느낀점
- AGAPO를 통해서 클리핑이 추론 과정에서 중요 토큰 생성을 저해하는 점을 발견하고 standard policy gradient 통해 안정성 도모. 클리핑 관련해서 여러 논문들이 문제점을 인식하고 있는 거 같음
- Asymmetric Sampling, 모든 모델이 틀린 질문은 버리는데 해당 질문도 강화학습에 활용해서 성능 향상 시킴
- Group & Global Advantages, 전체 배치를 통해 보상을 정규화하는 점은 훈련 안전성 유지할 수 있음
- 정답이 있는 수학, 코딩과 같은 건 명확하지만 창의적인 부분 해결은 미흡
- 학습 파이프라인이 빡빡해서 연구자 레시피에 좌지우지 될 거 같은 느낌
Reasoning Reinforcement Learning
모델의 추론 능력을 향상시키기 위해 SFT 이후 온라인 강화학습을 수행합니다.
이전 연구들에서는 GRPO(Group Relative Policy Optimization) 알고리즘과 verifiable rewards을 결합하는 것이 모델 성능을 효과적으로 향상시킬 수 있음을 보여주었습니다.
기존 GRPO의 한계를 해결하기 위해 AGAPO(Asymmetric Sampling and Global Advantage Policy Optimization)라는 새로운 알고리즘을 제안합니다.
훈련 데이터셋은 수학, 코드, 과학, 지시 따르기의 네 가지 범주에 걸쳐 선별된 데이터를 포함합니다.
더 유익한 데이터 샘플에 훈련을 집중시키기 위해 정확도 기반 필터링을 수행합니다.
SFT 모델로부터 8개의 응답을 생성하고 8개의 응답이 모두 정답인 샘플은 제외합니다.
이는 모델이 비효율적인 훈련을 피하기 위해 쉽게 푸는 문제들을 제거하는 사전 필터링 단계입니다.
RL에 사용되는 보상 함수는 각 범주에 맞게 조정됩니다.
수학의 경우 규칙 기반 검증기를 사용하여 정답 여부를 결정합니다.
코드에서는 최종 코드 블록이 관련된 모든 테스트 케이스를 통과하면 정답으로 간주됩니다.
과학의 경우 먼저 규칙 기반 검증기를 적용하고 응답이 오답으로 간주되면 LLM-심판(LLM-judge)이 더 유연한 검증을 수행합니다.
마지막으로 지시 따르기 범주에서는 모든 제약 조건이 충족되면 1의 보상을, 그렇지 않으면 0의 보상을 할당합니다.
알고리즘 설계 측면에서 AGAPO는 기존 방법들을 포괄적으로 개선합니다. 주요 특징은 다음과 같습니다:
Remove Clipped Objective:
이전 연구에서는 PPO(Proximal Policy Optimization)의 clip loss의 필요성에 의문을 제기했으며 이 클리핑된 목표 함수가 결정적인 저확률 토큰들이 gradient 업데이트에 기여하는 것을 막아 성능을 저하시킬 수 있음을 보여주었습니다.
이러한 토큰들은 종종 추론 경로에서 분기점 역할을 하는 성찰적 행동과 관련이 있습니다.
AGAPO는 PPO에서 클리핑을 제거하고 대신 standard policy gradient loss을 사용합니다.
이 접근법은 이러한 탐색적 토큰들이 무시되는 것을 방지하여 훈련 안정성을 유지하면서 더 실질적인 정책 업데이트를 가능하게 하도록 설계되었습니다.
Asymmetric Sampling:
이전 연구들은 모든 응답이 정답이거나 오답인 샘플들을 필터링했습니다.
왜냐하면 이러한 샘플들은 GRPO에 대해 0의 advantage을 초래하기 때문입니다.
하지만 최근 연구에서 Negative Sample Reinforcement의 효과가 나타남에 따라 AGAPO는 모든 응답이 오답인 샘플을 버리지 않는 비대칭 샘플링 방법을 활용하여 더 높은 비율의 부정적인 피드백을 포함시킵니다.
모두 오답인 샘플들의 경우 advantage 계산을 통해 작은 음의 보상이 할당되어 모델이 잘못된 추론 경로에서 벗어나도록 유도하는 데 사용될 수 있습니다.
Group&Global Advantages:
GRPO의 이점 계산 방법은 전체 배치의 분포를 고려하지 않기 때문에 모두 오답인 응답 그룹에 적절한 음의 보상을 할당하기 어렵습니다.
이를 개선하기 위해 AGAPO는 group과 global의 두 단계로 이점을 계산합니다.
그룹 수준에서는 검증 가능한 보상 정확도에 기반하여 응답 그룹 내에서 LOO(Leave-One-Out) 방법을 사용하여 이점을 계산합니다.
