Convolutional Layer 클래스 및 작동방식
torch.nn.Conv2d
-
영상처리를 위한 Convolution Layer. 입력으로 (N, Channel, Height, Width) shape의 tensor를 받는다.
- N: batch size
-
Hyper parameter
- in_channels
- 입력 데이터의 channel size
- out_channels
- 출력 데이터의 channel size.
- Layer 를 구성하는 kernel의 개수로 Feature map의 depth, channel의 크기가 된다.
- kernel_size
- Filter의 크기(height, width)
- 보통 홀수 크기로 잡는다. (3 3, 5 5). 주로 3 * 3 필터를 사용한다.
- height, width가 동일할 경우 정수(int) 한개의 값만 설정한다.
- padding=0
- input tensor의 추가할 padding(여백)의 크기. default는 0으로 padding을 추가 하지 않는다.
- "same": input의 height와 width와 동일한 output이 나오도록 padding을 추가한다.
- "valid": padding을 사용하지 않는다.
- stride=1
- 연산시 Filter의 이동 size(아래 참조)
- in_channels
-
Feature Map
- Filter(Conv2d의 unit)를 거쳐 나온 결과물(output)
- Feature map의 개수는 Filter당 한개가 생성된다.
- Feature map의 크기(shape)는 Filter의 크기(shape), Stride, Padding 설정에 따라 달라진다.
Input shape
- (데이터개수, channel, height, width)
- Channel: 하나의 data를 구성하는 행렬의 개수
- 이미지: 색성분
- 흑백(Gray scale) 이미지는 하나의 행렬로 구성
- 컬러 이미지는 RGB의 각 이미지로 구성되어 3개의 행렬로 구성
- Feature map: 특성개수
- 이미지: 색성분
- Height: 세로 길이
- Width: 가로 길이
- Channel: 하나의 data를 구성하는 행렬의 개수
Padding
- 이미지 가장자리의 픽셀은 convolution 계산에 상대적으로 적게 반영
- 이미지 가장자리를 0으로 둘러싸서 가장자리 픽셀에 대한 반영 횟수를 늘림
- 0으로 둘러싸는 것을 ZeroPadding이라고 한다.
- Padding을 이용해 Feature map(output)의 size(height,width)의 크기를 조절할 수 있다.
- Conv2d의 padding 속성은 다음 세가지 타입으로 설정한다.
- tuple
- (height, width): 각 int 값을 지정하며 height차원과 width 차원의 padding 개수를 각각 지정한다.
- int
- height와 width가 동일할 경우 int값으로 지정한다.
- str
- "valid"
- Padding을 적용하지 않음
- "same"
- Input과 output의 크기가 동일하게 되도록 padding 수를 결정 한다.
- 보통 same 패딩을 사용한다.
- Output의 크기는 Pooling Layer를 이용해 줄인다.
- "valid"
- tuple
Strides
- Filter(Kernel)가 한번 Convolution 연산을 수행한 후 옆 혹은 아래로 얼마나 이동할 것인가를 설정.
- 값으로는 다음 두가지 타입을 지정할 수 있다.
- tuple: (height방향 이동크기, width 방향 이동크기)
- int: height, width 방향 이동크기가 같은 경우 정수값 하나로 설정한다.
- 예) stride=2: 한 번에 두 칸씩 이동)
- convolution layer에서는 일반적으로 1을 지정한다.
Max Pooling Layer
- Pooling Layer
- Feature map의 특정 영역의 값들 중 그 영역을 대표할 수 있는 한개의 값을 추출하여 output을 만든다.
- Feature map의 size를 줄이는 역할을 한다.
- 대표적인 pooling layer로 Max Pooling과 Average Pooling이 있다.
torch.nn.MaxPool2d
- 해당 영역의 input 중 가장 큰 값을 출력
- 영역의 size와 stride를 동일하게 주어 값을 추출하는 영역이 안겹치도록 한다.
- 일반적으로 2*2 크기에 stride는 2를 사용한다.
- 이렇게 하면 shape을 각각 절반 크기로 줄인다.
