습하기가 매우 복잡해지기 때문입니다.
2.2.4. Replacing LayerNorm with BatchNorm
트랜스포머 기반 모델들은 feature들을 LayerNorm을 활용하여 normalize해줍니다. 반면에, ResNet과 같은 convolution-based model은 학습 과정을 안정화시키기 위해 Batch Norm을 사용합니다. LayerNorm은 배치 사이즈와 독립적으로 작동하며, 좀 더 구체적인 태스크에 친숙한 반면, BatchNorm은 적절한 batch size가 들어올 때 성능향상을 보인다는 장점이 있죠. LayerNorm → BatchNorm으로 변환해주었고, elite setting과 base setting 모두에서 성능 향상을 보이네요.
2.2.5. Introducing 3x3 convolutions
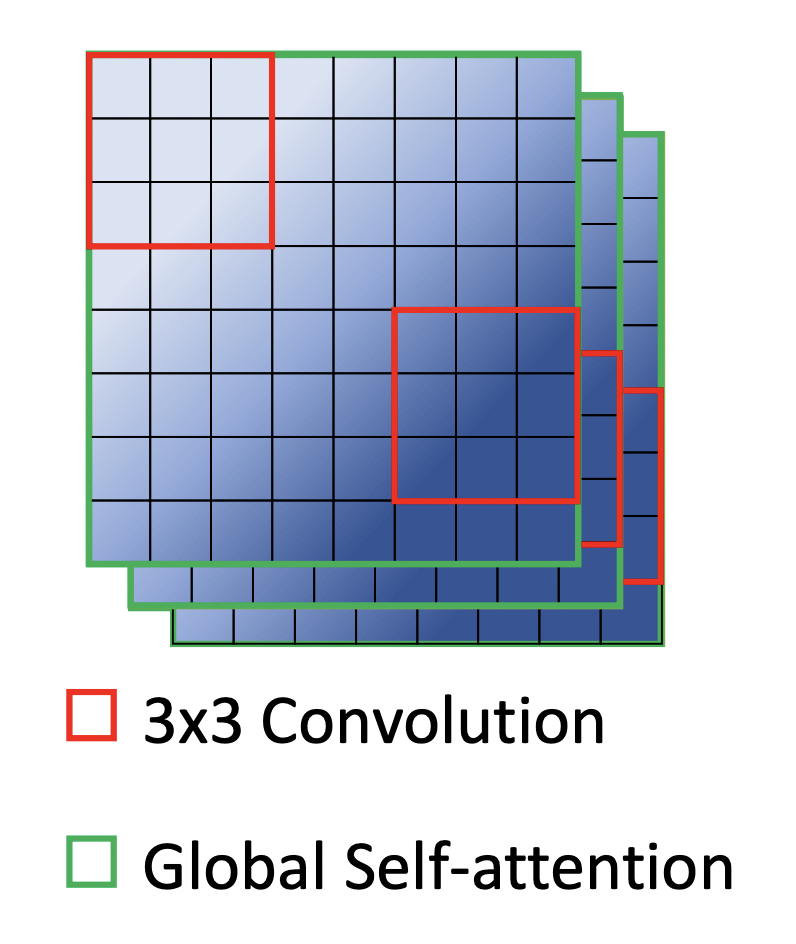 self attention이 모든 픽셀들 (all the tokens)간의 관계를 building하려고 한다면, convolution은 토큰들과 그들의 이웃한 토큰들 간의 관계를 building 해줍니다.
self attention이 모든 픽셀들 (all the tokens)간의 관계를 building하려고 한다면, convolution은 토큰들과 그들의 이웃한 토큰들 간의 관계를 building 해줍니다.
