도입
지난 시간에, 이런저런 최적화를 적용했음에도 성능이 넘파이와 비슷한 정도임을 확인하자, "어? 넘파이랑 비슷하게 수렴하네? 설마 메모리 한계에 부딪힌 건 아니겠지?"하는 의심을 해 버리고 말았다.
그래서, 사실상 내가 도달할 수 있는 한계라고 말할만한, 인텔이 직접 깎은 라이브러리인 mkl을 들고와서, 내가 한계의 몇 %정도까지 왔는지 점검해보고자 한다.
vs MKL
소스코드
USM을 사용해 메모리 영역을 디바이스로 넘기고, 해당 영역을 포인터로 제어하는 흐름 자체는 똑같다. 기존 코드에서 커널만 들어내서 mkl의 gemm으로 바꾼 셈이다.
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <sycl/sycl.hpp>
#include <oneapi/mkl.hpp> // 인텔 oneMKL 헤더
#include <stdexcept>
namespace py = pybind11;
py::array_t<float> mkl_matmul(py::array_t<float> a, py::array_t<float> b)
{
// 싱글턴 큐 유지 (기존 코드와 동일)
static sycl::queue q(sycl::default_selector_v);
static bool has_system_usm = q.get_device().get_info<sycl::info::device::usm_system_allocations>();
// 버퍼 정보 요청 및 차원/크기 검사 (기존 코드와 동일)
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: mkl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[1] != pufB.shape[0]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
const int M = pufA.shape[0], N = pufB.shape[1], K = pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
float *d_A = ptrA, *d_B = ptrB, *d_R = ptrR;
// USM 지원 여부에 따른 디바이스 메모리 할당 및 복사 (기존 코드와 동일)
if(!has_system_usm)
{
d_A = sycl::malloc_device<float>(M * K, q);
d_B = sycl::malloc_device<float>(K * N, q);
d_R = sycl::malloc_device<float>(M * N, q);
q.memcpy(d_A, ptrA, M * K * sizeof(float)).wait();
q.memcpy(d_B, ptrB, K * N * sizeof(float)).wait();
}
// ---< MKL 연산 파트 >---
try {
// oneapi::mkl::blas::row_major::gemm 호출
// 인자: queue, transA, transB, M, N, K, alpha, A, lda, B, ldb, beta, C, ldc
oneapi::mkl::blas::row_major::gemm(
q,
oneapi::mkl::transpose::nontrans,
oneapi::mkl::transpose::nontrans,
M, N, K,
1.0f, // alpha
d_A, K, // A의 선행 차원(lda)은 K
d_B, N, // B의 선행 차원(ldb)은 N
0.0f, // beta
d_R, N // C의 선행 차원(ldc)은 N
).wait(); // 연산이 끝날 때까지 대기
}
catch(sycl::exception const& e) {
// SYCL 비동기 에러 핸들링
throw std::runtime_error(std::string("oneMKL Exception: ") + e.what());
}
// 사용한 메모리 해제 및 복사 (기존 코드와 동일)
if(!has_system_usm)
{
q.memcpy(ptrR, d_R, M * N * sizeof(float)).wait();
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
return res;
}
PYBIND11_MODULE(mkl_mat, m) {
m.def("matmul", &mkl_matmul, "oneMKL based Matrix Multiplication via SYCL");
}코드가 훨씬 짧아진 모습. 내가 신나게 삽질해 놓은 것이 함수 한줄 띡으로 끝나니까, 어쩔 수 없이 씁쓸한 기분이 들지만, 이건 처음부터 알고 있던 사실이다.
참고로 gemm은 C = A@B가 아니라, C = alpha × (A@B) + beta × C 를 연산하기 때문에 alpha와 beta값은 각각 1.0, 0.0으로 넘겨주었고, lda, ldb, ldc는 행렬이 메모리 상에서 1차원으로 되어있기 때문에 한 행을 건너뛰려면 얼마를 더해야하는지 알려주는 변수이다(최적화 상황에 따라 그것이 행렬의 열 크기와 차이가 있을 수 있기 때문).
