느낀점
- 베이스 모델에 SFT, DPO, Online-RL만 사용?
- 한국어 데이터가 많아서 수능을 잘하는 건가?
- 추론 모델은 뭔가 벤치용?
Abstract
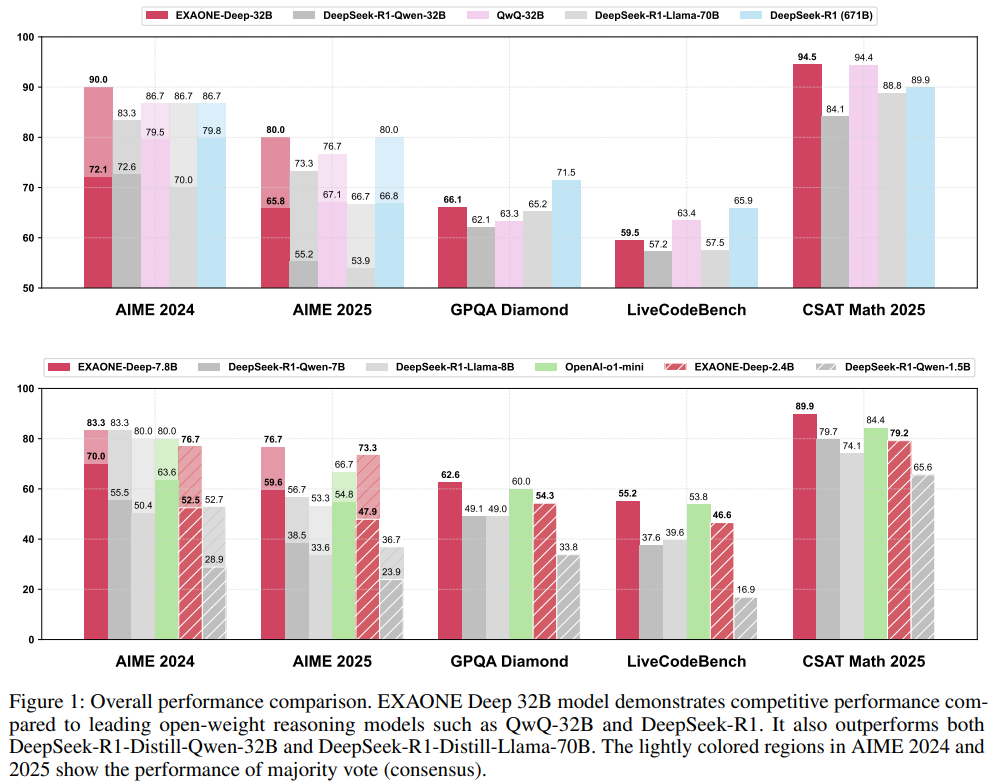
수학 및 코딩 벤치마크를 포함한 다양한 추론 과제에서 뛰어난 성능을 보이는 EXAONE Deep 시리즈를 공개합니다.
긴 사고 과정의 흐름을 포함하는 추론에 특화된 데이터셋을 사용하여 학습되었습니다.
평가 결과 작은 모델인 EXAONE Deep 2.4B와 7.8B는 유사한 크기의 다른 모델들을 능가하며 가장 큰 모델인 EXAONE Deep 32B는 현재 공개된 선두권의 모델들과 비교하여 경쟁력 있는 성능을 보였습니다.
모든 EXAONE Deep 모델은 연구 목적으로 개방되어 있습니다.
Introduction
최근 연구 분야에서는 테스트 단계에서의 컴퓨팅 자원을 조정하여 모델의 추론 성능을 향상시키는 추세가 증가하고 있습니다.
비슷한 기법으로 LG AI 연구원은 새로운 모델 라인업인 EXAONE Deep 2.4B, 7.8B 및 32B를 소개합니다.
해당 모델들은 EXAONE 3.5 시리즈를 기반으로 추론 과제에 최적화하여 fine-tuning된 모델입니다.