- 강제적인 downsampling 효과
- Input의 size를 줄여 계산속도를 높임
- 특징의 공간적 계층구조를 학습한다. => 부분적 특징을 묶어 전체적인 특징의 정보를 표현하게 된다.
- 학습할 weight가 없음: 일반적으로 convolutional layer 와 pooling layer를 묶어서 하나의 block으로 처리한다.
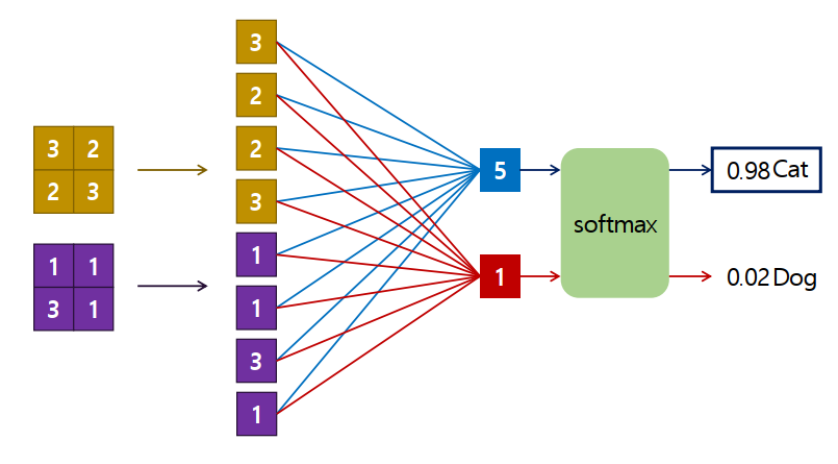
추론기
- 해결하려는 문제에 맞춰 Layer를 추가한다.
- Feature Extraction layer을 통과해서 나온 Feature map을 입력으로 받아 추론한 최종결과를 출력한다.
- Dense layer를 많이 사용했으나 지금은 Convolution layer를 사용하기도 한다.
- Feature Extractor와 추론 layer를 모두 Convolution Layer로 구성한 Network를 Fully Convolution Network(FCN)이라고 한다.
Example of CNN architecture
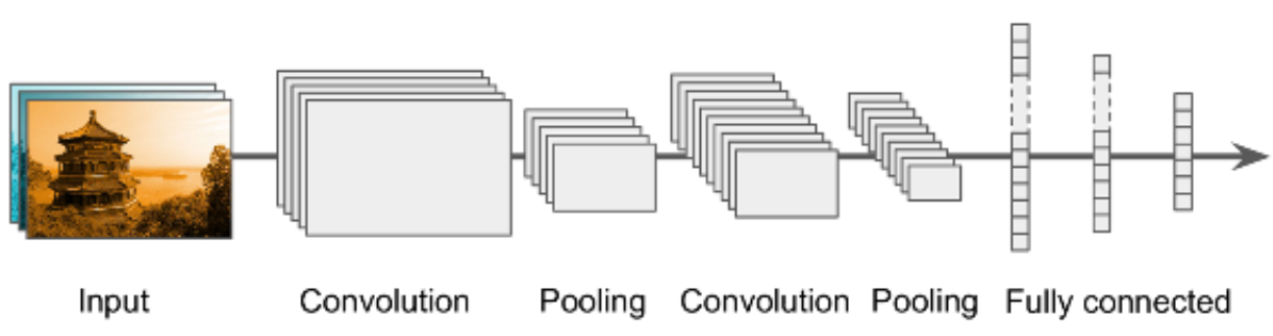
