GitHub 주소 (소스코드 공개중)
https://github.com/levelstage/AutoMine
일러두기
이번 글에서 딥러닝의 이론과 관련한 서술은 거의 하지 않을 예정이다. 어차피 이 프로젝트에서 다루는 수준의 딥러닝 이론은 사이토 고키 선생님의 책(『밑바닥부터 시작하는 딥러닝』)에 매우 잘 나와 있으므로, 내가 또 설명해봐야 복제에 불과하다고 생각한다. 이 시리즈는 프로젝트를 진행하면서 겪은 시행착오와 거기서 얻은 교훈들을 위주로 다룰 것이다.
시작
개발 환경은 Visual Studio Code로 설정했다. 가벼우며, GitHub와 간단하게 연동할 수 있고, 알고리즘 문제 풀 때 가볍게 사용하던 CodeRunner 확장을 Python에도 그대로 이용할 수 있어 사용했다. 자동완성 등을 제공하기 때문에 IDLE로 개발하는 것보다 훨씬 편했다.
간단한 계획
내가 처음 떠올린 핵심 아이디어는 다음과 같다:
- 지뢰찾기 풀이는 이미지 분석과 큰 차이가 없다.
- 이미지 분석은 CNN을 활용하면 간단하게 만들 수 있을 것이다.
- 10*10으로 만든다고 하면, filter 크기를 3x3, stride를 1로 잡는다고 할 때, 판 전체를 보고 추상화를 시키는데는 2층 정도면 충분할 것이다. (그 뒤에 완전연결 계층을 붙인다.)
- 그리고 이 모든 것은 책에 만드는 법이 자세하게 나와 있다.
무엇이 들어가고, 무엇이 나와야 하는가?
책의 숫자 인식 신경망은 batch_size × channel_size × height × width 그리드가 들어가서 0~9의 분류 확률값이 나왔다. 그렇다면 내 신경망엔 무엇이 들어가서 무엇이 나와야 할까?
본질적으로는 비슷하다. batch_size × channel_size × height × width 그리드가 들어가는것은 똑같다. 다만 channel을 재해석해 지뢰찾기의 각 칸의 값을 원-핫 인코딩한 것을 채널로 썼다. 그러니까, 지뢰찾기의 2차원 맵을 같은 숫자끼리 모아 3차원화 시킨 것이다.
이렇게 한 이유는 간단한데, AI에게 "모르는 칸"과 "숫자 칸"이 수학적으로 관련이 전혀 없는 아예 다른 값이라고 알려주기 위함이다. 또한 이렇게 함으로써 AI가 숫자에 정비례하는 행동을 하는 것이 아니라 숫자마다 다른 대응 전략을 세우는 것을 의도했다.
나오는 것은 좀 다른데, SoftMax를 활용해서 분류를 진행하는 출력이 아니라, Sigmoid를 활용해서 height × width의 안전 확률(지뢰가 아닐 확률) 그리드를 그대로 뱉어내도록 만들었다.
책과의 가장 큰 차이점은 책에서는 "누군가가 수집한 데이터셋"에서 샘플을 뽑아 학습을 진행했지만, 나는 모든 학습 데이터를 알고리즘으로 생성했다는 점이다. 해당 알고리즘에 대해서는 또 할 얘기가 많으므로, 다음 편에서 자세히 다루겠다.
레이어 만들기
레이어를 만들 때는 데이터의 흐름을 머릿속에 그리는 것이 가장 중요했다. 결과물만을 위해서는 무작정 책의 코드를 따라치는게 더 파이토닉하고 성능도 좋겠지만, 최대한 무슨 일이 일어나는지 내가 파악하고 싶어서 "무엇이 들어가고 무엇이 나와야 하는가" 정도의 정보만 참고하고 내부 연산은 최대한 직접 짰다.
그래서 주석을 보면 당시의 고통이 약간이나마 전해지는 것 같기도.
class Conv2d:
def __init__(self, in_channels, out_channels, filter_size, stride=1, padding=0, init_scale='he'):
"""
init_scale: 'he' (ReLU용) 또는 'xavier' (Sigmoid용) 또는 float값
"""
# 소중한 형상 정보들 저장
self.stride = stride
self.pad = padding
self.in_channels = in_channels
self.out_channels = out_channels
self.filter_size = filter_size
# 입력 노드 수 계산
fan_in = in_channels * filter_size * filter_size
# 표준편차 계산
if isinstance(init_scale, float):
z = init_scale
elif init_scale == 'he':
z = math.sqrt(2/fan_in)
else:
z = math.sqrt(1/fan_in)
# 가중치, 바이어스 초기값 설정
self.W = np.random.randn(out_channels, in_channels, filter_size, filter_size) * z
self.b = np.zeros(out_channels)
# 역전파용 캐시
self.x = self.col = self.col_W = None
# 기울기 저장소
self.dW = self.db = None
def forward(self, x):
# 형상 정보 가져오기
FN, C, FH, FW = self.W.shape
N, C, H, W = x.shape
out_h = (H + 2*self.pad - FH) // self.stride + 1
out_w = (W + 2*self.pad - FW) // self.stride + 1
# 입력 데이터 전개
col = im2col(x, FH, FW, self.stride, self.pad)
