느낀점
- 외부 데이터 전혀 없이 성능 개선 매력적
- 인간 데이터 의존성 제거
- 명확한 영역에서는 환경 구축이 좋지만 창의적인 활동에서 괜찮을까? 환경 구축 자체가 어려울 느낌
- 근데 베이스라인이 좋은 데이터로 구워야 잘 되는 거 아닌가? 콜드 스타트가 아님
- 한 번 편향적인 곳에 꽂히면 모델이 헤어날 올 수가 있을까?
Abstract
Reinforcement learning with verifiable rewar (RLVR)은 결과 기반 보상으로부터 직접 학습하여 언어 모델의 추론 능력을 향상시키는 데 좋은 결과를 보였습니다.
제로 베이스 세팅에서 작동하는 최근 RLVR 연구들은 추론 과정에 대한 레이블링에 supervised 없이 동작하지만 여전히 학습을 위해 인간에 의해 선별된 질문-답변 데이터셋에 의존합니다.
고품질의 사람이 만든 예시 데이터의 부족은 언어 모델 사전 학습 영역에서 이미 분명히 드러났듯이 장기적인 확장성에 대한 우려가 있습니다.
인공지능이 인간 지능을 능가하는 미래를 가정할 때 인간이 제공하는 작업은 초지능 시스템의 학습 잠재력을 제한할 수 있습니다.
이러한 우려를 해결하기 위해 외부 데이터에 의존하지 않고 단일 모델이 자신의 학습 진도를 최대화하는 작업을 스스로 제안하고 이를 해결함으로써 추론 능력을 향상시키는 새로운 RLVR 패러다임인 "Absolute Zero"를 제안합니다.
검증 가능한 reward source를 활용하여 개방적이면서도 근거 있는 학습을 유도하는 시스템인 "Absolute Zero Reasoner (AZR)"도 소개합니다.
외부 데이터 없이 전적으로 학습되었음에도 불구하고 AZR은 코딩 및 수학적 추론 작업에서 전반적으로 SOTA 수준의 성능을 달성하여 수만 개의 도메인 내 인간 선별 예시에 의존하는 기존의 제로 세팅 모델들을 능가합니다.
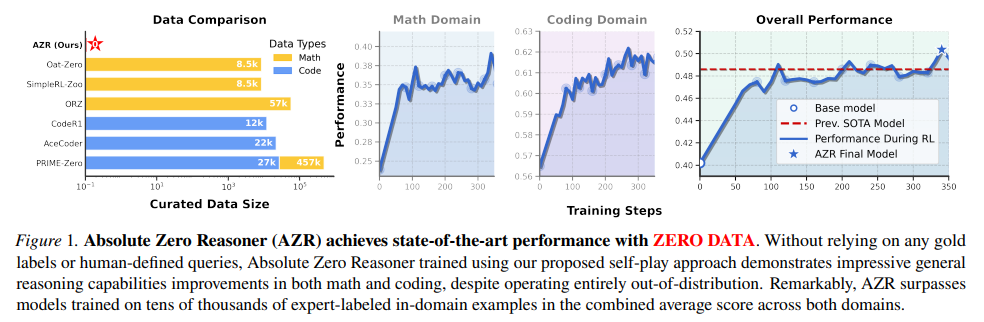
AZR 모델은 외부 데이터 없이 self-play approach만으로 수학과 코딩 영역 모두에서 뛰어난 추론 능력을 달성하는 것을 확인할 수 있다.

- 기존 지도 학습은 인간이 만든 직접적인 지시와 예시 데이터에 의존합
- 강화 학습은 reward 통해 학습하지만 여전히 인간의 개입이 필요
- Absolute Zeros는 인간의 개입 없이 스스로 학습하고 문제를 해결하는 완전한 자율 학습을 목표로 함
Introduction
LLM은 RLVR을 활용한 강화 학습을 통해 놀라운 추론 능력 향상을 이루었습니다.
RLVR은 결과 기반 피드백만을 사용하여 광범위한 작업 데이터셋에 대한 대규모 강화 학습을 가능하게 합니다.
