도입
지난 시간에는 VTune을 활용한 mkl의 gemm과의 벤치마킹을 통해, 하드웨어적인 천장이 어느정도인지, 현재 내 커널의 어느 부분에서 병목이 나고 있는 것인지를 체크해 보았다.
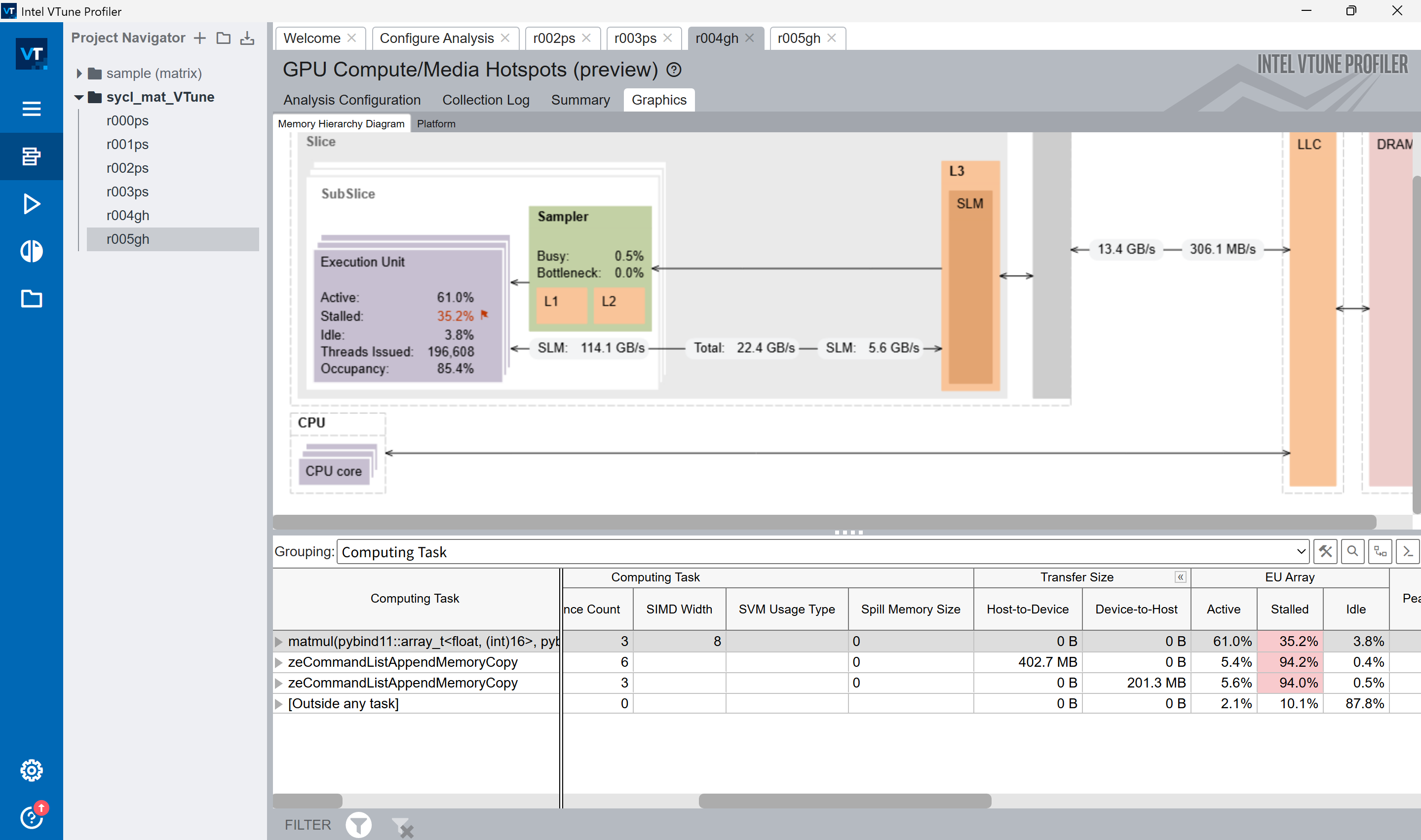
그리고 VTune을 통해 메모리의 계층구조도 까볼 수 있었는데, 충격적이게도 SLM이 하드웨어적으로 L3 안에 위치한다는 사실을 알아버렸다.(L1 아님!)
