느낀점
- 구글 덕분에 라이센스 걱정 없는 모델
- 이미지처리도 해주다니...
- 새로운 부분은 많이 없지만 세세한 포인트에 많은 노력
- 데이터 퀄 매우 중요

Abstract
Gemma 경량 모델에 새로운 멀티모달 버전인 Gemma 3를 소개합니다.
Gemma 3는 1B부터 27B까지 다양한 파라미터 크기를 가지며 시각 이해 능력(vision understanding)이 추가되고 더 많은 언어 지원과 최소 128K 토큰 이상의 긴 컨텍스트 처리가 가능합니다.
긴 컨텍스트를 처리할 때 KV-cache memory 급격히 늘어나는 문제를 해결하기 위해 모델 아키텍처를 개선했습니다.
local attention layers 비율을 global attention layers 대비 높이고 local attention의 범위를 짧게 유지하도록 설계했습니다.
Gemma 3 모델들은 distillation를 통해 훈련되었으며 pre-trained 및 instruction finetuned된 버전 모두에서 기존의 Gemma 2보다 우수한 성능을 보입니다.
특히 새롭게 개발한 post-training 기법은 수학, 대화, 명령어 수행, 다국어 능력을 크게 향상시키며, Gemma3-4B-IT는 Gemma2-27B-IT 모델과 경쟁 가능한 수준이고, Gemma3-27B-IT 모델은 Gemini-1.5-Pro와 벤치마크 전반에서 동등한 성능을 보입니다.
Introduction
Gemma 오픈 언어 모델을 소개합니다.
Gemini 프론티어 모델군과 함께 설계되었습니다.
이번 최신 버전의 크기는 Gemma 2와 유사하며, 1B(10억 파라미터) 모델이 새롭게 추가되었습니다.
다양한 하드웨어에서 구동될 수 있도록 설계되었습니다.
기존의 성능을 유지하거나 뛰어넘으면서도 multimodality, long context, multilinguality 등 몇 가지 새로운 기능들이 Gemma 모델군에 추가됩니다.
멀티모달의 측면에서 대부분의 Gemma 3 모델은 맞춤형 SigLIP 비전 인코더와 호환됩니다.
언어 모델은 이미지를 SigLIP에 의해 인코딩된 일련의 연속적인 soft tokens으로 간주됩니다.
이미지 처리 시 추론 비용을 줄이기 위해 비전 토큰 임베딩을 고정된 크기인 256개의 벡터로 압축합니다.
인코더는 고정된 해상도로 작동하지만, LLaVA에서 영감을 얻어 Pan and Scan(P&S) 방식으로 다양한 해상도를 지원합니다.
두 번째 주요 구조적 개선점은 성능 저하 없이 문맥의 길이를 128K(128,000) 토큰으로 늘린 것입니다.
긴 문맥 처리는 추론 과정에서 KV-cache memory가 폭발적으로 증가하는 문제가 있습니다.
이를 해결하기 위해 global layer 사이에 여러 개의 local layer를 교차 배치하고, local layer의 문맥 범위는 1024 토큰으로 제한합니다.
따라서 global layer만 긴 문맥 전체를 참조하며, 전역 레이어와 지역 레이어의 비율을 1(global) 대 5(local)로 설정했습니다.
pre-training의 최적화 방법은 일부 아키텍처 설계를 제외하면 Gemma 2와 유사합니다.
Gemini 2.0과 동일한 tokenizer를 사용하며 이미지 처리 기능을 도입하면서 다국어 능력을 향상시키기 위해 data mixture를 진행했습니다.
모든 Gemma 3 모델은 knowledge distillation를 활용하여 훈련됩니다.
post-training 단계에서는 mathematics, 추론, 대화 능력 향상에 중점을 두었으며, Gemma 3의 긴 문맥과 이미지 입력과 같은 새로운 기능을 통합했습니다.
우리는 수학, 코딩, 대화, instruction following, 다국어 능력 등 모든 영역에서 성능 향상을 가져오는 새로운 후처리 훈련 방식을 사용합니다.
