느낀점
- 한국어 모델 중에 가장 성능이 괜찮음
- 최신 연구 팔로우가 가장 잘 되어 있고 ablation study를 하면서 진행하는 거 같음
- 추론, 비추론 비율 설정 이유 궁금
- 데이터가 얼마나 많을까?
- 스페인어 토크나이저 사용하지 않는 이유?
- 하이브리드 어탠션이 RoPE, NoPE 대신해도 성능이 괜찮은지 궁금
Abstract
EXAONE 4.0을 소개합니다.
ON-REASONING 모드와 REASONING 모드를 통합하여 EXAONE 3.5의 뛰어난 사용성과 EXAONE Deep의 고급 추론 능력을 모두 갖추고 있습니다.
에이전트 AI 시대를 열기 위해 EXAONE 4.0은 에이전트 툴 사용(agentic tool use)과 같은 필수 기능을 포함하고 있습니다.
다국어 기능이 확장되어 기존의 한국어와 영어에 더해 스페인어도 지원합니다.
EXAONE 4.0 모델 시리즈는 두 가지 크기로 구성됩니다.
미드 사이즈 32B 모델: 고성능에 최적화
스몰 사이즈 1.2B 모델: 온디바이스(on-device) 애플리케이션용
EXAONE 4.0은 동급의 공개 모델보다 뛰어난 성능을 보이며 최첨단 모델과 비교해도 경쟁력이 있습니다.
Introduction
LG AI 리서치의 EXAONE 파운데이션 모델 시리즈의 일환인 EXAONE 언어 모델은 강력한 명령 이행 및 추론 능력을 통해 다양한 실제 애플리케이션을 지원하도록 개발되었습니다.
이전 버전인 EXAONE 3.5는 종합적인 명령 이행 능력을 강화하여 실제 사용성에 중점을 두었고 EXAONE Deep은 수학 및 코딩 분야에서 추론 성능을 강조했습니다.
에이전트 AI 시대를 염두해 EXAONE 4.0은 에이전트 툴 사용(agentic tool use)을 도입하고 추론 능력을 더욱 발전시켰습니다.
툴 사용 측면에서 다양한 외부 도구를 통합하여 에이전트나 애플리케이션을 개발할 수 있도록 설계되었습니다.
추론 성능과 관련해서는 EXAONE Deep에서 개발된 검증된 방법론을 활용하여 EXAONE 4.0의 능력이 향상되었습니다.
EXAONE 4.0은 NON-REASONING 모드와 REASONING 모드를 단일 모델로 통합하여 사용자가 하나의 모델에서 두 가지 모드를 모두 경험할 수 있도록 했습니다.
이전 버전의 EXAONE과 비교하여, 사전 학습에 사용된 토큰 수가 크게 증가하여 world knowledge을 강화했습니다.
전문가 지식을 더욱 향상시키기 위해 STEM(과학, 기술, 공학, 수학) 분야와 같은 전문 영역의 훈련 데이터를 선별하는 것이 다운스트림 작업에 중요한 역할을 합니다.
모델의 최대 컨텍스트 길이가 128K 토큰으로 확장되어 훨씬 더 긴 컨텍스트를 기반으로 하는 다양한 작업을 처리할 수 있어 사용성이 향상되었습니다.
긴 컨텍스트를 처리할 때의 주목할 만한 과제는 attention calculations의 연산 부담입니다.
global attention과 local attention을 결합한 하이브리드 아키텍처를 채택했습니다.
이 접근 방식은 훈련 및 추론 중 연산 비용을 줄이면서도 성능 저하를 최소화합니다.
EXAONE 4.0은 공식적으로 스페인어를 지원 언어에 추가하여 기존의 영어 및 한국어 이중 언어 지원을 확장했습니다.
스페인어 지원 개발은 이전 EXAONE 3.5 및 Deep 모델과 동일한 토크나이저와 어휘를 유지하면서 영어와 한국어 성능에 미치는 부정적인 영향을 최소화하도록 설계되었습니다.
EXAONE 4.0은 특히 세계 지식과 추론, 특히 수학 및 코딩 분야에서 뛰어난 성능을 보입니다.
NON-REASONING 모드와 REASONING 모드를 통합했음에도 불구하고, 명령 이행에서도 경쟁력 있는 성능을 확보했습니다.
이 모델은 또한 긴 컨텍스트 작업에서도 훌륭한 성능을 보여주며 특히 실제 사용자들이 자주 사용하는 문서 QA(Question Answering) 및 RAG(Retrieval Augmented Generation) 작업에서 탁월합니다.
