Abstract
대형 언어 모델(LLM)의 능력을 평가할 때, 원본 긴 문서에서 사용자의 질의와 관련된 내용을 식별하는 것은 LLM이 긴 텍스트 기반의 질문에 대답할 수 있는 중요한 조건입니다.
NeedleBench라는 프레임워크를 이용하여 긴 문서에서 사용자 질의를 체크할 수 있는 벤치마크를 소개합니다.
다양한 길이 구간(4k, 8k, 32k, 128k, 200k, 1000k 이상)과 긴 문맥 능력을 평가하는 일련의 과제를 포함합니다.
프레임워크는 모델의 다양한 문맥에서의 검색 및 추론 능력을 철저히 테스트하기 위해 중요한 데이터 포인트를 전략적으로 다양한 텍스트 깊이 영역에 삽입하는 방식을 사용합니다.
NeedleBench 프레임워크를 사용하여 주요 오픈 소스 모델이 질문과 관련된 주요 정보를 얼마나 잘 식별하고, 긴 텍스트 추론에 적용하는지를 평가합니다.
현실 세계의 긴 문맥 작업에서 발생할 가능성이 있는 논리적 추론 과제의 복잡성을 Ancestral Trace Challenge (ATC)를 제안합니다.
복잡한 긴 문맥 상황을 처리하는 LLM을 평가하는 간단한 방법을 제공합니다.
현재의 LLM이 실용적인 긴 문맥 응용 프로그램에서 상당한 개선의 여지가 있음을 알 수 있으며,
현실 세계의 긴 문맥 작업에서 발생할 가능성이 높은 논리적 추론 과제의 복잡성에 어려움을 겪고 있음을 보여줍니다.
Introduction
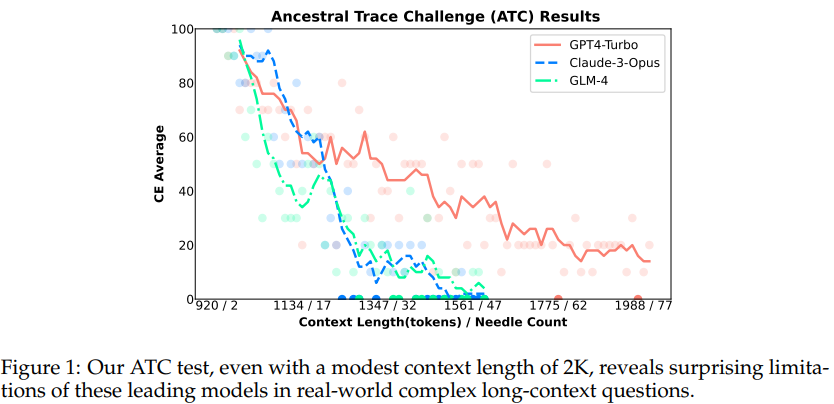
LLM이 긴 텍스트를 처리하는 능력은 다양한 상황에서 중요합니다.
예를 들어 LLMs는 긴 문서 내의 정보를 빠르게 식별하고 요약할 수 있어 다양한 응용 분야에서 매우 유용합니다.
LLMs 더 긴 문맥 창을 지원하도록 개발되었습니다.
예를 들어, GPT-4 최대 128k 토큰까지 긴 문맥을 입력으로 받을 수 있습니다.
Claude, Gemini 1.5, GLM4-9B-Chat, InternLM2.5-7B-Chat 수백만 문맥 창을 지원합니다.
모델이 더 긴 텍스트 길이를 수용함으로 따라 텍스트 내의 세부 사항을 이해하는지 확인하는 것이 점점 더 중요해지고 있습니다.
LLMs가 긴 텍스트를 처리하는 데 능력을 평가하기 위한 다양한 접근법이 제안되었습니다.
LongBench 데이터셋과 같은 기존 데이터셋은 일반적으로 5k~15k 토큰 범위의 길이를 특징으로 하는 이중 언어(중국어 및 영어) 긴 텍스트 이해를 위한 벤치마크를 제공합니다.
100만 토큰 수준에서 긴 문맥 LLMs의 성능을 정확하게 평가하는 것은 매우 중요한 과제입니다.