또한 CPU와 L3를 공유한다는것도 다 Gemini의 할루시네이션이었다. (다른 iGPU는 어떨지 몰라도) 잘 보면 LLC(Last Layer Cache)라고 해서 CPU의 마지막 캐시와 GPU의 L3 캐시가 따로 존재함을 알 수 있다. 아 물론, CPU와 LLC를 공유하긴 한다.
사실 어떻게 보면 Gemini가 대충 맞는 말을 한 것 같기도 하다. 이름이 틀려서 그렇지.
아무튼 어찌됐든 간에, 이전에 생각했던 대로 캐시 히트와 SLM의 대역폭을 최대화하는 상수값들을 찾는다는 내 목표가 바뀌지는 않았다.
직사각형 타일링
우선 상수 최적화를 위해, 행/열 방향 상수가 서로 다를 수 있는 환경을 만들어야 했다. 그런 김에, 필요한 상수들을 싹 전역 상수로 모아서 관리하기 편하게 만들었다. 그리고 float4, float8 이런 식으로 들어갔던 chunk의 자료형을 typedef로 관리하여 변경하기 쉽게 만들었다.
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <sycl/sycl.hpp>
#include <stdexcept>
namespace py = pybind11;
// float4를 8, 16 등으로 바꾸면 청크 크기 조절 가능. 단 CHUNK_SIZE도 같이 조정해야 함.
typedef sycl::float4 float_chunk;
const int CHUNK_SIZE = 4;
// 연산에 필요한 상수들
// 기본 상수
const int TILE_M = 16, TILE_N = 16, TILE_K = 16; // Tiling의 크기
const int BATCH_M = 4, BATCH_N = 4; // Coarsening의 크기
// 파생 상수
// 한 워크 그룹에 들어가는 스레드의 수 (안씀)
// const int GROUP_THREAD_COUNT = TILE_M * TILE_N;
// 한 행에 들어가는 스레드의 수는 Tile의 열 방향 크기 / CHUNK_SIZE
const int A_ROW_THREAD_COUNT = TILE_K / CHUNK_SIZE;
const int B_ROW_THREAD_COUNT = TILE_N * BATCH_N / CHUNK_SIZE;
// 타일을 다 채우기 위해 필요한 쓰레드의 수. GROUP_THREAD_COUNT보다 작거나 같아야 한다.
const int A_TILE_THREAD_COUNT = TILE_M * BATCH_M * A_ROW_THREAD_COUNT;
const int B_TILE_THREAD_COUNT = TILE_K * B_ROW_THREAD_COUNT;
py::array_t<float> matmul(py::array_t<float> a, py::array_t<float> b)
{
// 싱글턴 큐를 유지한다.
static sycl::queue q(sycl::default_selector_v);
static bool has_system_usm = q.get_device().get_info<sycl::info::device::usm_system_allocations>();
// 두 ndArray a, b를 받아서, 각각의 buffer_info를 python에 요청한다.
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
// 받은 buffer_info를 가지고 차원과 행렬의 크기를 검사한다.
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: sycl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[1] != pufB.shape[0]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
// 통과했다면, 크기를 기록해두고, return을 위한 ndArray를 생성한 뒤, buffer_info를 가져온다.
const int M = pufA.shape[0], N = pufB.shape[1], K = pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
// 가져온 각각의 buffer_info에서 실제 데이터가 저장된 주소를 가져온다.
// void* 형태로 시작 주소를 주기 때문에, float* 형태로 캐스팅
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
// 이제 포인터를 넘겨받았으니, 그대로 사용한다.
float *d_A = ptrA, *d_B = ptrB, *d_R = ptrR;
// 만약, 시스템 메모리 영역을 그대로 쓰지 못하는 디바이스라면(ex: VRAM 달린 그래픽카드)
// 직접 메모리 카피를 해준다.
if(!has_system_usm)
{
// 디바이스 메모리에 영역을 확보해준다.(꼭 free해주자.)
d_A = sycl::malloc_device<float>(M * K, q);
d_B = sycl::malloc_device<float>(K * N, q);
d_R = sycl::malloc_device<float>(M * N, q);
// 디바이스 메모리로 필요한 데이터를 복사해준다.
