도입
지난 시간에는 우선 DPC++에 익숙해지자는 생각으로 행렬 덧셈을 구현해 보았다. 그리고 결론적으로 행렬 덧셈처럼 데이터를 연산하는 것보다 연산장치로 데이터를 옮기는 데에 시간이 더 많이 드는 연산은 CPU에 비해 GPU가 불리하다는 결론까지 내려보았다.
그리하여 몸풀기도 끝났으니, 이제부터 진짜 하려고 했던 행렬 곱셈을 구현해볼 것이다. 처음부터 대단한 최적화를 적용하기보다는 우선 직관적으로 구현한 후, 차근차근 속도를 높여나갈 생각이다.
직관적 구현 (by CPU)
우선 행렬곱을 원활하게 구현하기 위해 행렬 클래스부터 정의했다.
class matrix
{
public:
matrix() : size_r(0), size_c(0) { }
matrix(const int a, const int b) : size_r(a), size_c(b), v(a*b, 0.0f) {}
int size_r, size_c;
void set_entry(const int r, const int c, const float value)
{
v[r*size_c + c] = value;
}
float get_entry(const int r, const int c) const
{
return v[r*size_c + c];
}
private:
std::vector<float> v;
};그리고 간단히 CPU만을 사용해서 3중 반복문으로 행렬 곱셈을 구현해보았다. 덤으로 성능 측정 코드까지 집어넣었더니...
matrix matmul_naive(const matrix& a, const matrix& b)
{
// 형상이 맞는지 확인
if (a.size_c != b.size_r) {
throw std::invalid_argument("Matrix size is not suitable for multiplication.");
}
// 3중 for문으로 res 행렬 생성 후 return.
matrix res = matrix(a.size_r, b.size_c);
for (int i = 0; i < a.size_r; ++i)
{
for (int j = 0; j < b.size_c; ++j)
{
float sum=0;
for (int k = 0; k < a.size_c; ++k)
{
sum += a.get_entry(i, k) * b.get_entry(k, j);
}
res.set_entry(i, j, sum);
}
}
return res;
}
int main()
{
const int N = 1024;
matrix A = matrix(N, N, std::vector<float>(N*N, 0.5f));
matrix B = matrix(N, N, std::vector<float>(N*N, 0.4f));
auto start = std::chrono::high_resolution_clock::now();
matmul_naive(A, B);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> cpu_time = end - start;
std::cout << "Naive: " << cpu_time.count() << " ms\n";
return 0;
} 
대충 16~17초 정도가 걸렸다. 캐시 히트율을 올리거나, 코어를 최대한으로 활용하면 당연히 이거보다 훨씬 빠르게 돌릴 수 있겠지만, 일단 대충 구현한 바 이렇고, 이제 전체적인 감을 확실히 잡은데다 비교 대상도 생겼으니 GPGPU 프로그래밍으로 넘어가자.
SYCL(with iGPU)로 구현하기 + 성능 비교
우선 버퍼로 matrix 내부의 v 벡터를 넘기기 위해, v의 포인터를 얻기 위한 멤버 함수를 추가한다.
class matrix
{
public:
// ...
float* data() { return v.data(); }
const float* data() const { return v.data(); }그리고 나서 sycl을 활용한 행렬곱 함수를 만들고, main 함수를 확장시켜 두 버전의 성능을 비교하도록 했다.
matrix matmul_sycl(sycl::queue& q, const matrix& a, const matrix& b)
{
if (a.size_c != b.size_r) {
throw std::invalid_argument("Matrix size is not suitable for multiplication.");
}
matrix res = matrix(a.size_r, b.size_c);
const int M = a.size_r, K = a.size_c, N = b.size_c;
// matrix 객체 안에 있는 vector 객체가 관리하는 float 배열의 포인터를 그대로 넘겨준다.
sycl::buffer<float, 1> bufA(a.data(), sycl::range<1>(M * K));
sycl::buffer<float, 1> bufB(b.data(), sycl::range<1>(K * N));
sycl::buffer<float, 1> bufR(res.data(), sycl::range<1>(M * N));
q.submit([&](sycl::handler& h) {
// Accessor 세팅
sycl::accessor accA(bufA, h, sycl::read_only);
sycl::accessor accB(bufB, h, sycl::read_only);
sycl::accessor accR(bufR, h, sycl::write_only, sycl::no_init);
// 작업을 M*N조각으로 나눈 후, idx를 부여하고 각 프로세서로 뿌린다.
h.parallel_for(sycl::range<2>(M, N), [=](sycl::id<2> idx) {
const int r=idx[0], c=idx[1];
float sum = 0.0f;
// 내적은 어쩔 수 없이 for문으로 해준다.
