도입
지난 시간까지는 행렬 곱셈 로직을 최적화하며, mkl과의 다소 의미없는 싸움을 해왔다. 표준 sycl만을 사용해서는 결국 mkl을 이기기는 커녕 가까이 따라붙는 것조차 힘들었다. 조금 찾아보니까, iGPU 전용 명령어들을 쓰면 L3에서 마치 SLM을 쓰는것처럼 브로드캐스팅을 한다거나, 레지스터들끼리 서로 데이터를 교환한다거나 하는 수법을 쓸 수 있는 것 같다. 그건 나중에 번외편이라도 파서 다룰 예정이다.
이번 시간에는 지하실에서 찾은 mkl이라는 무기를 활용해서, 학습을 돌리는 시간을 단축해볼 예정이다!
완전히 잘못 생각했다.
해야 하는 일은 간단했다. 우선 python을 intel OneAPI 환경에서 실행시킨다. 그 후, intel OneAPI의 dll들이 있는 디렉토리를 찾아 파이썬에게 알려준다. 그 다음, mkl_mat를 import해주고, np.dot() 자리에 mkl.matmul()을 넣으면 끝이다. 당장 해 보았더니...
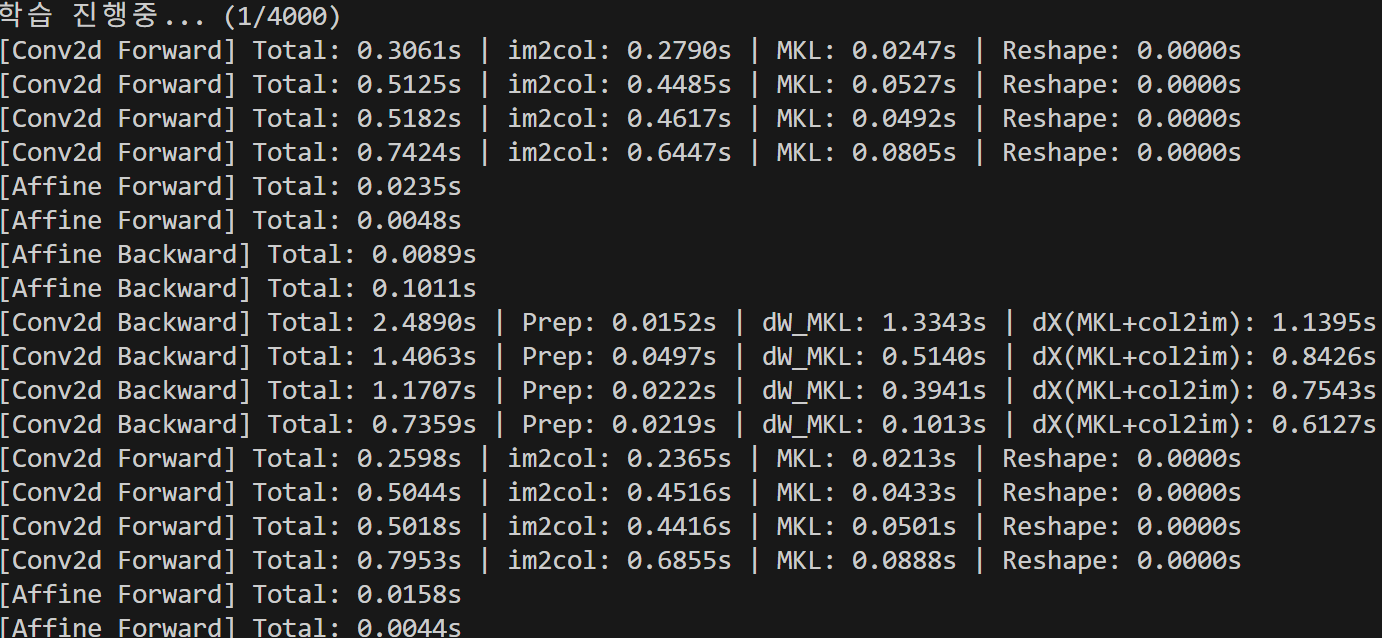
응? 어?