전체 배치(전역)에 걸쳐 정규화를 수행하여 전체 배치 분포를 고려한 최종 이점을 계산합니다.
Sequence Level Cumulative KL:
SFT 단계에서 학습된 능력을 보존하면서 성능을 향상시키기 위해 KL 페널티가 적용됩니다.
이전 연구에서 제안된 Sequence Level Cumulative KL을 채택하여 모델이 훈련 중에 적절한 경사를 받을 수 있도록 보장합니다.
Objective
AGAPO 목표 함수는 훈련 분포 에서 샘플링된 질문 q에 대해 정의됩니다.
각 질문에 대해, 현재 정책 는 G개의 후보 응답 그룹 를 생성합니다.
각 응답 o i에는 검증 가능한 보상 이 할당됩니다.
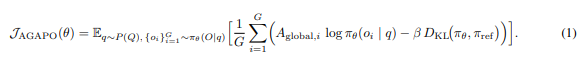
목표 함수 내의 전역 이점 는 두 단계로 계산됩니다.
각 그룹 내에서 LOO(leave-one-out) 이점이 계산됩니다.
이 이점은 이후 크기가 K=B×G인 전체 미니배치에 걸쳐 정규화되어 최종 전역 이점을 산출합니다:
Preference Learning with Hybrid Reward
강화 학습 단계에서는 검증 가능한 보상을 통해 정확성을 높이는 것을 목표로 하, 인간의 선호도는 사용하지 않습니다.
모델이 추론 작업에 특화되어 있기 때문에 다른 유형의 작업에서는 성능 저하가 관찰됩니다.
이러한 한계를 극복하기 위해 추가적인 preference learning 단계를 도입합니다.
선호 학습은 DPO(Direct Policy Optimization) 프레임워크와 유사하게 선택된 데이터와 거부된 데이터 쌍을 통해 인간의 선호도를 직접 학습함으로써 이루어집니다.
이 학습 과정에는 다양한 참조-없는 선호도 최적화 방법 중 SimPER를 사용합니다.
선호 학습을 위한 데이터셋은 RL 단계를 완료한 모델이 생성한 on-policy 응답을 기반으로 구성됩니다.
각 쿼리에 대해 작업당 4~16개의 응답을 생성하고,작업별로 맞춤 설정된 검증 가능 보상, 선호 보상, 언어 일관성 보상, 간결성 보상이 결합된 하이브리드 보상을 기반으로 선택된 응답과 거부된 응답을 선택합니다.
학습은 두 단계로 나누어 진행됩니다.
첫 번째 단계에서는 추론 모드의 성능을 유지하면서 생성 길이를 줄여 토큰 효율성을 높이는 데 중점을 둡니다.
따라서 추론 관련 검증 가능 학습 데이터의 경우 검증 가능 보상과 간결성 보상을 결합하여 정답 중에서 가장 짧은 응답을 선택된 옵션으로 선택합니다. 두 번째 단계에서는 human alignment을 위해 선호 보상과 언어 일관성 보상을 결합하여 사용합니다.
추론 모드 데이터의 경우, 추론 과정이 완료된 후 최종 답변에 대해서만 선호도 라벨링을 수행합니다.
두 번째 단계 학습 중 안정성을 확보하기 위해 첫 번째 단계의 데이터 일부를 샘플링하여 재사용합니다.
Evaluation
Benchmarks
World Knowledge
모델의 세계 지식을 평가하기 위해 다음 벤치마크를 사용했습니다.
MMLU-REDUX 및 MMLU-PRO: MMLU의 개선 및 확장 버전으로, 모델의 전반적인 지식 범위를 평가합니다.
GPQA-DIAMOND: 생물학, 물리학, 화학 분야의 전문가 수준 지식을 평가합니다.
Math/Coding
모델의 계산 능력을 평가하기 위해 다음 벤치마크를 사용했습니다.
수학:
AIME 2025
HMMT FEB 2025
두 벤치마크 모두 수학 올림피아드 대회 문제로 구성되어 있습니다.
코딩:
LIVECODEBENCH V5 및 V6
Instruction Following
모델이 사용자의 지시를 얼마나 잘 이해하고 따르는지 평가하기 위해 다음 벤치마크를 사용했습니다.
IFEVAL
MULTI-IF: 다국어 및 다중 턴 시나리오를 지원하는 IFEVAL의 확장 버전입니다. 여기서는 영어 하위 집합만을 사용해 다중 턴 명령어 이해 능력을 평가했습니다.
Long Context
모델이 장문 맥락을 이해하고 관련 작업을 해결하는 능력을 평가하기 위해 다음 벤치마크를 사용했습니다.
HELMET
RULER
LONGBENCH
HELMET의 LongCite 작업은 평가에서 제외되었습니다.