q.memcpy(d_A, ptrA, M * K * sizeof(float)).wait();
q.memcpy(d_B, ptrB, K * N * sizeof(float)).wait();
}
q.submit([&](sycl::handler& h) {
// Tiling을 위한 local memory 할당
// double buffering을 위해 3차원으로 할당. (2 페이지)
sycl::local_accessor<float, 3> tileA(sycl::range<3>(2, TILE_M*BATCH_M, TILE_K), h);
sycl::local_accessor<float, 3> tileB(sycl::range<3>(2, TILE_K, TILE_N*BATCH_N), h);
// float 배열을 float_chunk 배열로 reinterpret. 사실 원래 float배열인데 float_chunk로 보는 것이다.
float_chunk* vec_A = reinterpret_cast<float_chunk*>(d_A);
float_chunk* vec_B = reinterpret_cast<float_chunk*>(d_B);
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M/BATCH_M, N/BATCH_N), sycl::range<2>(TILE_M, TILE_N)), [=](sycl::nd_item<2> item) {
// 우선 전체를 batch_size로 쪼개서 global id를 먼저 부여한 후,
const int r = item.get_global_id(0), c = item.get_global_id(1);
// 생성된 녀석들을 tile_size 단위로 묶어서 local id를 추가로 부여하는 방식.
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
// 타일의 총 개수는 K / TILE_K
const int num_tiles = K / TILE_K;
// tid 계산 (이제 스레드를 일렬로 줄세운 후, 그대로 1차원 배열에 접근시킨다)
const int tid = local_r * TILE_N + local_c;
// 가져올 A와 B 청크의 global 좌표를 만들기 위한 base
const int base_a = (r-local_r)*BATCH_M;
const int base_b = (c-local_c)*BATCH_N/CHUNK_SIZE;
// 가져올 A와 B 청크의 local 좌표
const int load_a_r = tid/A_ROW_THREAD_COUNT;
const int load_a_c = tid%A_ROW_THREAD_COUNT;
const int load_b_r = tid/B_ROW_THREAD_COUNT;
const int load_b_c = tid%B_ROW_THREAD_COUNT;
// 외적값의 합을 저장할 배열을 생성
float sum[BATCH_M][BATCH_N] = {};
// 현재 읽어야 하는 페이지
bool current_page = 0;
// 가져온 청크를 해체하는 함수.
auto split_A = [&](const bool &page, const float_chunk &chunk){
#pragma unroll
for(int i=0; i<CHUNK_SIZE; ++i) tileA[page][load_a_r][load_a_c*CHUNK_SIZE+i] = chunk[i];
};
auto split_B = [&](const bool &page, const float_chunk &chunk){
#pragma unroll
for(int i=0; i<CHUNK_SIZE; ++i) tileB[page][load_b_r][load_b_c*CHUNK_SIZE+i] = chunk[i];
};
// 우선 0페이지를 채워준다.
float_chunk chunk_A, chunk_B;
if(tid < A_TILE_THREAD_COUNT)
{
chunk_A = vec_A[(base_a + load_a_r) * (K / CHUNK_SIZE) + load_a_c];
split_A(current_page, chunk_A);
}
if(tid < B_TILE_THREAD_COUNT)
{
chunk_B = vec_B[load_b_r * (N/CHUNK_SIZE) + (base_b + load_b_c)];
split_B(current_page, chunk_B);
}
item.barrier(sycl::access::fence_space::local_space);
// 타일링 루프 시작
for(int t=0; t<num_tiles; ++t)
{
// ---< 연산 전에 미리 LSU에 chunk를 요청 > ---
if(t < num_tiles-1){
if(tid < A_TILE_THREAD_COUNT) chunk_A = vec_A[(base_a + load_a_r) * (K/CHUNK_SIZE) + (load_a_c + (t+1)*TILE_K/CHUNK_SIZE)];
if(tid < B_TILE_THREAD_COUNT) chunk_B = vec_B[(load_b_r + (t+1)*TILE_K) * (N/CHUNK_SIZE) + (base_b + load_b_c)];
}
// ---< 연산 파트 > ---
float regA[BATCH_M], regB[BATCH_N];
// K축으로 루프 시작
#pragma unroll
for(int k=0; k<TILE_K; ++k)
{
// 로컬메모리 -> 레지스터로 ( ,k) / (k, ) 벡터를 옮긴다.
#pragma unroll
for (int i=0; i<BATCH_M; ++i) regA[i] = tileA[current_page][local_r*BATCH_M+i][k];
#pragma unroll
for (int i=0; i<BATCH_N; ++i) regB[i] = tileB[current_page][k][local_c*BATCH_N+i];
// 이제 오직 레지스터에만 접근하면서 외적을 계산할 수 있음!