"Zero" RLVR(딥시크)은 인간이 생성하거나 AI가 생성한 추론 과정을 전혀 사용하지 않고 콜드 스타트 증류 데이터를 생략하며, 기본 모델에 직접 작업 보상을 적용합니다.
여전히 전문가가 선별한 추론 질문-답변 쌍의 분포에 크게 의존하며 장기적인 확장성에 대한 우려를 낳습니다.
추론 모델이 계속 발전함에 따라 대규모 고품질 데이터셋을 구축하는 데 필요한 노력은 곧 지속 불가능해질 수 있습니다.
LLM 사전 학습 영역에서도 확장성 병목 현상이 이미 확인되었습니다. AI 시스템이 계속 발전하여 잠재적으로 인간의 지능을 능가함에 따라 인간이 설계한 작업에만 독점적으로 의존하는 것은 자율 학습 및 성장 능력에 제약을 가할 위험이 있습니다.
이를 위해 저희는 모델이 학습 가능성을 극대화하는 작업을 동시에 정의하고 효과적으로 해결하여 외부 데이터에 의존하지 않고 자기 경쟁을 통해 자체적으로 발전할 수 있는 새로운 추론 모델 패러다임인 "Absolute Zero"를 제안합니다.
좁은 도메인, 고정된 기능 또는 해킹에 취약한 학습된 보상 모델에 국한된 이전의 자기 경쟁 방법과는 대조적으로, Absolute Zero 패러다임은 실제 환경에 기반을 두면서 개방형 설정에서 작동하도록 설계되었습니다.
환경으로부터의 피드백을 검증 가능한 보상 소스로 활용하며 인간이 세상과의 상호 작용을 통해 배우고 추론하는 방식을 반영하여 신경망 보상 모델의 해킹과 같은 문제를 방지하는 데 도움이 됩니다.
자기 경쟁을 통해 개선되는 AlphaZero와 유사하게 제안하는 패러다임은 인간의 감독 없이 전적으로 자기 상호 작용을 통해 학습합니다.
저희는 Absolute Zero 패러다임이 대규모 언어 모델이 자율적으로 초인적인 추론 능력을 달성할 수 있도록 하는 유망한 단계라고 믿습니다.
코딩 작업을 제안하고 해결하는 Absolute Zero Reasoner (AZR)을 소개합니다.
코드 실행기를 개방적이면서도 실제 환경으로 간주하며 작업의 무결성을 검증하고 안정적인 학습을 위한 검증 가능한 피드백을 제공하기에 충분합니다.
AZR이 프로그램, 입력, 출력 3중항에서 특정 요소를 추론하고 추론하는 세 가지 유형의 코딩 작업을 구성하도록 합니다.
귀납, 연역, 유추라는 세 가지 상호 보완적인 추론 방식에 해당합니다.
접근 방식의 다중 작업 특성에 맞춰 새롭게 제안된 강화 학습 이점 추정기를 사용하여 전체 시스템을 종단 간으로 학습시킵니다.
어떠한 내부 분포 데이터 없이 완전히 학습되었음에도 불구하고 AZR은 수학 및 코딩의 다양한 추론 작업에서 놀라운 능력을 보여줍니다.
수학에서 AZR은 도메인별 감독으로 명시적으로 미세 조정된 제로 추론 모델과 경쟁력 있는 성능을 달성합니다.
코딩 작업에서 AZR은 RLVR을 사용하여 코드 데이터셋으로 특별히 학습된 모델을 능가하는 새로운 최고 성능을 확립합니다.
AZR은 도메인 내 데이터를 사용하여 "제로" 설정에서 학습된 이전의 모든 모델보다 평균 1.8 절대 점수 더 높은 성능을 보입니다.
이러한 놀라운 결과는 인간이 선별한 도메인별 데이터 없이도 일반적인 추론 기술이 나타날 수 있음을 강조하며 Absolute Zero를 유망한 연구 방향으로 AZR을 첫 번째 중요한 이정표로 자리매김합니다.
추론을 위한 인간 데이터 없이 AZR이 달성한 놀라운 결과 외에도 저희는 다음과 같은 매우 흥미로운 발견을 요약했습니다.
코드 사전 지식은 추론을 증폭시킵니다.