모델들을 fine-tuning에서 널리 활용되는 세 가지 주요 기법들인 Supervised Fine-Tuning( SFT), Direct Preference Optimization(DPO), Online Reinforcement Learning(Online RL)— 활용하여 학습시켰습니다.
2.4B 모델은 DeepSeek-R1-Distill-Qwen-1.5B와 비교하여 더 우수한 성능을 보였습니다.
7.8B 모델의 경우 비슷한 규모를 가진 공개 모델인 DeepSeek-R1-Distill-Qwen-7B 및 DeepSeek-R1-Distill-Llama-8B를 능가하고 proprietary 추론 모델인 OpenAI o1-mini도 뛰어넘었습니다.
32B 모델은 최상위 선두 추론 모델인 QwQ-32B, DeepSeek-R1과 견줄만한 경쟁력을 보였으며, 특히 DeepSeek-R1-Distill-Qwen-32B와 더 큰 규모인 DeepSeek-R1-Distill-Llama-70B 모델보다도 우수한 성능을 나타냈습니다.
Modeling
Data
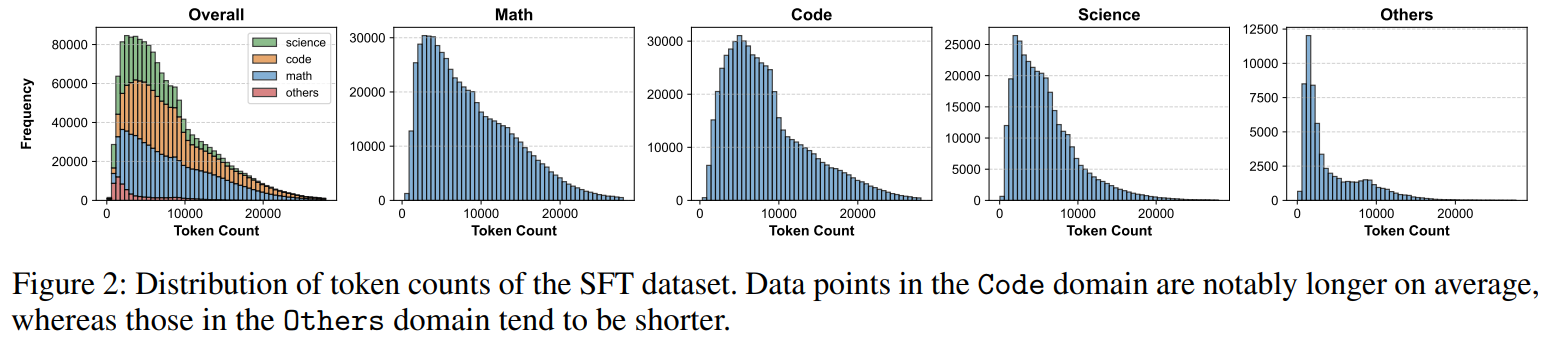
언어 모델의 추론 능력을 향상시키기 위해 SFT에 160만 개의 데이터를 사용, DPO에 2만 개, Online RL에 1만 개의 데이터를 활용하였습니다.
SFT 데이터셋은 총 약 120억 개의 토큰(token)으로 구성되어 있으며 길이 분포는 그림 2에서 확인할 수 있습니다.
해당 데이터셋은 그림 3에서 제시된 것과 같이, 모델이 긴 chain-of-thought(CoT)을 통해 추론을 수행하도록 안내하는 형태로 설계되었습니다.
Training
EXAONE Deep의 base 모델은 EXAONE 3.5 Instruct 모델이며, instruction을 이해하고 수행할 수 있도록 instruction-tuned이 된 모델입니다.
EXAONE Deep의 추론 능력을 강화하기 위해, SFT 및 DPO 데이터를 그림 3에 나타낸 것과 같은 templated format 으로 구성하였습니다.
각 학습 데이터는 structured thought process + 일관되고 정확한 답변으로 종합한 final answer로 구성됩니다.
EXAONE 3.5 Instruct 모델은 와 태그 내에서 추론(reasoning)을 수행하도록 학습되며 단계적으로 논리를 전개하는 것과 reflection, self-checking, correction까지 수행합니다.