#pragma unroll
for (int i=0; i<BATCH_M; ++i)
{
for(int j=0; j<BATCH_N; ++j)
{
sum[i][j] += regA[i] * regB[j];
}
}
}
// ---< 가져온 청크를 분해해서 다음 페이지 생성> --
if(t < num_tiles-1){
current_page = !current_page; // 페이지 전환
if(tid < A_TILE_THREAD_COUNT) split_A(current_page, chunk_A);
if(tid < B_TILE_THREAD_COUNT) split_B(current_page, chunk_B);
}
// 동료들의 연산 종료를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
}
// 레지스터 -> 시스템 메모리로 정답을 돌려주면 끝.
for (int i=0; i<BATCH_M; ++i)
{
for(int j=0; j<BATCH_N; ++j)
{
d_R[(r*BATCH_M+i)*N + (c*BATCH_N+j)] = sum[i][j];
}
}
});
});
// 결과를 기다리고, res를 return하면 끝... 이 아니라 사용한 메모리를 반드시 free시켜준다.
q.wait();
if(!has_system_usm)
{
// d_R -> res로 정답 행렬 복사
q.memcpy(ptrR, d_R, M * N * sizeof(float)).wait();
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
return res;
}
PYBIND11_MODULE(sycl_mat, m) {
// 함수 자체를 노출시킴.
m.def("matmul", &matmul, "SYCL based Matrix Multiplication");
}이 코드의 가장 큰 특징은, 한 그룹의 모든 스레드들을 일렬로 줄세우고, TileA와 TileB를 1차원 공간인 것 처럼 간주한 다음, 일렬로 줄 세운 스레드에게 앞에서부터 chunk를 하나씩 쥐어주며 Tile을 채우도록 한 설계이다. 따라서 스레드의 수×청크의 크기보다 TileA 혹은 TileB의 크기가 작다면, 일부는 chunk를 받지 않고 그냥 패스한다.
주의할 점은 스레드의 수×청크의 크기보다 타일의 크기가 커서는 안된다는 점과, TILE_K가 chunk_size보다 크거나 같아야 한다는 점이다.(div by 0 이슈)
아무튼 이 코드를 바탕으로 계속 값을 대입해서 시도해 본 결과
세부 조정
#include <pybind11/pybind11.h>
#include <pybind11/numpy.h>
#include <sycl/sycl.hpp>
#include <stdexcept>
namespace py = pybind11;
// float8을 4, 16 등으로 바꾸면 청크 크기 조절 가능. 단 CHUNK_SIZE도 같이 조정해야 함.
typedef sycl::float8 float_chunk;
const int CHUNK_SIZE = 8;
// 연산에 필요한 상수들
// 기본 상수
const int TILE_M = 16, TILE_N = 16, TILE_K = 8; // Tiling의 크기
const int BATCH_M = 8, BATCH_N = 4; // Coarsening의 크기
// 파생 상수
// 한 워크 그룹에 들어가는 스레드의 수 (안씀)
// const int GROUP_THREAD_COUNT = TILE_M * TILE_N;
// 한 행에 들어가는 스레드의 수는 Tile의 열 방향 크기 / CHUNK_SIZE
const int A_ROW_THREAD_COUNT = TILE_K / CHUNK_SIZE;
const int B_ROW_THREAD_COUNT = TILE_N * BATCH_N / CHUNK_SIZE;
// 타일을 다 채우기 위해 필요한 쓰레드의 수. GROUP_THREAD_COUNT보다 작거나 같아야 한다.
const int A_TILE_THREAD_COUNT = TILE_M * BATCH_M * A_ROW_THREAD_COUNT;
const int B_TILE_THREAD_COUNT = TILE_K * B_ROW_THREAD_COUNT;
py::array_t<float> matmul(py::array_t<float> a, py::array_t<float> b)
{
// 싱글턴 큐를 유지한다.
static sycl::queue q(sycl::default_selector_v);
static bool has_system_usm = q.get_device().get_info<sycl::info::device::usm_system_allocations>();
// 두 ndArray a, b를 받아서, 각각의 buffer_info를 python에 요청한다.
py::buffer_info pufA = a.request();
py::buffer_info pufB = b.request();
// 받은 buffer_info를 가지고 차원과 행렬의 크기를 검사한다.
if(pufA.ndim != 2 || pufB.ndim != 2){
throw std::runtime_error("Dimension Error: sycl_mat is made only for 2-dim matrices.");
}
if(pufA.shape[1] != pufB.shape[0]){
throw std::runtime_error("Size Error: Sizes of the matrices are not suitable.");
}
// 통과했다면, 크기를 기록해두고, return을 위한 ndArray를 생성한 뒤, buffer_info를 가져온다.
const int M = pufA.shape[0], N = pufB.shape[1], K = pufA.shape[1];
py::array_t<float> res({M, N});
py::buffer_info pufR = res.request();
// 가져온 각각의 buffer_info에서 실제 데이터가 저장된 주소를 가져온다.
