도입
지난 시간에는 NumPy에게 카운터펀치를 맞고 다시 지하실로 내려가, 지금까지 사용하지 않았던 이론상 최강의 메모리: 레지스터를 활용하기 위해 행렬곱을 외적 방법으로 구하는 커널을 작성했다. 이번 시간에는 거기서 더더욱 시간을 줄이기 위해 아래의 세 가지 최적화를 적용해볼 생각이다.
- 불필요한 오버헤드를 줄인다.
- GPU의 메모리 버스를 100% 활용한다.
- 산술 연산과 메모리 접근을 동시에 진행하여 메모리 병목을 숨긴다.
세 가지 다 직관적인 해결 방법이므로, 하나씩 바로 진행해보자.
USM
지금까지는 포인터를 직접 건드리지 않고, sycl::buffer를 활용해서, 메모리 관리를 객체에 위임했다. 이렇게 하면, 스코프가 종료될 때 자동으로 sycl::buffer의 소멸자가 호출되기 때문에 메모리 누수라거나, 원래 메모리로 결과 데이터를 복사해가는 것을 잊어버리는 사고를 원천 차단할 수 있다는 장점이 있지만, 사실 내가 지금 사용하는 iGPU는 이런 일련의 과정이 아무 의미가 없는데, 따로 VRAM 없이 시스템 메모리를 그대로 쓰기 때문이다. 별도의 메모리 관리 객체가 전혀 필요 없다.
심지어 만약 VRAM이 달린 GPU/ACC를 사용한다고 해도 내가 해야하는 관리는, "alloc한 메모리를 free해 주기"와 "계산된 res행렬을 시스템 메모리로 옮겨주기" 이 두개밖에 없다는 것을 깨달았고, 그러면 메모리 관리도 내가 직접 해도 되는 것 아닐까? 하는 생각이 들었다.
그 모든 것을 해결할 수 있는 sycl의 기능이 바로 USM(Unified System Memory)으로, 시스템 메모리 뿐만 아니라 GPU의 VRAM도 포인터 다루듯이 주소를 얻어오고, 메모리 alloc/copy/free를 실행할 수 있게 해주는 기능이다.
일단 내가 iGPU를 쓰긴 하지만, 어떤 GPU로도 돌릴 수 있는(그게 sycl의 장점이기도 하니 최대한 살리고 싶었다.) 모듈을 지향하고 있기 때문에, VRAM이 있는 장치일 경우 그것을 감지해서 여러가지 메모리 조작을 해 줄 필요가 있었다.
그러다 보니, 처음에는 매번 함수에서 q의 .device()에 접근해서 system_allocations(sycl이 아닌 c++기본 malloc, free 등)를 지원하는지 확인해야하나 하고 생각했는데, 이를 해결할 완벽한 방법이 하나 있었으니, 바로 static singleton이다. C++ 11이상부터는 함수 안에 static으로 변수를 선언하고 초기화할 시, 그 초기화가 모든 스레드 안전하게 단 한번만 일어난다고 한다. 즉, 함수 안에 간단히 싱글턴 객체를 만들 수 있는 것이다.
여기서 힌트를 얻어서, 파이썬 포팅도 살짝 바꿔보았다. 이전까지는 matmul()함수가 MultEngine이라는 객체의 메소드로 들어갔지만(sycl::queue 객체를 계속 우려먹기 위해), 아예 sycl::queue를 함수의 static singleton으로 선언해버리면 그런 지저분한 방법을 쓰지 않아도 되었다. 이 부분은 아래의 코드에서 직접 확인해 보길 바란다.
하여튼, 아래가 USM을 적절히 활용해 기존의 buffer와 accessor가 주던 오버헤드를 날려버린 코드이다.
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <sycl/sycl.hpp>
#include <stdexcept>
namespace py = pybind11;
py::array_t<float> matmul(py::array_t<float> a, py::array_t<float> b)
{
// 싱글턴 큐를 유지한다.
static sycl::queue q(sycl::default_selector_v);
static bool has_system_usm = q.get_device().get_info<sycl::info::device::usm_system_allocations>();
// 두 ndArray a, b를 받아서, 각각의 buffer_info를 python에 요청한다.