학습이 오래 걸린 원인이 행렬곱뿐만이 아니었다는 사실을 알게 되었다.
별 생각 없이 작성했던 im2col, col2im이 무시무시한 병목으로 작용하고 있었다. 말도 안 돼.
그래서? 이것을 내버려 둘 것인가? 안될 말씀이다. 오히려, 지금 이것을 찾아낸 것이 모델의 효율성 측면에서 지금까지 열심히 해온 행렬곱 최적화보다 중대한 사항이다.
그래서 이걸 어떻게 할 거냐고?
C++로 만든다.
답은 명쾌하다. 이것이 원본의 utils.py
import numpy as np;
# im2col 함수
def im2col(im, filter_h, filter_w, stride, pad):
N, C, H, W = im.shape
OH = (H+2*pad-filter_h)//stride + 1
OW = (W+2*pad-filter_w)//stride + 1
col = np.zeros((N*OH*OW, C*filter_h*filter_w))
padded = np.pad(im, ((0,0), (0,0), (pad, pad), (pad, pad)))
for i in range(N):
for y in range(OH):
for x in range(OW):
col[i * OH * OW + y * OW + x,:] = padded[i, :, y*stride:y*stride+filter_h, x*stride:x*stride+filter_w].reshape((1, C*filter_h*filter_w))
return col
# col2im 함수
def col2im(col, input_shape, filter_h, filter_w, stride, pad):
N, C, H, W = input_shape
OH = (H+2*pad-filter_h)//stride + 1
OW = (W+2*pad-filter_w)//stride + 1
# N, OH, OW, C, filter_h, filter_w
padded = np.zeros((N, C, H + 2*pad, W + 2*pad))
for i in range(N):
for y in range(OH):
for x in range(OW):
padded[i, :, y*stride:y*stride+filter_h, x*stride:x*stride+filter_w] += col[i * OH * OW + y * OW + x, :].reshape(C, filter_h, filter_w)
if pad == 0:
return padded
return padded[:, :, pad:-pad, pad:-pad]
보면 알겠지만, 그 느리기로 유명한 파이썬에서 3중 반복문을 돌리고 있다. 이걸 sycl 커널로 옮겨버릴 생각이다. 인덱싱을 할 때 자잘한 계산이 많은데, 병렬 처리를 통해 이를 가속할 수 있지 않을까 하는 노림수이다.
im2col
im2col은 인덱싱 구현이 좀 복잡하긴 하지만(2달만에 하니까 하나도 기억이 안 나서 좀 고생했다.), 기본적으로 맨 처음 만들었던 행렬 덧셈과 그닥 차이가 없으므로 소스만 올리고 넘어가겠다.
py::array_t<float> mkl_im2col(py::array_t<float> im, int FH, int FW, int stride, int pad) {
py::buffer_info pufIm = im.request();
int N = pufIm.shape[0];
int C = pufIm.shape[1];
int H = pufIm.shape[2];
int W = pufIm.shape[3];
int OH = (H + 2 * pad - FH) / stride + 1;
int OW = (W + 2 * pad - FW) / stride + 1;
// 결과 행렬 크기: (N*OH*OW, C*FH*FW)
py::array_t<float> col({N * OH * OW, C * FH * FW});
float* col_ptr = static_cast<float*>(col.request().ptr);
float* im_ptr = static_cast<float*>(pufIm.ptr);
float *d_im = im_ptr, *d_col = col_ptr;
if (!has_system_usm) {
d_im = sycl::malloc_device<float>(im.size(), q);
d_col = sycl::malloc_device<float>(col.size(), q);
q.memcpy(d_im, im_ptr, im.size() * sizeof(float)).wait();
}
int col_width = C * FH * FW;
q.submit([&](sycl::handler& h) {
h.parallel_for(sycl::range<1>(col.size()), [=](sycl::id<1> idx) {
int r = idx / col_width;
int c_idx = idx % col_width;
int n = r / (OH * OW);
int oy = (r / OW) % OH;
int ox = r % OW;
int c = c_idx / (FH * FW);
int fh = (c_idx / FW) % FH;
int fw = c_idx % FW;
// 실제 이미지 좌표 계산 (패딩 포함)
int y = oy * stride + fh - pad;
int x = ox * stride + fw - pad;
// 범위 체크 (패딩 영역은 0)
if (y >= 0 && y < H && x >= 0 && x < W) {
d_col[idx] = d_im[((n * C + c) * H + y) * W + x];
} else {
d_col[idx] = 0.0f;
}
});
}).wait();
if (!has_system_usm) {
q.memcpy(col_ptr, d_col, col.size() * sizeof(float)).wait();
sycl::free(d_im, q);
sycl::free(d_col, q);
}
return col;
}col2im
col2im은 데이터를 받아서, 인덱싱해서, 적절한 칸에 쏙 넣어주기만 하면 되는 im2col과는 묘하게 다른데, 여러 데이터가 한 칸에 더해지기 때문에, 동시성의 문제가 발생할 수 있다.
