군집 (Clustering)
비지도 학습(unsupervised learning) 알고리즘으로 비슷한 특성을 가지는 데이터들끼리 그룹으로 묶는다.
적용 예
- 비슷한 데이터들 분류
- Feature를 바탕으로 비슷한 특징을 가진 데이터들을 묶어서 성향을 파악한다.
- 이상치 탐지
- 모든 군집에 묶이지 않는 데이터는 이상치일 가능성이 높다
- 준지도학습
- 레이블이 없는 데이터셋에 군집을 이용해 Label을 생성해 분류 지도학습을 할 수 있다. 또는 레이블을 좀더 세분화 할 수 있다.
k-means (K-평균)
- 가장 널리 사용되는 군집 알고리즘 중 하나.
- 데이터셋을 K개의 군집으로 나눈다. K는 하이퍼파라미터로 사용자가 지정한다.
- 군집의 중심이 될 것 같은 임의의 지점(Centroid)을 선택해 해당 중심에 가장 가까운 포인드들을 선택하는 기법.
알고리즘 이해
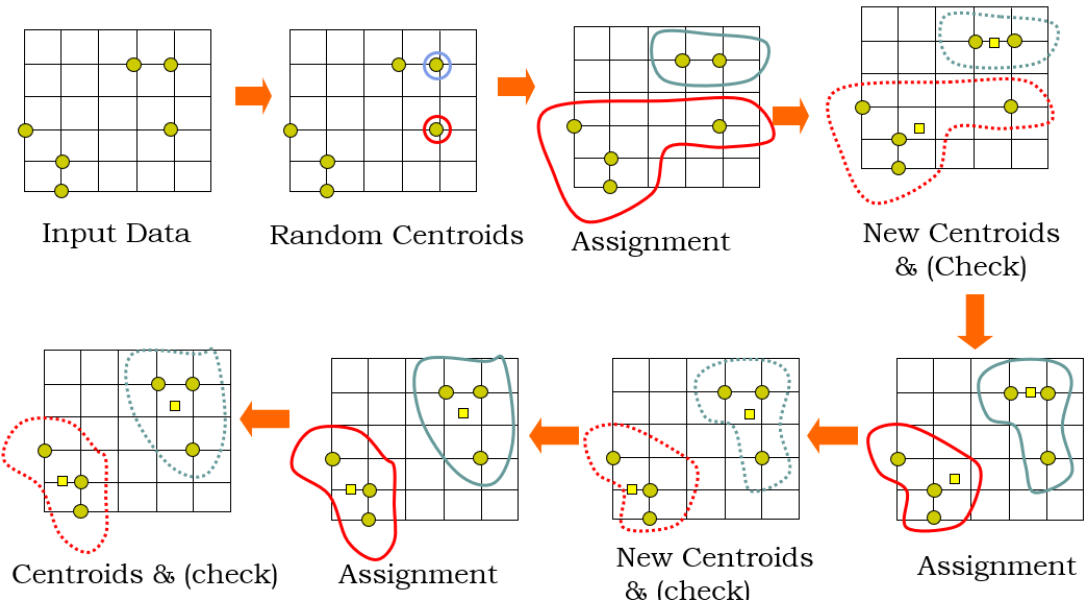
특징
- K-means은 군집을 원 모양으로 간주 한다.
- 모든 특성은 동일한 Scale을 가져야 한다.
- Feature Scaling 필요
- 이상치에 취약하다.
KMeans
- sklearn.cluster.KMeans
- 하이퍼파라미터
- n_clusters: 몇개의 category로 분류할 지 지정.