// void* 형태로 시작 주소를 주기 때문에, float* 형태로 캐스팅
float* ptrA = static_cast<float*>(pufA.ptr);
float* ptrB = static_cast<float*>(pufB.ptr);
float* ptrR = static_cast<float*>(pufR.ptr);
// 이제 포인터를 넘겨받았으니, 그대로 사용한다.
float *d_A = ptrA, *d_B = ptrB, *d_R = ptrR;
// 만약, 시스템 메모리 영역을 그대로 쓰지 못하는 디바이스라면(ex: VRAM 달린 그래픽카드)
// 직접 메모리 카피를 해준다.
if(!has_system_usm)
{
// 디바이스 메모리에 영역을 확보해준다.(꼭 free해주자.)
d_A = sycl::malloc_device<float>(M * K, q);
d_B = sycl::malloc_device<float>(K * N, q);
d_R = sycl::malloc_device<float>(M * N, q);
// 디바이스 메모리로 필요한 데이터를 복사해준다.
q.memcpy(d_A, ptrA, M * K * sizeof(float)).wait();
q.memcpy(d_B, ptrB, K * N * sizeof(float)).wait();
}
q.submit([&](sycl::handler& h) {
// Tiling을 위한 local memory 할당
// double buffering을 위해 3차원으로 할당. (2 페이지)
sycl::local_accessor<float, 3> tileA(sycl::range<3>(2, TILE_M*BATCH_M, TILE_K), h);
sycl::local_accessor<float, 3> tileB(sycl::range<3>(2, TILE_K, TILE_N*BATCH_N), h);
// float 배열을 float8 배열로 reinterpret. 사실 원래 float배열인데 float8로 보는 것이다.
float_chunk* vec_A = reinterpret_cast<float_chunk*>(d_A);
float_chunk* vec_B = reinterpret_cast<float_chunk*>(d_B);
h.parallel_for(sycl::nd_range<2>(sycl::range<2>(M/BATCH_M, N/BATCH_N), sycl::range<2>(TILE_M, TILE_N)), [=](sycl::nd_item<2> item) {
// 우선 전체를 batch_size로 쪼개서 global id를 먼저 부여한 후,
const int r = item.get_global_id(0), c = item.get_global_id(1);
// 생성된 녀석들을 tile_size 단위로 묶어서 local id를 추가로 부여하는 방식.
const int local_r = item.get_local_id(0), local_c = item.get_local_id(1);
// 타일의 총 개수는 K / TILE_K
const int num_tiles = K / TILE_K;
// tid 계산 (이제 스레드를 일렬로 줄세운 후, 그대로 1차원 배열에 접근시킨다)
const int tid = local_r * TILE_N + local_c;
// 가져올 A와 B 청크의 global 좌표를 만들기 위한 base
const int base_a = (r-local_r)*BATCH_M;
const int base_b = (c-local_c)*BATCH_N/CHUNK_SIZE;
// 가져올 A와 B 청크의 local 좌표
const int load_a_r = tid/A_ROW_THREAD_COUNT;
const int load_a_c = tid%A_ROW_THREAD_COUNT;
const int load_b_r = tid/B_ROW_THREAD_COUNT;
const int load_b_c = tid%B_ROW_THREAD_COUNT;
// 외적값의 합을 저장할 배열을 생성
float sum[BATCH_M][BATCH_N] = {};
// 현재 읽어야 하는 페이지
bool current_page = 0;
// 가져온 청크를 해체하는 함수.
auto split_A = [&](const bool &page, const float_chunk &chunk){
#pragma unroll
for(int i=0; i<CHUNK_SIZE; ++i) tileA[page][load_a_r][load_a_c*CHUNK_SIZE+i] = chunk[i];
};
auto split_B = [&](const bool &page, const float_chunk &chunk){
#pragma unroll
for(int i=0; i<CHUNK_SIZE; ++i) tileB[page][load_b_r][load_b_c*CHUNK_SIZE+i] = chunk[i];
};
// 우선 0페이지를 채워준다.
