Abstract
총 3550억 개의 파라미터와 320억 개의 활성 파라미터를 가진 오픈소스 MoE(Mixture-of-Experts) 대규모 언어 모델인 GLM-4.5를 선보입니다.
이 모델은 thinking 모드와 direct response 모드를 모두 지원하는 하이브리드 추론 방식을 특징으로 합니다.
GLM-4.5는 23조(23T) 개의 토큰에 대한 다단계 훈련과 전문가 모델 반복 및 강화 학습을 통한 포괄적인 후속 훈련을 통해 agentic, reasoning, coding(ARC) 과제 전반에 걸쳐 강력한 성능을 달성했습니다.
주요 벤치마크 점수는 TAU-Bench 70.1%, AIME 24 91.0%, SWE-bench Verified 64.2%입니다.
GLM-4.5는 여러 경쟁 모델보다 훨씬 적은 파라미터를 가지고 있음에도 불구하고, 평가된 모든 모델 중 전체 3위, 에이전트 벤치마크에서는 2위를 차지했습니다. 저희는 추론 및 에이전트 AI 시스템 연구 발전을 위해 GLM-4.5 (3550억 파라미터)와 더 작은 버전인 GLM-4.5-Air (1060억 파라미터)를 함께 공개합니다.
오픈소스 모델 중에서 인상적인 성능을 보여주고 있는 모습
Introduction
LLM은 일반적인 지식 저장소에서 벗어나 만능 문제 해결사로 빠르게 발전하고 있습니다.
AGI의 궁극적인 목표는 다양한 영역에서 인간 수준의 인지 능력을 갖춘 모델을 만드는 것입니다.
이를 위해서는 특정 작업에서의 탁월함을 넘어, 복잡한 문제 해결, 일반화, 스스로 개선하는 능력을 통합적으로 갖추어야 합니다.
LLM이 실제 환경에 더 깊숙이 통합됨에 따라 실제 생산성을 높이고 복잡한 전문 작업을 해결하기 위한 핵심 역량을 개발하는 것이 중요해졌습니다.
진정한 범용 모델의 척도가 되는 세 가지 핵심 상호 연결된 역량을 제시합니다: 외부 도구 및 현실 세계와 상호 작용하는 Agentic abilities, 수학 및 과학과 같은 영역에서 다단계 문제를 해결하는 complex Reasoning, 실제 소프트웨어 공학 작업을 다루는 advanced Coding skills입니다.
OpenAI의 o1/o3나 Anthropic의 Claude Sonnet 4와 같은 최첨단 독점 모델들은 특정 ARC(에이전트, 추론, 코딩) 영역(예: 수학적 추론 또는 코드 수정)에서 획기적인 성능을 보여주었지만, 이 세 가지 영역 모두에서 탁월한 단일의 강력한 오픈 소스 모델은 아직까지 찾아보기 힘들었습니다.
새로운 모델: GLM-4.5와 GLM-4.5-Air
모든 역량을 통합하려는 목표를 가지고 두 개의 새로운 모델, GLM-4.5와 GLM-4.5-Air를 소개합니다.
-
새로운 모델들은 기존의 오픈 소스 LLM 모델들을 에이전트, 추론, 코딩 작업 전반에서 능가하며, 상당한 성능 향상을 보였습니다.
-
GLM-4.5와 GLM-4.5-Air는 모두 하이브리드 추론 모드를 특징으로 합니다: 복잡한 추론 및 에이전트 작업을 위한 thinking mode'와 즉각적인 응답을 위한 non-thinking mode입니다.
-
GLM-4.5는 총 355B 파라미터와 활성화된 32B 파라미터를 가진 MoE(Mixture of Experts) 모델입니다. GLM-4.5는 다음의 ARC 벤치마크에서 강력한 성능을 보여줍니다.
-
에이전트: TAU-Bench에서 70.1%, BFCL v3에서 77.8%를 기록하여 Claude Sonnet 4와 비슷한 수준입니다. 웹 브라우징 에이전트의 경우, BrowseComp에서 26.4%를 기록하여 Claude Opus 4(18.8%)를 훨씬 능가하고 o4-mini-high(28.3%)에 근접했습니다.
-
추론: 다양한 난이도의 추론 벤치마크에서 뛰어난 성능을 보였으며, AIME 24에서 91.0%, GPQA에서 79.1%, LiveCodeBench에서 72.9%, HLE(Humanity’s Last Exam)에서 14.4%를 달성했습니다.
-
코딩: SWE-bench Verified에서 64.2%, Terminal-Bench에서 37.5%를 기록하여 GPT-4.1 및 Gemini-2.5-pro를 능가하고 Claude Sonnet 4에 근접했습니다.