- 속성
- labels_ : 데이터포인트별 label
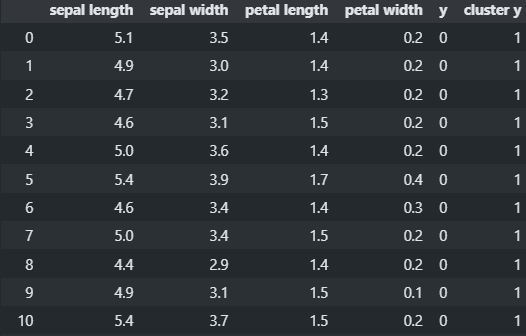
import numpy as np import pandas as pd from sklearn.datasets import load_iris columns = ['sepal length', 'sepal width', 'petal length', 'petal width'] X, y = load_iris(return_X_y=True)데이터전처리
- Feature scaling
from sklearn.preprocessing import StandardScaler X_scaled = StandardScaler().fit_transform(X)KMeans 생성 및 학습
from sklearn.cluster import KMeans kmeans = KMeans(n_clusters=3) # 몇개 군집(cluster)을 나눌지 kmeans.fit(X_scaled) # 어떻게 나눌지 학습 -> 그 결과(0, 1, 2)를 labels_ instance 변수에 저장.print(X.shape, kmeans.labels_.shape)(150, 4) (150,)
kmeans.labels_array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 2, 2, 2, 0, 0, 0, 2, 0, 2, 0, 0, 0, 0, 0, 0, 2,
0, 0, 0, 0, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0, 0, 0, 0, 0, 2, 2, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 2, 2, 2, 2, 2,
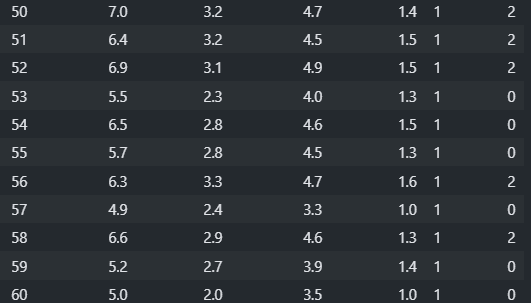
2, 0, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0])import pandas as pd df = pd.DataFrame(X, columns=columns) df['y'] = y df['cluster y'] = kmeans.labels_ pd.options.display.max_rows = 150 df
df['cluster y'].value_counts()cluster y
0 52
1 50
2 48
Name: count, dtype: int64
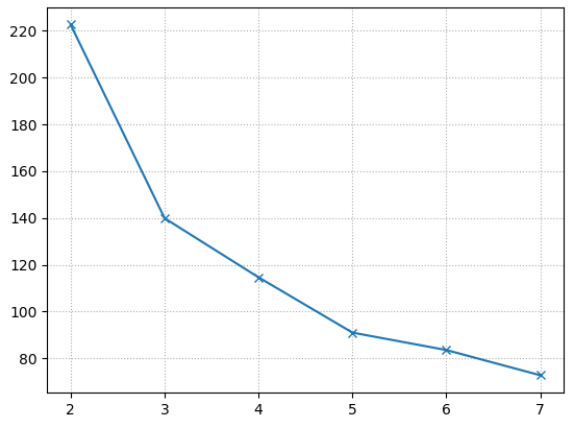
Inertia value(응집도) 를 이용한 적정 군집수 판단
- inertia
- 군집내 데이터들과 중심간의 거리들의 합으로 군집의 응집도를 나타내는 값이다.
- 값이 작을 수록 응집도가 높게 군집화가 잘되었다고 평가할 수 있다
- KMean의 inertia_ 속성으로 조회할 수 있다.
- 군집 단위 별로 inertia 값을 조회한 후 급격히 떨어지는 지점이 적정 군집수라 판단 할 수 있다.
- 그룹을 많이 나눌 수록 center 에서 떨어진 것은 다른 그룹으로 묶이게 되므로 응집도가 높아진다. (inertia value값 작아짐.)
- 그룹을 너무 많이 나누면 Inertia value 값이 작아지는 비율이 점점 낮아진다. 왜냐하면 center 중심에 가까이 있는 것들이 다시 나눠 지게 되어 거리의 합이 크게 바뀌지 않기 때문이다. 이런 경우 나눌 필요가 없는 것을 나누었다고 볼 수 있다.
- Inertia value가 크게 바뀌지 않는 지점을 찾아 k 값으로 지정하는 것이 좋다.
kmeans.inertia_139.82543466174204
k_list = [2, 3, 4, 5, 6, 7] inertia_list = [] for k in k_list: model = KMeans(n_clusters=k) model.fit(X_scaled) inertia_list.append(model.inertia_)inertia_list[222.36170496502308,
139.82049635974982,
114.62685984300724,
91.04736144274712,
83.60944069378978,
72.85195344974797]import matplotlib.pyplot as plt plt.plot(k_list, inertia_list, marker='x') plt.grid(True, linestyle=":") plt.show()
군집 평가지표
실루엣 점수
- 실루엣 계수 (silhouette coefficient)
- 개별 관측치가 해당 군집 내의 데이터와 얼마나 가깝고 가장 가까운 다른 군집과 얼마나 먼지를 나타내는 지표
- -1 ~ 1 사이의 값을 가진다. 1에 가까울 수록 좋은 지표이다.
-1에 가까우면 잘못된 그룹에 할당되어 있다는 의미0에 가까우면 군집의 경계에 위치한다는 의미1에 가까우면 자신이 속한 그룹의 센터에 가까이 있다는 의미
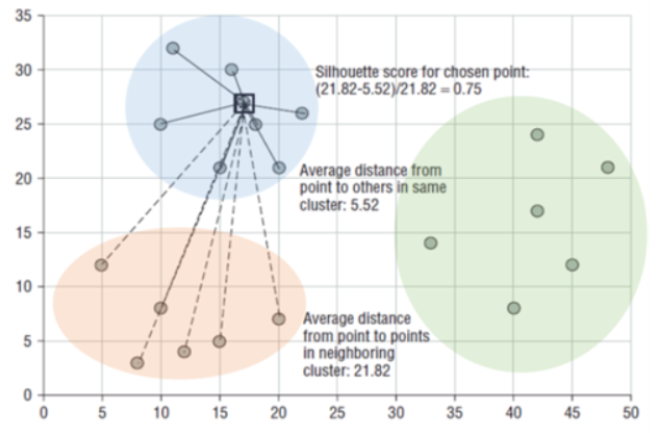
- 특정 데이터 포인트의 실루엣 계수 값은 해당 데이터 포인트와 같은 군집 내에 있는 다른 데이터 포인트와의 거리를 평균한 값 a(i), 해당 데이터 포인트가 속하지 않은 군집 중 가장 가까운 군집과의 평균 거리 b(i)를 기반으로 계산된다.
