BidderOwn 프로젝트를 진행하며 홈화면의 상품 목록 api를 개발하게 되었다.
학습 차원에서 성능 테스트와 개선한 부분을 정리해보았다.
참고
이전 게시물인 경매 종료 처리 Spring batch에서 Redis로 리팩토링 하기 게시글과 이어지는 부분이 있다.
상황
상품 정보를 가져올 때 정렬 기준에 따라 다른 쿼리가 발생하기 때문에 Querydsl을 사용하여서 구현하게 되었다.
이때 아래와 같은 데이터가 필요하였다.
- 상품 기본 정보
- 좋아요 개수
- 댓글 개수
- 입찰자 수
입찰가 최고가격입찰자 최저가격
방법 1 - 기본
처음에는 JPA의 기본 기능을 사용하여서 데이터를 가져왔다.
// querydsl
public List<Item> findItems__v1(int sortCode, String searchText, boolean isBidding, Pageable pageable) {
return queryFactory.selectFrom(item)
.where(
eqToSearchText(searchText),
eqNotDeleted(),
eqBidding(isBidding)
)
.orderBy(orderBySortCode(sortCode))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}// DTO
... 생략
.commentsCount(item.getComments().size())
.bidCount(item.getBids().size())
.heartsCount(item.getHearts().size())page size가 9이고 상품 당 5 + 1의 쿼리가 발생하기 때문에 46개의 쿼리가 발생하게 된다.
이때 ngrinder로 간단하게 api 트래픽 테스트를 진행하였을 때 아래와 같은 결과가 나왔다.
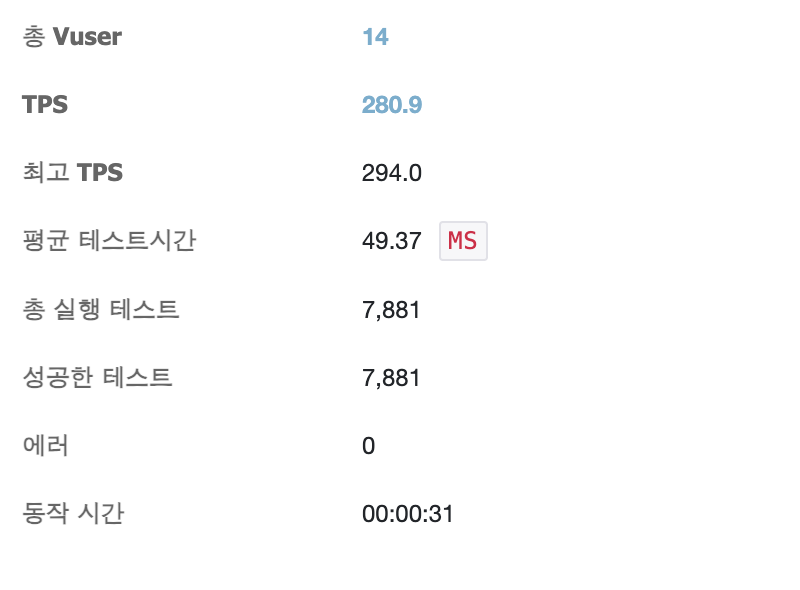
TPS가 280정도로 복잡한 쿼리가 아니기 때문에 준수한 수준이 나온다.
방법 2 - No offset
학습 차원에서 paging 성능을 개선할 방법을 찾던 중 jojoldu 님의 블로그를 보니 no offset이라는 방식이 있어서 적용해보았다.
No offset
간단히 페이징 방법은 페이지 값이 커질 수록 이전 페이지까지 전부 읽어들인 후에, 필요한 페이지를 읽게 되지만
no offset 방식을 적용하면 정렬되어있고 유니크한 id 값 기준으로 (id ~ id + page size) 만큼 가져오기 때문에 첫 번째 페이지와 이후 페이지가 같은 성능을 보일 수 있다.