float_chunk chunk_A, chunk_B;
if(tid < A_TILE_THREAD_COUNT)
{
chunk_A = vec_A[(base_a + load_a_r) * (K / CHUNK_SIZE) + load_a_c];
split_A(current_page, chunk_A);
}
if(tid < B_TILE_THREAD_COUNT)
{
chunk_B = vec_B[load_b_r * (N/CHUNK_SIZE) + (base_b + load_b_c)];
split_B(current_page, chunk_B);
}
item.barrier(sycl::access::fence_space::local_space);
// 타일링 루프 시작
for(int t=0; t<num_tiles; ++t)
{
// ---< 연산 전에 미리 LSU에 chunk를 요청 > ---
if(t < num_tiles-1){
if(tid < A_TILE_THREAD_COUNT) chunk_A = vec_A[(base_a + load_a_r) * (K/CHUNK_SIZE) + (load_a_c + (t+1)*TILE_K/CHUNK_SIZE)];
if(tid < B_TILE_THREAD_COUNT) chunk_B = vec_B[(load_b_r + (t+1)*TILE_K) * (N/CHUNK_SIZE) + (base_b + load_b_c)];
}
// ---< 연산 파트 > ---
float regA[BATCH_M], regB[BATCH_N];
// K축으로 루프 시작
#pragma unroll
for(int k=0; k<TILE_K; ++k)
{
// 로컬메모리 -> 레지스터로 ( ,k) / (k, ) 벡터를 옮긴다.
#pragma unroll
for (int i=0; i<BATCH_M; ++i) regA[i] = tileA[current_page][local_r*BATCH_M+i][k];
#pragma unroll
for (int i=0; i<BATCH_N; ++i) regB[i] = tileB[current_page][k][local_c*BATCH_N+i];
// 이제 오직 레지스터에만 접근하면서 외적을 계산할 수 있음!
#pragma unroll
for (int i=0; i<BATCH_M; ++i)
{
for(int j=0; j<BATCH_N; ++j)
{
sum[i][j] += regA[i] * regB[j];
}
}
}
// ---< 가져온 청크를 분해해서 다음 페이지 생성> --
if(t < num_tiles-1){
current_page = !current_page; // 페이지 전환
if(tid < A_TILE_THREAD_COUNT) split_A(current_page, chunk_A);
if(tid < B_TILE_THREAD_COUNT) split_B(current_page, chunk_B);
}
// 동료들의 연산 종료를 기다린다.
item.barrier(sycl::access::fence_space::local_space);
}
// 레지스터 -> 시스템 메모리로 정답을 돌려주면 끝.
for (int i=0; i<BATCH_M; ++i)
{
for(int j=0; j<BATCH_N; ++j)
{
d_R[(r*BATCH_M+i)*N + (c*BATCH_N+j)] = sum[i][j];
}
}
});
});
// 결과를 기다리고, res를 return하면 끝... 이 아니라 사용한 메모리를 반드시 free시켜준다.
q.wait();
if(!has_system_usm)
{
// d_R -> res로 정답 행렬 복사
q.memcpy(ptrR, d_R, M * N * sizeof(float)).wait();
sycl::free(d_A, q);
sycl::free(d_B, q);
sycl::free(d_R, q);
}
return res;
}
PYBIND11_MODULE(sycl_mat, m) {
// 함수 자체를 노출시킴.
