도입
지난 시간에는 행렬 곱셈을 나이브한 구현부터 시작해서, iGPU를 활용하는 단순 구현(by SYCL)을 거쳐, 타일링까지 도입해 보았다.
그러고 나니, 슬슬 넘파이 이겼냐? 싶은 생각이 들었고, 슬슬 넘파이와 성능 비교를 해볼 때가 된 것 같아서, 오늘은 그것을 해보려고 한다.
pybind11
우리가 사용하는 python은 CPython이 일반적으로, 인터프리터의 구현이 C로 되어있다고 한다. 그래서, C/C++로 되어있는 확장 모듈을 상대적으로 간편하게 활용할 수 있는 것이다. 뭐, 간편하다고는 해도 서로 다른 두 언어를 연결하는만큼, 원래는 복잡한 API를 준수해서 열심히 코드를 짜야 하지만, 이 프로젝트는 그것에 대해서는 큰 관심이 없으므로, 누군가가 만들어 놓은 좋은 코드를 가져다 쓰기로 했다. 그것이 pybind11이다.
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <sycl/sycl.hpp>
#include <stdexcept>
namespace py = pybind11;
class MultEngine
{
public:
MultEngine() : q(sycl::default_selector_v) {}
py::array_t<float> matmul(py::array_t<float> a, py::array_t<float> b)
{
// 두 ndArray a, b를 받아서, 각각의 buffer_info를 python에 요청한다.
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
// 받은 buffer_info를 가지고 차원과 행렬의 크기를 검사한다.
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: sycl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[1] != pufB.shape[0]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
// 통과했다면, 크기를 기록해두고, return을 위한 ndArray를 생성한 뒤, buffer_info를 가져온다.
const int M = pufA.shape[0], N = pufB.shape[1], K = pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
// 가져온 각각의 buffer_info에서 실제 데이터가 저장된 주소를 가져온다.
// void* 형태로 시작 주소를 주기 때문에, float* 형태로 캐스팅
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
// 구해놓은 포인터를 sycl의 버퍼에 넘겨주면, 이제 데이터의 주도권을 sycl로 완전히 넘긴것.
sycl::buffer<float, 1> bufA(ptrA, sycl::range<1>(M * K));
sycl::buffer<float, 1> bufB(ptrB, sycl::range<1>(K * N));
sycl::buffer<float, 1> bufR(ptrR, sycl::range<1>(M * N));
// 타일링을 위해 타일 크기를 지정해주고,
const int TILE = 16;
// q에 행렬 연산 작업을 제출해준 후,
q.submit([&](sycl::handler& h) {
// Accessor 세팅
sycl::accessor accA(bufA, h, sycl::read_only);
sycl::accessor accB(bufB, h, sycl::read_only);
sycl::accessor accR(bufR, h, sycl::write_only, sycl::no_init);
// Tiling을 위한 local memory 할당
sycl::local_accessor<float, 2> tileA(sycl::range<2>(TILE, TILE), h);
sycl::local_accessor<float, 2> tileB(sycl::range<2>(TILE, TILE), h);
// 작업을 M*N조각으로 나눈 후, TILE*TILE 크기의 코어 팀에게 작업을 배정한다.
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M, N), sycl::range<2>(TILE, TILE)), [=](sycl::nd_item<2> item) {
const int r = item.get_global_id(0), c = item.get_global_id(1);
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
const int NUM_TILES = K / TILE;
float sum = 0.0f;
// 메모리 접근은 타일 단위로,
for (int t = 0; t < NUM_TILES; ++t)
{
tileA[local_r][local_c] = accA[r * K + (t*TILE + local_c)];
tileB[local_r][local_c] = accB[(local_r + t*TILE) * N + c];
item.barrier(sycl::access::fence_space::local_space);
// 내적 연산은 여전히 하나씩 접근해야 하지만, 로컬 메모리에 접근하는거라 훨씬 빠름!
for (int k = 0; k < TILE; ++k)
{
sum+=tileA[local_r][k] * tileB[k][local_c];
}
item.barrier(sycl::access::fence_space::local_space);
}
accR[r * N + c] = sum;
});
});
// 결과를 기다리고, res를 return하면 끝.
q.wait();
return res;
}
private:
sycl::queue q;
};
PYBIND11_MODULE(sycl_mat, m) {
// 파이썬 쪽에 "MultEngine"이라는 이름으로 클래스 노출
py::class_<MultEngine>(m, "MultEngine")
.def(py::init<>()) // 생성자 연결
.def("matmul", &MultEngine::matmul); // matmul 메서드 연결
}지난번에 만들어 놓은 matmul_sycl_tiled() 메서드의 커널은 그대로 옮겨오지만, 파이썬에서 생성한 NumPy 배열에 접근해야 하므로, 버퍼 관련 설정은 좀 바꿀 필요가 있었다. 거창하게 말했지만, 요지는 파이썬에게 행렬의 차원, size에 대한 정보와 entry가 실제로 들어있는 배열의 시작 포인터를 달라고 할 필요가 있었다는 것이다.
pybind11에서는 그걸 pybind11::buffer_info라는 오브젝트를 request() 하는 것으로 간단하게 획득할 수 있었고, 거기다가 PYBIND11_MODULE이라는 강력한 매크로를 제공해주는 덕분에, 쓸데없는 수고를 들이지 않고 간단하게 포팅할 수 있었다.