그 결과 instruction-tuned을 거친 Gemma 3 모델은 이전 버전보다 성능 면에서 크게 우수하며 강력하고 활용도가 높습니다.
Model Architecture
Gemma 3 모델은 이전 버전과 마찬가지로 decoder-only transformer 구조를 따르며, 대부분의 아키텍처 요소는 앞서 나온 Gemma 1, 2와 유사합니다.
post-norm를 사용한 GQA(Grouped-Query Attention)과 RMSNorm을 이용한 pre-norm를 적용했습니다.
Gemma 2의 soft-capping을 QK-norm으로 교체했습니다.
local, global 레이어의 5:1 interleaving
우리는 local sliding window self-attention과 global self-attention을 교차로 배치합니다.
모델의 첫 번째 레이어는 local 레이어로 시작하고 global 레이어 하나당 다섯 개의 지역 레이어가 반복되는 형태를 사용합니다(즉, local layer 5개 후 global layer 1개가 나오는 구조).
long context
Gemma 3 모델은 최대 128K 토큰의 긴 문맥을 지원합니다.
1B 모델은 예외적으로 32K 토큰까지만 지원합니다.
global 셀프 어텐션 레이어의 RoPE(Rotary Positional Embedding) 기반 frequency를 기존 10k에서 1M으로 높였고, local 레이어는 기존의 10k frequency를 그대로 유지했습니다.
Vision modality
Vision encoder
SigLIP 인코더의 400M 버전을 활용합니다.
Vision Transformer를 CLIP loss의 변형으로 훈련한 것입니다.
Gemma의 비전 인코더는 896 × 896 픽셀 크기의 정사각형 이미지를 입력으로 사용하며, visual assistant 작업에서 얻은 데이터로 finetuning합니다.
단순화를 위해 비전 인코더를 Gemma의 4B, 12B, 27B 모델 간에 공유하며 훈련 중에는 비전 인코더의 파라미터를 frozen하여 유지합니다.
Pan & Scan (P&S)
Gemma 비전 인코더는 고정된 해상도인 896 × 896으로 작동합니다.
이는 비정사각형 이미지를 처리하거나 고해상도 이미지를 처리할 때 아티팩트를 유발할 수 있으며 이로 인해 텍스트가 읽을 수 없게 되거나 작은 물체가 사라지는 문제가 발생합니다.
우리는 추론 단계에서 이를 해결하기 위해 adaptive windowing 알고리즘을 도입했습니다.
이 알고리즘은 이미지를 겹치지 않는 동일한 크기의 작은 조각으로 나누어 전체 이미지를 모두 커버한 다음 각 조각을 896 × 896 픽셀로 리사이즈하여 비전 인코더에 입력합니다.
이 윈도잉 기법은 필요한 경우에만 적용되며, 최대 조각의 개수를 제어할 수 있습니다.
이는 오직 추론 시에만 적용되는 최적화 기법이며, 더 빠른 추론이 필요하면 비활성화할 수도 있습니다.
Instruction-Tuning
Techniques
우리의 후속 학습 접근법은, 큰 크기의 명령어 조정(Instruction Tuning, IT) 모델인 교사(teacher) 모델로부터의 지식 증류(Knowledge Distillation; Agarwal et al., 2024; Anil et al., 2018; Hinton et al., 2015)를 개선한 버전을 사용하는 동시에, BOND(Sessa et al., 2024), WARM(Ramé et al., 2024b), WARP(Ramé et al., 2024a)의 개선된 버전을 기반으로 한 강화학습(RL) 미세조정 단계도 포함합니다.
Reinforcement Learning Objectives
모델이 helpfulness, math, coding, reasoning, instruction following, multilingual 성능을 높이도록 여러 reward 함수를 사용하며 동시에 모델의 harmfulness을 최소화합니다.
이를 위해 human feedback 데이터를 활용해 학습된 weight averaged 보상 모델, code execution feedback, 수학 문제 해결에 대한 ground-truth 보상 등으로부터 학습합니다.