툴 사용 측면에서는 경쟁 모델과 유사한 수준에 도달하여, 다가오는 에이전트 AI 시대에 필수적인 기본 역량을 갖추기 시작했습니다.
Modeling
Model Configurations
EXAONE 4.0 모델은 EXAONE 3.5 모델과 비슷한 구조적 틀을 유지하지만 아키텍처에 몇 가지 주요 차이점을 포함합니다.
어텐션 메커니즘에 대한 접근 방식을 수정했습니다.
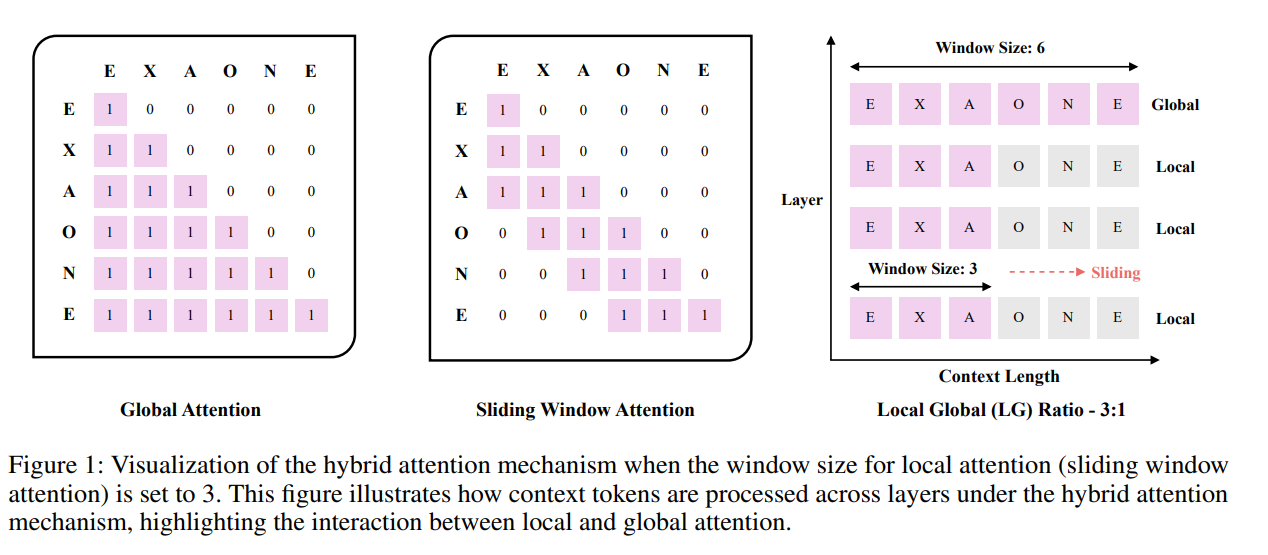
EXAONE 3.5 모델에서는 모든 레이어가 글로벌 어텐션을 사용했지만 EXAONE 4.0 모델은 그림 1에서 보는 것처럼 로컬 어텐션(슬라이딩 윈도우 어텐션 방식)과 글로벌 어텐션을 3:1 비율로 결합하는 하이브리드 어텐션 메커니즘을 사용합니다.
모든 레이어에서 글로벌 어텐션을 사용하는 모델이 더 좋은 성능을 보인다는 과거 연구 결과와 달리 최근 연구들은 더 큰 윈도우 크기(예: 512에서 1,024 또는 4,096)를 사용하고 소수의 레이어에만 글로벌 어텐션을 적용해도 여전히 우수한 장문 컨텍스트 성능을 달성할 수 있음을 시사했습니다.
Mamba와 같은 이질적인 구조와 함께 소량의 글로벌 어텐션을 주기적으로 통합하면 전역적인 컨텍스트를 이해하는 능력을 유지하는 데 도움이 된다고 보고되었습니다.
EXAONE 4.0 모델 설계 시 단문 컨텍스트 성능에 대한 부작용을 최소화하기 위해 4K의 슬라이딩 윈도우 크기를 선택했습니다.
글로벌 어텐션에 Rotary Position embedding을 사용하지 않아서 길이가 긴 문맥에 대한 편향을 방지하고 전역적인 시야를 유지할 수 있습니다.
로컬 어텐션 메커니즘 설계의 경우 청크 어텐션 전략을 사용하지 않았습니다.
