Dataset Shift
학습/테스트 데이터의 feature 또는 타겟값의 분포가 다른 상황을 말한다.
- Covariate Shfit
- Prior Probability Shfit
- Concept Shfit
Covariate Shift
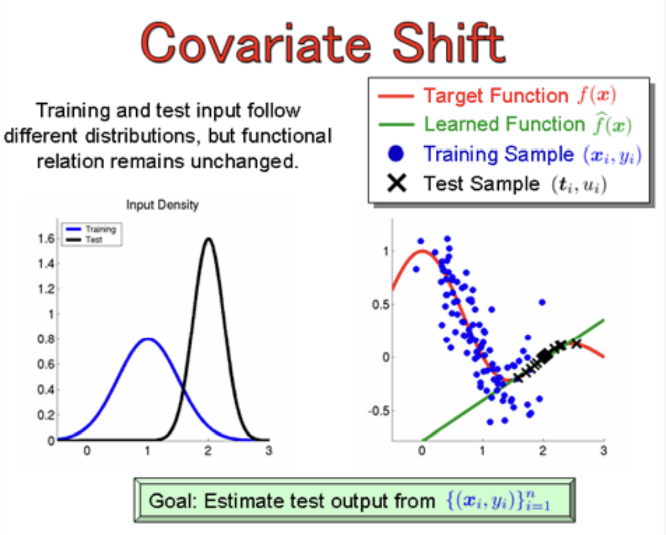
독립변수들 간의 공변량(covariate)의 분포가 변화하는 현상을 말한다. 표본의 대표성 문제와 관련되어있다고 생각해도 좋을 것 같다. 전체 데이터셋의 분포를 잘 반영하는 학습/테스트 셋이 아니기 때문에, 표본의 대표성이 떨어진다고 볼 수 있다고 생각한다. 크게 Sample Section Bias 또는 Non-stationary Environmetns 두 가지 원인이 있다
Sample Selection Bias
데이터 수집 과정에서 모집단의 분포처럼 균일하게 선택하지 못하여 발생하는 경우
Non-stationary Environments
학습 환경과 테스트 환경과 다른 경우. 시간/공간의 변화로 인해서 발생될 수 있다.
Prior Probability Shift
covariate shift가 x변수의 분포에 관한 것이라면, prior probability shfit는 y의 분포와 관련있다. y의 분포가 불균형이 있을때, 즉 unbalanced dataset인 경우가 대표적이다
Concept Shift
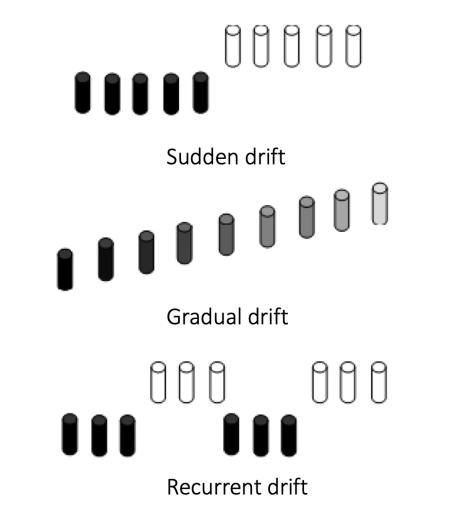
입력 feature와 레이블의 관계가 변화한 경우로, 시간의 흐름에 의존적인 경우에 발생되기 쉽다. 변화 양상에 따라 gradual, sudden, recurrent 세 가지가 있다.
-
Gradual Concept Drift
시간에 따라 점진적으로 발생하는 concept drift로 경제적 변화가 대표적이다. -
Sudden Concept Drift
Covid-19와 같이 큰 이벤트로 인해 전/후의 concept이 변하는 경우 -
Recurrent Concept Drift
주기적으로 발생하는 concept drift. 대표적으로 계절에 따라 어떤 성격이 주기적으로 변하는 경우가 되겠다.
Concept drift를 대처하기 위해서는 모델 배포 후에 지속적인 모니터링이 필요하다.
- Online learning : 새로운 데이터가 들어올 때마다 지속적으로 모델을 업데이트하는 방법. batch learning과 상반되는 방식
- Periodically re-train : 주기적인 재학습
- Re-sampling using instance selection : 데이터의 분포를 고려하여 의도적인 샘플링을 통해 모집단의 대표성을 유지하는 방법
- Ensemble learning with model weighting: 여러 모델의 결과를 합산하여 일반화 성능을 향상시킴
- Feature dropping : 개별 피쳐당 하나의 모델을 여러개 만들어 AUC-ROC를 모니터하며 concept drift를 유발하는 피쳐를 삭제