# 입력 데이터에 곱할 가중치도 전개
col_W = self.W.reshape(FN, -1).T
# 합성곱 연산! 이거 한번 하려고 지금까지 행렬을 접었다가 폈다가, 왔다리 갔다리...
out = np.dot(col, col_W) + self.b
# 출력에 맞게 형상을 변환시켜 준다.
out = out.reshape(N, out_h, out_w, -1).transpose(0, 3, 1, 2)
# 출력 전에 역전파를 대비해 소중한 변수들을 저장
self.x, self.col, self.col_W = x, col, col_W
return out
def backward(self, dout):
dout = dout.transpose(0,2,3,1).reshape(-1, self.out_channels)
self.db = np.sum(dout, axis=0)
self.dW = np.dot(self.col.T, dout).T.reshape(self.out_channels, self.in_channels, self.filter_size, self.filter_size)
dx = col2im(np.dot(dout, self.col_W.transpose()), self.x.shape, self.filter_size, self.filter_size, self.stride, self.pad)
return dx네트워크 만들기
네트워크는 사실 layer들을 잇기만 하면 되니, 코드를 짜는 것 자체는 그닥 어렵지 않았다. 그러나 한번 만들어두면 끝인 layer들과 달리 학습이 잘 안 풀릴 때마다 계속 조정을 거듭하느라 수정은 상당히 많이 진행했다.
아래의 코드는 DeepConvNet의 생성자인데, 초기 계획보다 합성곱 계층이 2배로 늘어난 것을 볼 수 있다. 책은 MNIST 숫자 인식 신경망을 만드는 만큼 마지막에 소프트맥스를 쓰지만, 내가 만들 신경망은 10x10 그리드를 받으면 10x10 확률 그리드를 출력하도록 만들 계획이라 마지막 계층은 시그모이드가 되었다
def __init__(self, input_dim=(10, 10, 10),
hidden_size=256, output_size=100, loss_W=5.0):
# 확정 안전, 확정 지뢰에 대한 loss의 가중치 설정
self.loss_W = loss_W
# 입력받은 형상을 쓰기 좋게 분할해준다
C, H, W = input_dim
# conv2의 출력 개수를 미리 계산해둔다(Affine과 연결하기 위해)
pool_output_size = 64 * H * W
# layer들을 저장할 dictionary
self.layers = OrderedDict()
# 1층: 게임판 모양의 기초적인 패턴을 추출해줄 Conv1 세팅
self.layers['Conv1'] = layers.Conv2d(C, 32, 3, 1, 1)
self.layers['Relu1'] = layers.ReLU()
# 2층: 패턴들의 상호작용을 분석해줄 Conv2 세팅
self.layers['Conv2'] = layers.Conv2d(32, 32, 3, 1, 1)
self.layers['Relu2'] = layers.ReLU()
# 3,4 층: 더 깊은 패턴 분석을 위한 층 추가.
self.layers['Conv3'] = layers.Conv2d(32, 64, 3, 1, 1)
self.layers['Relu3'] = layers.ReLU()
self.layers['Conv4'] = layers.Conv2d(64, 64, 3, 1, 1)
self.layers['Relu4'] = layers.ReLU()
# 은닉층: 완전연결을 통해 추론을 진행할 Affine 세팅
self.layers['Affine1'] = layers.Affine(pool_output_size, hidden_size)
self.layers['Relu5'] = layers.ReLU()
# 출력을 위해 마지막으로 합성곱을 진행할 Affine 세팅
self.layers['Affine2'] = layers.Affine(hidden_size, output_size)
# 출력&오차: 시그모이드와 CrossBinaryEntropy로 출력 및 오차를 담당함
self.layers['Sigmoid1'] = layers.Sigmoid()
self.last_layer = layers.BinaryCrossEntropy()또한 책과 다른 점 하나는 바로 loss 함수이다.
def loss(self, x, t):
y = self.predict(x)
mask = x[:,0].reshape(x.shape[0], -1)
weights = np.ones_like(t)
# 논리적으로 맞출 수 있는 칸을 틀렸을 때 더 강한 loss를 부여한다. (가중 loss)
is_deterministic = (t < 0.05) | (t > 0.95)
weights[is_deterministic] = self.loss_W
return self.last_layer.forward(y, t, mask, weights)이 개량된 loss 함수의 특징은 다음과 같다:
1. 마스크를 통한 부분 채점
2. 확정 안전/확정 지뢰 칸에 대한 가중 채점
1번: 원-핫 인코딩된 입력 데이터의 0채널(밝혀진 칸은 0, 어두운 칸은 1)을 추출해서 마스크를 만들고, 해당 마스크를 손실 함수 계층(CrossBinaryEntropy)에 전달해 어두운 칸에 대해서만 채점을 진행하도록 만든다. 당연히 처음부터 이걸 만든건 아니었고, 이게 없을 때는 AI가 "아, 열린 칸에 대해 안전하다고만 대충 말하면 맞네?" 하는 경향을 보였기 때문에 추가했다.