빌드
빌드는 CMakeLists.txt를 다음과 같이 수정한 후,
cmake_minimum_required(VERSION 3.14)
project(sycl_mat_project)
# 1. 파이썬과 pybind11 환경 찾기
find_package(Python COMPONENTS Interpreter Development REQUIRED)
find_package(pybind11 CONFIG REQUIRED)
# ---------------------------------------------------
# [타겟 1] 직접 최적화한 커스텀 SYCL 모듈
# ---------------------------------------------------
pybind11_add_module(sycl_mat sycl_mat.cpp)
# Intel DPC++ (SYCL) 전용 컴파일 옵션 붙이기
target_compile_options(sycl_mat PRIVATE -fsycl -O3)
target_link_options(sycl_mat PRIVATE -fsycl)
# ---------------------------------------------------
# [타겟 2] oneMKL 기반 SYCL 모듈 (새로 추가)
# ---------------------------------------------------
pybind11_add_module(mkl_mat mkl_mat.cpp)
# MKL을 쓰기 위해 핵심 플래그인 '-Qmkl'을 추가합니다.
target_compile_options(mkl_mat PRIVATE -fsycl -Qmkl -O3)
target_link_options(mkl_mat PRIVATE -fsycl -Qmkl)이전과 똑같은 방법으로 빌드했다. 자세한 사항은 #3 참고.
벤치마킹 결과
이후 test.py를 적절히 수정해서 벤치마킹을 돌려보았더니,
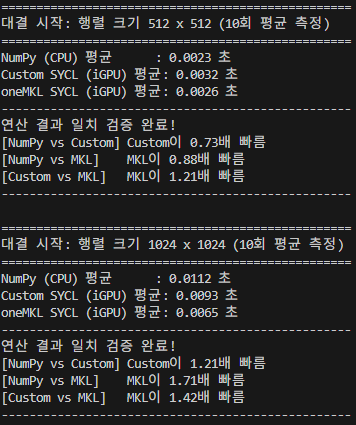
숫자가 작은 구간에서는 MKL 역시 오버헤드로 인해 고전하는 모습을 볼 수 있으나,
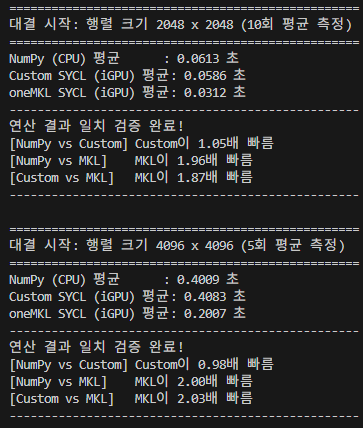
숫자가 큰 구간에서는 NumPy와 내 커스텀 커널을 압살하는 퍼포먼스를 보여준다. 대단하군.
빨판상어 메타
그런데 이건 기회이다! 모니터 프로그램으로 두 커널의 병목 지점을 분석하면, 도대체 내 커널이 mkl과 비교했을 때 어떤 부분에서 추가로 병목을 겪는지를 확인해 볼 수 있을 터였다.
그런 의미에서 intel의 VTune Profiler를 세팅해보자. 사실 세팅이라고 해도 별거 없는데,
- VTune Profiler를 켠다.
- 새 프로젝트를 생성한다.
- Configure Analasys에 들어가서 Application 부분에 python의 절대 경로를, Application parameters 부분에 테스트 코드(.py)의 절대 경로를 적는다.