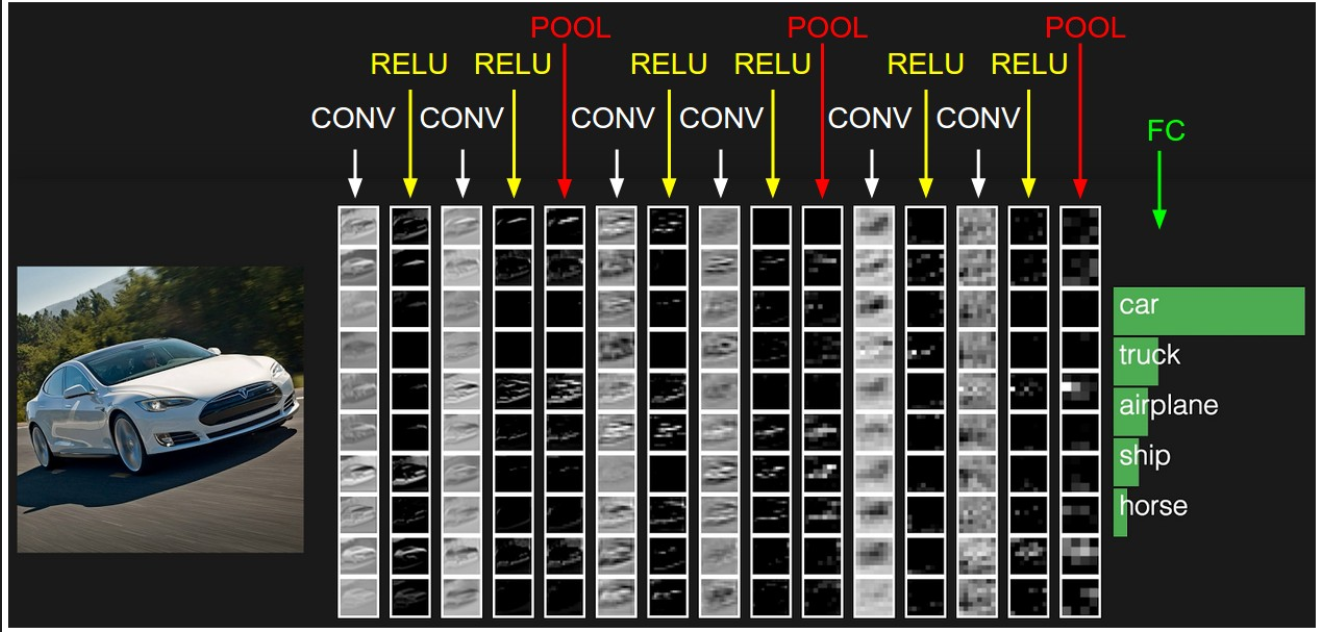
- 일반적으로 convolutional layer + pooling layer 구조 묶어서 여러 개 쌓는다(연결한다).
- 동일한 레이어들의 구조를 반복해서 쌓을 때 그 구조를 Layer block이라고 한다.
- convolution과 pooling layer를 묶어서 반복한 것을 convolution block이라고 한다.
- Bottom단의 Convolution block에서 Top 단의 convolution block으로 진행 될 수록 feature map의 size(height, width)는 작아지고 channel(depth)는 증가한다.
- Top 단으로 갈수록 동일한 size의 fliter로 입력 이미지 기준으로 더 넓은 영역 특성을 찾도록 모델을 구성하기 위해 size를 줄인다.
- Top 단으로 갈수록 더 큰 영역에서 특성을 찾게 되므로 Filter의 개수를 늘려 더 많은 특성을 찾도록 한다.
- 마지막에 Fully connected layer를 이용해 추론한다.