Mohtashami & Jaggisms는 반복적으로 유사한 텍스트에 키 정보 패스키를 포함하고 끝에서 이 정보를 쿼리하여 LLama-7B 모델의 기본 정보 추출 능력을 평가하는 패스키 테스트 접근법을 소개합니다.
패스키 방법을 100K를 초과하는 길이로 확장하여 긴 텍스트 내의 다양한 깊이에 패스키를 삽입합니다.
패스키와 관련이 없는 보다 다양한 비반복적인 개인 에세이 세트를 필러 정보로 사용하여 Needle In A Haystack(NIAH) 테스트를 개발했습니다.
해당 테스트는 문맥 창을 200k로 확장하고 클로드 및 GPT-4 모델에 대해 스트레스 테스트를 수행합니다.
긴 텍스트에서 주요 정보를 추출하는 건초 더미 속 바늘 찾기 테스트를 통과하는 것이 정말로 LLMs가 복잡한 현실 세계의 긴 문맥 문제를 처리할 수 있음을 의미할까요?
일반적으로 현실 세계의 작업은 모델이 단일 정보 조각이 아닌, 여러 분산된 질문 관련 정보를 검색하고 통합해야 합니다.
여러 주요 정보 포인트를 식별하고 텍스트 내의 관련 콘텐츠를 광범위하게 통합하여 심층적이고 정확한 분석을 제공해햐 함을 의미합니다.
따라서 현실적인 응용을 위한 LLMs의 긴 문맥 능력을 향상시키려면 정확한 정보 검색뿐만 아니라 강력한 추론 능력이 필요합니다.
기존의 긴 문맥 정보 추출 평가 방법의 한계와 현실 세계 응용 시나리오와의 불일치를 해결하기 위해, 우리는 NeedleBench 데이터셋을 소개합니다.
NeedleBench는 모델의 긴 텍스트 문맥 내에서 정보를 추출하고 분석하는 능력을 종합적이고 목표적으로 평가하기 위한 고급 긴 문맥 정보 능력 평가 방법을 포함합니다.
복잡한 긴 문맥 작업을 시뮬레이션하기 위해 Ancestral Trace Challenge (ATC) 테스트를 개발했습니다.
- 다양한 길이 구간(4k, 8k, 32k, 128k, 200k, 1000k 이상)과 다양한 텍스트 깊이 범위에 걸쳐 LLMs의 이중 언어 긴 문맥 능력을 평가하기 위한 작업을 포함하는 맞춤형 데이터셋 프레임워크입니다.
- ATC를 제안하여 현실 세계 시나리오에서 복잡한 긴 문맥 작업을 시뮬레이션하며, 복잡한 긴 문맥 상황에서 LLMs를 평가하기 위한 간단한 방법을 제공합니다.
- 우리는 주요 모델이 질문과 관련된 주요 정보를 식별하고 추론하는 성능에 대한 세밀한 평가 및 분석을 수행했습니다.
Tasks and Datasets
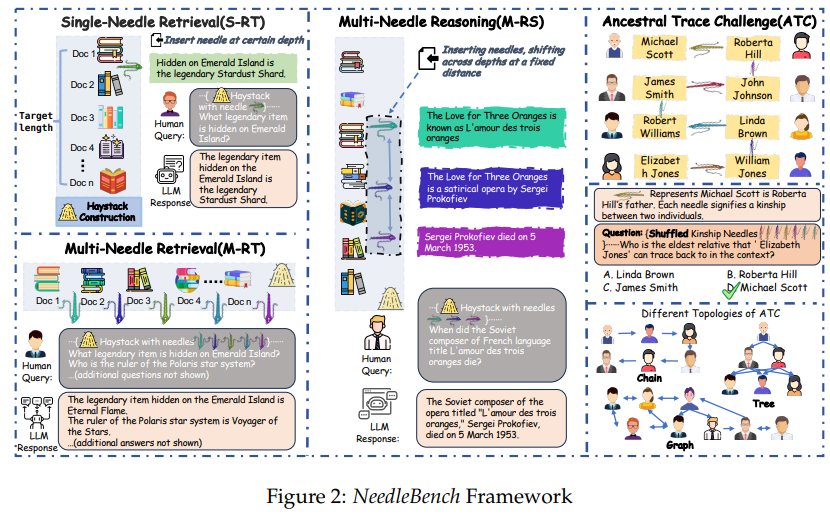
위 이미지는 NeedleBench 프레임워크에 대한 그림입니다.