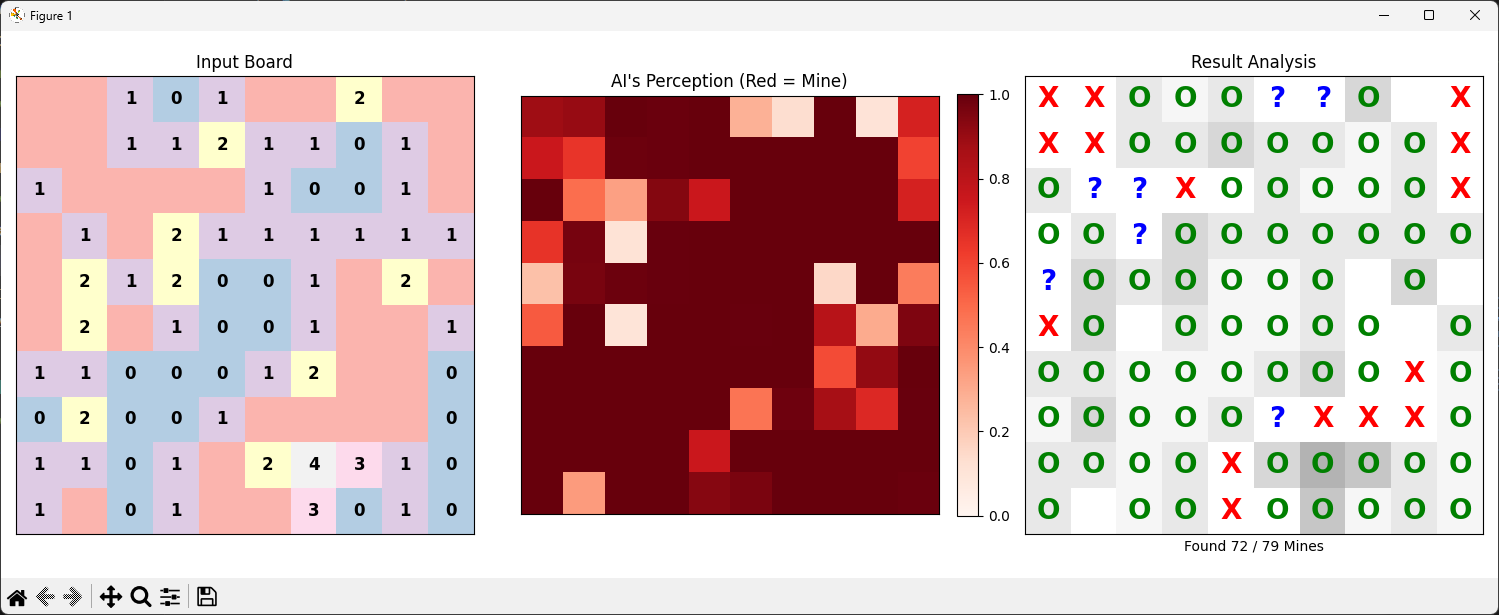
▲ 보면 알겠지만, 열린 칸만 기가 막히게 잘 맞추는 모습이다. (당시에는 열린 칸을 지뢰 취급해서 학습했기 때문에 빨간색임.)
2번: 그런데 마스킹을 도입하니 문제가 생겼다. 일반적으로 지뢰찾기는 가면 갈수록 게임 판의 논리성이 증가한다. 처음에 아무것도 모르는 암흑 상태일 때는 찍기 게임이다. 그런데 문제는 이렇게 논리가 적은 상태일수록 암흑 칸의 수가 많고, 그렇게 되면 손실 계층에 의한 채점이 진행될 때 무논리(찍기 칸, 애매한 칸) 칸을 논리 칸보다 많이 채점하게 되는데, 그 경우 신경망이 "확실한 칸을 잘 맞추기"보다는 "애매한 칸을 애매하다고 잘 말하기"로 흘러가는 현상이 생겼다.
특히 신경망이 약 0.6~0.7 정도의 적당한 값을 도배하여 뱉어내는 현상이 자주 나타났는데, 이건 매우 좋지 않았다. 그래서 생각한 것이 가중 채점으로, 논리 칸을 틀릴 경우 5배로 세게 전기충격을 주는 요법이다. 이러면 사실상 논리 칸이 기존의 5배 정도로 늘어나 버리는 효과를 가지는데, 원래는 이론상 1을 넘을 수 없던 배치 평균 loss가 2~3까지 올라간 상태로 학습이 시작된다.