-
-
GLM-4.5-Air는 106B 파라미터를 가진 더 작은 MoE 모델입니다. 이 모델은 100B 규모 모델들 중 상당한 도약을 의미하며, Qwen3-235B-A22B 및 MiniMax-M1과 비슷한 수준이거나 능가하는 성능을 보여줍니다.
평가 결과 및 접근성
-
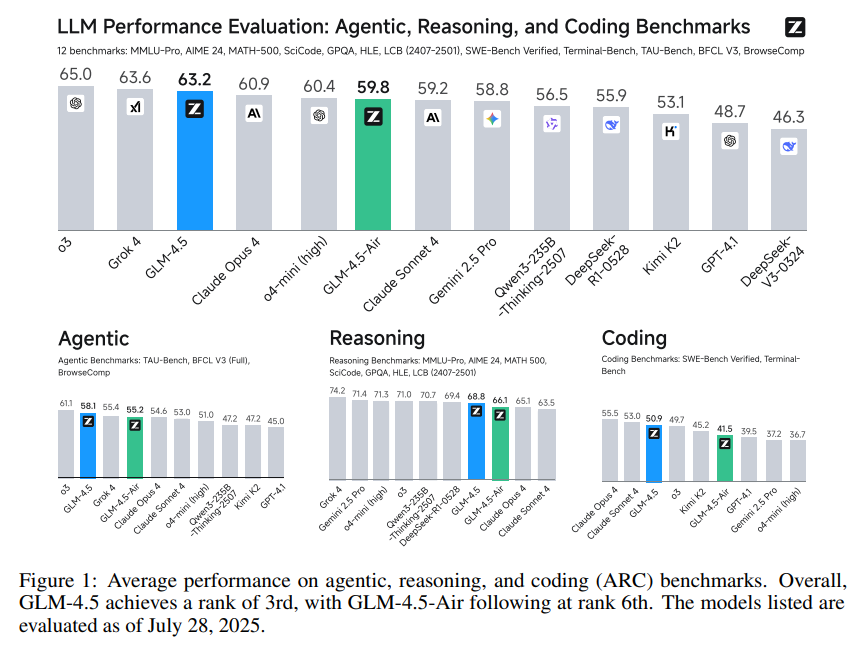
그림 1은 에이전트, 추론, 코딩(ARC) 작업 전반에 걸친 12개 벤치마크의 평균 성능을 보여줍니다. 전반적으로 GLM-4.5는 3위, GLM-4.5-Air는 6위를 기록했습니다. 에이전트 작업에서는 OpenAI o3에 이어 2위, 코딩 작업에서는 Claude Sonnet 4에 근접한 3위를 차지했습니다.
-
GLM-4.5는 DeepSeek-R1의 절반, Kimi K2의 3분의 1에 불과한 파라미터 수를 가지고 있어 매우 효율적입니다.
-
그림 2는 SWE-bench Verified 점수와 다양한 오픈 소스 모델의 파라미터 수를 보여주는데, GLM-4.5와 GLM-4.5-Air가 Pareto Frontier에 위치하고 있음을 알 수 있습니다. 더 자세한 평가 결과는 섹션 4에 명시되어 있습니다.
Pre-Training
Architecture
GLM-4.5 시리즈에서는 MoE(Mixture of Experts) 아키텍처를 채택하여 학습 및 추론의 계산 효율성을 향상시켰습니다.
MoE 레이어에는 loss-free balance routing과 sigmoid gates를 사용합니다.
DeepSeek-V3, Kimi K2와 달리, 더 깊은 모델이 더 나은 추론 능력을 보인다는 것을 발견하여 모델의 너비(히든 차원 및 라우팅된 전문가 수)를 줄이고 높이(레이어 수)를 늘렸습니다.
self-attention 구성 요소에는 부분 RoPE를 적용한 Grouped-Query Attention을 사용합니다.
어텐션 헤드 수를 2.5배(5120 히든 차원에 대해 96개 헤드) 늘렸습니다.
헤드 수를 늘려도 헤드가 더 적은 모델에 비해 학습 손실이 개선되지는 않았지만, MMLU 및 BBH와 같은 추론 벤치마크에서는 성능이 지속적으로 향상되었습니다.
어텐션 로짓의 범위를 안정화하기 위해 QK-Norm도 통합했습니다.
GLM-4.5와 GLM-4.5-Air 모두 추론 시 speculative decoding을 지원하기 위해 MTP(Multi-Token Prediction) 레이어로 MoE 레이어를 추가했습니다.
Pre-Training Data
사전 훈련 코퍼스는 웹페이지, 소셜 미디어, 서적, 논문, 코드 저장소의 문서들로 구성됩니다.
각 출처에 맞는 데이터 처리 파이프라인을 신중하게 설계했습니다.