3가지 주요 구성 요소로 이루어져 있습니다.
nge-Needle Retrieval(S-RT):
- 특정 깊이에서 바늘을 삽입하여 목표 길이를 찾는 과정입니다.
- 예시: "에메랄드 섬에 숨겨진 전설적인 물건은 무엇인가?"라는 질문에 대해 "에메랄드 섬에 숨겨진 전설적인 물건은 Stardust Shard입니다."라는 대답을 제공합니다.
- 인간의 질문과 LLM(대형 언어 모델)의 응답이 포함됩니다.
Multi-Needle Retrieval (M-RT):
- 여러 문서에서 바늘을 찾아 목표 길이를 찾는 과정입니다.
- 예시: "에메랄드 섬에 숨겨진 전설적인 물건은 무엇인가?"와 "Polaris 항성계의 통치자는 누구인가?"라는 질문에 대한 응답으로 "에메랄드 섬에 숨겨진 전설적인 물건은 The Final Flame입니다. Polaris 항성계의 통치자는 Voyager of the Stars입니다."라는 응답을 제공합니다.
- 여러 문서에서 정보를 추출하여 종합적인 응답을 제공합니다.
Multi-Needle Reasoning (M-RS):
- 특정 거리에서 바늘을 삽입하고 이동시켜 추론을 통해 목표를 찾는 과정입니다.
- 예시: "언제 프랑스어 오페라 '사랑의 세 오렌지'의 작곡가인 프로코피예프가 사망했는가?"라는 질문에 대해 "프랑스어 오페라 '사랑의 세 오렌지'의 작곡가는 세르게이 프로코피예프입니다. 그는 1953년 3월 5일에 사망했습니다."라는 응답을 제공합니다.
- 여러 문서의 내용을 결합하여 추론을 통해 응답을 생성합니다.
Ancestral Trace Challenge (ATC):
- 가족 관계를 나타내는 그래프에서 특정 사람의 친족 관계를 찾는 과정입니다.
- 예시: "Elizabeth Jones의 가장 오래된 친족은 누구인가?"라는 질문에 대해 "Roberta Hill"이라는 응답을 제공합니다.
- 그래프의 다양한 토폴로지를 통해 친족 관계를 추적합니다.
Needle Design
모델의 고유한 지식이 정보 검색 능력에 방해가 되지 않도록 하기 위해,
Single-Needle Retrieval(S-RT)와 Multi-Needle Retrieval 과제에서 바늘(핵심 정보)을 추상적이고 현실 세계에 존재하지 않는 것으로 의도적으로 설계합니다.
Multi-Needle Reasoning 과제의 경우, 우리는 R4C 데이터셋을 활용하여 바늘 코퍼스를 구성합니다.
데이터셋은 HotpotQA 데이터셋의 확장판으로, 질문에 답하는 데 필요한 각 추론 단계를 자세히 설명하는 'Derivation' 정보를 포함하고 있으며, HotpotQA에 존재하는 모호한 대명사 문제를 해결합니다.
Haystack Design
PaulGrahamEssays 데이터셋을 사용하여 프롬프트를 목표 길이로 확장합니다.
중국어 Haystack의 설계에서는 ChineseDomainModelingEval 데이터셋을 활용하여 중국어 텍스트 소스의 다양성과 품질을 보장합니다.
이 데이터셋은 금융부터 기술에 이르는 광범위한 주제를 다루며, 최신의 고품질 중국어 기사를 제공하고, 도메인 특화 긴 텍스트를 처리하는 다양한 모델의 능력을 평가하기 위한 안정적인 벤치마크를 제공합니다.
Experiments
우리는 모델의 성능을 평가하기 위해 서로 다른 위치에 놓인 바늘의 회수 정확도를 메트릭으로 사용합니다.