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
// 받은 buffer_info를 가지고 차원과 행렬의 크기를 검사한다.
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: sycl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[1] != pufB.shape[0]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
// 통과했다면, 크기를 기록해두고, return을 위한 ndArray를 생성한 뒤, buffer_info를 가져온다.
const int M = pufA.shape[0], N = pufB.shape[1], K = pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
// 가져온 각각의 buffer_info에서 실제 데이터가 저장된 주소를 가져온다.
// void* 형태로 시작 주소를 주기 때문에, float* 형태로 캐스팅
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
// 이제 포인터를 넘겨받았으니, 그대로 사용한다.
float *d_A = ptrA, *d_B = ptrB, *d_R = ptrR;
// 만약, 시스템 메모리 영역을 그대로 쓰지 못하는 디바이스라면(ex: VRAM 달린 그래픽카드)
// 직접 메모리 카피를 해준다.
if(!has_system_usm)
{
// 디바이스 메모리에 영역을 확보해준다.(꼭 free해주자.)
d_A = sycl::malloc_device<float>(M * K, q);
d_B = sycl::malloc_device<float>(K * N, q);
d_R = sycl::malloc_device<float>(M * N, q);
// 디바이스 메모리로 필요한 데이터를 복사해준다.
q.memcpy(d_A, ptrA, M * K * sizeof(float)).wait();
q.memcpy(d_B, ptrB, K * N * sizeof(float)).wait();
}
// 타일링을 위해 타일 크기를 지정해주고,
const int TILE = 16;
// coarsening을 위해 batch_size를 지정
const int BATCH = 4;
// q에 행렬 연산 작업을 제출해준 후,
q.submit([&](sycl::handler& h) {
// Tiling을 위한 local memory 할당
// A는 row vector, B는 column vector만 필요하므로,
// coarsening을 할 시, 한 쪽 차원으로만 늘려도 ok.
sycl::local_accessor<float, 2> tileA(sycl::range<2>(TILE*BATCH, TILE), h);
sycl::local_accessor<float, 2> tileB(sycl::range<2>(TILE, TILE*BATCH), h);
// coarsening으로 인해 전체 쓰레드의 수가 1 / (batch_size ^ 2) 로 감소함.
// 또한 TILE의 크기는 (batch_size)배가 된다.
// 한 스레드는 이제 (batch_size × batch_size) 영역을 커버하게 된다.
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M/BATCH, N/BATCH), sycl::range<2>(TILE, TILE)), [=](sycl::nd_item<2> item) {
// 우선 전체를 batch_size로 쪼개서 global id를 먼저 부여한 후,
const int r = item.get_global_id(0), c = item.get_global_id(1);
// 생성된 녀석들을 tile_size 단위로 묶어서 local id를 추가로 부여하는 방식.
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
// 따라서 global_id에 batch_size를 곱하면 자기가 담당하는 구역의 시작 인덱스가 구해짐.
// local_id는 좀 더 복잡한데, local_r은 A입장에서는 채워야 하는 로컬 메모리 영역의 행에 해당하고,
// B 입장에서는 batch_size를 곱해야 채워야할 entry들의 시작 행에 해당한다.
// local_c는 그 반대이다.
// NUM_TILES는 동일하다.
const int NUM_TILES = K / TILE;
// 외적값의 합을 저장할 배열을 생성 및 초기화
float sum[BATCH][BATCH];
for(int i=0; i<BATCH; ++i)
for(int j=0; j<BATCH; ++j)
sum[i][j] = 0;
// 한 타일씩 점프하는건 기존과 동일.
for(int t=0; t<NUM_TILES; ++t)
{
// 먼저 로컬 메모리부터 채운다.
// 이전과 달리 담당구역 전체를 채워야 하기 때문에 루프.