- 원하는 분석 옵션을 고르고 실행버튼 누르면 끝!
그리하여 GPU 행렬 연산을 하는 그 순간만 필터링해서 그래프화 한것을 보았더니,
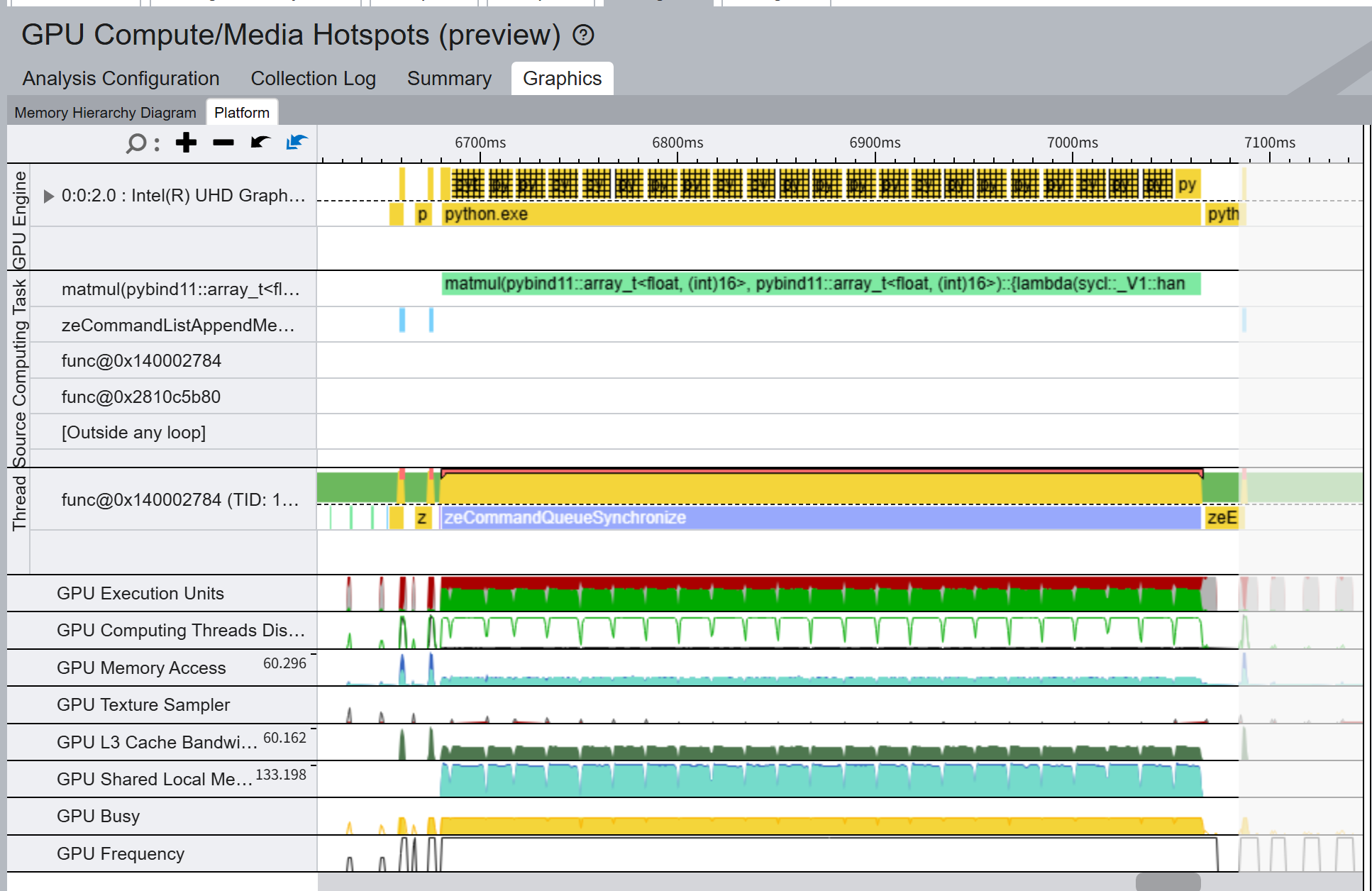
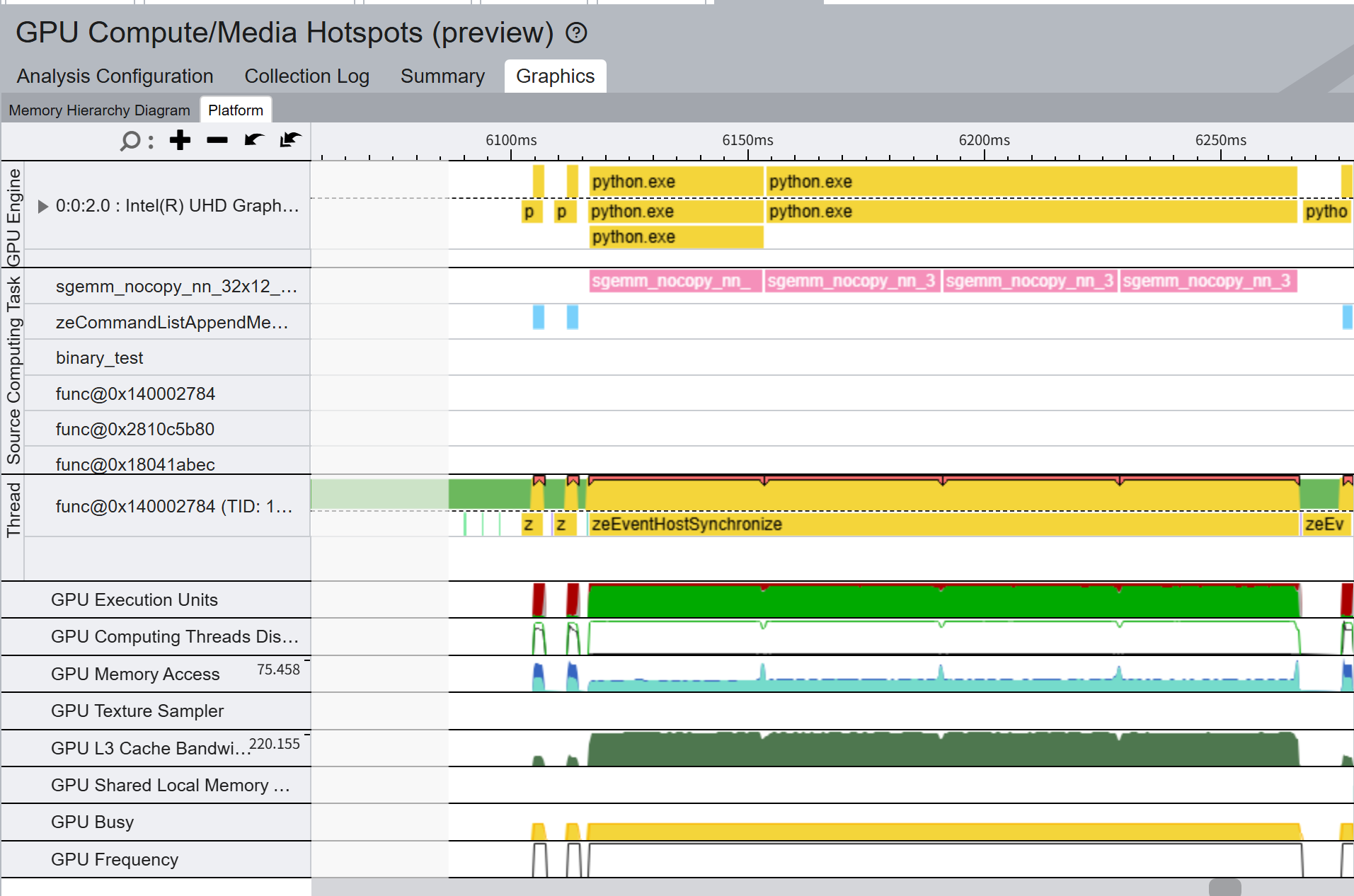
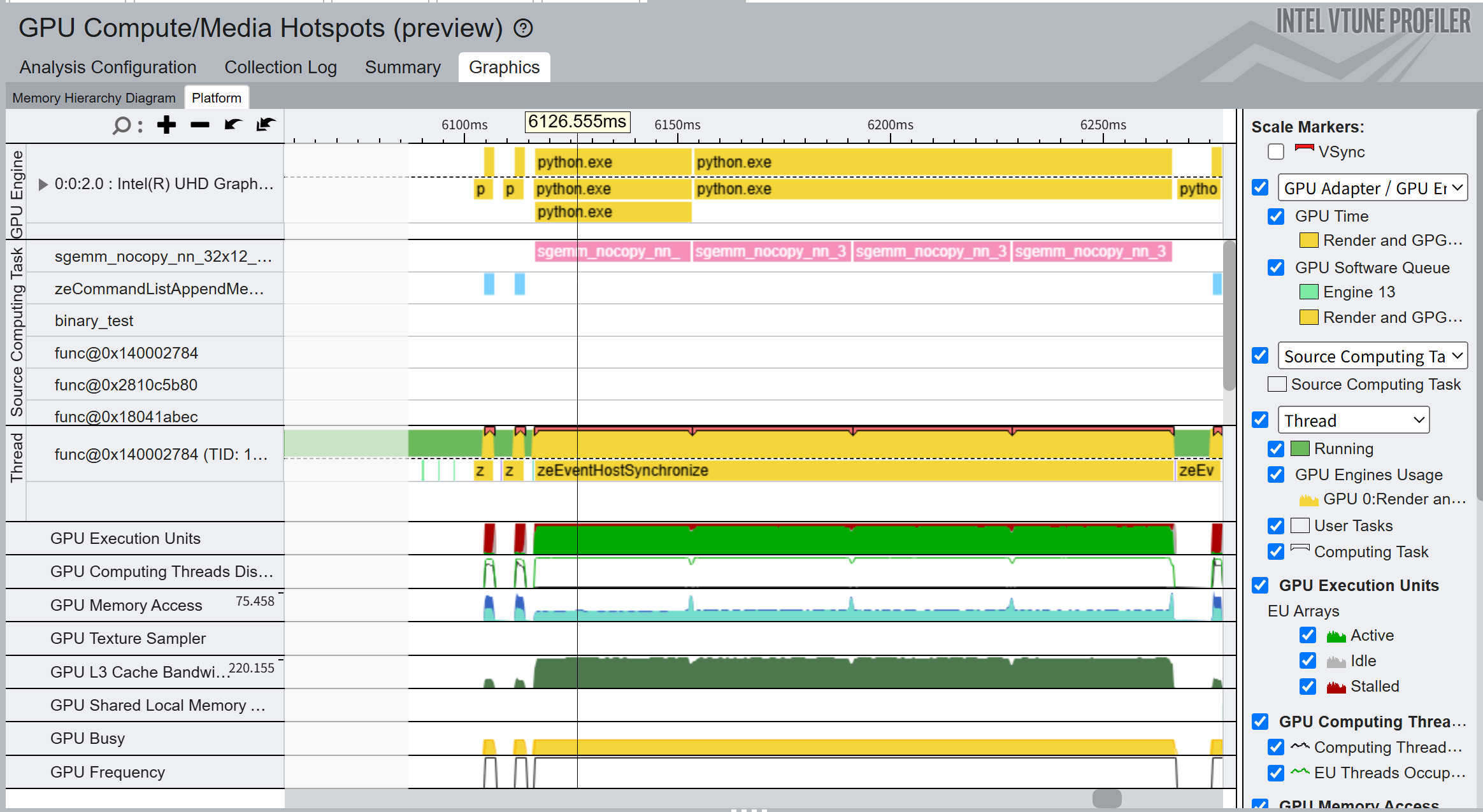
(위의 것이 내 커널, 아래 것이 mkl의 실행 결과이다.)
몇가지 차별점이 확 눈에 들어오는데,
- GPU 쪽에 넘어온 커널의 수가 내 경우에는 람다 함수 하나라고 표시되어 있는데, mkl은 sgemm_어쩌구가 4개. 즉, 커널을 4개로 나누어서 전달한 것이 보인다.
- GPU Execution Units 부분의 붉은 부분의 면적이 내 커널 쪽이 훨신 크다. 붉은 부분의 정체는 stalled 상태인 스레드로, 뭔가 작업을 받았지만 메모리를 기다리느라 일을 못하고있는 상태를 나타낸다.
- GPU 메모리에 대한 접근이 mkl 쪽이 2배정도 많다. 즉, mkl GPU 메모리를 더 많이 활용하고 있다. 또한 mkl에는 그 양이 2배정도로 늘어나는 스파이크가 4개정도 목격된다.
- L3 캐시의 대역폭이 mkl쪽이 압도적으로 크다. 응? 캐시???
응? 캐시라고?
잠깐. 캐시라고? GPU에도 캐시가 있다는 말인가? 지금까지 GPU에는 캐시 대신에 SLM(Shared Local Memory)이 있다고 생각했는데? 아니라고?