for (int k = 0; k < K; ++k) {
sum += accA[r*K + k] * accB[k*N + c];
}
accR[r*N + c] = sum;
});
});
// 함수가 종료되면서 버퍼의 소멸자가 호출되며, 복사된 데이터가 원래 위치로 돌아온다.
return res;
}
int main()
{
// 곱할 두 행렬을 세팅해준다.
const int SIZE = 1024;
matrix A = matrix(SIZE, SIZE, std::vector<float>(SIZE*SIZE, 0.5f));
matrix B = matrix(SIZE, SIZE, std::vector<float>(SIZE*SIZE, 0.4f));
// CPU에서 3중 반복문을 돌리는 직관적인 구현
auto start = std::chrono::high_resolution_clock::now();
matmul_naive(A, B);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> cpu_time = end - start;
std::cout << "Naive: " << cpu_time.count() << " ms\n";
// iGPU를 활용한 구현
try {
sycl::queue q;
start = std::chrono::high_resolution_clock::now();
matmul_sycl(q, A, B);
end = std::chrono::high_resolution_clock::now();
std::chrono::duration<double, std::milli> gpu_time = end - start;
std::cout << "sycl: " << gpu_time.count() << " ms\n";
}
catch(sycl::exception const& e)
{
std::cerr << "SYCL: " << e.what() << '\n';
}
return 0;
}성능을 비교해보면...?
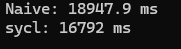
응? 생각보다 별 차이 안나네? 그런데 사실 여기까지는 예상 안이긴 하다. 이전에 행렬 덧셈을 구현했을 때 이미 경험한 메모리 병목을 또 겪었을 뿐이다. 소스코드를 잘 보면, 각 프로세서는 루프를 돌면서 바로 이 문제의 코드: accA[rK+k] accB[k*N +c]를 매 반복마다 실행하게 되는데, 이 말은 곧 각 프로세서들이 분명 분산해서 일을 하긴 하지만, 매 작업마다 메모리에 액세스를 요청하기 때문에 결국 모든 프로세서가 메모리 대역폭이라는 병목에 몰리게 되는 것이다. 그런데, 잘 생각해보면, 이 병목은 쉽게 해소 가능하다.
지금 가장 큰 문제는, 마치 이전에 구현했던 행렬 덧셈마냥 메모리에서 데이터를 가져온 후 바로 그것을 땅바닥에 버리는 행위이다. 행렬 곱셈은 덧셈과 달리 하나의 entry에 여러 번 접근하기 때문에, 차라리 대량의 데이터를 local memory로 한번에 옮겨 놓고, 그것을 여러번 참조하는 것이 효과적이다.(local memory는 SRAM으로, DRAM보다 훨씬 빠르다.) 그런데 local memory는 그 크기가 작으므로, 큰 데이터를 어떻게 나누어서 가져올지 생각을 해 봐야 하는데, 이 일련의 행위를 Tiling이라고 부르는 것 같다.
메모리 병목을 돌파하자: Tiling
일단 타일링으로 넘어가기 전에, 내가 지금까지 작성한 코드가 정확히 어떤 방식으로 작동하는지 짚어볼 필요가 있었다.
잘 생각해보면, GPU에 M×N(=1024×1024)개의 코어가 있을 리 없지 않은가? 따라서 이 코드:
// 작업을 M*N조각으로 나눈 후, idx를 부여하고 각 프로세서로 뿌린다.
h.parallel_for(sycl::range<2>(M, N), [=](sycl::id<2> idx) {의 실제 동작은 M×N의 작업을 바로 할당하는 것이 아니라, M×N의 가상 작업자들을 만들어 놓고, 그들에게 일을 예약하는 식으로 작동한다. 손이 남는 코어가 생기면 다음 가상 작업자의 일을 그 코어가 받는 식이다.
그리고 sycl은 이 가상 작업자들을 n명씩 묶어서 작업을 시키는 기능을 제공하는데, 이것이 Tiling을 구현하는 핵심이다. 작업자들을 가상의 팀으로 묶은 후, 그들에게 공용으로 사용할 데이터(=원본 행렬의 일부)를 미리 로컬 메모리로 복사해 온다. 이러면 각 작업자들이 매번 시스템 메모리로 데이터를 가지러 갈 필요가 없다. 바로 옆에 있는 로컬 메모리로 가면 된다. 기존에 같은 entry를 여러 작업자들이 중복으로 접근하면서 생기던 병목을 해소할 수 있는 것이다. 해당 entry를 건드리는 작업자들을 묶어서 데이터를 미리 제공해 두는 것으로!