// 헷갈리면 안되는 부분이, TILE 크기 자체는 동일하기 때문에,
// K축(A의 열축, B의 행축. 이하 설명 생략.)으로 진행하는 속도는 기존과 똑같음.
// 즉 이 경우, 로컬 메모리의 형태가 정사각형이 아니다.
for(int i=0; i<BATCH; ++i)
{
// 인덱스 지옥 on.
// 그런데 까보면 그냥 기존에 하던 일을 수직/수평으로 확장한 것 뿐이다.
// 로컬 메모리의 크기가 K축에 수직인 방향으로만 늘어났기 때문에,
// 한 스레드 입장에서 채워야 할 메모리의 양은 BATCH배 밖에 안 늘었다.
tileA[local_r*BATCH+i][local_c] = d_A[(r*BATCH+i)*K + (local_c+TILE*t)];
tileB[local_r][local_c*BATCH+i] = d_B[(local_r+TILE*t)*N + (c*BATCH+i)];
}
// 동료들의 메모리 채우기를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
float regA[BATCH], regB[BATCH];
// K축으로 루프 시작
for(int k=0; k<TILE; ++k)
{
// 로컬메모리 -> 레지스터로 ( ,k) / (k, ) 벡터를 옮긴다.
for (int i=0; i<BATCH; ++i)
{
regA[i] = tileA[local_r*BATCH+i][k];
regB[i] = tileB[k][local_c*BATCH+i];
}
// 이제 오직 레지스터에만 접근하면서 외적을 계산할 수 있음!
for (int i=0; i<BATCH; ++i)
{
for(int j=0; j<BATCH; ++j)
{
sum[i][j] += regA[i] * regB[j];
}
}
}
// 동료들의 연산 종료를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
}
// 레지스터 -> 시스템 메모리로 정답을 돌려주면 끝.
for (int i=0; i<BATCH; ++i)
{
for(int j=0; j<BATCH; ++j)
{
d_R[(r*BATCH+i)*N + (c*BATCH+j)] = sum[i][j];
}
}
});
});
// 결과를 기다리고, res를 return하면 끝... 이 아니라 사용한 메모리를 반드시 free시켜준다.
q.wait();
if(!has_system_usm)
{
// d_R -> res로 정답 행렬 복사
q.memcpy(ptrR, d_R, M * N * sizeof(float)).wait();
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
return res;
}
PYBIND11_MODULE(sycl_mat, m) {
// 함수 자체를 노출시킴.
m.def("matmul", &matmul, "SYCL based Matrix Multiplication");
}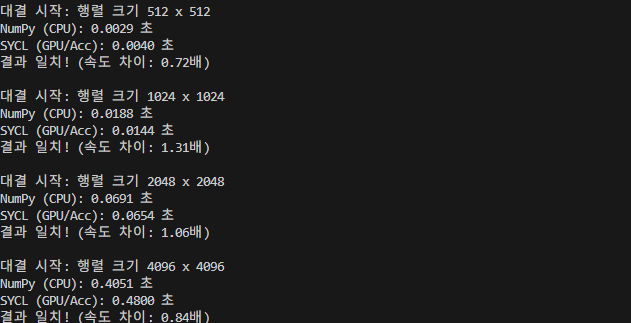
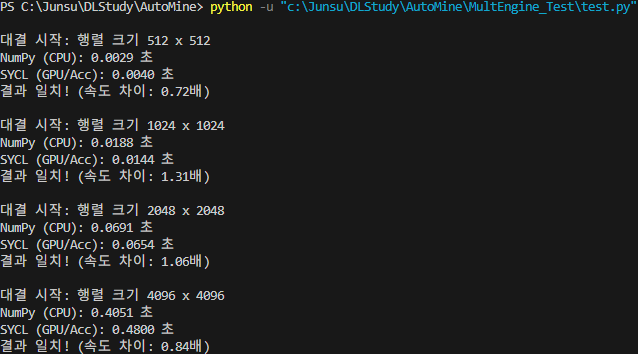
솔직히 별 기대 안했는데, iGPU 입장에서 생각보다 buffer/accessor라는 객체가 무거운 오버헤드였던 모양이다. 하지만, 아직 멀었다.