-
i: i번째 원소
-
s(i): i번째 원소의 실루엣 점수
-
a(i): 같은 군집의 다른 데이터포인터들과의 거리평균
-
b(i): 다른 군집의 데이터 포인터들과의 거리평균
-
분자: 두 군집 간의 거리 값은 b(i) - a(i)
-
분모: 이 값을(분자) 정규화 하기 위해 Max(a(i),b(i)) 값으로 나눈다
-
sklearn.metrics.silhouette_samples()
- 개별 관측치의 실루엣 계수 반환
-
sklearn.metrics.silhouette_score()
- 실루엣 계수들을의 평균
-
좋은 군집화의 지표
- 실루엣 계수 평균이 1에 가까울수록 좋다.
- 실루엣 계수 평균과 개별 군집의 실루엣 계수 평균의 편차가 크지 않아야 한다.
from sklearn.metrics import silhouette_samples, silhouette_score # (X, cluster) sil_values = silhouette_samples(X_scaled, kmeans.labels_) print(sil_values.shape) # 개별 데이터의 실루엣 점수 sil_values(150,)
array([ 0.73413466, 0.5672972 , 0.67694353, 0.61958032, 0.72841923,
0.61029029, 0.69793178, 0.73062959, 0.48652719, 0.63088432,
0.67444185, 0.7214888 , 0.57750797, 0.54819332, 0.5536699 ,
0.45823545, 0.62147934, 0.72867808, 0.58655898, 0.67757009,
0.66053176, 0.69025451, 0.69627256, 0.63699896, 0.70098812,
0.5439823 , 0.70446638, 0.72151127, 0.71444709, 0.66711803,
0.62482443, 0.64789763, 0.590005 , 0.54145847, 0.62772264,
0.67572703, 0.66565723, 0.7243247 , 0.55131495, 0.72457356,
0.73320416, 0.07341257, 0.63643245, 0.6634946 , 0.64876547,
0.55819708, 0.67893424, 0.66537768, 0.68930675, 0.71048601,
0.3538225 , 0.18133012, 0.37202823, 0.54551931, 0.10738259,
0.53666961, 0.24078206, 0.41538578, -0.03768897, 0.54614318,
0.42902252, 0.33330778, 0.46781223, 0.31852156, 0.49319503,
0.21007503, 0.39003983, 0.5460289 , 0.40148819, 0.58319498,
0.04156808, 0.44904007, 0.35928011, 0.41482825, 0.19414152,
0.08099709, 0.06886403, 0.35512819, 0.36537147, 0.5547234 ,
0.56797572, 0.55789417, 0.56632228, 0.38516592, 0.40445534,
0.11610396, 0.29667719, 0.41411172, 0.43737502, 0.58805806,
0.58520523, 0.22629008, 0.57875924, 0.4442093 , 0.58414313,
0.42579741, 0.49720185, 0.32326245, 0.43847367, 0.55109513,
0.42069063, 0.34336907, 0.52192663, 0.15979761, 0.43770527,
0.47182643, 0.47356974, 0.44644785, 0.02495796, 0.46385417,
0.44785817, -0.00122091, 0.50213827, 0.38142571, 0.0605206 ,
0.44332359, 0.35897802, 0.41025842, 0.33121205, 0.41555507,
0.5470904 , 0.31925292, 0.40192795, 0.16749233, 0.52413838,
0.51582792, 0.16422479, -0.01502214, 0.22509886, 0.44277193,
0.41575891, 0.39855184, 0.24381402, 0.17796304, 0.33869848,
0.46818051, 0.41926758, 0.36630838, 0.07832549, 0.53820947,
0.50563201, 0.51047867, 0.34336907, 0.53994149, 0.50077468,
0.4615969 , 0.22541011, 0.3851404 , 0.38475384, 0.0927865 ])sil_values.mean()0.45937792074496625
silhouette_score(X_scaled, kmeans.labels_)0.45937792074496625
df['silhouette_coef'] = sil_values # 클러스트(군집) 별 실루엣 점수 평균 df.groupby('cluster y')['silhouette_coef'].mean()cluster y
0 0.396324
1 0.635963
2 0.343743
Name: silhouette_coef, dtype: float64