자세한 내용은 이전 게시물인 No offset 적용기 및 서비스 개선에 있다.
public List<Item> findItems__v2(Long lastItemId, int sortCode, String searchText, boolean isAll, Pageable pageable) {
return queryFactory
.selectFrom(item)
.where(
ltItemId(lastItemId),
eqToSearchText(searchText),
eqNotDeleted(),
eqBidding(isAll)
)
.orderBy(orderBySortCode(sortCode))
.offset(pageable.getOffset()) // 정렬기준에 따라 paging 적용
.limit(pageable.getPageSize())
.fetch();
}private BooleanExpression ltItemId(Long itemId) {
if (itemId == null) {
return null;
}
return item.id.lt(itemId);
}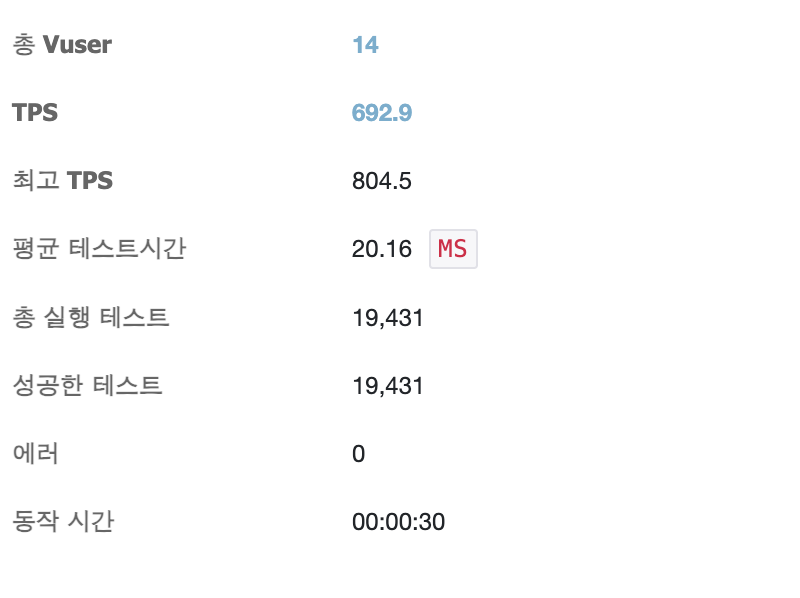
No offset 방식만 적용해도 TPS가 크게 상승하고 MMT도 절반 이상 줄어듬을 알 수 있다.
여기서 쿼리의 개수를 줄이거나 count 쿼리를 개선할 방법이 없을까?
방법 3 - 테이블에 개수 정보 추가?
매번 상품 데이터를 가져올 때마다 27개의 count 쿼리를 날리게 되고 이를 개선해보고 싶었다.
자주 쓰이는 데이터라고 판단하여서 Item 테이블에 저장해보았다.
@Getter
@MappedSuperclass
public abstract class ItemBase extends BaseEntity {
private int bidCount;
private int commentCount;
public void increaseBidCount() {
this.bidCount++;
}
public void decreaseBidCount() {
this.bidCount--;
}
public void increaseCommentCount() {
this.commentCount++;
}
public void decreaseCommentCount() {
this.commentCount--;
}
}문제는 개수 컬럼을 관계형 데이터베이스 저장할 경우 동시성 문제가 발생하기 때문에 정상적인 처리가 되지 않는다. 물론 동시성 문제를 해결하면 되지만 근본적으로 좋지 않은 구조라고 생각되었다.
그렇다면 count 쿼리를 줄이면서 성능 개선을 할 방법이 없을까?
이 문제를 멘토님에게 조언을 구하고 함께 고민한 결과 두 가지 결론이 도출되었다.
- redis에 count 정보를 저장하고 incr 명령어를 통해 개수 증가
- CQRS 패턴을 통해 count 정보 읽기와 쓰기 분리
방법 4.1 - CQRS
먼저 querydsl 최종 메서드이다.
public List<ItemsResponse> findItems(Long lastItemId, int sortCode, String searchText, boolean isBidding, Pageable pageable) {
return queryFactory
.select(
Projections.constructor(
ItemsResponse.class,
item.id,
item.title,
item.minimumPrice,
item.thumbnailImageFileName,
item.itemStatus,
item.expireAt
)
)
.from(item)
.where(
ltItemId(lastItemId),
eqToSearchText(searchText),
eqNotDeleted(),
eqBidding(isBidding)
)
.orderBy(orderBySortCode(sortCode))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}DTO로 받도록 변경만하였다.
처음엔 단순하게 count 정보를 읽어오는 데이터베이스는Redis로, 각각의 정보 삽입은 MariaDB로 분리만 하였다.
흐름은 다음과 같다.
- redis에 업데이트 시간 기록
- 댓글 엔티티 생성
- 5초마다 업데이트 시간 이후에 생성된 댓글, 입찰, 좋아요 데이터를 전부 읽어온다.