Agentic Tool Use
LLM 기반 에이전트의 도구 사용 능력을 평가하기 위해 가장 널리 사용되는 두 벤치마크를 사용했습니다.
BFCL-V3: 함수 호출 능력의 다양한 측면을 평가합니다.
TAU-BENCH: gpt-4.1-2025-04-14 모델을 사용자 역할로 사용하여 도구 호출 성능을 평가합니다.
Multilinguality
영어 외에 한국어와 스페인어에 대한 모델의 성능을 평가했습니다.
Korean
KMMLU-PRO 및 KMMLU-REDUX:
기존 KMMLU의 데이터 오류 및 오염 문제를 해결하기 위해 사용되었습니다.
전문가 및 전문 지식의 실제 적용 능력을 평가합니다.
Korean School Math (KSM): HRM8K의 하위 집합으로, 고등학교부터 올림피아드 수준까지의 다양한 수학 지식을 평가합니다.
KO-LONGBENCH: 장문 맥락의 한국어 입력 처리 능력을 평가하는 자체 벤치마크입니다.
Spanish
MMMLU (ES) 및 MATH500 (ES): 기존 벤치마크의 스페인어 번역 버전을 사용했습니다.
WMT24++: 번역 품질을 평가하는 데 사용되는 벤치마크입니다. 영어-스페인어 쌍에 대해서만 평가했으며, LLM-as-a-judge를 통해 점수를 매겼습니다.
Baselines
다양한 관점에서 언어 모델의 성능을 평가하기 위해 최근 공개된 오픈-웨이트 모델들이 베이스라인 모델로 선정되었습니다.
이 모델들에는 비슷한 규모의 모델뿐만 아니라 100B(1000억)개 이상의 파라미터를 가진 최첨단 모델들도 포함되어 있으며 이들은 뛰어난 성능을 보여줍니다.
이 모델들은 세 가지 유형으로 나눌 수 있습니다:
- 비추론(Non-Reasoning) 모델: CoT(Chain-of-Thought) 스타일로 응답을 생성합니다.
- 추론(Reasoning) 모델: long CoT 스타일로 응답을 생성합니다.
- 하이브리드(Hybrid) 모델: 모드에 따라 CoT 또는 long CoT 스타일로 응답을 생성합니다.
Experimental Setup
하이퍼파라미터
평가 안정성을 보장하기 위해 제한된 예제를 가진 각 벤치마크 문제에 대해 n개의 다른 응답을 샘플링합니다.
구체적으로 GPQA-DIAMOND는 n = 8, AIME 2025와 HMMT FEB 2025는 n = 32, LIVECODEBENCH V5/6, TAU-BENCH, MATH500 (ES)는 n = 4를 샘플링합니다.
정확도는 n개의 샘플에 대한 평균값입니다.
REASONING 모드에서는 temperature를 0.6, top-p를 0.95로 설정하고, 32B 모델에만 1.5의 presence penalty를 적용합니다.
NON-REASONING 모드에서는 단일(n=1) 응답 생성 시 greedy decoding을 사용하며, n > 1개의 응답을 생성할 때는 추론 모드와 동일한 샘플링 설정(presence penalty는 0.0)을 사용합니다.
AIME 2025, HMMT FEB 2025, LIVECODEBENCH V5/6 및 KSM 벤치마크에서는 최대 64K 토큰을 생성하고, 다른 벤치마크에서는 32K 토큰을 생성합니다.
소형 모델의 긴 컨텍스트 평가
SMALL-SIZE 비추론 모델의 긴 컨텍스트 성능을 평가할 때, Qwen3 1.7B와 Qwen3 0.6B의 32K 토큰 한계를 넘기 위해 YaRN [45]을 적용하여 최대 64K 토큰까지 추론이 가능하도록 했습니다.
참고로, Gemma-3-1B, EXAONE-3.5-2.4B-Instruct, Qwen3 1.7B, Qwen3 0.6B와 같은 모델의 최대 32K 토큰 컨텍스트 길이에서의 평가 결과는
베이스라인 재현
베이스라인 모델의 경우, 사용 가능한 경우 각 모델의 공식 기술 보고서, 블로그, 또는 리더보드6에 보고된 점수를 사용했습니다.
그렇지 않은 경우, 명시된 권장 설정을 따라 평가 환경에서 결과를 재현했습니다.
