도입
바로 직전, '밑바닥부터 시작하는 지뢰찾기 인공지능: AutoMine' 프로젝트를 통해 NumPy만으로 CNN 기반의 지뢰찾기 AI를 구현해 보았다.
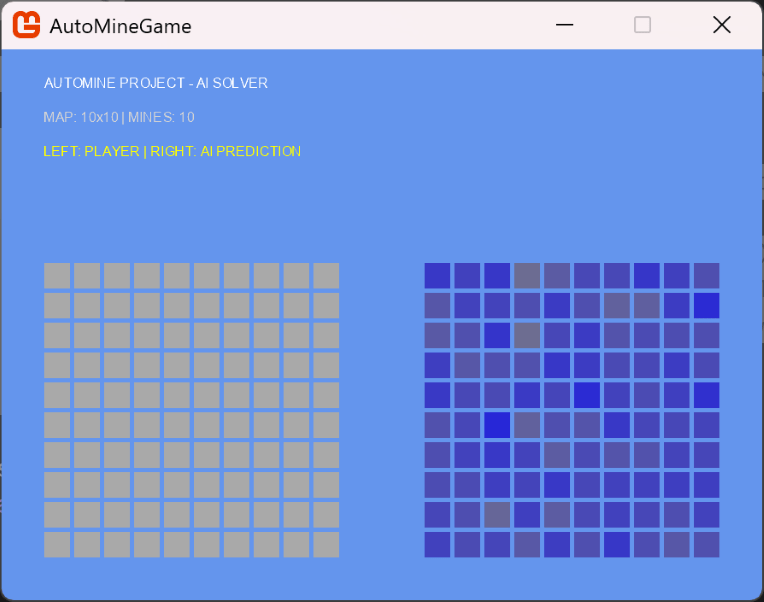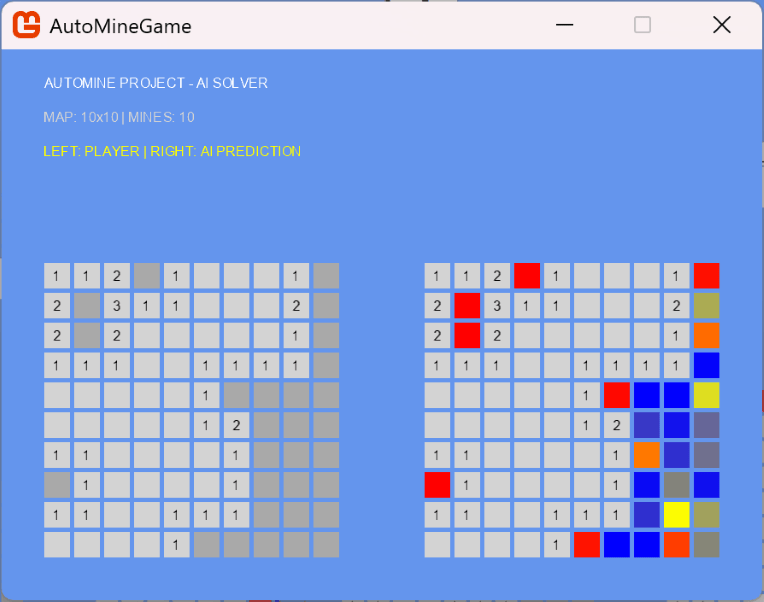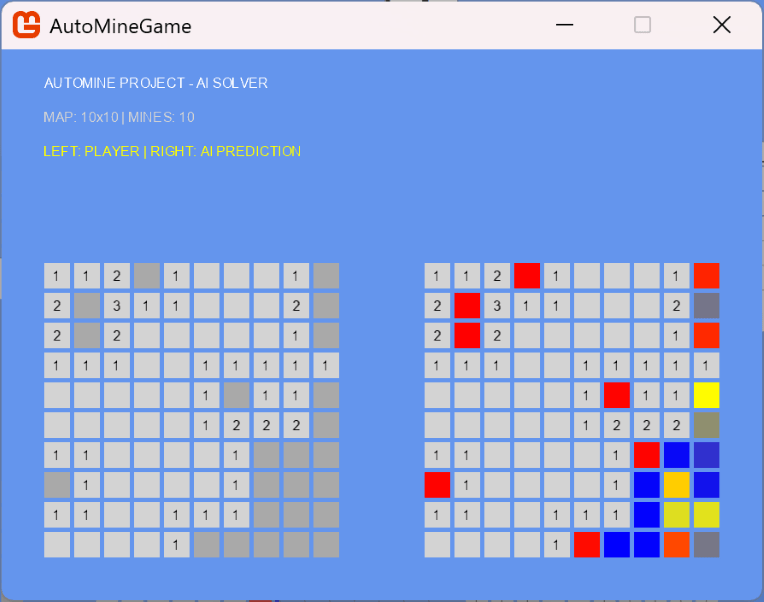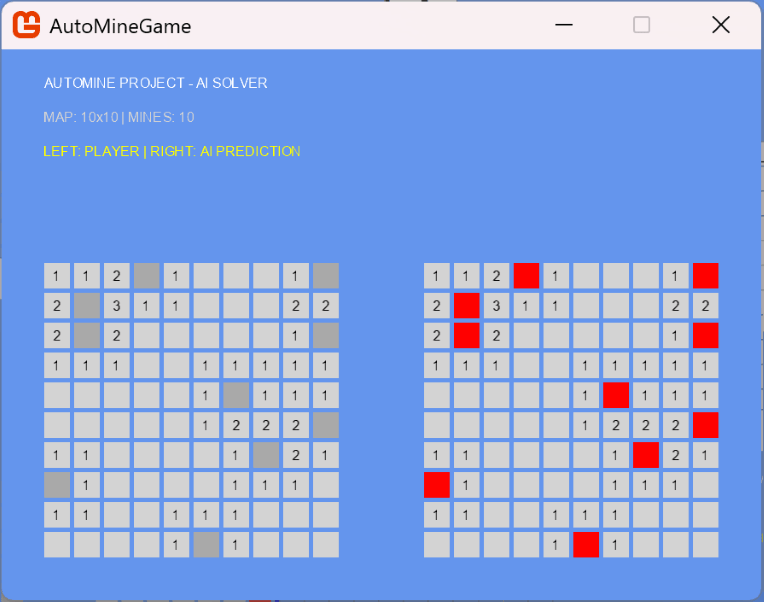
이 AI는 직접 게임을 클리어하는 것이 아니라, 비공개된 칸의 지뢰 확률을 예측하여 지뢰라면 붉은색, 안전하다면 파란색으로 시각화하도록 훈련되었다. 실제 작동 모습은 다음과 같다.
사실 이 프로젝트는 사이토 고키의 책 "밑바닥부터 시작하는 딥러닝" 한 권과 LLM의 도움을 조금만 받는다면 누구나 무난하게 진행할 수 있는 난이도였다. 계획대로라면 금방 끝났어야 했다.
하지만 마지막 포스트에서 밝혔듯, AI에게 무지성으로 코드를 맡기다 발생한 시각화 프로그램 및 학습 데이터 생성 프로그램의 대참사, 그로 인한 무한 수정의 굴레, 그리고 결정적으로 외장 그래픽카드가 없는 열악한 환경 탓에 모델을 한 번 학습시키는 데 1시간 30분이나 걸리는 참사가 벌어졌다. 결국 프로젝트는 예상보다 훨씬 늘어지고 말았다.
비록 많은 교훈을 얻고 개발자로서 성장할 수 있었지만, 여기서 끝내기엔 아쉬움이 남았다. "이건 진정한 의미의 '밑바닥'이 아니다"라는 생각이 들었기 때문이다.