Data filtering
모델 성능을 극대화하기 위해 post-training에서 사용되는 데이터를 최적화합니다.
개인 정보를 포함한 데이터, 안전하지 않거나 유해한 출력 예시, 잘못된 자기 식별 데이터, 중복된 예시 등을 필터링하여 제거합니다.
또한 모델의 환각(hallucination)을 최소화하기 위해 맥락 내 출처 명시, 불확실성 표현, 답변 거부를 촉진하는 데이터 하위 집합을 포함하면 다른 성능 지표에 악영향을 주지 않으면서도 모델의 사실성을 높이는 데 도움이 됩니다.
[BOS] 토큰
사전 훈련과 IT 모델 모두 텍스트 시작점에 [BOS] 토큰을 사용합니다.
단, 텍스트 자체인 “[BOS]”라는 글자는 [BOS] 토큰으로 변환되지 않으므로 이 토큰은 별도로 명시적으로 추가해야 합니다.
예를 들어 Flax의 토크나이저는 add_bos=True 옵션을 통해 이 토큰을 자동으로 추가할 수 있습니다.
PT vs IT Formatting
모든 모델은 동일한 tokenizer를 공유하지만, IT 형식 지정을 위한 몇 가지 제어 토큰이 추가로 존재합니다.
중요한 차이점은 PT 모델은 문장 생성의 끝에 토큰을 출력하지만 IT 모델은 생성의 끝에 <end_of_turn> 토큰을 출력한다는 점입니다.
따라서 어떤 모델 유형이든 fine-tuning을 수행할 때는 각 모델 타입에 맞는 end 토큰을 반드시 추가해야 합니다.
Experiments
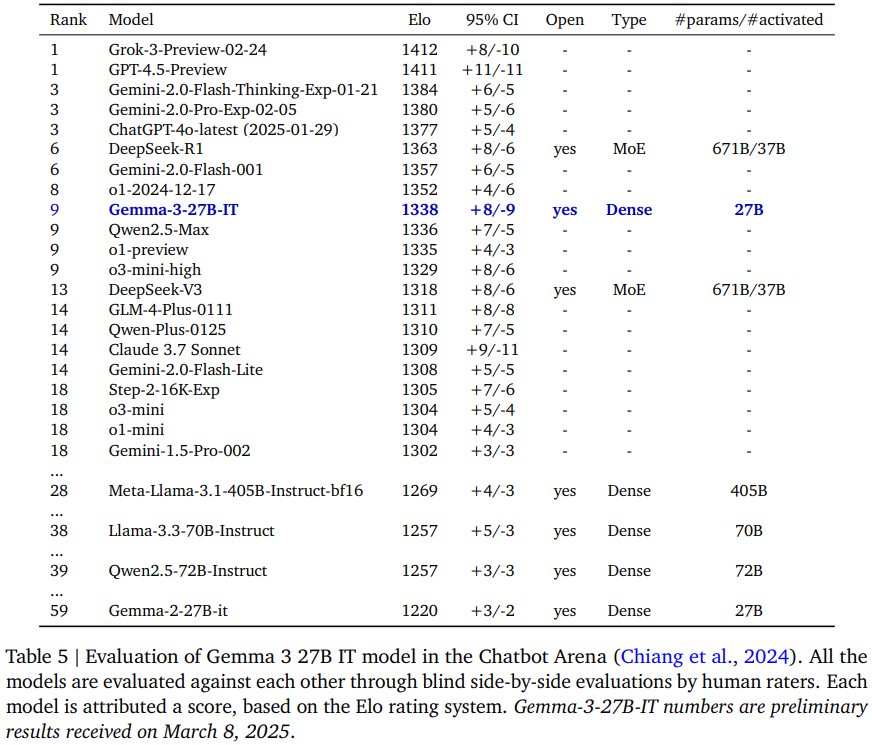
챗봇 아레나 성능 매우 작은 모델 and not MoE로 매우 높은 성능