벡터화
이 개념에 대해서, 처음에는 "아, float를 하나씩 가져올걸 float4를 쓰면 4개씩 가져오니까, 메모리에 1/4번 접근하네? 와 그러면 엄청 빨라지는거 아니야?" 하고 단순하게 생각했는데, 실상은 그것보다 훨씬 복잡하다.
GPU는 여러 스레드가 병렬적으로 동작하도록 설계된 장치이기 때문에, 당연히 메모리 접근도 병렬적으로 하도록 만들어졌다. 따라서, 메모리 접근 요청이 발생할 때 마다 시스템 메모리와 스레드 사이의 머나먼 길을 왔다갔다 하는 것이 아니라, 일정 양의 메모리 접근 요청을 받아서 그 영역을 모두 포함하는 덩어리, 청크 단위로 데이터를 옮긴다. 청크는 당연히 연속된 메모리 공간을 뜯어오는 것이기 때문에, 요청받은 메모리 영역이 집적되어 있을수록 효율이 올라간다.
즉, 스레드들이 요청하는 메모리 공간의 영역이 정확히 딱 붙어있을수록 메모리 대역폭을 100%에 가깝게 활용할 수 있다는 말이다. 이렇게 여러 스레드가 한꺼번에 메모리와 소통하는 방식을 coalescing이라고 한다.
그런데 지금 상황을 한번 보자?
tileA[local_r*BATCH+i][local_c] = d_A[(r*BATCH+i)*K + (local_c+TILE*t)];
tileB[local_r][local_c*BATCH+i] = d_B[(local_r+TILE*t)*N + (c*BATCH+i)];이 상황을 이해하려면 스레드들이 움직이는 찰나의 순간을 멈춰놓고 봐야 한다. GPU의 스레드들은 똑같은 타이밍에 똑같은 명령어(i가 동일한 루프)를 실행한다. 이때 가로로 나란히 묶인 스레드 그룹(즉, local_r은 같고 local_c가 0, 1, 2...로 연속해서 증가하는 스레드들)이 정확히 어느 주소를 찌르고 있는지 확인해보자.(local_r이 같으면 r도 같고, local_c가 같으면 c도 같다는 사실을 기억하자.)
이 코드에서는 d_A와 d_B에 대한 접근을 요구하고 있다.
먼저 d_A의 인덱싱(... + local_c + ...)을 보자. 스레드 0번(local_c=0)이 주소 0을 찌를 때, 스레드 1번(local_c=1)은 주소 1을 찌른다. 즉, 스레드들이 나란히 붙어서 연속된 메모리를 요구하므로 coalescing이 완벽하게 일어난다.
반면 d_B의 인덱싱(... + c*BATCH + ...)은 다르다. BATCH가 4라고 할 때, 스레드 0번이 주소 0을 찌르는 순간, 바로 옆의 스레드 1번은 주소 4를 찌른다. 스레드들이 4칸씩 간격을 두고 듬성듬성 메모리를 요구하니, 메모리 컨트롤러 입장에서는 대역폭이 줄줄 새는 최악의 상황인 것이다.
이 문제를 해결하기 위해 투입할 소방수가 바로 vectorization으로, 루프를 돌리지 않고, 애초에 float를 BATCH개만큼 요구해 버리는 것이다. 이러면 중간중간 뚫려 있던 빈공간을 완전히 메워버리고 완벽한 coalescing이 가능하다. 명령어 실행 횟수가 줄어 오버헤드를 추가로 줄일 수 있다는 것도 장점이다.
그런데, tileA의 경우, row방향으로 인덱싱을 하고 있는데, 이러면 float4를 활용하기가 애매해 보인다. d_A는 1차원 배열이고, col방향으로 인덱싱을 하고 있기 때문이다.