다양한 길이와 깊이의 데이터 세트에서 성능을 순차적으로 평균화함으로써 NeedleBench 내 각 작업에서 모델의 성능을 얻습니다.
각 작업의 점수를 평균화하여 전체 점수를 제공하며, 이는 각 작업의 기여를 균형 있게 나타내도록 합니다.
결과의 안정성을 보장하기 위해 각 테스트를 여러 번 반복했습니다. 토큰 수는 GPT-42의 토크나이저를 사용하여 일관되게 계산되었습니다.
또한, 각 모델의 토크나이저 차이로 인해 발생할 수 있는 프롬프트 전체를 수신하지 못하는 문제를 완화하기 위해 다양한 버퍼 크기를 도입했습니다.
실험에서는 질문 명령 프롬프트를 확장된 텍스트의 끝에 일관되게 배치했습니다.
각 특정 작업에서 예측과 참조 간의 유사성을 평가하기 위해, Levenshtein 거리를 사용하며, 와 은 각각 길이가 n인 예측과 참조의 목록을 나타냅니다.
각 와 쌍의 점수는 에 대해 정의된 핵심 키워드 집합 내의 핵심 키워드의 존재 여부에 따라 조정됩니다.
에서 핵심 키워드를 누락한 예측에 대해 페널티 계수 α = 0.2가 점수 계산에 적용됩니다. 개별 점수 Scorei의 공식은 다음과 같습니다:
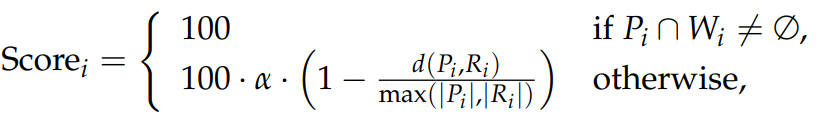
여기서 는 와 간의 Levenshtein 거리이며, ||와 ||는 각자의 길이를 나타냅니다.
최종 점수는 n번 반복한 Scorei의 평균입니다.
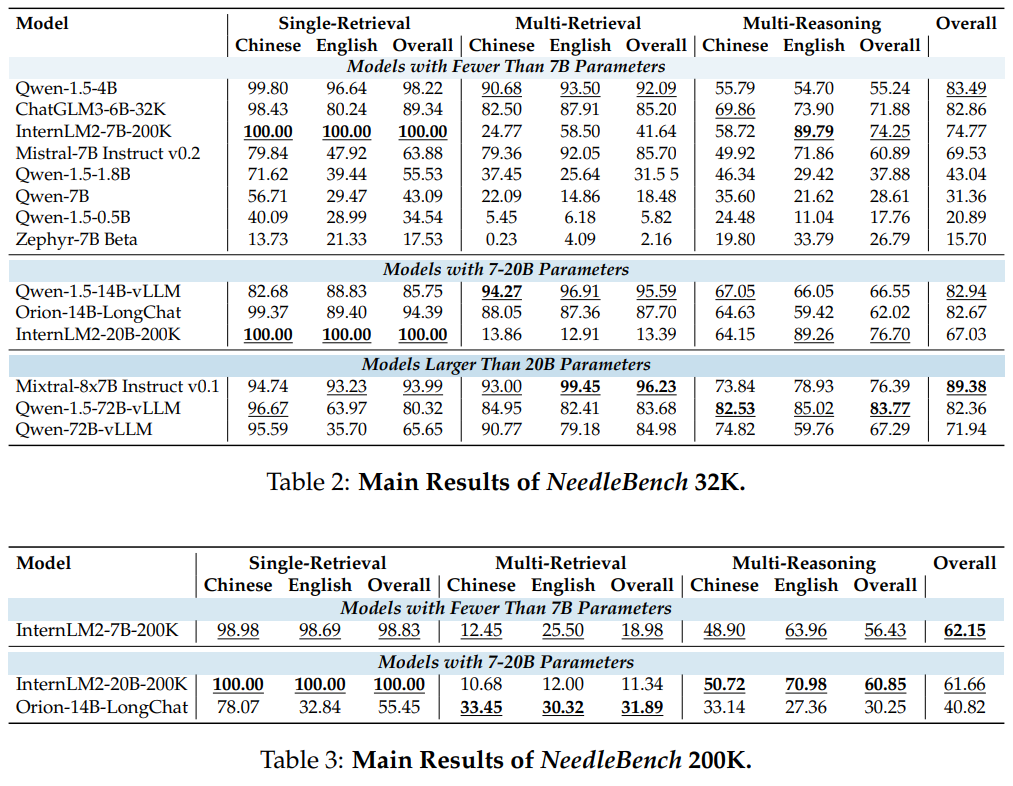
NeedleBench 32K 및 200K
InternLM2-7B-200K: Single-Retrieval에서 완벽한 성과를 달성하여 단일 정보 포인트를 정확하게 검색하는 강력한 능력을 보여줍니다.