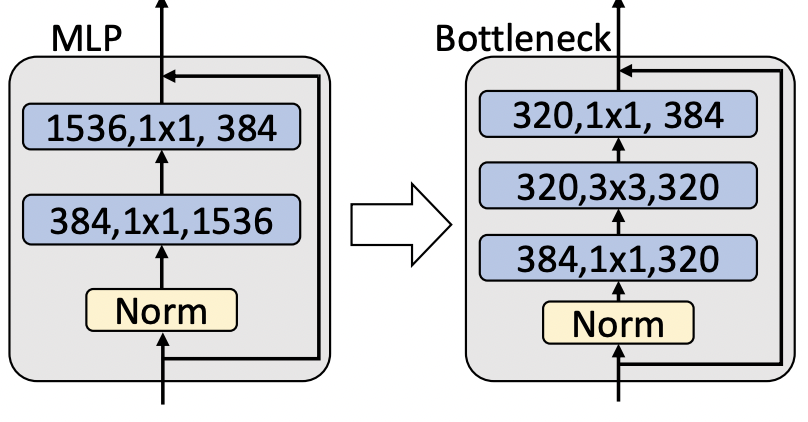 1x1 convolution들 사이에, 3x3 convolution들을 추가해 주었고, 이를 통해
1x1 convolution들 사이에, 3x3 convolution들을 추가해 주었고, 이를 통해 MLP Block을 BottleNet Block으로 변환해 주었습니다.
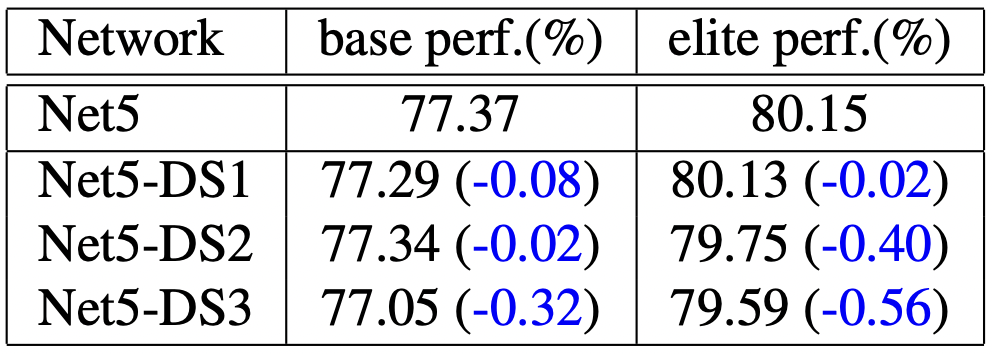
base setting 기준으로 local한 관계를 leverage하게 학습할 수 있게 되지만, elite setting 기준으로는 성능의 하락을 보이네요.
2.2.6. Removing position embedding
트랜스포머 기반 모델에서, position embedding은 position 정보를 토큰으로 인코딩하기 위해 사용됩니다. 해당 논문에서는 DeiT → ResNet으로 변환하는 과정이기 때문에 position embedding을 제거하여 실험을 진행했습니다. DeiT에서 바로 position embedding을 제거하면 3.95%라는 큰 성능 하락이 발생하지만, 위 5가지 변환 단계를 거친 모델에서 position embedding을 제거하면 0.29%라는 성능 하락을 보여줍니다.
즉, pure transformer 모델에서는 positonal embedding이 중요한 역할을 하지만, 해당 변환모델에서는 그 중요성이 축소된다는 점을 눈여겨 볼만 합니다.
2.2.7. Replacing self-attention with feed-forward
block 내부에 있는 self-attention 모듈을 convolution 모듈인 bottleneck block들로 대체하는 과정으로, 이 과정을 통해 convolution model이 됩니다.
base setting과 elite setting에서 이전 단계보다 더 낮은 성능을 보여주는데, 이는 self-attention이 elite setting에서 더 높은 성능을 가능케하는 파트이며, ViT와 DeiT의 성능을 낮추는 것에는 책임이 없다는 것을 의미합니다.
2.2.8. Adjusting the shape of network
현재 transition model이 ResNet과 depth, widths, bottleneck ratio등의 모델 구조가 다르기 때문에 이러한 부분을 바꾸어 주는 마지막 단계입니다. base setting에서는 성능 향상을 보였는데, 이는 transition model이 ResNet보다는 떨어지는 성능을 보인다는 것이죠. 그러나, elite setting에서는 ResNet보다 transition model의 성능이 더 잘 나왔습니다.