예를 들어, 스레드 a와 스레드 b가 모두 변수 V에서 값을 읽어 10을 더한 값을 다시 V에 가져다 놓는다는 작업을 동시에 수행할 때, 우리는 V의 초기값이 0이라면, 20이 되는 것을 기대하겠지만, 실제로는 a가 연산을 하는 동안 b가 데이터를 읽어서 둘 다 10+10을 하는 바람에 답이 20이 되어 버리는 상황이 발생할 수 있다.
그 상황을 막아주는 것이 바로 sycl의 atomic_ref로, 다른 녀석이 해당 자원을 사용하고 있다면, 사용이 끝날 때까지 같은 자원을 공유하는 스레드가 기다려준다는 간단한 기능이다. 이것으로 동시성 문제는 가볍게 해결된다. 소스코드는 아래와 같다. atomic_ref말고는 im2col과 대체로 비슷하다.
py::array_t<float> mkl_col2im(py::array_t<float> col, int N, int C, int H, int W, int FH, int FW, int stride, int pad)
{
int OH = (H + 2 * pad - FH) / stride + 1;
int OW = (W + 2 * pad - FW) / stride + 1;
int HP = H + 2 * pad; // Padded Height
int WP = W + 2 * pad; // Padded Width
py::array_t<float> res({N, C, HP, WP});
float* res_ptr = static_cast<float*>(res.request().ptr);
float* col_ptr = static_cast<float*>(col.request().ptr);
float *d_col, *d_res;
if(!has_system_usm) {
// 디바이스 메모리 할당
d_col = sycl::malloc_device<float>(col.size(), q);
d_res = sycl::malloc_device<float>(res.size(), q);
// 입력 복사 및 결과물 0 초기화 (필수!)