- redis에 있는 상품의 각 count 데이터 업데이트
@Component
public class ItemCountScheduler implements Scheduler {
...생략
private final CommentService commentService;
private final BidService bidService;
@Override
public void run() {
LocalDateTime updatedAt = itemRedisRepository.getBiddingItemUpdatedAt();
bidService.getBidsAfter(updatedAt)
...생략
commentService.getCommentsAfter(updatedAt)
...생략
itemRedisRepository.updateBiddingItemUpdatedAt();
}
}ItemCountScheduler를 스케줄러를 통해 5초마다 실행시켜서 처리하였다.
이 방식엔 문제점이 몇 가지 있었다.
첫 번째로 mariadb의 정보를 읽어오기 위해 여러 도메인의 service를 의존하게 된다.
새로운 count 정보가 필요하게 될 때마다 각 도메인 별로 비즈니스 로직을 작성하고 ItemCounterScheduler에 코드를 추가해야 한다.
실제로 '좋아요' 개수 정보가 추가되고 이 과정을 똑같이 겪으며 이상함을 느꼈다.
방법 4.2 - CQRS
위에서 발견한 문제를 해결하기 위해 먼저 상품 count 정보를 업데이트 하기 위해 필요한 데이터를 정리하였다.
{
"itemId": 10,
"type": "bid"
}그 후 두 가지 기능을 추가하였다.
- 작업 버퍼(큐)
- EntityListener
작업 버퍼는 위에서 정리한 데이터 redis에 잠시 저장해 놓는다. 이렇게 저장해 놓은 데이터는 스케줄러를 통해 일괄 처리하게 된다.
EntityListener는 JPA의 Entity가 생성, 수정, 삭제 전/후 이벤트를 리스닝하여 특정 작업을 할 수 있다. 이 리스너를 통해서 작업 버퍼에 적절한 데이터를 넣게 된다.
흐름은 다음과 같다.
- 댓글, 입찰, 좋아요 entity가 추가되면 EntityListener를 통해 작업 버퍼에 넣는다.
- 5초마다 이 버퍼를 비우면서 item count 정보를 업데이트하게 된다.
CountTask
public interface CountTask extends BufferTask {
CounterTaskType getType();
int getDelta();
}CountTask는 작업 버퍼에 들어갈 타입이다. id(BufferTask 상속), type, delta 정보가 들어있다.
여기서 id는 작업이 필요한 데이터의 id이고 type은 count 타입, delta는 개수를 조절한다. 예를 들어, 좋아요가 취소됐다면 -1 값을 저장한다.
CommentCountTask
댓글의 CountTask 타입 예시이다.
@Getter
public class CommentCountTask implements CountTask {
private CounterTaskType type;
private Long id;
private int delta;
public static CommentCountTask of(Long itemId, int delta) {
return CommentCountTask.builder()
.type(CounterTaskType.comment)
.id(itemId)
.delta(delta)
.build();
}
}ItemCountBuffer
public class ItemCountBuffer implements CountBuffer {
private final RedisTemplate<String, CountTask> redisTemplate;
private ListOperations<String, CountTask> opsList;
@Value("${custom.redis.item.bidding.item-count-buffer}")
private String key;
@PostConstruct
public void init() {
opsList = redisTemplate.opsForList();
}
@Override
public void push(CountTask bufferTask) {
opsList.rightPush(key, bufferTask);
}
@Override
public long size() {
return Optional.ofNullable(opsList.size(key)).orElse(0L);
}
@Override
public List<CountTask> popAll() {
List<CountTask> tasks = opsList.range(key, 0, -1); // 0 ~ bufferSize
redisTemplate.delete(key);
return tasks;
}
}ItemCountBuffer는 RedisTemplate의 List 자료구조를 사용하여 구현하였다. 데이터를 넣고 한번에 비우는 메서드가 있다.
CommentEntityListener
public class CommentEntityListener {
@PostPersist
public void postPersist(Comment comment) {
ItemCountBuffer itemCountBuffer = BeanUtils.getBean(ItemCountBuffer.class);
itemCountBuffer.push(CommentCountTask.of(comment.getItem().getId(), 1));
}
@PostRemove
public void postRemove(Comment comment) {
ItemCountBuffer itemCountBuffer = BeanUtils.getBean(ItemCountBuffer.class);
itemCountBuffer.push(CommentCountTask.of(comment.getItem().getId(), -1));
}
}댓글이 생성되거나 삭제되면 CommentEntityListener를 통해서 ItemCountBuffer에 들어가게 된다.
ItemCountScheduler
@Component
public class ItemCountScheduler implements Scheduler {
private final ItemCountBuffer itemCountBuffer;
private final ItemRedisService itemRedisService;
/**
* 현재 itemCountBuffer 에 있는 작업을 가져와서 한번에 처리합니다.
