Loss Functions and Optimization
- SVM loss(hinge loss)
:- : 정답이 아닌 class의 score
- : 정답 class의 score
📌 정답 class - 오답 class > safety margin(이 경우 1) 인 경우 loss 가 0
📌 위의 조건이 아니면, 정답이 아닌 class() - 정답 class() + 1(safety margin)의 값이 loss

 개구리를 잘 분류했는지 SVM loss를 계산해보면,
개구리를 잘 분류했는지 SVM loss를 계산해보면,
max(0, 2.2 - (-3.1) + 1) + max(0, 2.5 - (-3.1) + 1)
= max(0, 6.3) + max(0, 6.6)
= 12.9
 최종 loss는 이 세 가지의 loss 들을 평균내면 된다.
최종 loss는 이 세 가지의 loss 들을 평균내면 된다.
-
Q1. 만약 자동차의 score가 0.5만큼 감소하면 loss에는 어떤 일이 발생하는지?
: 그래도 여전히 loss 는 0SVM loss(hinge loss) 의 특성: score 값 그 자체에 관심이 있는 것이 아니라 다른 클래스보다 높은지에만 관심이 있다.
-
Q2. SVM loss 의 가능한 min/max 값은?
: min:0, max: ∞ -
Q3. 만약 W를 0에 가까운 값에 초기화한다면, N 개의 sample과 C 개의 class가 있을 때 loss 는?
: 에서 와 는 0에 가까운 값일 것이기 때문에 1에 가까운 값이 C-1번 더해지게 되므로 C-1 -
Q4. W가 매우 작아져서 score가 0에 근사해지면?
: max(0, 0-0+1) + max(0, 0-0+1) = 2 가 되고,
cat, car, frog -> (2 + 2 + 2) / 3 = 2 즉, loss는 C-1 (sanity check) 👉 eㅣ버그 용으로 많이 사용
-
Q5. 정답 class 값을 제외시키지 않고 계산하면?
: max(0, 5.1-3.2+1) + max(0, -1.7-3.2+1) + max(0, 3.2-3.2 + 1)
👉 loss가 1만큼 증가
👉 최종 loss(평균값) 이 1만큼 증가하게 된다. -
Q6. 를 사용하면?
: 결과가 달라진다, 그 이유는 제곱을 하면 non-linear 해지기 때문
👉 squared hinge loss 라고 부름
직선이 아니라 곡선으로 제곱승으로 올라가기 때문에 ‘매우매우 안좋다’, ‘매우매우 좋다’를 따질 때 유용
그런데, 만일 인 를 발견했다고 했을 때, 이 는 unique 한 값일까?
그렇다고 볼 수 없다! 위의 예시에서 W에 2배를 해줘도 여전히 L = 0 이기 때문이다.  즉, W는 unique한 값이 아니라 여러 개가 될 수 있다. 그렇게 된다면 현재 W가 train set에 맞춰져 있는데, 이것이 test set에 W가 잘 맞춰진다는 보장이 없다(overfitting이 발생할 가능성) 우리가 원하는 것은 새로운 data에 대해서 예측을 더 잘하고 싶은 것이다..
즉, W는 unique한 값이 아니라 여러 개가 될 수 있다. 그렇게 된다면 현재 W가 train set에 맞춰져 있는데, 이것이 test set에 W가 잘 맞춰진다는 보장이 없다(overfitting이 발생할 가능성) 우리가 원하는 것은 새로운 data에 대해서 예측을 더 잘하고 싶은 것이다..
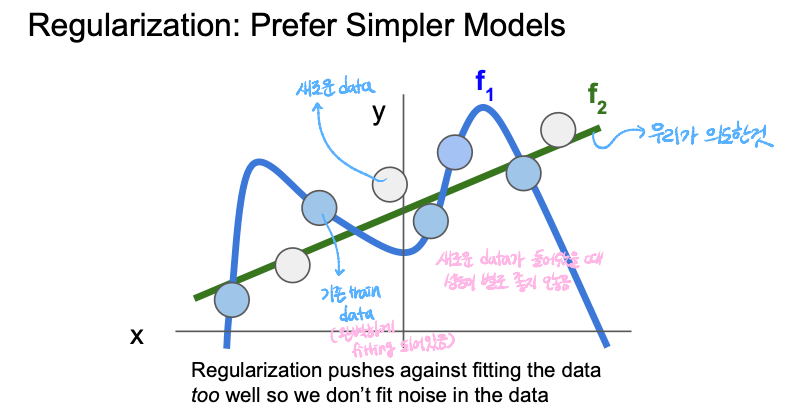
Regularization(λR(W))
: 모델이 좀 더 단순한 W를 선택하도록 도와준다
- λ: regularization strength (hyperparameter)
- 머신러닝에서 차수가 깊어지면 깊어질수록 차원의 저주가 걸리게 됨으로 차원이 깊어지지 않도록(다항식이 커지지 않도록) 방지
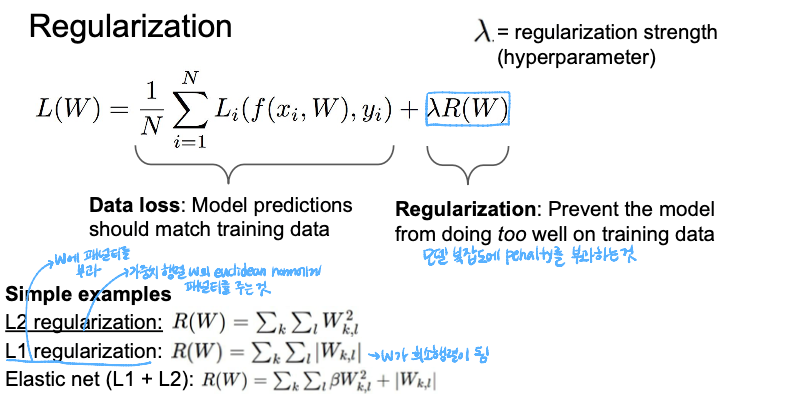
- L1 regularization: 통상적으로 값을 빼준다. 작은 가중치는 0으로 수렴하게 되고, 결론적으로 중요한 가중치만 남게 된다. 그래서 의미 있는 값을 원하면 L1을 사용하는 것이 좋음
- L2 regularization: 가중치를 0에 가깝도록 유도하고, 데이터를 spread해준다. 그래서 모든 데이터 값을 고려해준다.