Experimental Results
주요 결과는 다음과 같이 요약할 수 있습니다:
수학/코딩 분야의 우월성
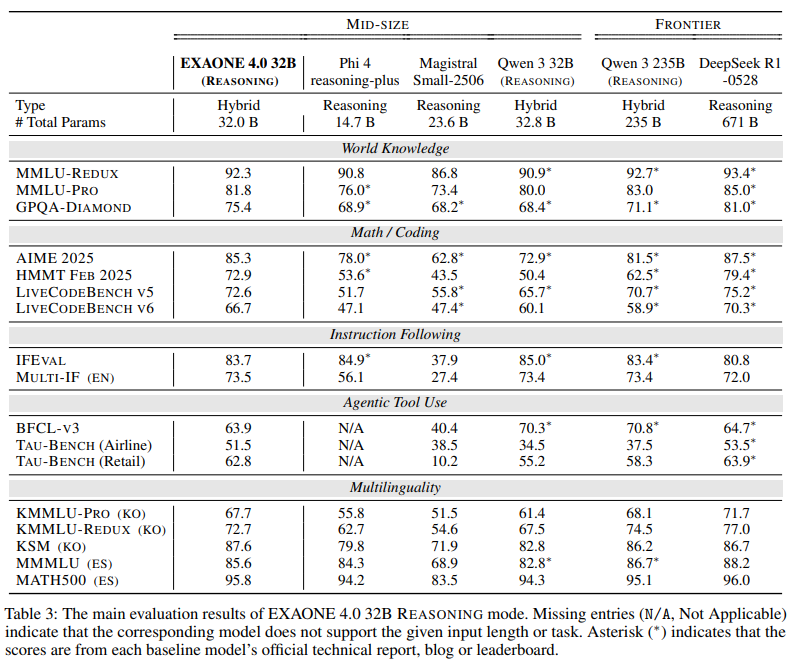
EXAONE 4.0 모델은 수학/코딩 벤치마크에서 뛰어난 성능을 보였습니다.
EXAONE 4.0 32B 모델은 모든 수학/코딩 벤치마크에서 추론 및 비추론 모드 모두 Qwen3 235B를 능가했습니다.
EXAONE 4.0 1.2B 모델은 추론 모드의 EXAONE Deep 2.4B를 제외한 모든 베이스라인을 뛰어넘는 성능을 보였습니다.
도구 사용 시나리오에서의 경쟁력 있는 성능
EXAONE 4.0 32B 모델은 베이스라인 모델들과 비교하여 tool use 측면에서 경쟁력 있는 성능을 보여줍니다.
추론 모드에서는 TAU-BENCH에서 R1-0528과 비슷한 성능을 보였고 비추론 모드에서는 BFCL-V3 결과에서 Qwen3 235B와 비슷한 결과를 달성했습니다. 이는 두 베이스라인 모델이 EXAONE 4.0 모델보다 훨씬 크다는 점을 고려하면 주목할 만한 결과입니다.
EXAONE 4.0 1.2B 모델은 작은 크기에도 불구하고 TAU-BENCH(Retail)에서 베이스라인 대비 가장 높은 성능을 달성했습니다.
세계 지식 및 GPQA
두 모델 모두 World Knowledge 카테고리의 벤치마크에서 뛰어난 성적을 거두었습니다.
베이스라인 모델에 비해 상대적으로 크기가 작음에도 불구하고 경쟁력 있는 성능을 달성했습니다.
벤치마크 중에서도 EXAONE 4.0 모델은 특히 GPQA-DIAMOND에서 더 나은 성능을 보여주었습니다.
EXAONE 4.0 32B와 1.2B 모델 모두 추론 모드를 사용할 수 있을 때 GPQA-DIAMOND에서 두 번째로 높은 성능을 달성했습니다.
Reasoning Budget
추론에 사용되는 토큰의 수를 조절하고 추론 예산에 따라 성능이 어떻게 변하는지 관찰했습니다.
주 실험에서 수학/코딩 카테고리 벤치마크의 최대 토큰 수를 64K로 설정한 반면 이 섹션에서는 추론에 사용되는 토큰 수를 1K에서 64K까지 다양하게 설정했습니다.
모델의 생성이 최대 토큰 예산에 도달하면 생성을 중단하고 "사용자의 제한된 시간을 고려하여, 지금 바로 생각에 기반한 해결책을 제시해야 합니다."라는 텍스트를 추가한 후 답변 부분을 생성하도록 진행했습니다.
주 실험과 동일한 수의 샘플링 응답(AIME 2025는 n = 32, LIVECODEBENCH V6는 n = 4)을 각 쿼리에 사용하고, n개의 응답에 대한 평균 결과를 도출했습니다. 답변 부분의 길이는 8K로 고정했습니다.
추론 예산이 줄어들면 성능 저하가 일부 발생하지만 EXAONE 4.0 모델은 32K의 추론 예산에서도 여전히 경쟁력 있는 성능을 보여줍니다.
AIME 2025의 32B 모델이 12.3%의 성능 감소를 보인 것을 제외하고는, 다른 모델들의 감소율은 5%와 비슷하거나 그보다 낮아 베이스라인 모델에 비해 경쟁력 있는 결과를 유지했습니다.