그런 초기값에서 시작해서 나중에 loss가 0.6 언저리까지 내려가는 것을 보니 기분이 상당히 좋았다. 참고로 맨 처음에는 이 가중 채점의 상수를 20으로 설정했고, 이렇게 하니까 신경망이 극단적인 값 말고는 뱉지를 않아서 1/4로 줄인 것이다. 초기 로스가 무려 7.xxx였는데, 나중에 1 이하로 내려가는 걸 보니 기분이 묘했다.
학습 코드
그리하여 매우 간단하게 만든 학습 코드. 보면 알겠지만, NumPy 말고는 다 밑바닥부터 구현한 .py 파일을 임포트하고 있다.
처음에는 옵티마이저로 SGD를 간단히 구현해서 만들었지만, 인공지능한테 시켜서 Adam 형님을 생성해서 사용해 본 이후, "와 이건 신세계다" 라고 생각해 Adam 역시 밑바닥부터 구현해 사용했다.
또한 GPU가 없는 노트북을 쓰기 때문에 CPU만으로 학습을 진행했는데, 1이터당 약 0.5초 정도 걸렸다. 맨 처음에 "오버피팅 걱정은 어차피 없는데 1만 이터 정도 돌려버릴까?" 하고 생각했는데, 1시간 반을 기다려야 하길래 이터 수를 줄이다가 결국 4,000 정도가 최선이라고 판단하고 고정했다.
from Networks.network import DeepConvNet
from Networks.optimizer import Adam
from Teacher.teacher import MsTeacher
import numpy as np
# 원활한 학습을 위해 숫자 힌트 데이터를 원-핫 인코딩한다.
# 여기서 0은 닫힌 칸, 1~9는 각각 0~8을 의미한다.
def to_one_hot(grid_batch, num_classes=10):
"""
grid_batch: (N, H, W) - 값은 0~10 정수
Return: (N, C, H, W) - C=10
"""
# 0 9개 1 1개 있는 벡터 10개를 만들고, grid_batch를 인덱스 배열로 사용해서 해당하는 위치에 벡터를 넣는다.
# 형상은 (N, H, W, num_classes) 이렇게 된다.
one_hot = np.eye(num_classes)[grid_batch]
# 내가 원하는 형상은 (N, num_classes(C), H, W)이므로 transpose 하여 return
return one_hot.transpose(0, 3, 1, 2)
# 하이퍼파라미터 설정
epoch_size = 100 # 에폭은 그냥 편의상 나눠서 확인(데이터가 무한히 많음.)
iters = 4000
batch_size = 100
learning_rate = 0.001
# 각각의 기본값을 미리 맞춰 두었으므로 그대로 사용.
net = DeepConvNet()
trainer = MsTeacher()
opt = Adam()
# 이전에 학습했던 my_model.pkl 얘를 불러올수도 있음
# net.load_params()
print("학습 시작!")
for i in range(iters):
print("학습 진행중... ("+str(i)+"/"+str(iters)+")")
# 배치 크기만큼 학습 데이터를 생성
x_raw, t = trainer.generate_dataset(batch_size)
# 리스트를 numpy 배열로 변환
x_raw = np.array(x_raw)
t = np.array(t).reshape(batch_size, -1) # 정답 레이블 형상을 맞춰준다
# x를 원-핫 인코딩
x = to_one_hot(x_raw)
# 기울기를 구해준다.
grad = net.gradient(x, t)
# optimizer로 가중치 갱신!
opt.update(net, grad)
# 손실함수값을 한 에폭마다 보여준다.(였는데 그냥 매 이터마다 모니터링하고싶어서 이렇게 함)
loss = net.loss(x, t)
print(str(i//epoch_size)+"번째 에폭, 현재 손실: " + str(loss))
net.save_params()
마무리
이 정도가 파이썬에서 핵심적인 신경망 구현이다. 그런데 나를 정말로 힘들게 한 것은 이 신경망 구현은 아니었다. 신경망을 정말 많이 수정하긴 했지만, 까보니 그 모든 문제는 다른 곳에서 나온 것이었기 때문이다.
그렇다. 아래의 두 부분을 잘못 만드는 바람에 엄청난 삽질을 엉뚱한 곳에서 한 것이었다.
1. Teacher
2. Visualizer
다음 포스트는 이 두 부분을 어떻게 만들었으며, 발생한 오류들과 그것이 어떻게 나를 괴롭혀왔는지를 말해보자. 약간의 스포일러를 하자면, 자업자득이었다. 안일한 생각과 약간의 불성실함이 불러온 재앙이었다.