q.memcpy(d_col, col_ptr, col.size() * sizeof(float));
q.fill(d_res, 0.0f, res.size()).wait();
} else {
d_col = col_ptr;
d_res = res_ptr;
std::fill(d_res, d_res + res.size(), 0.0f);
}
// col 행렬의 가로 길이는 한 윈도우의 총 원소 수
int col_width = C * FH * FW;
q.submit([&](sycl::handler& h) {
// 행렬의 모든 원소(N*OH*OW * C*FH*FW)를 병렬 처리
h.parallel_for(sycl::range<1>(col.size()), [=](sycl::id<1> idx) {
// 행렬 상의 row, col 위치 계산
int r = idx / col_width;
int c_idx = idx % col_width;
// 윈도우 위치(n, oy, ox) 계산
int n = r / (OH * OW);
int oy = (r / OW) % OH;
int ox = r % OW;
// 필터 내 위치(c, fh, fw) 계산
int c = c_idx / (FH * FW);
int fh = (c_idx / FW) % FH;
int fw = c_idx % FW;
// 이미지 상의 실제 좌표 (Padding 포함 좌표)
int y = oy * stride + fh;
int x = ox * stride + fw;
// 1차원 인덱스로 변환하여 Atomic Add
int img_idx = ((n * C + c) * HP + y) * WP + x;
auto atm = sycl::atomic_ref<float, sycl::memory_order::relaxed,
sycl::memory_scope::device,
sycl::access::address_space::global_space>(d_res[img_idx]);
atm.fetch_add(d_col[idx]);
});
}).wait();
if(!has_system_usm) {
// 결과만 시스템 메모리로 가져오기
q.memcpy(res_ptr, d_res, res.size() * sizeof(float)).wait();
sycl::free(d_col, q);
sycl::free(d_res, q);
}
return res;
}Transpose 행렬곱 지원
마지막으로, 기왕 mkl을 쓰기로 한 거, transpose 기능까지 알뜰하게 써먹기로 했다. 이걸 쓰지 않을 경우, transpose한 행렬을 ascontiguousarray함수로 가공해서 넘겨야 하는데, 여기서 퍼포먼스에 피해가 가기 때문이다.
mkl이 자체적으로 transpose를 지원하기 때문에, 나는 차원만 잘 맞춰주면 되었다.
py::array_t<float> mkl_matmul(py::array_t<float> a, py::array_t<float> b, bool a_T, bool b_T)
{
// 버퍼 정보 요청 및 차원/크기 검사 (전치를 고려해서 검사)
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: mkl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[!a_T] != pufB.shape[b_T]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
// 전치 후의 size를 기준으로 하여 맞춘다.
const int M = a_T ? pufA.shape[1] : pufA.shape[0];
const int N = b_T ? pufB.shape[0] : pufB.shape[1];
const int K = a_T ? pufA.shape[0] : pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
float *d_A = ptrA, *d_B = ptrB, *d_R = ptrR;
// USM 지원 여부에 따른 디바이스 메모리 할당 및 복사 (기존 코드와 동일)
if(!has_system_usm)
{
d_A = sycl::malloc_device<float>(M * K, q);
d_B = sycl::malloc_device<float>(K * N, q);
d_R = sycl::malloc_device<float>(M * N, q);
q.memcpy(d_A, ptrA, M * K * sizeof(float)).wait();
q.memcpy(d_B, ptrB, K * N * sizeof(float)).wait();
}
// ---< MKL 연산 파트 >---
try {
// oneapi::mkl::blas::row_major::gemm 호출
// 인자: queue, transA, transB, M, N, K, alpha, A, lda, B, ldb, beta, C, ldc
// 선행 차원은 전치 이전의 것을 넘겨야 함.
oneapi::mkl::blas::row_major::gemm(
q,
a_T ? oneapi::mkl::transpose::trans : oneapi::mkl::transpose::nontrans,
b_T ? oneapi::mkl::transpose::trans : oneapi::mkl::transpose::nontrans,
M, N, K,
1.0f, // alpha
d_A, pufA.shape[1], // A의 선행 차원(lda). 전치 여부와 상관 없이 원본 K를 넘김
d_B, pufB.shape[1], // B의 선행 차원(ldb). 역시 전치 여부와 상관 없이 원본 N 넘기기.
0.0f, // beta
d_R, N // C의 선행 차원(ldc)은 N. 이건 전치 후를 기준으로 하는게 맞음.