기본 Qwen-Coder-7b 모델은 Qwen-7b보다 수학 성능이 3.6점 낮았습니다.
그러나 두 모델 모두에 대한 AZR 학습 후 코더 변형이 기본 모델보다 0.7점 앞섰는데 이는 강력한 코딩 능력이 AZR 학습 후 전반적인 추론 개선을 잠재적으로 증폭시킬 수 있음을 시사합니다.
AZR에서 도메인 간 전이가 더욱 두드러집니다.
RLVR 후 전문 코드 모델은 수학 정확도를 평균 0.65점만 향상시키는 반면 자체 제안 코딩 추론 작업으로 학습된 AZR-Base-7B와 AZR-Coder-7B는 각각 수학 평균을 10.9점과 15.2점 향상시켜 훨씬 더 강력한 일반화된 추론 능력 향상을 보여줍니다.
더 큰 기반 모델이 더 큰 이득을 가져옵니다.
성능 향상은 모델 크기에 따라 확장됩니다.
3B, 7B, 14B 코더 모델은 각각 +5.7점, +10.2점, +13.2점의 성능 향상을 보여주며 이는 지속적인 스케일링이 AZR에 유리함을 시사합니다.
The Absolute Zero Paradigm
Preliminaries
Supervised Fine-Tuning (SFT)
SFT는 인간 전문가 또는 우수한 AI 모델이 제공한 작업-추론-답변 데모 데이터셋 을 필요로 합니다. 여기서 는 질의, 는 정답 추론 과정, 그리고 는 정답입니다.
모델은 다음 negative log-likelihood를 최소화하여 응답을 모방하도록 학습됩니다
그러나 최첨단 수준에서는 증류할 더 강력한 모델이 없으며 전문적인 인간 레이블링은 확장성이 떨어집니다.
Reinforcement Learning with Verifiable Rewards (RLVR)
순수한 모방의 한계를 넘어서기 위해 RLVR은 레이블링된 추론 과정 없이 작업과 답변으로 이루어진 데이터셋 만을 필요로 합니다.
RLVR을 통해 모델은 자체적으로 CoT를 생성하고 정답 을 사용하여 검증 가능한 보상 을 계산할 수 있습니다.
그러나 학습 작업 분포 와 그 질의 및 정답 세트는 여전히 인간 전문가에 의해 레이블링됩니다.
학습 가능한 정책 는 기대 보상을 최대화하도록 최적화됩니다
요약하자면 SFT와 RLVR 모두 질의, 데모 또는 검증자와 같은 인간이 선별한 데이터셋에 여전히 의존합니다.
이는 확장성을 제한합니다.
Absolute Zero 패러다임은 모델이 환경과의 상호 작용을 통해 완전히 자체적으로 작업을 생성하고, 해결하고, 학습할 수 있도록 함으로써 이러한 의존성을 제거합니다.
Absolute Zero
본 논문에서는 학습 중에 모델이 동시에 작업을 제안하고, 해결하고, 두 단계 모두에서 학습하는 Absolute Zero 패러다임을 제안합니다.
외부 데이터는 필요하지 않으며, 모델은 일부 환경의 도움을 받아 완전히 자체 플레이와 경험을 통해 학습합니다.
그림 2는 지도 학습 및 RLVR과 Absolute Zero를 대조하여 자체 개선 작업 제안 및 자체 플레이를 통한 해결을 가능하게 함으로써 우리의 접근 방식이 인간이 선별한 데이터의 필요성을 어떻게 제거하는지 강조합니다.
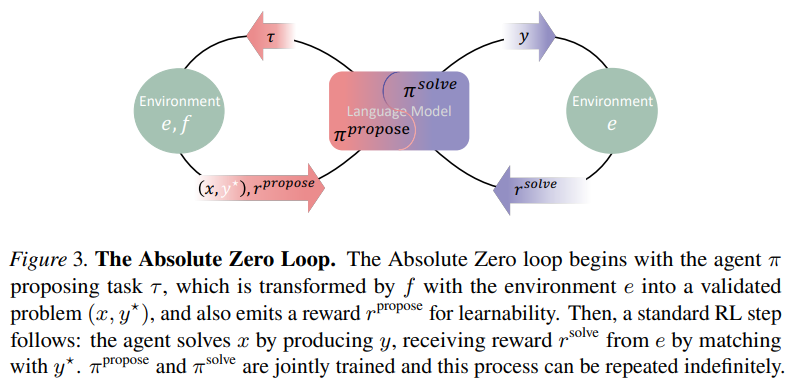
Absolute Zero 설정을 구체화하기 위해 이제 하나의 모델이 제안자와 해결자 역할을 모두 수행할 수 있는 방법을 정의합니다.