여기서는 위에서 말했던 빈공간을 채운다는 개념이 아예 먹히지 않는다. 그래서 sycl은 아예 모든 스레드가 채워야 하는 메모리 영역을 1자로 편 다음, 순서대로 스레드에게 분배하는 방식을 제안한다. 자세한 부분은 코드에 주석으로 설명하겠다.
py::array_t<float> matmul(py::array_t<float> a, py::array_t<float> b)
{
// --- 위쪽 생략 ---
// float 배열을 float4 배열로 reinterpret. 사실 원래 float배열인데 float4로 보는 것이다.
sycl::float4* vec_A = reinterpret_cast<sycl::float4*>(d_A);
sycl::float4* vec_B = reinterpret_cast<sycl::float4*>(d_B);
// coarsening으로 인해 전체 쓰레드의 수가 1 / (batch_size ^ 2) 로 감소함.
// 또한 TILE의 크기는 (batch_size)배가 된다.
// 한 스레드는 이제 (batch_size × batch_size) 영역을 커버하게 된다.
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M/BATCH, N/BATCH), sycl::range<2>(TILE, TILE)), [=](sycl::nd_item<2> item) {
// 우선 전체를 batch_size로 쪼개서 global id를 먼저 부여한 후,
const int r = item.get_global_id(0), c = item.get_global_id(1);
// 생성된 녀석들을 tile_size 단위로 묶어서 local id를 추가로 부여하는 방식.
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
// (r-local_r) * BATCH를 하면 해당 워크 그룹의 최상단 행의 인덱스를 구할 수 있다. 열도 마찬가지.
// NUM_TILES는 동일하다.
const int NUM_TILES = K / TILE;
// 외적값의 합을 저장할 배열을 생성 및 초기화
float sum[BATCH][BATCH];
for(int i=0; i<BATCH; ++i)
for(int j=0; j<BATCH; ++j)
sum[i][j] = 0;
// 한 타일씩 점프하는건 기존과 동일.
for(int t=0; t<NUM_TILES; ++t)
{
// ---< 로컬 메모리 채우기 파트 >---
// 우선 모든 스레드를 일렬로 줄세운다. 이제 자신의 r, c는 중요하지 않고,
// 오직 local_r, local_c에 의존해서 채워야 하는 영역을 지정해준다.
// 따라서 이제 tileA도 가로로 채워진다.
const int tid = local_r * TILE + local_c;
// 데이터가 한 행에 TILE개 있으므로, 한 행을 맡는 스레드의 수는 (TILE/BATCH)개
const int load_A_r = tid / (TILE/BATCH);
const int load_A_c = tid % (TILE/BATCH);
// float4가 되면서 column의 수가 K/4로 줄어든 효과를 얻는다.
sycl::float4 chunk = vec_A[((r-local_r)*BATCH+ load_A_r) * (K/4) + (load_A_c + t*(TILE/4))];
// 이제 청크 -> 로컬 메모리로 내용 채우기
tileA[load_A_r][load_A_c*4] = chunk.x();
tileA[load_A_r][load_A_c*4+1] = chunk.y();
tileA[load_A_r][load_A_c*4+2] = chunk.z();
tileA[load_A_r][load_A_c*4+3] = chunk.w();
// B는 데이터가 한 행에 TILE*BATCH개 있으므로, 한 행을 맡는 스레드의 수는 TILE*BATCH/BATCH = (TILE)개
const int load_B_r = tid / TILE;
const int load_B_c = tid % TILE;
// 마찬가지로 column의 수를 1/4로 줄여준다.