안정성을 제공하는 잘 확립된 sparse attention 형태인 슬라이딩 윈도우 어텐션을 채택했습니다.
청크 어텐션과 달리 슬라이딩 윈도우 어텐션은 오픈소스 프레임워크에서 폭넓게 지원되어 강력한 구현과 손쉬운 통합이 보장됩니다.
장문 컨텍스트 미세 조정 중에 단문 컨텍스트 영역에서 성능 저하가 발생하는 것을 방지하기 위해 EXAONE 4.0 모델은 신중한 데이터 선택 방법론과 점진적 훈련 방식을 채택하여 효율성과 성능의 균형을 효과적으로 맞추고 있습니다.
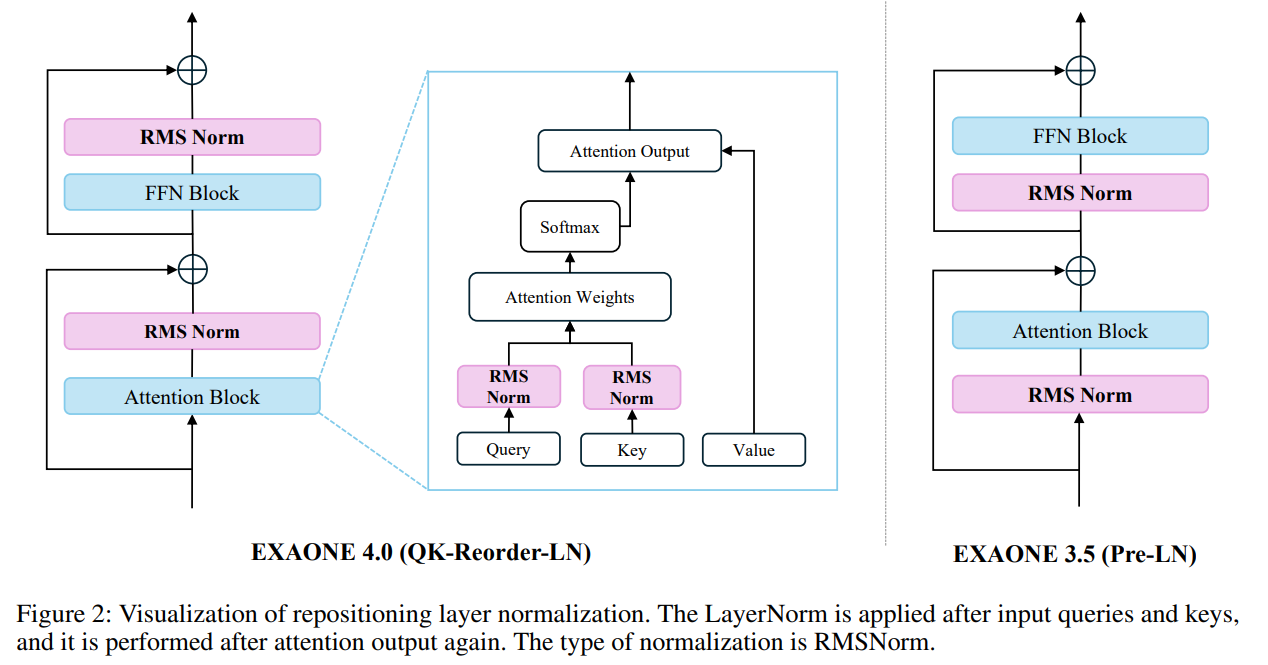
EXAONE 4.0 모델의 또 다른 중요한 변화는 그림 2에 나타난 layerNorm의 재배치입니다.
최근 연구들에 따르면, 모델 성능에 크게 영향을 미치지 않는 일부 레이어가 주로 깊은 레이어에서 발견됩니다.
이 문제는 안정성을 높이지만 모델 깊이가 깊어질수록 출력의 분산이 기하급수적으로 증가하는 Pre-LN 트랜스포머 아키텍처 때문인 것으로 분석됩니다. 레이어가 깊어짐에 따라 출력에 더 많은 스케일링을 제공하여 분산을 제어하는 간단한 연산이 제안되었지만 입력 쿼리와 키 다음에 레이어 정규화를 적용하고 어텐션 출력 후 레이어 정규화를 수행하는 QK-Reorder-LN 방식이 더 많은 연산량을 소비함에도 불구하고 다운스트림 작업에서 더 나은 성능을 제공한다는 것을 발견했습니다.