빌드
이렇게 pybind11을 가지고 C++로 모듈 소스를 다 짠 이후에는, 이것을 python이 알아들을 수 있는 형태로 빌드해주어야 한다. 즉 소스를 가지고 .pyd 파일(파이썬 라이브러리 파일 on Windows)을 빌드해야 한다는 것이다. 이렇게 .pyd 파일을 만들어서 해당 모듈을 사용할 .py 파일과 같은 디렉토리에 넣어주기만 하면, 파이썬 인터프리터가 모듈을 import할 때의 검색 범위에 해당 .pyd 파일도 자동으로 들어간다.
빌드에는 cmake를 사용했다. 인텔 OneAPI를 설치할 때 자동으로 설치됐기 때문에 따로 깔아줄 필요는 없었다.
사실 코딩하는것보다 빌드하는 것에서 더 애를 먹었던 것 같다. 그 이유는 다음과 같다.
-
의존관계: 내가 만든 모듈은 sycl과 pybind11이라는 STL이 아닌 두 라이브러리를 사용한다. 따라서 두 라이브러리의 경로를 컴파일러에게 명확히 알려주어야 했다.
-
Release 사양으로 컴파일: 별 생각 없이 컴파일을 시도하면 Debug 사양으로 컴파일이 되어서, 작동 시간이 몇십배로 늘어난다. 반드시 Release 사양으로 컴파일 할 필요가 있다.
-
컴파일러: cmake에 아무것도 알려주지 않으면, 얘는 자연스럽게 자신의 기본 컴파일러인 visual studio를 활용해서 컴파일을 시도한다. 그런데, sycl같은 경우 intel OneAPI의 컴파일러인 icx가 필요하므로(visual studio 같은 경우 parallel_for 등 GPU에게 내리는 명령들을 이해하지 못한다.) 그것을 cmake에게 알려줄 필요가 있었다.
이런 사실들을 시행착오를 통해 알아내며, 결국 "돌아가는" 빌드 명령어를 찾아냈다.
cmake -G "Ninja" -DCMAKE_BUILD_TYPE=Release -DCMAKE_CXX_COMPILER=icx -Dpybind11_DIR="pybind11의 경로" CMakeList.txt의 경로
cmake --build . --config Release 간단히 말로 풀어서 설명하자면
첫번째 줄은
cmake야. CMakeList.txt를 읽고, 거기 쓰인대로 빌드 설계도를 만들어서 Ninja라는 Generator에게 빌드 파일을 만들라고 시키되, 컴파일러는 icx를 쓰고 Release 사양으로 만들라고 전하는 계획서 만들어와. 아 그리고, pybind11어디있는지 모르지? 여기있어.
같은 뜻이다. 두번째 줄은 계획서대로 그냥 빌드하라는 뜻이다. 아, 참고로 Ninja는 OneAPI를 깔면 같이 깔리는 Generator인데, cmake가 빌드의 설계도를 만드는 녀석이라면 Generator는 이 설계도를 가지고 실제로 컴파일러를 부려먹는 작업반장 같은 녀석이라고 한다. 이 프로젝트에서는 "일단 돌아가는 빌드"를 목표로 하기 때문에, 그 이상 딥하게 찾아보지는 않았다.
CMakeList.txt의 내용물은 아래와 같다. (cmake관련 문법은 하나도 모르기에 Gemini의 도움을 받아 작성했다.)
cmake_minimum_required(VERSION 3.14)
project(sycl_mat_project)
# 1. 파이썬과 pybind11 환경 찾기
find_package(Python COMPONENTS Interpreter Development REQUIRED)
find_package(pybind11 CONFIG REQUIRED)
# 2. 파이썬 모듈로 컴파일 (타겟 이름: sycl_mat)
pybind11_add_module(sycl_mat sycl_mat.cpp)
# 3. Intel DPC++ (SYCL) 전용 컴파일 옵션 붙이기
target_compile_options(sycl_mat PRIVATE -fsycl -O3)
target_link_options(sycl_mat PRIVATE -fsycl)자, 그래서 모듈은 완성했고, 이제 python을 돌려볼 시간이다.