그런 의미에서 Tiling을 적용한 코드는 다음과 같다.(참고로, 행렬의 크기는 2의 n제곱(n은 5 이상의 자연수)꼴이라고 가정한다. 그 이외에는 에러남.)
matrix matmul_sycl_tiled(sycl::queue& q, const matrix& a, const matrix& b)
{
if (a.size_c != b.size_r) {
throw std::invalid_argument("Matrix size is not suitable for multiplication.");
}
matrix res = matrix(a.size_r, b.size_c);
const int M = a.size_r, K = a.size_c, N = b.size_c;
// 가상 작업자를 묶을 타일의 크기
const int TILE = 16;
// matrix 객체 안에 있는 vector 객체가 관리하는 float 배열의 포인터를 그대로 넘겨준다.
sycl::buffer<float, 1> bufA(a.data(), sycl::range<1>(M * K));
sycl::buffer<float, 1> bufB(b.data(), sycl::range<1>(K * N));
sycl::buffer<float, 1> bufR(res.data(), sycl::range<1>(M * N));
q.submit([&](sycl::handler& h) {
// Accessor 세팅
sycl::accessor accA(bufA, h, sycl::read_only);
sycl::accessor accB(bufB, h, sycl::read_only);
sycl::accessor accR(bufR, h, sycl::write_only, sycl::no_init);
// Tiling을 위한 local memory 할당
sycl::local_accessor<float, 2> tileA(sycl::range<2>(TILE, TILE), h);
sycl::local_accessor<float, 2> tileB(sycl::range<2>(TILE, TILE), h);
// 작업을 M*N조각으로 나눈 후, TILE*TILE 크기의 코어 팀에게 작업을 배정한다.
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M, N), sycl::range<2>(TILE, TILE)), [=](sycl::nd_item<2> item) {
const int r = item.get_global_id(0), c = item.get_global_id(1);
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
const int NUM_TILES = K / TILE;
float sum = 0.0f;
// 이제 메모리 접근은 타일 단위로,
for (int t = 0; t < NUM_TILES; ++t)
{
tileA[local_r][local_c] = accA[r * K + (t*TILE + local_c)];
tileB[local_r][local_c] = accB[(local_r + t*TILE) * N + c];
item.barrier(sycl::access::fence_space::local_space);
// 내적 연산은 여전히 하나씩 접근해야 하지만, 로컬 메모리에 접근하는거라 훨씬 빠름!
for (int k = 0; k < TILE; ++k)
{
sum+=tileA[local_r][k] * tileB[k][local_c];
}
item.barrier(sycl::access::fence_space::local_space);
}
accR[r * N + c] = sum;
});
});
// 함수가 종료되면서 버퍼의 소멸자가 호출되며, 복사된 데이터가 원래 위치로 돌아온다.
return res;
}이전 코드랑 작동 원리는 완전히 동일하지만, 로컬 메모리 공간에 미리 대량의 데이터를 읽어놓고, 각각의 작업자들이 sum을 갱신할 때 시스템 메모리가 아닌 로컬 메모리에 접근한다는 정도의 차이가 있다. 자 그럼 얼마나 빨라졌을까...

네?
뭔가가 잘못됐다. 그리고 실제로 뭔가가 잘못됐는데, 바로 visual studio의 디버그 기능 때문이었다. 내가 아무것도 모르고 빌드를 디버그 모드로 했는데, 그렇게 하니까 visual studio가 이 프로그램의 모든 데이터를 추적하느라 훨씬 많은 시간을 먹어버린 것이다. 그리하여 모드를 release로 바꾸고 다시 돌리니 다음과 같았다.
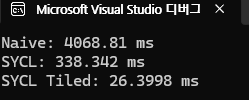
정말 괄목할만한 성능 향상이다! 주목해야할 점이 하나 더 있다면, 알고 보니 기존 SYCL도 대단한 향상을 이루었다는 점. 컴파일을 어떻게 하냐에 따라 프로그램의 퍼포먼스가 크게 바뀔 수 있다는 사실을 깨달아 버렸다...
마무리
생각보다 싱겁다면 싱겁게도, 행렬 연산 구현이 얼추 마무리되었다. 그런데 갑자기 이런 생각이 들었다. iGPU를 사용하긴 했는데, 설마 NumPy한테 지는 건 아니겠지 하는... NumPy는 정말 하드웨어를 극한까지 짜내서 사용한다고 하던데, 솔직히 나는 아직 내 intel UHD Graphics 녀석을 한계까지 짜내고 있지 않다고 생각한다. 그냥 적당히 최적화한거고...
그런 의미에서 다음 시간에는 현재까지의 코드를 파이썬에서 사용할 수 있게 포팅하고, 넘파이와 같은 운동장에서 승부를 볼 생각이다! 과연, 이길 수 있을까?