*/
@Override
public void run() {
List<CountTask> tasks = itemCountBuffer.popAll();
itemRedisService.handleTasks(tasks);
}
}
이전과 달리 의존을 줄일 수 있었고 코드도 간결해졌다. handleTasks()함수를 redis의 파이프라인을 통해 버퍼의 모든 데이터를 상품 count 정보를 업데이트한다.
...생략
public void handleTasksWithPipelined(List<CountTask> tasks) {
redisTemplate.executePipelined((RedisCallback<?>) connection -> {
for (CountTask task : tasks) {
connection.hIncrBy(
(biddingItemInfoKey + task.getId()).getBytes(),
(task.getType() + countSuffix).getBytes(),
task.getDelta()
);
}
return null;
});
} //redis의 I/O를 줄이기 위해 파이프라인 기능을 사용하게 되었다.이렇게 해서 mariadb에 매번 count 쿼리를 날리지 않고 redis에서 가져오도록 설계를 하였다.
(만약 redis에 count 정보가 없다면 기존처럼 count 쿼리를 사용하여 가져온다.)
이제 성능을 테스트해보자.
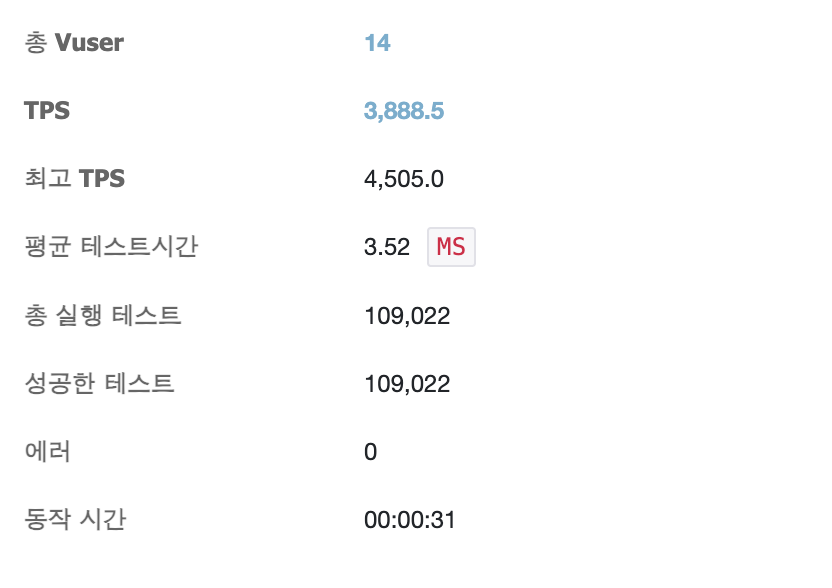
TPS가 3888정도고 MTT도 처음보다 10배 이상 좋아졌다.
회고
CQRS 패턴을 흉내를 낸 정도지만 여러 자료를 찾아보고 여러 아키텍처를 접하게 되며 이벤트 소싱, 카프카, sqs 등 많은 키워드를 접할 수 있어서 배운 점이 많았다. 또한 아키텍처를 고민하고 직접 코드를 작성하다 보며 성능이 개선되는 것을 눈으로 볼 수 있었기 때문에 재미있고 성장이 되는 시간이었다.
아쉬운 것은 필요에 의한 성능개선이 아니라는 것이다. 실제 서비스를 모니터링하면서 개선하였다면 더 적절한 방법을 적용할 수 있고 배울 점도 많을 것 같다는 생각이 든다.
또한 이번 프로젝트는 단일 서버이기 때문에 단순히 스프링의 스케줄러로 처리하였지만 서버가 여러 개라면 사용하기 어려운 부분이 있다. 서비스가 더욱 복잡하다면 이러한 작업을 처리하는 서버를 따로 둬서 효율적으로 처리할 수 있을 것 같다.
다른 정렬 조건을 추가하였을 때는 no offset 방식을 사용할 수 없기 때문에 최신순이 아닌 조건에서는 커버링 인덱스 방식을 적용해 볼 수 있을 것 같다.
참고 자료
https://jojoldu.tistory.com/528
https://velog.io/@max9106/nGrinderPinpoint-test1
https://jaehoney.tistory.com/309
23.07.25
CQRS는 학습 차원에서 적용해본 것이기 때문에 팀원들과 상의 후에 오버엔지니어링으로 판단되어서 main 브랜치에서는 기능이 제거되었다.

좋은 글 잘 읽었습니다, 감사합니다.