m.def("matmul", &matmul, "SYCL based Matrix Multiplication");
}얼추 최적의 조건을 찾았다. 속도는
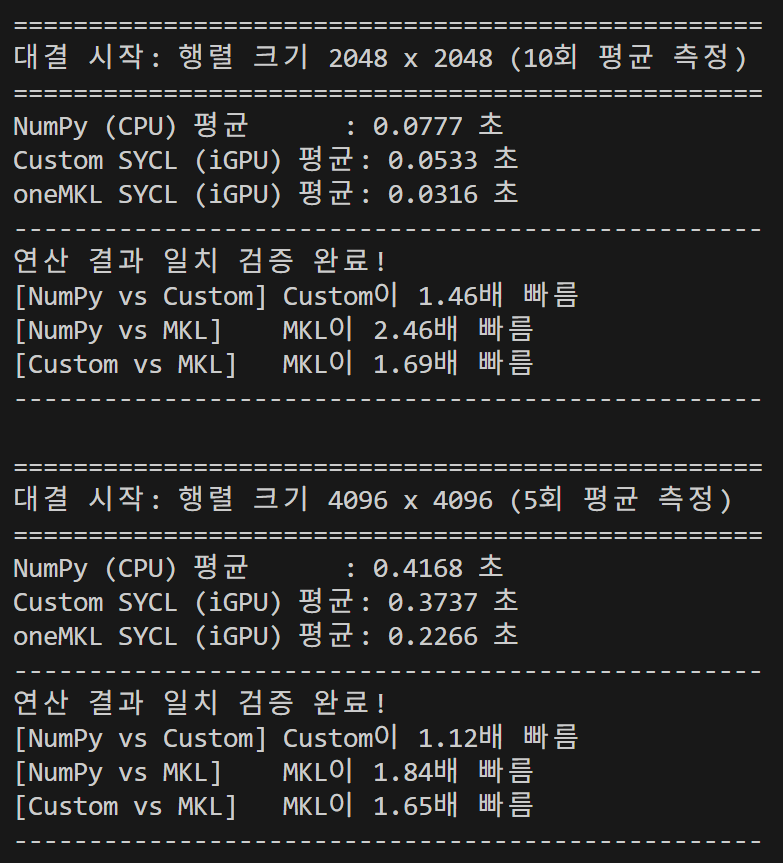
얼추 이 정도.
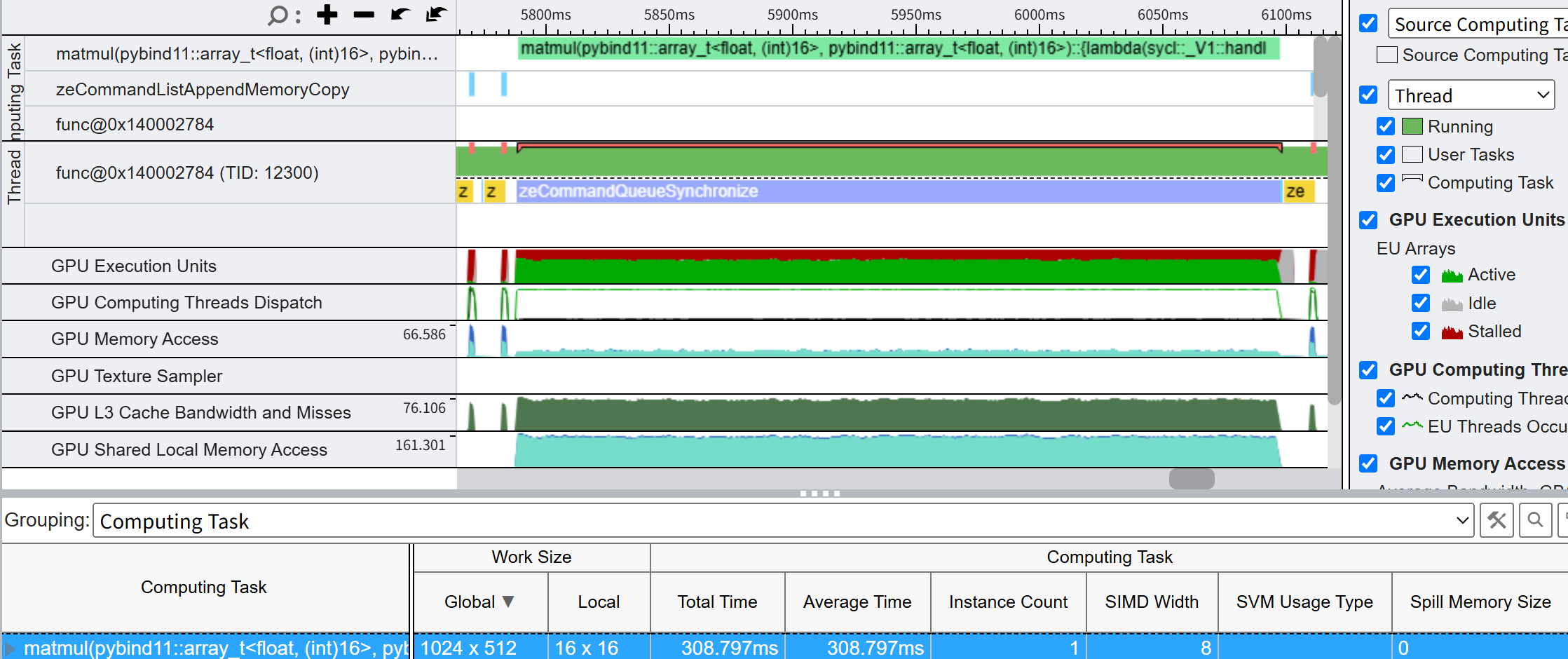
VTune으로 모니터링 하면 이런 느낌이다. Stalled 비율은 약 30% 정도. 8×4가 최적인 이유는, 워크 그룹의 특성 때문인 것 같다. GPU에서 SLM으로 데이터를 요청할 때, 스레드 몇 개의 요청을 묶어서 보내게 되는데, 여기서 이 스레드들은 연속된 local_c 값을 가지고 있기 때문에 local_r이 동일하고, 따라서 A 행렬의 데이터를 얻을 때는 모두가 같은 데이터를 원하는 셈이 된다. 그런데 SLM은 이렇게 같은 데이터를 원하는 녀석들에게 데이터를 뿌려줄 때 브로드캐스팅을 통해 빠른 속도를 낼 수 있기 때문에 A 행렬의 데이터를 가져올 때는 엄청나게 빠르다.