chunk = vec_B[(load_B_r + t*TILE) * (N/4) + ((c-local_c)+load_B_c)];
// 로컬 메모리 채우기
tileB[load_B_r][load_B_c*4] = chunk.x();
tileB[load_B_r][load_B_c*4+1] = chunk.y();
tileB[load_B_r][load_B_c*4+2] = chunk.z();
tileB[load_B_r][load_B_c*4+3] = chunk.w();
// 동료들의 메모리 채우기를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
// ... 이하 연산 파트 동일
뭔가 여러 의미로 놀라운 결과인데, 1024×1024 구간만 압도적으로 퍼포먼스가 좋고, 나머지는 좀 밀리는 상태이다. 하지만 이것은 그야말로 스냅샷으로, 각각을 10번씩 시도해서 평균을 내 보자. 아래가 수정한 벤치마크 소스이다.
import os
import numpy as np
import time
intel_bin_path = r"C:\Program Files (x86)\Intel\oneAPI\compiler\latest\bin"
if os.path.exists(intel_bin_path):
os.add_dll_directory(intel_bin_path)
import sycl_mat
def benchmark(size, iterations=10):
print(f"\n대결 시작: 행렬 크기 {size} x {size} ({iterations}회 평균 측정)")
# --- Warm-up ---
A_warm = np.random.rand(size, size).astype(np.float32)
B_warm = np.random.rand(size, size).astype(np.float32)
res_np_warmup = np.dot(A_warm, B_warm)
res_sycl_warmup = sycl_mat.matmul(A_warm, B_warm)
if not np.allclose(res_np_warmup, res_sycl_warmup, atol=1e-3):
print("결과가 일치하지 않습니다. 로직 확인 필요.")
return
# --- NumPy 연산 ---
np_times = []
for _ in range(iterations):
A = np.random.rand(size, size).astype(np.float32)
B = np.random.rand(size, size).astype(np.float32)
start = time.perf_counter()
_ = np.dot(A, B)
end = time.perf_counter()
np_times.append(end - start)
avg_np_time = sum(np_times) / iterations
print(f"NumPy (CPU) 평균: {avg_np_time:.4f} 초")
# --- SYCL 연산 ---
sycl_times = []
for _ in range(iterations):
A = np.random.rand(size, size).astype(np.float32)
B = np.random.rand(size, size).astype(np.float32)
start = time.perf_counter()
_ = sycl_mat.matmul(A, B)
end = time.perf_counter()
sycl_times.append(end - start)
avg_sycl_time = sum(sycl_times) / iterations
print(f"SYCL (GPU/Acc) 평균: {avg_sycl_time:.4f} 초")
print(f"결과 일치! (속도 차이: {avg_np_time / avg_sycl_time:.2f}배)")
for s in [512, 1024, 2048, 4096]:
benchmark(s, iterations=10)
결과는 얼추 이런 느낌인데, 여기서 CPU의 속도는 일정하지 않고, 돌릴대마다 빨라졌다가 느려졌다가 했다. 하지만 gpu의 속도는 대충 저정도에 수렴했다. 여기서 알 수 있는 사실은 방금 1.89배라는 숫자가 나온 것도, GPU가 잘해서가 아니라, "CPU가 그때 잠깐 바빴어서"라는 결론을 내릴 수 있었다.
그렇다. 아직 부족하다.
더블 버퍼링
사실, GPU의 산술논리연산장치(ALU)와 Load/Store Unit(LSU)는 별개의 유닛이다. 즉, 서로 독립적으로 일한다. 따라서 LSU가 데이터를 가지러 메모리로 향한 동안 ALU가 연산을 수행하는 것이 가능하다. 그런데 지금의 코드를 잘 보면
// chunk를 vec_A에서 가져와서 그걸 로컬 메모리로 분배하는 부분이다.
// float4가 되면서 column의 수가 K/4로 줄어든 효과를 얻는다.
sycl::float4 chunk = vec_A[((r-local_r)*BATCH+ load_A_r) * (K/4) + (load_A_c + t*(TILE/4))];
// 이제 청크 -> 로컬 메모리로 내용 채우기
tileA[load_A_r][load_A_c*4] = chunk.x();
// ...이렇게 chunk를 가져오라는 명령을 내리자 마자 다음 코드에서 그 chunk의 내용물을 물어보기 때문에, 이렇게 발생한 의존성으로 코드가 앞으로 나아갈 수 없다. 그래서 지금의 코드는 ALU와 LSU를 독립적으로 굴리지 못하고, 서로가 서로를 기다리며 병목을 발생시키고 있다.