이해를 돕기 위해 그림 3에 그림을 포함했습니다. 를 우리의 파라미터화된 언어 모델이라고 합시다.
이는 학습 중에 제안자 와 해결자 의 두 가지 역할을 수행하는 데 사용됩니다.
제안자는 먼저 변수 에 조건화된 제안된 작업을 샘플링합니다:
.
그런 다음 이 작업은 검증되어 환경 와 함께 유효한 추론 작업을 구성하는 데 사용됩니다: .
여기서 는 작업 질의이고 는 정답 레이블입니다.
그런 다음 해결자는 답변 를 생성합니다.
각 제안된 작업 는 작업 질의 에 대해 학습한 후 의 예상 개선 정도를 나타내는 학습 가능성 보상 에 의해 점수가 매겨집니다.
또한 동일한 정책은 환경이 다시 검증자 역할을 하는 작업 질의 에 대한 답변에 대해 솔루션 보상 을 받습니다.
음이 아닌 계수 는 새롭고 학습 가능한 작업을 탐색하는 것과 모델의 추론 및 문제 해결 능력을 향상시키는 것 사이의 균형을 맞춥니다.
Absolute Zero 설정의 목표를 다음과 같이 공식적으로 정의합니다:
데이터 확장 부담이 인간 전문가에서 제안 정책 와 환경 로 옮겨가는 것에 주목하십시오.
이 두 역할은 학습 작업 분포를 정의-진화시키고 제안된 작업을 검증하고, 안정적이고 자율적인 학습을 지원하는 근거 있는 피드백을 제공하는 데 모두 책임이 있습니다.
제안 시 는 작업 생성을 위한 조건부 변수 역할을 합니다.
실제로 는 지속적으로 업데이트되는 작업 메모리에서 과거 쌍의 작은 하위 집합을 샘플링하여 인스턴스화할 수 있지만 패러다임에 특정 구현이 연결되어 있지는 않습니다.
제안 프로세스를 안내하기 위해 제안된 작업 를 해결함으로써 모델이 얼마나 향상될 것으로 예상되는지를 측정하는 학습 가능성 보상 를 사용합니다.
또한 솔루션 보상 는 모델 출력의 정확성을 평가합니다. 함께, 이 두 신호는 모델이 도전적이면서도 학습 가능한 작업을 제안하고, 추론 능력을 향상시키도록 안내하여 궁극적으로 자체 플레이를 통한 지속적인 개선을 가능하게 합니다.
Absolute Zero 쉬운 설명
인간이 미리 만들어 놓은 데이터 없이 인공지능 모델 스스로 문제를 만들고 풀면서 똑똑해지는 방식 -> 어린아이가 환경을 탐색하고 스스로 질문하고 답을 찾아가는 방식을 모방
Absolute Zero <- 학습에 필요한 외부 데이터 0
- 모델(LLM) 자체 역할 부여
- 제안자 (Proposer): 문제나 작업 아이디어() 생각
- 해결자 (Solver): 생각해낸 문제 직접 해결
- 문제 만들기 및 검증
- 제안자가 아이디어 생성
- 환경 이 아이디어 받아서 구체적인 문제()와 그 문제의 정답() todtjd
- 문제 풀이(해결자)
- 환경이 만들어준 문제에 대한 답 생성
- 두 가지 피드백 (보상)
- 제안 보상 : 도전적인 문제였는가를 평가하는 보상
- 해결 보상 : 문제를 얼마나 정확하게 풀었는가를 평가하는 보상
- 학습 목표
- 두 가지 보상을 모두 높이는 것