대신 B 행렬의 데이터를 가져올 때는, 서로 다른 주소에서 데이터를 뽑아오기 때문에(local_c는 다르니까) A 행렬에서 데이터를 뽑아올 때보다 오래 걸린다. 이 말은 곧, 한번 가져올 때 B보다 A에서 더 많이 가져와도 병목이 없다는 뜻이고, 즉 A가 클수록 속도 면에서 이득을 본다는 뜻인데, 아쉽게도 A를 8보다 더 크게 만들면 레지스터 스필이 일어나 다시 느려진다.(넓이가 같은 직사각형은 두 변의 길이 차이가 좁을수록 둘레가 짧아진다.)
마무리
사실 내가 이번 시간에 겪은 시행착오에 비해 포스팅 자체는 매우 짧게 끝났다. 그래도 이번 작업을 통해 속도가 많이 올랐다. 0.4초대에서 0.3초대로 들어왔으니까. 한 50ms정도 줄인 것 같다. 일단 내가 sycl만 가지고 줄일 수 있는 곳은 한계가 온 것 같다. 현 시점에서 L3 대역폭과 SLM 대역폭을 합치면 230GB/s 정도로, mkl이 L3 단독으로 내는 수치와 거의 근접했다.
즉, 이 이상 뭔가를 할 수는 있기는 할텐데 미미하며, 여기서 기록을 더 줄이려면 컴파일러랑 싸우거나 인텔의 내부 어셈블리 명령어를 써야 할 것 같다. 이 부분은, AutoMine++ 프로젝트에서는 직접적으로 다루지는 않겠다. 아마 번외편으로 포스트가 올라갈 것이다.
그럼 다음 시간에는? 잊고 있었지만, 이 프로젝트, 사실 딥러닝을 위한 프로젝트로, 슬슬 항복하고 MKL의 gemm을 사용한 커널을 파이썬에 연결하고자 한다.
엥? 그럼 나는 아무 의미 없는 삽질을 한 것 아닐까? 어차피 MKL 쓸거면, 도대체 왜 sycl로 행렬곱 만드느라 시간을 낭비했나?
어... 솔직히 틀린 말은 아닌데, 그래도 내가 이렇게 박치기를 하면서 MKL의 대단함을 체감하지 않았다면, "애걔? (내장)그래픽카드를 썼는데 NumPy보다 2배밖에 안 빠르네? 뭔가 이상한 거 아냐?"하고 생각하지 않았을까? 사실은 NumPy도 무진장 빠른 것이며, iGPU는 VRAM의 부재, CPU와의 캐시 공유 등 온갖 패널티를 가지고 있다는 사실을 몰랐을 테니까. 그래서 결국 또 이상한 삽질을 하는 결과로 이어졌을 것이다.
한 마디로, 결국 프로그램을 만드는 것은 사람이라는 것이다. 아무리 정답에 가까운 코드를 짜더라도 만든 녀석이 그것이 정답이라고 확신하지 못한다면 결국 삽질을 하게 된다. 삽질 보존의 법칙이다.
약간 억지스러운 정당화이긴 하지만, 아무튼 후회는 없다. 다음 시간에는 신경망으로 다시 돌아가보도록 하자!