마지막으로, EXAONE 4.0 모델 시리즈는 32B와 1.2B의 두 가지 구성으로 구성됩니다.
이 모델들은 표 1에 자세히 나와 있듯이 한국어와 영어 토큰이 거의 동일한 비율로 구성된 어휘집을 공유하며, 소수의 다국어 토큰도 포함하고 있습니다.
Pre-training

엑사원(EXAONE) 4.0 모델의 사전 학습에 사용된 데이터와 컴퓨팅 자원 양은 표 2에 요약되어 있습니다.
엑사원 3.5 32B 모델의 경우 사전 학습에 6.5조 개의 토큰이 사용되었습니다.
엑사원 4.0 32B 모델은 이 양을 두 배로 늘려 14조 개의 토큰을 사용했습니다.
이렇게 데이터를 늘린 것은 모델의 세계 지식을 향상시키기 위한 것입니다.
더 광범위한 학습 데이터 사용이 성능에 뚜렷한 영향을 미치는 MMLU-Redux와 같은 지식 기반 벤치마크에서 눈에 띄는 개선을 가져옵니다.
최근 연구에서 추론 성능이 사전 학습 중에 접한 문서에서 얻은 인지 행동에 의해 크게 영향을 받는다는 점을 보여주었기 때문에 학습 후 성능을 향상시키기 위해 사전 학습 중에 엄격한 데이터 큐레이션을 수행합니다.
Context Length Extension
EXAONE 4.0 모델은 최대 컨텍스트 길이가 128K 토큰으로 확장되었습니다.
2단계 컨텍스트 길이 확장 과정을 거칩니다.
4K 토큰의 컨텍스트 길이로 사전 학습된 모델을 32K 토큰으로 확장하고, 이후 128K 토큰으로 추가 확장합니다.
장문 컨텍스트 미세 조정 과정은 모델 성능의 철저한 검증을 위해 각 단계에서 'Needle In A Haystack, NIAH' 테스트를 수행하며 세심하게 진행됩니다.
이 반복적인 개선은 모든 구간에서 일관되게 "그린 라이트" 신호가 관찰될 때까지 계속되며 이는 모델의 전반적인 성능을 저해하지 않으면서 컨텍스트 길이가 성공적으로 128K 토큰으로 확장되었음을 의미합니다.
1.2B 모델의 경우, 컨텍스트 길이가 64K 토큰까지 확장되었으며 이는 10억 매개변수(1B-parameter) 범위의 대부분 모델이 지원하는 일반적인 최대 길이인 32K 토큰보다 약 두 배 더 긴 길이입니다.
Post-training
EXAONE 4.0에서는 다양한 사용자 지시에 응답하고 비추론 및 추론 모델을 효과적으로 통합하기 위해 여러 단계의 학습을 진행합니다.
학습 과정은 크게 세 단계로 구성됩니다: 지도 미세 조정(SFT), 추론 강화 학습(RL), 그리고 그림 3에 나타난 바와 같이 비추론 및 추론 모드를 통합하기 위한 preference learning입니다.
후반부 학습 단계의 중요한 특징은 효율적인 성능 향상을 위해 SFT 데이터가 대규모로 확장되었다는 점입니다.
추론 능력을 개선하기 위해 RL이 활용됩니다. 또한, 비추론 및 추론 모드를 자연스럽게 통합하기 위해 2단계 선호 학습 과정에서 하이브리드 보상 메커니즘이 사용됩니다.
Large-scale Supervised Fine-tuning
SFT 데이터셋의 구성은 비추론 데이터와 추론 데이터로 나뉩니다.
세계 지식, 수학/코드/논리, 에이전트 도구 사용, 장문 컨텍스트, 다국어성이라는 다섯 가지 고유한 영역으로 분류될 수 있습니다.
데이터 수집 및 생성 전략은 각 목적과 영역에 따라 차별화되었으며 자세한 방법론은 다음과 같습니다.
세계 지식(World Knowledge)
세계 지식 영역은 광범위한 분야와 다양한 난이도를 포괄하므로 방대한 지식을 요약하는 것이 중요합니다.
따라서 교육적 가치를 기준으로 웹에서 수집한 문제를 필터링하고 고품질 데이터의 사용을 우선시했습니다.
이 중에서 추론 모드 학습에 활용하기 위해 전문적이고 난이도가 높은 데이터도 샘플링했습니다.
수학, 코드, 논리(Math, Code, Logic)
수학, 코드, 논리 작업의 경우 중요성에 비해 고유한 문제의 수가 상대적으로 제한적입니다.
