이전 no offset으로 인기순 쿼리 개선에 이어서 경매 마감 순으로 정렬해보면서 index와 커버링인덱스 방식을 통해 쿼리를 개선해보자.
데이터는 3000만개가 존재한다.
index
먼저 간단하게 expire_at 순으로 정렬되기 때문에 expire_at에 index를 걸어보자.
인덱스 적용 전
select * from item order by expire_at asc limit 10 offset 10000;


type이 ALL이고 Extra가 Using filesort이기 때문에 데이터가 많아질 수록 성능에 직접적으로 영향을 줄 가능성이 높다.
인덱스 적용 후
create index idx__expire__at on item (expire_at);
JPA
JPA는 다음과 같이 설정하면 된다.@Entity @Table(indexes = @Index(name = "idx_item_expire_at", columnList = "expireAt")) @EntityListeners(value = ItemEntityListener.class) public class Item extends BaseEntity {
똑같은 쿼리로 차이점을 알아보자.
select * from item order by expire_at asc limit 10 offset 10000;


type이 index로 바뀌었고 idx__expire__at의 인덱스를 정상적으로 타는 것을 알 수 있다.
이제 실제 코드도 빨라졌는지 확인해보자.
Querydsl
public List<ItemsResponse> findItemsSortByExpireAt(int sortCode, String searchText, boolean isAll, Pageable pageable) {
return queryFactory
.select(
Projections.constructor(
ItemsResponse.class,
item.id,
item.title,
item.minimumPrice,
item.comments.size(),
item.bids.size(),
item.hearts.size(),
item.thumbnailImageFileName,
item.itemStatus,
item.expireAt
)
)
.from(item)
.where(
eqToSearchText(searchText),
eqNotDeleted(),
eqBidding(isAll)
)
.orderBy(orderBySortCode(sortCode))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}간단하게 테스트 코드를 돌려서 시간을 측정해보자.
@DisplayName("정렬기준 3")
@Test
void test016() {
List<ItemsResponse> items = itemCustomRepository.findItemsSortByExpireAt(
3,
"",
false,
PageRequest.of(10000, 10)
);
assertThat(items.size()).isEqualTo(10);
}
인덱스를 적용했음에도 13초나 걸렸다.
이 코드에는 두 가지 문제가 있다.
하나씩 문제점을 알아보고 해결해보자.
문제점 1 - ORDER BY 인덱스
첫 번째 문제의 이유는 기존 코드의 orderBySortCode() 메서드 때문이다.
private OrderSpecifier<?>[] orderBySortCode(int sortCode) {
List<OrderSpecifier<?>> orderSpecifiers = new ArrayList<>();
switch (sortCode) {
case 2 -> orderSpecifiers.add(item.bids.size().desc());
case 3 -> orderSpecifiers.add(item.expireAt.asc());
}
orderSpecifiers.add(item.id.desc());
return orderSpecifiers.toArray(new OrderSpecifier[0]);
}sortCode에 따라 정렬 후 기본 정렬 기준으로 id desc로 설정하였다.
ORDER BY는 다음 조건에서 인덱스를 타지 않는다.
인덱스 a, b, c
1.order by b, c→ 인덱스 첫번째 컬럼인 a가 빠짐
2.order by a, c→ 인덱스에 a, c 사이에 b가 빠짐
3.order by a, c, b→ 순서가 일치하지 않음
4.order by a, b desc, c→ b 혼자 desc
5.order by a, b, c, d→ 인덱스에 존재하지 않는 컬럼 d로 인해 사용 불가
5번 이유로 실제로 쿼리를 실행해보면 아래 이미지와 같이 인덱스를 타지 않는 것을 알 수 있다.

해결 1 - ORDER BY 인덱스
마감시간이 밀리초단위로 저장되기 때문에 겹칠 가능성이 매우 적다고 판단하여서 기 기본 정렬을 제거하였다.
//..orderBy(orderBySortCode(sortCode))
.orderBy(item.expireAt.asc()) 문제 2 - WHERE 인덱스
두 번째 문제로는 WHERE에서 인덱스를 타지 않는 것이다.
실제 조건을 걸어서 쿼리를 실행해보았다.

위 이미지처럼 key가 NULL인 것으로 보아 인덱스를 타지 못하였다.
해결 2 - WHERE 인덱스
WHERE 조건에 들어가는 컬럼을 expire_at과 묶어서 Composite index를 걸어주었다.
CREATE INDEX idx_item_expire_at ON item (expire_at, item_status, deleted);
JPA
@Entity @Table(indexes = @Index(name = "idx_item_expire_at", columnList = "expireAt, itemStatus, deleted")) @EntityListeners(value = ItemEntityListener.class) public class Item extends BaseEntity { ... }
다시 똑같은 쿼리를 실행해보자.

인덱스 적용 후 key를 보았을 때 정상적으로 인덱스를 타고있다.
그럼 다시 테스트 코드를 실행해보자.

13초 걸리던 작업이 0.9초로 많이 개선되었음을 알 수 있다.
커버링 인덱스
1만 페이지까지 조회할 가능성도 적고 인덱스만 걸어도 성능상 문제는 없지만 조금 더 성능을 개선해보자.
커버링 인덱스?
커버링 인덱스란 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스를 말한다.
SELECT, WHERE, ORDER BY, GROUP BY 등 사용되는 컬럼이 모두 index 컬럼에 포함되는 경우이다.
위에서처럼 CREATE INDEX idx_item_expire_at ON item (expire_at, item_status, deleted); 인덱스를 적용함으로써 커버링 인덱스를 사용할 준비는 끝났다.
커버링 인덱스가 빠른 이유
커버링 인덱스가 빠른 이유는 앞서 말한 것처럼 컬럼에 사용되는 데이터가 모두 인덱스에 포함되기 때문에 빠른 것이다.
일반적으로 SELECT * FROM ~ LIMIT ~ OFFSET의 쿼리는 데이터 블록에 접근하게 된다.
만약 1006 ~ 1008번 데이터 찾으려고하면 1008번까지 데이터블록에 접근하게 된다.