Qwen-1.5-72BvLLM: 72B의 상당한 매개변수를 가지고 있는 Multi-Reasoning에서 뛰어난 성과를 보여, 복잡한 정보 간의 관계를 이해하고 추론하는 데 있어 우위를 점합니다.
Mixtral-8x7B Instruct v0.1: 특히 검색 작업에서 전반적으로 뛰어난 성과를 보여줍니다.
200K 문맥 길이
InternLM2-7B-200K: Single-Retrieval 작업에서 일관된 강점을 계속 보여주지만, Multi-Retrieval 테스트에서는 성능이 크게 저하됩니다.
Orion-14B-LongChat: Multi-Retrieval 작업에서 더 능숙하지만, Single-Retrieval 작업에서는 약 80K 문맥 길이에 도달하면 성능이 저하됩니다.
NeedleBench 1000K
평가를 더욱 확장하여 문맥 길이를 1000K 토큰까지 늘립니다.
우리는 InternLM2.5-7B-1M 및 GLM4-9B-Chat-1M 모델을 이 문맥 길이에서 평가합니다.
NeedleBench의 두 모델에 대한 종합적인 결과를 표 4에 제시합니다.
대부분의 작업에서 InternLM2.5-7B-Chat-1M이 GLM4-9B-Chat-1M보다 더 나은 성과를 보이는 것을 알 수 있습니다.
GLM4-9B-Chat-1M의 성능이 InternLM2.5-7B-Chat-1M보다 현저히 떨어지는 이유를 조사합니다.
성능 차이가 큰 작업 중 하나는 Single-Retrieval 작업입니다.
상대적으로 낮은 문맥 길이에서도 GLM4-9B-Chat-1M 모델의 영어 버전이 성능이 저조한 것을 발견했습니다.
모델 출력을 검토한 결과, GLM4-9B-Chat-1M 모델이 원본 텍스트에 관련된 내용이 없다고 생각하여 질문에 답하지 못하는 경우가 자주 발생함을 알 수 있습니다.
Conclusion
LLMs가 긴 문맥의 정보 검색 및 추론을 처리하는 능력을 철저히 평가했습니다.
오픈 소스 LLMs가 긴 텍스트를 해석하고 추론하는 데 있어 주목할 만한 한계를 가지고 있음을 밝혀냈습니다.
GPT-4 Turbo와 Claude 3와 같은 모델들이 확장된 문맥 길이에서 단일 정보 검색 능력에서 진전을 보였음에도 불구하고, 우리의 발견은 현실 세계의 긴 문맥 작업에서 발생할 가능성이 있는 논리적 추론 과제의 복잡성으로 인해 이러한 모델들이 겪는 어려움을 강조합니다.
복잡한 정보 검색과 다단계 추론을 요구하는 시나리오에서 LLMs의 유용성을 향상시킬 여지가 많음을 시사합니다.
우리의 보고서는 AI 연구 커뮤니티 내에서 LLMs의 긴 문맥 이해 및 추론 능력을 향상시키기 위한 집중적인 노력이 중요함을 강조합니다.
NeedleBench 평가에서 식별된 단점을 해결하면 현실 세계의 복잡한 긴 문맥 작업에 더 효과적으로 대비할 수 있게 될 것입니다.