이는 주로 이러한 영역에서 정확한 정답을 확립하는 것이 필수적이지만 어렵기 때문이며 이로 인해 원하는 만큼 많은 고품질 문제를 구축하는 데 한계가 있습니다.
따라서 검증 불가능한 문제를 생성하기보다는 검증 가능한 답변이 있는 질의에 대해 다양한 응답으로 학습하고 고유한 질의의 다양성이나 수를 늘리는 것만큼 고유한 질의당 여러 응답을 생성하는 것이 효과적임을 확인했습니다.
추론 모드에서는 수학 및 코드 영역에 대한 응답이 더 길어지는 경향이 있어 degeneration 및 언어 불일치의 위험이 증가하므로 신중한 필터링을 적용합니다.
코드 영역의 경우 문제 해결을 넘어 풀스택 개발에 초점을 맞춘 소프트웨어 엔지니어링 데이터셋을 코드 corpora로부터 생성하여 데이터 수집을 확장했습니다.
Long Context
Long Context SFT 데이터셋은 확장된 입력을 포괄적으로 이해해야 하는 작업에 초점을 맞춰 웹 말뭉치에서 구축됩니다.
분산된 정보를 식별하고 추론하도록 모델을 학습시키기 위해 컨텍스트 길이와 핵심 콘텐츠의 위치를 체계적으로 다양화했습니다.
이 데이터셋에는 장문의 응답을 생성하기 위한 instruction을 따르는 질의도 포함되어 있어 모델이 일관성 있고 구조화된 장문의 출력을 생성할 수 있도록 합니다.
한국어의 경우, 법률, 행정, 기술 문서와 같은 문서를 다듬어 장문 컨텍스트 데이터를 큐레이션합니다.
그런 다음 이 문서들을 다양한 범위의 장문 컨텍스트 입력 형식을 수용하도록 재구성하여 구조와 콘텐츠 범위에 변형을 주었습니다.
Agentic Tool Use
에이전트 도구 사용 능력을 향상시키기 위해 다양한 도구 목록을 활용하여 단일 턴 및 멀티 턴 작업에 초점을 맞춘 데이터셋을 구축합니다.
단일 도구 호출을 위한 데이터셋을 만드는 데 그치지 않, 더 복잡하고 long-horizon의 도구 호출 데이터를 구축하는 데 중점을 둡니다.
이에 따라 사용자 상호 작용, 환경으로부터의 실행 피드백, 반복적 추론을 통합하여 에이전트가 사용자가 원하는 목표를 달성하도록 안내하는 사용자-에이전트 대화를 개발합니다.
이 데이터셋은 에이전트 도구 사용 학습을 더 잘 지원하기 위해 다단계 및 다중 턴 형식으로 구성됩니다.
Multilinguality
한국어와 스페인어를 모두 지원하기 위해, 각 언어에 특화된 문화 및 역사 지식을 다루는 것뿐만 아니라 사용자와 유창하고 자연스러운 대화를 나눌 수 있도록 하는 데이터셋을 구축합니다.
양 언어로 새로운 지시문을 만들고 추가적으로 엄선된 기존 샘플을 번역하여 질의로 활용했습니다.
한국어의 경우 모델이 한국 사용자로부터의 도메인별 질의를 잘 처리할 수 있도록 관련 교육 및 산업 전문가 관련 주제를 다루는 데이터를 큐레이션합니다.
Unified Mode Training
통합 데이터셋에서 비추론 데이터는 주로 다양한 작업으로 구성되는 반면 추론 데이터는 수학 및 코드 영역에 중점을 둡니다.
두 모드를 순차적으로 미세 조정하기보다는 두 모드를 결합하여 함께 학습시킵니다.
두 모드 간의 비율은 추론 모드 데이터의 양에 의해 결정됩니다.
추론 모드의 토큰 비율이 너무 높으면 비추론 모드가 활성화되었을 때에도 모델이 추론 모드인 것처럼 동작하는 경향을 보입니다.
ablation studies를 통해 추론과 비추론 데이터의 토큰 비율을 1.5:1로 설정했습니다.
통합된 비추론/추론 모드 미세 조정 후, 도메인 불균형을 해결하기 위해 코드 및 도구 사용 영역의 고품질 추론 데이터를 사용하여 두 번째 라운드 학습을 수행하고, 이러한 샘플을 재사용하여 성능을 더욱 향상시킵니다.