추론 과정을 거쳐 도출된 final answer은 독립적으로 이해 가능하도록 설계되었으며 thought process을 통해 도출된 핵심 인사이트를 명확하고 간결하게 요약합니다.
structured approach을 통해 EXAONE Deep 모델은 robust한 추론을 수행할 수 있으며 주어진 질문에 대해 근거가 충분하고 정확한 답변을 제시할 수 있습니다.
DPO를 위한 학습 알고리즘으로는 SimPER[19], Online RL을 위해서는 GRPO의 변형을 사용합니다.
Evaluation
Benchmarks
모델의 성능 평가를 위해 다음 벤치마크를 활용했습니다:
MATH-500, 미국 수학경시대회 초청시험(AIME) 2024, 2025, 2025학년도 대학수학능력시험(CSAT)의 수학 영역, GPQA Diamond, LiveCodeBench (24.08-25.02), MMLU, MMLU-Pro[18].
텍스트 문제뿐 아니라 보충적인 그래픽 정보를 포함하는 한국 대학수학능력시험(CSAT)의 수학 영역의 경우, 평가 시에는 그래픽 정보는 제외하고 텍스트 문제만 활용했습니다.
이 그래픽 정보 대부분은 텍스트로도 설명되어 있기 때문에 그래픽 정보 제외로 인한 성능 평가에 대한 영향은 최소한으로 간주됩니다.
CSAT 수학 영역에서는 학생들이 미적분, 확률과 통계, 기하 세 가지 과목 중 하나를 선택할 수 있으며, 본 연구에서는 이 세 가지 선택과목에서 얻은 점수의 평균을 최종 점수로 산정하였습니다.
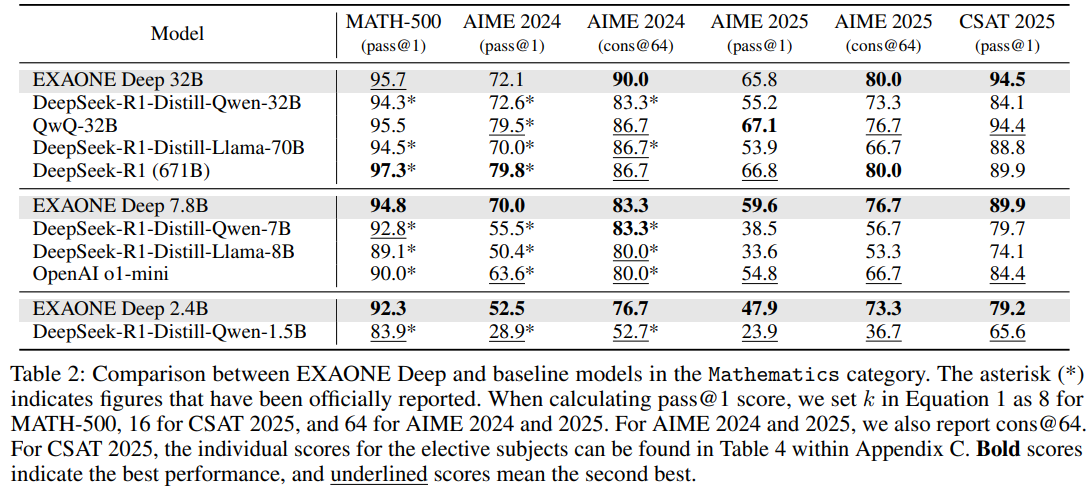
확실히 수능을 잘하는 모습
한계
EXAONE Deep 모델은 reasoning 과제에서 뛰어난 성능을 발휘하도록 특별히 fine-tuning된 모델입니다.
base models은 instruction 기반의 instruction-fine-tuning을 거쳤으며 일반적으로 명령을 잘 수행할 수 있지만 실제 현실 세계에서 더욱 다양한 용도로 활용하고자 할 때에는 실질적인 응용 시나리오에 최적화된 EXAONE 3.5 Instruct 모델의 사용을 강력히 권장합니다.