커버링 인덱스는 인덱스를 먼저 찾고 그 인덱스에 해당하는 데이터 블록에만 접근하여서 성능을 개선할 수 있다.

이 후 JPA의 설명을 위해 쿼리를 두 가지로 나누어서 작성하였으나 SQL로 한번에 처리가능하다.
(JPA는 join에 서브쿼리를 지원하지 않는다)SELECT * FROM item i JOIN ( SELECT id FROM item WHERE deleted=b'0' AND item_status='BIDDING' ORDER BY expire_at asc LIMIT 10 OFFSET 300000 ) AS tmp ON tmp.id = i.id;
적용
Querydsl로 적용하기 전에 데이터베이스 성능을 먼저 확인해보자.
커버링 인덱스 적용 전
극명한 차이를 보기위해 offset을 30만으로 설정하였다.
SELECT *
FROM item
WHERE deleted=b'0' AND item_status='BIDDING'
ORDER BY expire_at asc
LIMIT 10
OFFSET 300000;
커버링 인덱스 적용 후
SELECT *
FROM item i
JOIN (
SELECT id
FROM item
WHERE deleted=b'0' AND item_status='BIDDING'
ORDER BY expire_at asc
LIMIT 10
OFFSET 300000
) AS tmp ON tmp.id = i.id;

11초에서 0.073초로 엄청나게 빨라졌다.
Querydsl
위에 그림대로 쿼리를 두개로 나누어서 구현하였다.
먼저 커버링 인덱스로 id를 찾고 WHERE id IN (...)으로 id에 해당하는 데이터만 접근하였다.
public List<ItemsResponse> findItemsSortByExpireAt(String searchText, boolean isAll, Pageable pageable) {
List<Long> ids = queryFactory
.select(item.id)
.from(item)
.where(
eqToSearchText(searchText),
eqNotDeleted(),
eqAll(isAll)
)
.orderBy(
item.expireAt.asc(),
item.itemStatus.asc()
)
.limit(pageable.getPageSize())
.offset(pageable.getOffset())
.fetch();
if (CollectionUtils.isEmpty(ids)) return new ArrayList<>();
return queryFactory
.select(
Projections.constructor(
ItemsResponse.class,
item.id,
item.title,
item.minimumPrice,
item.comments.size(),
item.bids.size(),
item.hearts.size(),
item.thumbnailImageFileName,
item.itemStatus,
item.expireAt
)
)
.from(item)
.where(item.id.in(ids))
.fetch();
}Querydsl 테스트
쿼리처럼 테스트코드도 빠르게 처리되었다.

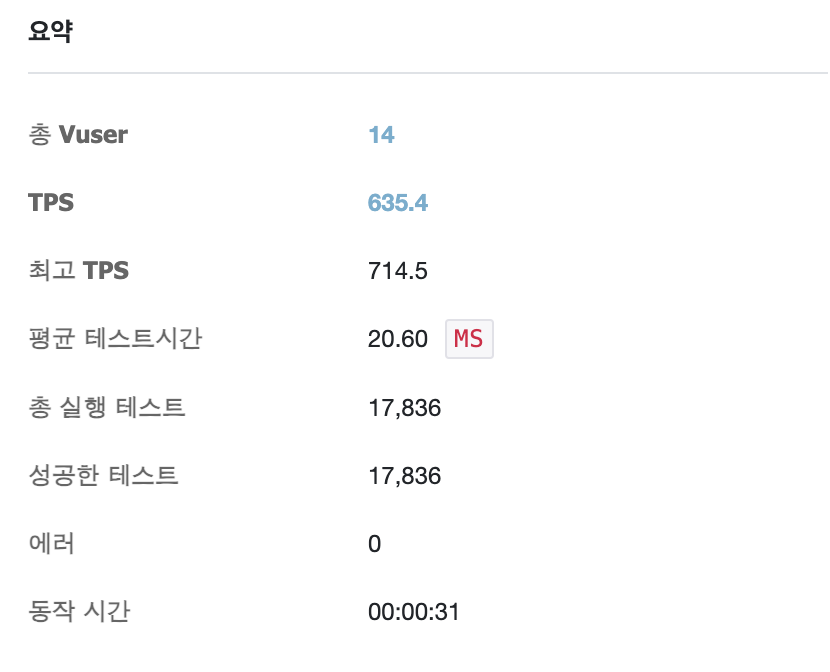
간단하게 ngrinder로 트래픽을 주었을 때도 TPS가 635정도로 빠른 성능을 보인다.
회고
처음에 단순히 커버링 인덱스를 적용하기 위해서 공부하였으나 인덱스에 대해서 자세히 공부할 수 있었다.
성능 개선을 공부하기 위해 다른 기술이나 패턴을 먼저 공부하려고 하였지만 역시 중요한 것은 인덱스를 적용하는 등 근본적인 성능을 먼저 개선하는 것이 중요한 것을 깨달았다.
데이터베이스 조회 성능은 no offset과 마찬가지로 데이터 블록 접근을 최대한 줄이고 인덱스를 최대한 활용하는 것이 중요한 점인듯 하다.
참고
https://jojoldu.tistory.com/529
https://jojoldu.tistory.com/243
