
프로젝트 진행 중 외부 서버의 API를 통해 상품 데이터를 받아 우리 데이터베이스에 저장해야 하는 상황이 있었는데, 이 과정에서 스프링 배치를 적용하기 전에 기존 코드의 성능을 먼저 개선해보고자 했었다.
해당코드는 아래와 같다.
private final RestTemplate restTemplate;
private final ProductRepository productRepository;
@Value("${api.product.url}")
private String apiUrl;
@Override
@Transactional
public void fetchAndSaveProductData() {
UriComponentsBuilder builder = UriComponentsBuilder.fromHttpUrl(apiUrl)
.queryParam("_start", 0)
.queryParam("_limit", 100);
ProductDataRequest[] productDataRequests = restTemplate.getForObject(
builder.toUriString(),
ProductDataRequest[].class
);
if (productDataRequests != null) {
for (ProductDataRequest request : productDataRequests) {
productRepository.save(request.toEntity());
}
}
}현재 보면 start부터 limit 만큼 데이터를 가져와 개수만큼 for문을 돌면서 한 개씩 save()를 하고 있다. 이 과정에서 매번 개별 INSERT 쿼리가 실행된다.
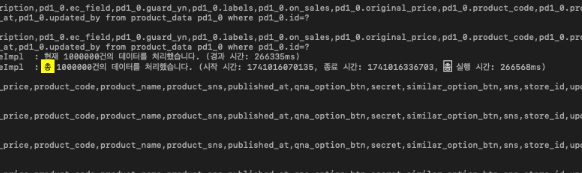
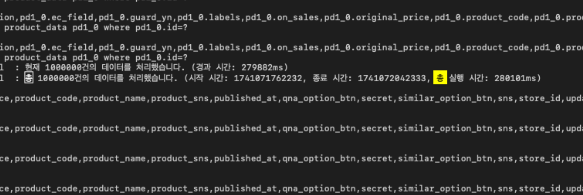
처음에는 save() 대신 saveAll()로 변경해보았지만 성능 차이는 거의 없었고, 이로 인해 두 방식의 차이점이 궁금해졌다.
save()와 saveAll()의 동작 비교
save()
@Transactional
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null");
if (this.entityInformation.isNew(entity)) {
this.entityManager.persist(entity);
return entity;
} else {
return (S)this.entityManager.merge(entity);
}
}우선 save를 보자
- this.entityInfomation.isNew(entity): 새 엔티티면 persist 메서드로 INSERT한다.
- 기존 엔티티면 merge 메서드로 UPDATE한다.
👉 (S)는 타입 캐스팅으로, merge 메서드의 반환 값을 원래 타입 S로 변환한다.
saveAll()
@Transactional
public <S extends T> List<S> saveAll(Iterable<S> entities) {
Assert.notNull(entities, "Entities must not be null");
List<S> result = new ArrayList();
for(S entity : entities) {
result.add(this.save(entity));
}
return result;
}
이번에는 saveAll에 대해서 알아보자
- Iterable< S > entities는 여러 엔티티의 컬렉션을 받는다. Iterable은 반복 가능한 객체를 나타내는 인터페이스이다.
- 새 빈 결과 리스트 result를 만든다.
- for문을 돌면서 "각각의 엔티티마다 save 메서드를 호출"한다.
- save된 엔티티를 result 리스트에 추가하고 마지막에 결과를 반환한다.
결론
결과적으로 saveAll()은 내부적으로 for문을 돌며 save()를 호출하기 때문에 둘다 똑같이 엔티티의 개수만큼의 INSERT 쿼리가 생성된다.
그 외적인 것들을 비교해보자면
트랜잭션 관점
- save()와 saveAll() 모두 @Transactional 어노테이션이 적용되어 있어, 각 메서드 호출은 하나의 트랜잭션으로 처리된다.
- save()를 여러 번 호출할 경우 각각 별도의 트랜잭션으로 처리될 수 있다.
- saveAll()은 모든 엔티티가 하나의 트랜잭션으로 관리되기 때문에 하나의 엔티티 저장이 실패하면 모든 엔티티 저장이 롤백된다.
- 현재 코드의 메서드 자체에도 @Transactional 애너테이션이 있기때문에 전체 커밋 수는 동일하게 한 번이다.
메모리 사용량 비교
- saveAll()은 모든 결과를 저장할 ArrayList를 생성하므로 대량의 데이터를 처리할 때 ArrayList크기에 따라 힙메모리 사용량이 증가할 수 있다.
앞서 본것처럼 save,saveAll 둘다 내부적으로 각 엔티티마다 개별 SQL 쿼리를 실행한다. 이는 대량의 데이터를 처리할 때 큰 오버헤드가 예상된다. 또한 각 SQL의 실행마다 데이터베이스 커넥션을 사용하기 때문에 커넥션 풀에도 부담을 준다. 따라서 JPA 배치 설정, JDBC batch update, native SQL 등의 대용량 배치처리를 하는것을 고려해 보는게 좋아 보인다. 또는 saveAll()를 더 최적화하기 위해서 데이터를 청크단위로 관리하고 flush이후 clear를 통해 영속성 컨텍스트(1차 캐시)에서 비워 GC가 회수할 가능성을 생기게 하는 방식으로 바꾸는걸 고려해볼 수 있을것 같다.