내가 '밑바닥'이라고 생각했던 NumPy 아래에는 더 깊은 심연이 있었고, 그곳을 파고들면 프로젝트의 가장 큰 골칫거리 중 하나이던 "학습 속도"를 획기적으로 줄일 수 있을 것 같았다. 그래서 나는 여기서 멈추지 않고, 곡괭이를 다시 들기로 했다.
지하실을 향해
처음에는 "NumPy를 아예 0부터 내가 다시 만들어볼까?" 하는 여러모로 대담한 생각을 했다. import MyNumpy as np라니, 얼마나 멋진가.
하지만 곧 현실을 깨달았다. NumPy 역시 핵심 연산은 C/C++로 최적화되어 있던 것이다. 내가 어설프게 다시 만든다 한들 성능이 나아질 리 만무했고, 슬라이싱이나 브로드캐스팅 같은 유틸리티 기능을 구현하는 건 시간 낭비에 가까웠다.
문제의 핵심은 결국 "행렬 곱(Matrix Multiplication)"이다. 딥러닝 학습 시간의 대부분을 잡아먹는 바로 그 녀석이다.
"그럼 그냥 CUDA 기반의 CuPy나 PyTorch를 쓰면 되는 거 아냐?"
맞는 말이다. 하지만 앞서 말했듯 내 노트북에는 NVIDIA 그래픽카드가 없다. 대신 Intel 내장 그래픽(iGPU)은 달려 있다.
그래서 이번 프로젝트 AutoMine++의 목표는 다음과 같다.
NumPy(CPU)와 CuPy(CUDA) 사이의 틈새시장, 즉 '내장 그래픽'을 굴려서 행렬 연산을 가속화하는 엔진을 직접 구현하여 기존 AutoMine에 이식하는 것이다.
현재 상황...
음. 큰 야망을 가지는 것은 좋지만, 냉정하게 내 상황을 보자. 나는 이제 막 인공지능학과 1학년을 마치고 갓 전역한, 깡통에 불과하다.
이 상태로 무작정 덤벼들었다간 그냥 Gemini한테 "코드 좀 짜줘 징징"하며 부탁하고, 정작 나는 그 코드가 왜 돌아가는지도 모르는 허수아비가 될 가능성이 뻔하다. 그래서 본격적인 개발에 앞서, 무기가 되어줄 두 권의 책을 먼저 구입했다.
1. Effective C++ (제3판)
- 스콧 마이어스 지음 / 프로텍 미디어
- 알고리즘 문제 풀이용 C++이 아니라, 실전적 개발을 위한 C++을 익히기 위해 선택했다. 객체지향 문법은 배웠지만, 실전적인 메모리 관리와 테크닉이 부족한 나에게 필수적인 지침서가 될 것이다.
2. 컴퓨터 시스템 (CSAPP, Computer Systems: A Programmer's Perspective)
- Randal E. Bryant 외 / 퍼스트북
- 단순히 코드를 짜는 것을 넘어, 하드웨어 레벨에서 최적화를 이해하기 위해 골랐다. 캐시 메모리, 프로세서 구조 등 "왜 내 코드가 느린가?"에 대한 답을 줄 것이라 기대한다.
이 책들을 처음부터 끝까지 정독하면서 시험이라도 보는 것처럼 공부하기보다는 프로젝트를 진행하며 막히는 순간마다 꺼내 보는 백과사전으로 활용할 계획이다.
앞으로의 전개
이 시리즈는 뭔가 거창한 개발 강의(?) 라기보다는 맨땅에 헤딩하며 공부한 내용, 책에서 얻은 깨달음, 그리고 개발 과정에서 겪는 삽질을 기록하는 개발 일지이자 오답 노트로서 전개될 것 같다.
한 번도 가본 적 없는 로우 레벨의 세계라 두렵기도 하지만, 한편으론 내 손으로 직접 성능의 한계를 뚫어본다는 생각에 가슴이 두근거린다.
밑바닥을 넘어 지하실로! 음... 넘는다는 표현을 써도 되는걸까?