어... 그래서 Gemini 선생님한테 급하게 물어보니, 이런 답변을 주었다. 정말 의외인 대답이었고, 머리를 망치로 얻어맞은 기분... 이라기보다 중, 고등학교 올라가서 무리수, 복소수 등 초등학교 때 "존재하지 않음"으로 취급했던 수들을 알게 된 것과 비슷한 기분이었다.
GPU에도 캐시가 있다. L2 캐시라고 해서 코어들끼리 공유하는 캐시가 있고, L1 캐시라고 해서 하드웨어 쪽이 알아서 사용하는(프로그래머가 제어할 수 없는) 캐시가 있다.
그리고 하나의 코어는 여러개의 스레드로 이루어져 있는데, 같은 코어에 속한 스레드끼리 공유하는 메모리가 SLM이지 않은가? GPU에서는 바로 그 SLM이 사실은 L1 캐시의 파티션으로서 구현되어 있다.
그럼 우리가 아까 본 L3 캐시는 무엇일까? 사실 그 L3 캐시는 GPU의 것이 아니다. CPU의 것이다.
그렇다. 그러니까 iGPU는 CPU의 L3 캐시(제일 덩치가 큰 캐시)를 스스로의 L2 캐시인 것처럼 사용한다는 것이다. 터무니없는 반전이다.
응? 잠깐잠깐. 그러면 CPU의 캐시를 빌려 쓰는 mkl 쪽이, 코어별로 붙어있는 L1 캐시를 사용하는 내 커널보다 빠른게 이상하지 않나?
mkl은 무슨 요술을 부리는가
안 이상하다. 일단 mkl이 정확히 어떻게 돌아가는지 소스코드를 볼 수는 없지만, VTune이 분석한 결과를 훑어보면 얼추 mkl의 gemm을 돌릴 때 무슨 일이 일어나는지 짐작해 볼 수 있다. 단서는 아래와 같다.