즉- 요점은, vec_A에서 chunk를 가져오는 코드와 가져온 chunk를 분해하는 로직 사이에 ALU가 일하는 코드를 넣으면 두 유닛이 서로를 기다리는 시간을 줄이고, 병목을 '숨길' 수 있게 된다. 두 유닛의 성능을 더욱 최선에 가깝게 끌어낼 수 있다는 것.
실제적인 구현은, 말 그대로 버퍼를 두 개 만드는 식으로 구현한다. 로컬 메모리 영역을 3차원으로 사용해서 페이지를 2개 만들고, 1페이지 로드 -> 1페이지 분배 -> 루프(-> 2페이지 로드 -> 1페이지 연산 -> 2페이지 분배 -> 1페이지 로드 -> 2페이지 연산 -> 1페이지 분배 ->) 이런 식으로 구현된다.
자세한 것은 아래의 실제 구현을 참조하자. 커널 부분만 수정했으므로 그 부분만 가져왔다.
q.submit([&](sycl::handler& h) {
// Tiling을 위한 local memory 할당
// double buffering을 위해 3차원으로 할당. (2 페이지)
sycl::local_accessor<float, 3> tileA(sycl::range<3>(2, TILE*BATCH, TILE), h);
sycl::local_accessor<float, 3> tileB(sycl::range<3>(2, TILE, TILE*BATCH), h);
// float 배열을 float4 배열로 reinterpret. 사실 원래 float배열인데 float4로 보는 것이다.
sycl::float4* vec_A = reinterpret_cast<sycl::float4*>(d_A);
sycl::float4* vec_B = reinterpret_cast<sycl::float4*>(d_B);
// coarsening으로 인해 전체 쓰레드의 수가 1 / (batch_size ^ 2) 로 감소함.
// 또한 TILE의 크기는 (batch_size)배가 된다.
// 한 스레드는 이제 (batch_size × batch_size) 영역을 커버하게 된다.
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M/BATCH, N/BATCH), sycl::range<2>(TILE, TILE)), [=](sycl::nd_item<2> item) {
// 우선 전체를 batch_size로 쪼개서 global id를 먼저 부여한 후,
const int r = item.get_global_id(0), c = item.get_global_id(1);
// 생성된 녀석들을 tile_size 단위로 묶어서 local id를 추가로 부여하는 방식.
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
// 타일의 총 개수는 K / TILE
const int NUM_TILES = K / TILE;
// tid 계산
const int tid = local_r * TILE + local_c;
// A는 데이터가 한 행에 TILE개 있으므로, 한 행을 맡는 스레드의 수는 (TILE/BATCH)개
const int load_A_r = tid / (TILE/BATCH);
const int load_A_c = tid % (TILE/BATCH);
// B는 데이터가 한 행에 TILE*BATCH개 있으므로, 한 행을 맡는 스레드의 수는 TILE*BATCH/BATCH = (TILE)개
const int load_B_r = tid / TILE;
const int load_B_c = tid % TILE;
// 외적값의 합을 저장할 배열을 생성 및 초기화
float sum[BATCH][BATCH];
for(int i=0; i<BATCH; ++i)
for(int j=0; j<BATCH; ++j)
sum[i][j] = 0;
// 현재 읽어야 하는 페이지
bool current_page = 0;
// 코드 중복을 위해 길다란 코드는 람다화. 이러면 나중에 청크 길이를 늘리거나 할 때도 편해짐.