).wait(); // 연산이 끝날 때까지 대기
}
catch(sycl::exception const& e) {
// 예외 발생 시 할당된 디바이스 메모리를 먼저 정리 (USM 미지원 환경)
if (!has_system_usm) {
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
// SYCL 비동기 에러 핸들링
throw std::runtime_error(std::string("oneMKL Exception: ") + e.what());
}
// 사용한 메모리 해제 및 복사 (기존 코드와 동일)
if(!has_system_usm)
{
q.memcpy(ptrR, d_R, M * N * sizeof(float)).wait();
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
return res;
}마무리
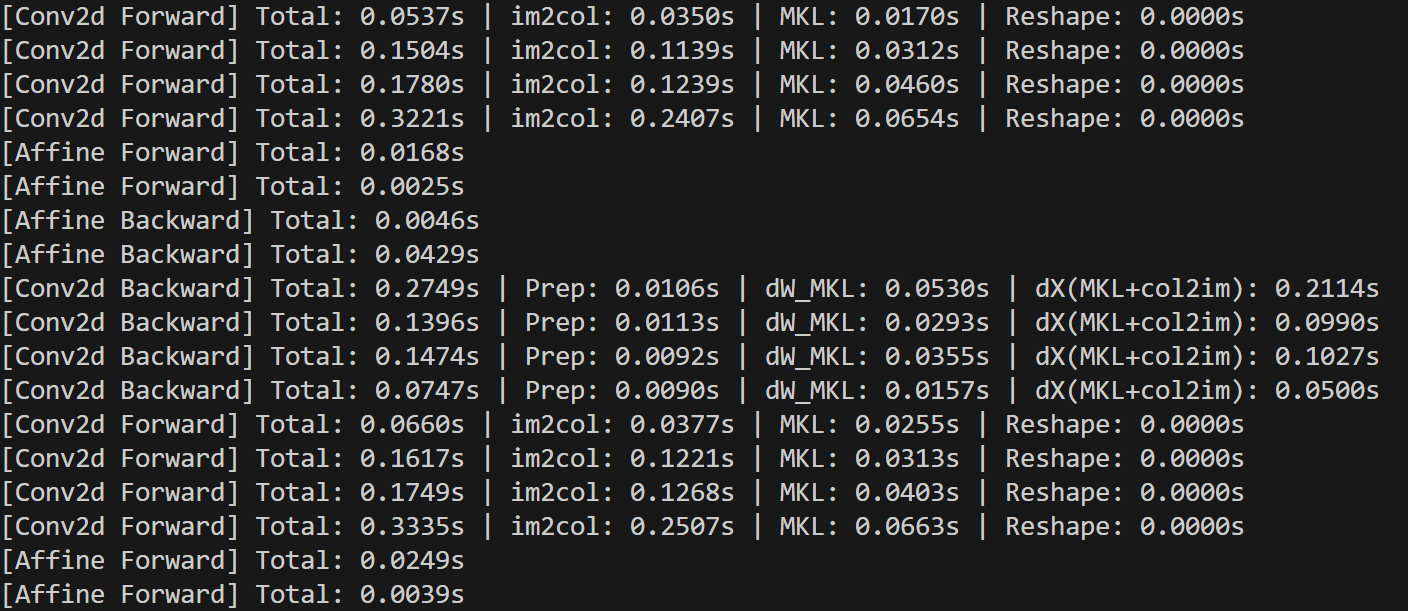
batch size 1000짜리 10×10×10 행렬 데이터로 1이터 학습시키는데에 9.5827sec -> 2.1725sec로 상당한 효과를 거두었다!
이렇게 되면, 모델을 학습시키는 속도가 올라가니, batch_size를 키우거나 iter수를 더욱 늘려 성능이 개선된 모델을 만들기 위한 선택지가 늘어난다.
밑바닥을 뚫고 지하실로 떠난 여정이 드디어 끝이 났다. 솔직히 힘들었지만, 그만큼 재미있었고, 사실 여기서 아예 끝낼 생각도 없다.
번외편으로 intel 내부 어셈블리를 사용해본다거나 하면서 소소하게 이어질 계획이고, 이번 프로젝트를 통해 절실하게 느낀 시스템 지식 부족을 채우기 위해, CS: APP를 매 주 조금씩 읽으며 읽은 부분을 요약해서 올릴 예정이다.
그걸 다 읽고 나면, 여기서 추가로 커널을 개선할 생각을 해볼 수 있을지도? 그런 의미에서 여기까지 읽어주신 분이 만약 계시다면, 재미없는 글 읽느라 고생하셨습니다.
감사합니다!