Convolutional Neural Network 모델 정의
MNIST
import os import torch from torch import nn from torchinfo import summary import matplotlib.pyplot as plt import numpy as np from module.data import load_mnist_dataset, load_fashion_mnist_dataset from module.train import fit from module.utils import plot_fit_result device = "cuda" if torch.cuda.is_available() else "cpu"### 하이퍼파라미터 선언 epochs = 1 batch_size = 256 lr = 0.001Data 준비
## Dataset->DataLoader data_path = r"C:\Classes\deeplearning\datasets" train_loader = load_mnist_dataset(data_path, batch_size) test_loader = load_mnist_dataset(data_path, batch_size, False)CNN 모델 정의
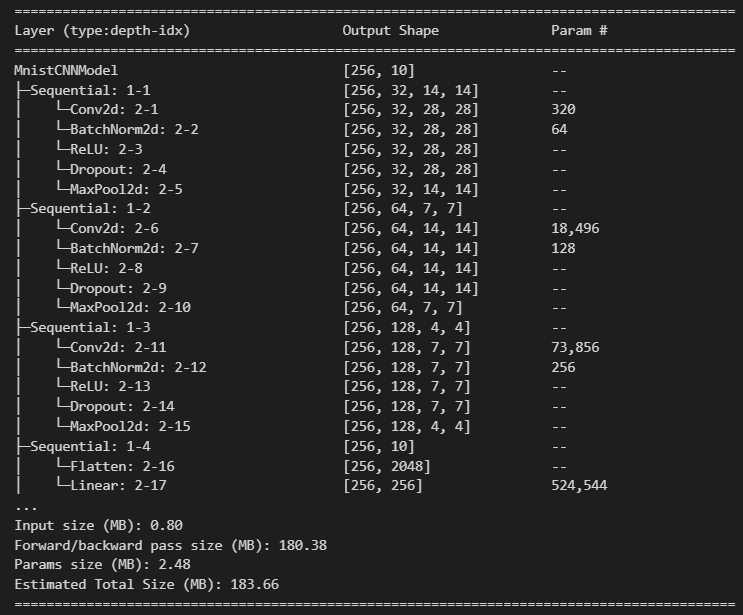
# Conv (layer) block # 1. Conv + ReLU + MaxPooling, (Conv + ReLU + Conv + ReLU +MaxPooling) # 2. Conv + BatchNorm + ReLU + MaxPooling (BatchNorm 은 Conv, Activation 사이에 정의) # 3. Conv + ReLU + Dropout + MaxPooling (Dropout activiation 다음에 정의) # 4. Conv + BatchNorm + ReLU + Dropout + MaxPooling # # CNN: filter(channel-depth) 개수는 늘리고 size(height, width)는 줄여나가도록 모델 네트워크를 구성. #### depth 늘리는 것: Convolution Layer, size 를 줄이것: Max Pooling import torch.nn as nnclass MnistCNNModel(nn.Module):def __init__(self, dropout_rate): super().__init__() # conv block 단위 생성. # Conv: kernel size- 3 x 3, stride=1(default), padding=same, MaxPooling: kernel size-2, stride=1 self.b1 = nn.Sequential( nn.Conv2d(1, 32, kernel_size=3, stride=1, padding="same"), nn.BatchNorm2d(32), # 입력 channel 수 nn.ReLU(), nn.Dropout(p=dropout_rate), nn.MaxPool2d(kernel_size=2, stride=2) ) self.b2 = nn.Sequential( nn.Conv2d(32, 64, kernel_size=3, padding="same"), # stride기본값: 1 nn.BatchNorm2d(64), nn.ReLU(), nn.Dropout(p=dropout_rate), nn.MaxPool2d(kernel_size=2, stride=2) ) self.b3 = nn.Sequential( nn.Conv2d(64, 128, kernel_size=3, padding="same"), nn.BatchNorm2d(128), nn.ReLU(), nn.Dropout(p=dropout_rate), nn.MaxPool2d(kernel_size=2, stride=2, padding=1) # input: 7 X 7 -> padding 1 ( 8 X 8) ) # # 추론기 -> Linear() self.classifier = nn.Sequential( ## conv output: 3차원, linear input: 1차원 nn.Flatten(), nn.Linear(in_features=128*4*4, out_features=256), nn.ReLU(), nn.Dropout(p=dropout_rate), nn.Linear(256, 10) # out_features=10: 정답 class 수. (0 ~ 9) )def forward(self, X): out = self.b1(X) out = self.b2(out) out = self.b3(out) out = self.classifier(out) return outcnn_mnist_model = MnistCNNModel(0.5) summary(cnn_mnist_model, (batch_size, 1, 28, 28))
Train
# 모델 생성 model = MnistCNNModel(0.3).to(device) # loss 함수 loss_fn = nn.CrossEntropyLoss() # 다중 분류 # optimizer optimizer = torch.optim.Adam(model.parameters(), lr=lr)# fit() os.makedirs('saved_models', exist_ok=True) save_path = "saved_models/mnist_cnn_model.pth" result = fit(train_loader, test_loader, model, loss_fn, optimizer, epochs, save_model_path=save_path, device=device, mode="multi")Epoch[1/10] - Train loss: 0.12209 Train Accucracy: 0.98235 || Validation Loss: 0.11540 Validation Accuracy: 0.98410
<<<<<<<저장: 1 - 이전 : inf, 현재: 0.11539805261418223