-
커널의 상태: 커널 이름이 mkl_gemm 뭐 이런게 아니라, sgemm_nocopy_nn이라고 되어 있으며, 4개로 분열되어 있다. nocopy라는 말은 말 그대로, 시스템 메모리에서 SLM으로의 카피가 일어나지 않는다는 사실을 가리키는 것이라고 짐작되고(SLM의 대역폭이 말 그대로 0이다.), 커널이 4개로 나뉘어 있는 것으로 보아, 아마 내 CPU의 L3 캐시 크기를 고려해서 캐싱하기 적절한 사이즈로 나눈 것 같다.(정확하지는 않다.)
-
메모리 병목의 해소: 메모리 병목이 해소되었다는 사실 그 자체도 단서이다. Stalled에 해당하는 스레드 수가 훨씬 적은데, 즉? 이상한 마법을 부려서 연산속도를 올린게 아니라, 어떤 방법을 썼든, 메모리 액세스 타임 자체를 줄였다는 것이다.
-
내 커널의 L3 대역폭: 나는 캐시에 대해 전혀 아무것도 시킨게 없는데, 알아서 L3 캐시를 가져다 쓰고 있다. 즉, 실제로 GPU의 L2 캐시 역할을 L3가 하고 있다.(메모리와 SLM 사이의 캐시 역할)
-
tile 및 batch 크기: VTune을 통해, mkl이 내부에서 global_size, local_size를 어떻게 두고 있는지를 엿볼 수 있으며, SIMD width라는 정체불명의 수치가 8임을 알 수 있다. 찾아보니, 하드웨어가 한꺼번에 처리하는 명령의 단위 크기라고 하며, SIMD width가 8이면 8의 배수의 명령을 처리하기가 매우 수월하다 정도로 이해하면 될 것 같다.
종합하면, 어차피 행렬 연산을 위해 시스템 메모리에서 로컬 메모리로 데이터를 옮길 때, 반드시 L3를 지난다는 것. 그리고 mkl은 이 L3의 히트율을 무지막지하게 올린 다음(Tile 및 Batch 크기 조정, 커널 나누기 등), L1을 지나지 않고 그 데이터를 바로 레지스터에 꽂은 다음, 모종의 방법(일단 현 시점에서는 알 수 없다.)을 사용해 로컬 메모리에 정보를 복사하지 않고 레지스터끼리 직접 데이터를 교환하여 처리하는 것 같다.
그리고, 추가로 그래프가 저렇게 평평하다는 것은, 프리페칭을 잘만 활용하면(아마 배치 사이즈를 늘려서 연산장치가 메모리를 기다리는 시간을 없애면) 연산장치가 노는 일을 크게 줄일 수 있다는 걸 암시하는 것 같다.
그래서 내가 해야하는거? 간단한데, 그냥 세부 조정이다. 뭔가 거시적인 알고리즘을 추가하는게 아니라, Batch의 크기, Tile의 크기 등을 세부적으로 조정하면서 캐시 히트율이 높으며, SIMD width에 맞으며, 유효한 프리페칭이 가능한 범위의 상수를 찾아야 한다.
정정
나중에 intel VTune으로 내 iGPU를 까보고 안 사실인데, 내 iGPU는 L1캐시를 SLM으로 쓰는게 아니라, L3 캐시를 SLM으로 쓴다. 즉, 캐싱과 로컬 메모리의 대역이 동일하다. 역시 LLM은 곧이곧대로 믿을 수 없다(이전의 AutoMine 프로젝트의 교훈). 그래도 내가 해야할 일 자체는 그닥 변하지 않았는데, 세부 조정을 해야 한다.
마무리
이제 정말 내가 할 수 있는 부분에서는 끝이 다가오는 것 같다. 솔직히 이번 프로젝트 내내 내 하드웨어 지식의 짧음이 크게 느껴진다. 일단 얼추 지금 할 수 있는 범위의 일을 끝내면, 한동안은 하드웨어에 대해 이론적으로 공부를 하는 시간을 가져야 할 것 같다.
그런 의미에서 다음 시간에는 사실상 내가 취할 수 있는 마지막 수단, 현재 커널의 세부 조정을 해볼 시간이다. 솔직히 MKL을 이기는 것은 바라지도 않고, 30% 정도의 성능 개선만 얻어도 너무 기쁠 것 같다.