잠시 지하실 밖으로 (python에서 NumPy와 대결)
import os
import numpy as np
import time
# DLL 경로 설정
intel_bin_path = r"oneAPI에 있는 .dll의 경로"
if os.path.exists(intel_bin_path):
os.add_dll_directory(intel_bin_path)
import sycl_mat
engine = sycl_mat.MultEngine()
def benchmark(size):
print(f"\n대결 시작: 행렬 크기 {size} x {size}")
# 데이터 생성 (float32 = C++의 float)
A = np.random.rand(size, size).astype(np.float32)
B = np.random.rand(size, size).astype(np.float32)
# --- SYCL Warm-up (JIT 컴파일 시간 제외를 위해 한 번 먼저 돌림) ---
_ = engine.matmul(A[:16, :16], B[:16, :16])
# --- NumPy 연산 ---
start = time.perf_counter()
res_np = np.dot(A, B)
end = time.perf_counter()
np_time = end - start
print(f"NumPy (CPU): {np_time:.4f} 초")
# --- SYCL 연산 ---
start = time.perf_counter()
res_sycl = engine.matmul(A, B)
end = time.perf_counter()
sycl_time = end - start
print(f"SYCL (GPU/Acc): {sycl_time:.4f} 초")
# --- 검증 및 결과 ---
if np.allclose(res_np, res_sycl, atol=1e-3):
print(f"결과 일치! (속도 차이: {np_time / sycl_time:.2f}배)")
else:
print("결과가 일치하지 않습니다. 로직 확인 필요.")
# 단계별 대결
for s in [512, 1024, 2048, 4096]:
benchmark(s)자, 대망의 결과는 어땠을까.
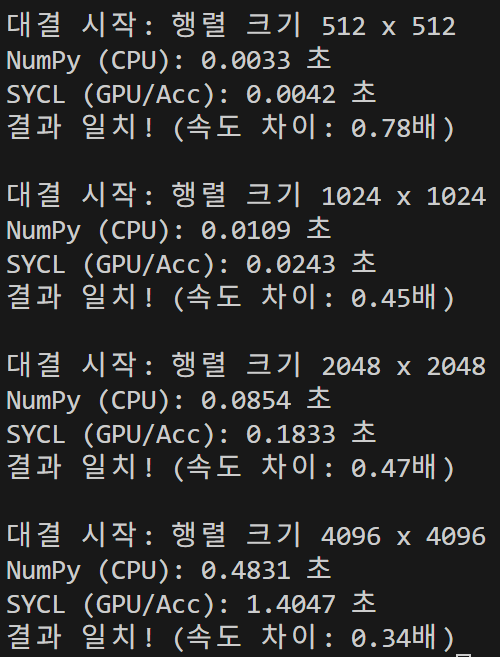
어느정도 예상한 안타까운 결과였다. iGPU를 쓰는데도 CPU한테 상대가 되지 않았다. NumPy의 행렬연산은 intel이 만들어둔 라이브러리를 이용하는데, CPU를 만든 회사에서 만든 만큼, 기기의 성능을 정말 한계까지 끌어다가 사용한다는 것 같다. 즉, 하드웨어 차이가 아무리 나 봤자, 그걸 제어하는 소프트웨어에 의해 그 차이가 극복될 수 있다는 것이다. 나는 iGPU를 사용했지만 그것의 성능을 100% 끌어내지 못하고 있기 때문에, CPU의 100%에 패배한 것이다.
마무리 (다시 지하실로!)
그렇다면, NumPy를 이기기 위해 내가 해야할 일은 단 하나이지 않은가? 그렇다. 기기의 성능을 100%에 끌어내는 것이다!
우선, 기본적으로 행렬곱 연산을 진행할 때, CPU를 쓰든 GPU를 쓰든 곱셈을 하고, 더하기를 하는 횟수는 동일할 것이다. 그리고 그 부분에서 GPU는 CPU보다 빠를 것이다. 그것은 내가 무슨 짓을 해도 바꿀 수 없는 부분이다. GPU라고 해서 CPU보다 더 적은 연산을 해도 되는 것은 아니다. 그렇다면, 내가 바꿀 수 있는 부분은 무엇인가? 그것은 바로 메모리 병목에 대한 부분이다. 지금보다도 더 적게 메모리에 접근하며, 더 진하게 로컬 메모리를 우려먹을 수 있는 방법을 찾아야 한다.
그런 의미에서 다음 시간에는 다시 지하실로 돌아가 커널을 더욱 최적화할 계획이다. 이쪽에도 인텔 형님들이 만들어둔 해답지가 있다는 사실을 알고는 있지만, 이것을 스스로의 힘으로 돌파하는것이 이번 프로젝트의 성격에 훨씬 맞으며 내 성장에도 훨씬 도움이 되리라 믿는다.