- 일반적으로 L1 보다 L2를 많이 사용한다고 한다. 그 이유는 L1은 내가 원하는 특성이 제거되지만 L2는 모든 값을 고려해주기 때문이다!
Softmax Classifier(Multinomial Logistic Regression)
:
: class별 확률분포를 사용하여 예측 점수 자체에 추가적인 의미를 부여
-
Softmax Classifier에서 사용하는 Loss는 Cross entropy loss라고 하며, 정답이 나올 확률의 최소값을 의미한다.
-
👉 (정답 클래스가 정답일 확률)
-
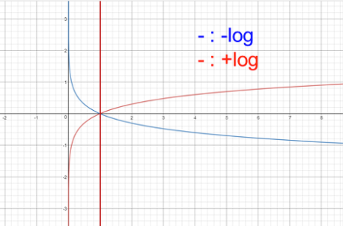
를 해주는 이유는 얼마나 가 얼마나 나쁜지를 측정하기 위함 👉 는 확률(x축)이 1에 가까워질수록 loss(y축)가 0에 가까워진다.
-
softmax를 이전 예시에 적용해보면,

- exp 를 취해서 score 값을 양수로 만듦
- 정규화 시켜서 확률분포로 만들어줌
- 정답 class에 -log를 취함(cross-entropy loss 값)
-
최종적인 목표는 정답 class에 대한 -log 확률(loss function)이 최소화되는 것을 찾는 것이다

-
KL-Divergence: cross entropy와 entropy(고정된 값) 의 분포가 얼마나 다른지 측정, 실제로 entropy 값은 고정되어있기 때문에 모델이 학습하면서 cross entropy를 최소화해야함

💡 Cross Entropy?
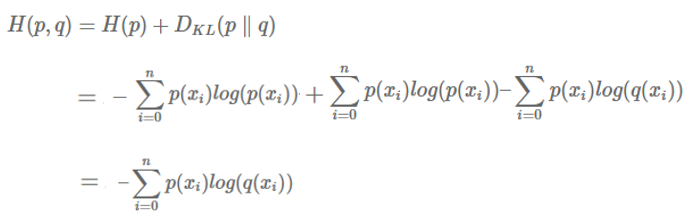 수식을 보면 알 수 있듯이 Cross entropy는 true distribution 의 entropy와, 와 의 KL divergence의 합으로 정의가 되어있다.
수식을 보면 알 수 있듯이 Cross entropy는 true distribution 의 entropy와, 와 의 KL divergence의 합으로 정의가 되어있다.
true distribution 는 주로 one-hot encoded vector를 사용한다. 예를 들어서, MNIST classification에서 숫자 2의 경우 true distribution(GT) 는 {0,0,1,0,0,0,0,0,0,0} 이 된다.
softmax layer의 output 값들()은 0~1 사이 확률 값이 되고 다 더하면 1이 된다. 즉, 와 의 차이를 구하려면, 두 확률 분포 간의 차이를 측정하는 지표인 Cross entropy를 사용하면 되는 것이다.
그런데, 는 이미 one-hot encoding이 되어 있다. 이러한 경우, Cross entropy는 시그마를 사용하지 않고 나타낼 수 있다.
이 때문에 softmax layer에서 loss를 구할 때 출력값에 를 취해주는 것이다.
이렇게 Cross entropy를 최소화하면서 neural network를 학습시키게 되는데, 이 Cross entropy 식 자체가 P에 대한 Entropy와 P, Q간의 KL divergence의 합으로 구성이 되어있기 때문에 어떻게 보면 KL divergence를 최소화하는 것과 같다.
-
Q1. softmax loss의 min, max 값은?
: min = 0, max = ∞ (-log 그래프를 보면 알 수 있음) -
Q2. 초기에 모든 score 값이 대략적으로 같으면 loss는?
: , 만약 C가 10인 경우, loss 는 대략 2.3

-
Q3. 만약 class score를 2배 해주면?
- SVM: 변화 X (정답 class score가 정답이 아닌 class score+1 보다 크면 딱히 영향이 없음)
- Softmax: 변화 O (확률로 계산되기 때문에 조금만 데이터가 변경되어도 바로 확률에 영향을 미침, 매우 민감)