auto split_A = [&](const bool &page, const sycl::float4 &chunk){
tileA[page][load_A_r][load_A_c*4] = chunk.x();
tileA[page][load_A_r][load_A_c*4+1] = chunk.y();
tileA[page][load_A_r][load_A_c*4+2] = chunk.z();
tileA[page][load_A_r][load_A_c*4+3] = chunk.w();
};
auto split_B = [&](const bool &page, const sycl::float4 &chunk){
tileB[page][load_B_r][load_B_c*4] = chunk.x();
tileB[page][load_B_r][load_B_c*4+1] = chunk.y();
tileB[page][load_B_r][load_B_c*4+2] = chunk.z();
tileB[page][load_B_r][load_B_c*4+3] = chunk.w();
};
// 우선 0페이지를 채워준다.
sycl::float4 chunk_A = vec_A[((r-local_r)*BATCH + load_A_r) * (K/4) + (load_A_c)];
sycl::float4 chunk_B = vec_B[(load_B_r) * (N/4) + ((c-local_c)+load_B_c)];
split_A(current_page, chunk_A);
split_B(current_page, chunk_B);
item.barrier(sycl::access::fence_space::local_space);
// 타일링 루프 시작
for(int t=0; t<NUM_TILES; ++t)
{
// ---< 연산 전에 미리 LSU에 chunk를 요청 > ---
if(t < NUM_TILES-1){
chunk_A = vec_A[((r-local_r)*BATCH + load_A_r) * (K/4) + (load_A_c + (t+1)*TILE/4)];
chunk_B = vec_B[(load_B_r + (t+1) * TILE) * (N/4) + ((c-local_c)+load_B_c)];
}
// ---< 연산 파트 > ---
float regA[BATCH], regB[BATCH];
// K축으로 루프 시작
for(int k=0; k<TILE; ++k)
{
// 로컬메모리 -> 레지스터로 ( ,k) / (k, ) 벡터를 옮긴다.
for (int i=0; i<BATCH; ++i)
{
regA[i] = tileA[current_page][local_r*BATCH+i][k];
regB[i] = tileB[current_page][k][local_c*BATCH+i];
}
// 이제 오직 레지스터에만 접근하면서 외적을 계산할 수 있음!
for (int i=0; i<BATCH; ++i)
{
for(int j=0; j<BATCH; ++j)
{
sum[i][j] += regA[i] * regB[j];
}
}
}
// ---< 가져온 청크를 분해해서 다음 페이지 생성> --
if(t < NUM_TILES-1){
current_page = !current_page; // 페이지 전환
split_A(current_page, chunk_A);
split_B(current_page, chunk_B);
}
// 동료들의 연산 종료를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
}
// 레지스터 -> 시스템 메모리로 정답을 돌려주면 끝.
for (int i=0; i<BATCH; ++i)
{
for(int j=0; j<BATCH; ++j)
{
d_R[(r*BATCH+i)*N + (c*BATCH+j)] = sum[i][j];
}
}
});
});결과...

이제 슬슬 넘파이를 거의 다 따라잡았다. 특히 원래 행렬 크기가 커질수록 점점 더 뒤쳐지던 현상이 있었는데, 이제는 오히려 행렬 크기가 일정 이상일 때 넘파이와 상대적으로 더 비슷한 퍼포먼스를 보인다.
마무리
이제야 겨우 넘파이에 손이 닿았다. 그런데, 솔직히 말하면 기대보다 훨씬 못한 성과이다. 나는 iGPU더라도 꼴에 GPU이니 CPU를 압도하는 성능을 내기를 기대했는데, 그러지 못하고 있다. 슬슬 이런 생각도 들기 시작했다. (NumPy와 비슷한 수준으로 속도가 수렴한다는 점이 이런 생각을 가속시켰다.)
이게 정말 내 문제인가? 그냥 시스템 메모리가 VRAM에 비해 너무 느리기 때문에 생기는 iGPU의 한계 아닐까?
그런 의미에서 다음 시간에는, 인텔 형님들이 만든 mkl의 gemm(GEneral Matrix Multiply)을 돌려보고, 정말 이게 내 문제인지(높은 확률로 그럴 것이지만) 알아볼 생각이다. 그러고 나서 내 문제가 맞다면, 추가적인 최적화를 진행해보자.