Epoch[2/10] - Train loss: 0.09952 Train Accucracy: 0.98130 || Validation Loss: 0.09316 Validation Accuracy: 0.98340
<<<<<<<저장: 2 - 이전 : 0.11539805261418223, 현재: 0.093156498670578
Epoch[3/10] - Train loss: 0.11717 Train Accucracy: 0.97543 || Validation Loss: 0.11376 Validation Accuracy: 0.97600
Epoch[4/10] - Train loss: 0.06415 Train Accucracy: 0.98817 || Validation Loss: 0.06278 Validation Accuracy: 0.98810
<<<<<<<저장: 4 - 이전 : 0.093156498670578, 현재: 0.0627757616341114
Epoch[5/10] - Train loss: 0.10670 Train Accucracy: 0.97413 || Validation Loss: 0.10420 Validation Accuracy: 0.97380
Epoch[6/10] - Train loss: 0.07991 Train Accucracy: 0.98752 || Validation Loss: 0.08260 Validation Accuracy: 0.98470
Epoch[7/10] - Train loss: 0.05045 Train Accucracy: 0.99042 || Validation Loss: 0.05138 Validation Accuracy: 0.99090
<<<<<<<저장: 7 - 이전 : 0.0627757616341114, 현재: 0.05137930030468851
Epoch[8/10] - Train loss: 0.04340 Train Accucracy: 0.99130 || Validation Loss: 0.04542 Validation Accuracy: 0.98980
<<<<<<<저장: 8 - 이전 : 0.05137930030468851, 현재: 0.04541729437187314
Epoch[9/10] - Train loss: 0.06679 Train Accucracy: 0.98468 || Validation Loss: 0.06880 Validation Accuracy: 0.98190
Epoch[10/10] - Train loss: 0.06055 Train Accucracy: 0.98662 || Validation Loss: 0.06228 Validation Accuracy: 0.98540
164.44112515449524 초plot_fit_result(*result)
colab에서 학습한 모델을 이용해서 검증 및 추론
import torch import torch.nn as nn from torchvision import transforms from module.data import load_mnist_dataset from module.train import test_multi_classification device = 'cuda' if torch.cuda.is_available() else 'cpu'# 모델 loading cnn_model = torch.load('saved_models/mnist_cnn_model.pth', map_location=torch.device('cpu')) # cuda 에서 학습 모델을 cpu에서 사용하도록 설정 cnn_model = cnn_model.to(device) cnn_modelMnistCNNModel(
(b1): Sequential(
(0): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1), padding=same)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.3, inplace=False)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(b2): Sequential(
(0): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=same)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.3, inplace=False)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(b3): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=same)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.3, inplace=False)
(4): MaxPool2d(kernel_size=2, stride=2, padding=1, dilation=1, ceil_mode=False)
)
(classifier): Sequential(
(0): Flatten(start_dim=1, end_dim=-1)
(1): Linear(in_features=2048, out_features=256, bias=True)
(2): ReLU()
(3): Dropout(p=0.3, inplace=False)
(4): Linear(in_features=256, out_features=10, bias=True)
)
)### test set loading 후 모델 평가 test_loader = load_mnist_dataset(r"C:\Classes\deeplearning\datasets", batch_size=256, is_train=False) loss, acc = test_multi_classification(test_loader, cnn_model, nn.CrossEntropyLoss(), "cpu") print(f"Loss: {loss}, Accuracy: {acc}")Loss: 0.13318236041814088, Accuracy: 0.9857