Replacing self-attention with bottleneck blocks.
Replacing MLP layers with bottleneck blocks
2.3. Summary
3. Experiments
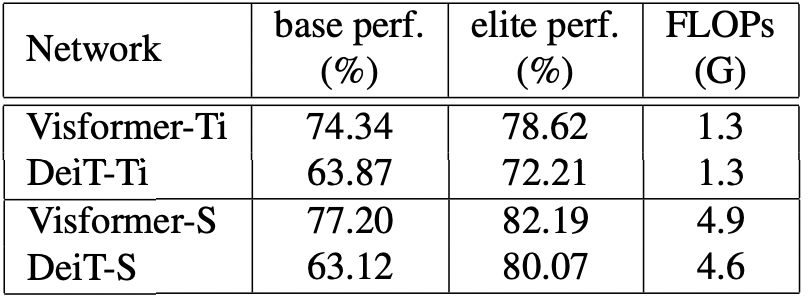
Table 6. The comparison of base and elite performance as well as
the FLOPs between Visformer and DeiT, the direct baseline.
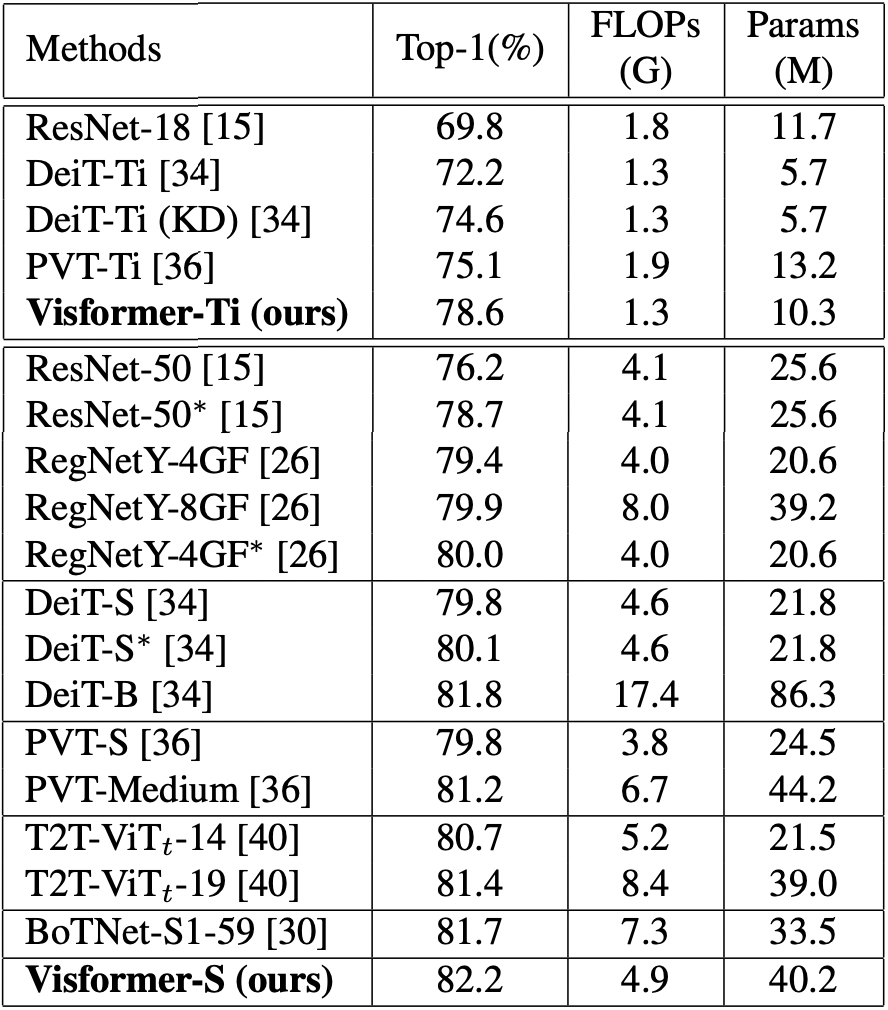
Table 7. Comparison among our method and other Transformerbased vision models. ‘*’ indicates that we re-run the model using
the elite setting. ‘KD’ stands for knowledge distillation
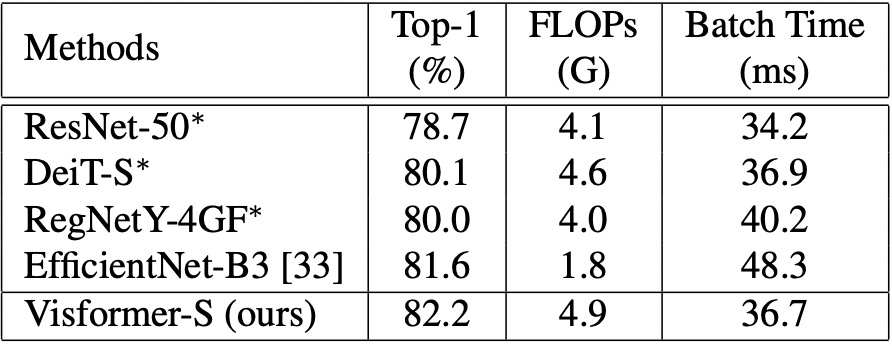
Table 8. Comparison of inference efficiency among Visformer-S and other models. A batch size of 32 is used for testing. Besides EfficientNet-B3, other models are trained using the elite setting.
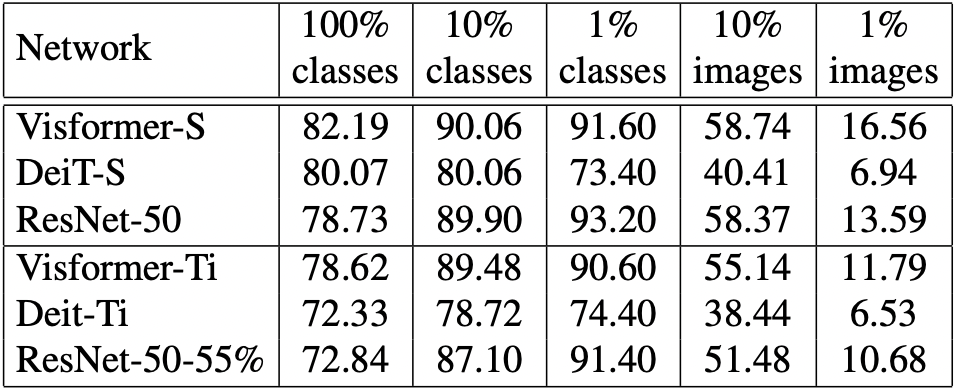
Table 9. Comparison among Visformer, DeiT, and ResNet, in terms of classification accuracy (%) using limited training data. The elite setting with 300 epochs is used for all models.
5. Conclusion
visual task에 좀 더 친숙한 transformer based model을 제안했다는 점이 해당 논문의 contribution입니다.
각 변환 step의 모델을 평가하기 위해, base setting, elite setting을 사용하였습니다.
transformer model과 convolution model이 왜 다른 성능을 보이며, 다른 기전을 보이는지 알아보기 위해 그 차이를 8가지 스텝으로 나누어 각각 transition을 진행하였고, 각각의 장점을 취하고 단점은 버린 최종 모델을 제작해낼 수 있었습니다.
Summary
First, for the first time, we introduce the lower-bound and upperbound to investigate the performance of Transformer-based vision models.
Second, we close the gap between the Transformer-based and convolution-based models by a gradual transition process and thus identify the properties of the designs in the Transformer-based and convolution-based models.
Third, we propose the Visformer as the final model that achieves satisfying lower-bound and upper-bound and enjoys good scalability at the same time.
