Semi & Self Supervised Learning
Supervised Learning의 한계
지도학습은 정답이 정해져 있는 데이터를 기반으로 패턴을 학습한다. 그 결과, 보여지지 않은 데이터에 대해서는 일반적으로 성능이 떨어진다. 높은 일반화 성능을 위해서는 많은 양의 labeled 데이터가 요구된다. 하지만 다량의 labeled 데이터를 구하기 어려운 상황도 많다. 라벨링에 시간이 너무 많이 요구되는 경우도 있고, 좋은 품질의 학습데이터를 구하기 위하여 전문적인 라벨링 기술이 필요한 경우도 있다. labeled data가 적은 경우에는 labeled data의 분포가 진짜 데이터의 분포 전체를 커버하지 못할 수도 있기 때문에 학습데이터에는 없는 새로운 테스트 데이터가 들어왔을 때 잘 맞추지 못할 가능성이 크다.
Semi-supervised Learning
비교적 적은 양의 labeled 데이터와 많은 양의 unlabeled 데이터가 있다면 semi-supervised learning(준지도학습)을 적용해 볼 수 있다. labeled 데이터에는 supervised learning을 적용하고, unlabeled 데이터에는 unsupervised learning을 적용하는 방법이다. labeled 되지 않은 데이터로부터 특징을 잘 추출할 수 있다면, labeled 데이터로부터 약간의 가이드를 받아 일반화 성능을 올릴 수 있다.
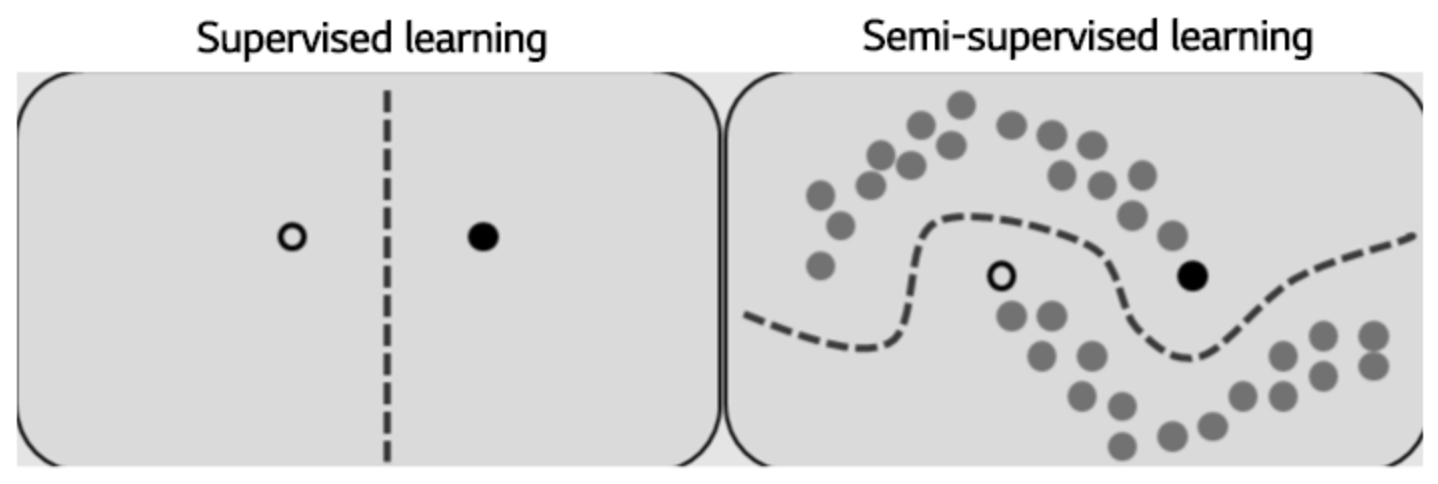
Semi-supervised learning의 목적함수는 supervised loss Ls 와 unsupervised loss Lu의 합을 최소화하는 것으로 표현할 수 있다. 그 말인즉슨 supervised, unsupervised를 1-stage로 한큐에 학습한다. 이것이 2-stage로 이루어지는 self-supervised learning, transfer learning 등과의 차이점이다.
소량의 labeled data에 적용하는 supervised loss의 경우 target이 discrete value인지 continuous value인지에 따라 classification loss/regression loss를 선택하여 학습하면 된다. 그리고 대용량 unlabeled data는 unsupervised loss를 주어 데이터의 특성에 대해 학습하게 된다. 여기서 unlabeled data에 주는 unsupervised task를 어떻게 정할 것이냐에 따라 방법론이 나뉘게 된다. 이는 semi-supervised learning의 일반적인 가정을 먼저 살펴본 후에 자세히 설명하도록 하겠다.
Semi-supervised Learning의 전제조건
- The Smoothness Assumption :
만약 데이터 포인트 와 가 고밀도 지역에서 가까이 위치하다면, 해당하는 출력 와도 가까워야한다.
이는 같은 class에 속하고 같은 cluster인 두 입력이 입력공간 상에서 고밀도 지역에 위치하고 있다면, 해당하는 출력도 가까워야한다는 것을 의미한다. 반대도 역시 성립하는데, 만약 두 데이터포인트가 저밀도지역에서 멀리 위치한다면, 해당하는 출력도 역시 멀어야 한다. 이러한 가정은 분류 문제엔 도움이 되는 가정이지만 회귀에선 별로 도움이 안된다.
- The Cluster Assumption :
만약에 데이터 포인트들이 같은 cluster에 있다면, 그들은 같은 class일 것이다.
이 가정이 성립한다면 하나의 cluster는 하나의 class를 나타낼 것이고 이를 통해 decision boundary는 저밀도지역을 통과해야만 한다라고 말할 수 있다.
- The Manifold Assumption :
고차원의 데이터를 저차원 manifold로 보낼 수 있다.
고차원의 공간상에서 generative task를 위한 진짜 data distribution은 추정하기 어렵다. 또한 discriminative task에서도 고차원에서는 class간의 distance가 거의 유사하기 때문에 분류하기 어렵다. 그러나 만약 데이터를 더 낮은 차원으로 보낼 수 있다면 우리는 unlabeled 데이터를 사용해서 저차원 표현을 얻을 수 있고 labeled 데이터를 사용해 더 간단한 task를 풀 수 있다.
- Entropy minimization
- Proxy-label method
- Generative models
- Consistency regularization (Consistency training)
- Holistic methods
- Graph-based methods