-
웹: 사전 훈련 문서의 대부분은 인터넷에서 수집한 영어 및 중국어 웹페이지입니다. Nemotron-CC에서 영감을 받아, 수집된 웹페이지를 quality scores의 버킷으로 나눴습니다. 품질 점수가 높은 버킷의 문서는 더 많이 샘플링하고, 가장 낮은 품질 점수의 버킷에 있는 문서는 폐기합니다. 가장 높은 품질 점수의 버킷은 사전 훈련 과정에서 3.2 epochs 이상 기여합니다. 이 방식을 통해 사전 훈련 코퍼스는 추론 작업에 필요한 고빈도 지식을 강조하는 동시에 long-tail 세계 지식의 범위를 개선할 수 있습니다. 템플릿에서 자동으로 생성되어 높은 점수를 받은 유사한 웹페이지가 다수 발견되었는데, 이는 MinHash 중복 제거로는 제거할 수 없었습니다. 따라서 문서 임베딩을 기반으로 유사 웹페이지를 제거하기 위해 SemDedup 파이프라인을 추가로 적용했습니다.
-
다국어: 더 많은 자연어를 지원하기 위해, 사전 훈련 코퍼스에 다국어 문서를 포함했습니다. 다국어 코퍼스는 자체 수집한 웹페이지와 Fineweb-2 [27]에서 가져왔습니다. 문서의 교육적 유용성을 판단하는 품질 분류기를 적용하여 고품질 다국어 문서를 더 많이 샘플링합니다.
-
코드: GitHub 및 다양한 코드 호스팅 플랫폼에서 소스 코드 데이터를 선별했습니다. 코드 코퍼스는 예비 규칙 기반 필터링을 거친 후, 언어별 품질 모델을 사용하여 샘플을 세 가지 등급(고품질, 중간 품질, 저품질)으로 분류합니다. 훈련 중에는 고품질 코드를 더 많이 샘플링하고 저품질 샘플은 제외합니다. 모든 소스 코드 데이터에 대해 Fill-In-the-Middle 훈련 목표를 적용했습니다. 코드 관련 웹 문서의 경우, 텍스트 사전 훈련 코퍼스에서 2단계 검색 프로세스를 사용합니다. 문서는 먼저 HTML 코드 태그의 존재 유무 또는 코드 관련 내용을 감지하도록 훈련된 FastText 분류기를 통해 1차적으로 선택됩니다. 검색된 문서는 전용 모델을 통해 품질 평가를 거쳐 고품질, 중간 품질, 저품질 범주로 분류되며, 소스 코드와 동일한 품질 기반 샘플링 전략을 따릅니다. 마지막으로, 선택된 웹페이지에 대해 fine-grained parser를 사용하여 코드의 형식과 내용을 더 잘 보존하도록 re-parse합니다.
-
수학 & 과학: 추론 능력 강화를 위해 웹페이지, 서적, 논문에서 수학 및 과학 관련 문서를 수집합니다. 대규모 언어 모델을 사용하여 수학 및 과학에 대한 교육 콘텐츠의 비율을 기준으로 후보 문서의 점수를 매기고, 소규모 분류기를 훈련하여 이 점수를 예측합니다. 특정 임계값 이상의 점수를 받은 문서는 사전 훈련 코퍼스에서 더 많이 샘플링됩니다.
GLM-4.5의 사전 훈련 과정은 두 단계로 나뉩니다. 첫 번째 단계에서는 주로 웹페이지의 일반 문서로 모델을 훈련합니다. 두 번째 단계에서는 GitHub의 소스 코드와 코딩, 수학, 과학 관련 웹페이지를 더 많이 샘플링하여 훈련합니다.
Mid-Training: Boost Reasoning & Agentic Capacity
pre-training 이후 중요한 응용 분야에서 모델의 성능을 더욱 향상시키기 위해 몇 가지 단계를 추가합니다.
대규모 일반 문서로 전통적인 사전 학습을 하는 것과 달리, 이 학습 단계들은 명령어 데이터를 포함한 중간 규모의 도메인 특화 데이터셋을 활용합니다. 따라서 우리는 이 학습 단계들을 미드 트레이닝이라고 부르며, 다음을 포함합니다.
저장소(Repo) 수준 코드 트레이닝
이 학습 단계에서는 동일한 저장소의 연결된 코드 파일들을 추가하여 크로스 파일 종속성을 학습합니다. 모델의 소프트웨어 엔지니어링 능력을 향상시키기 위해, GitHub에서 모델이 필터링한 이슈, PR(Pull Requests), 커밋도 포함합니다. 관련된 이슈, PR, 커밋을 하나의 맥락으로 연결하고, 커밋은 'diff(변경사항)'와 유사한 형식으로 구성됩니다. 대규모 저장소를 포함하기 위해 학습 시퀀스 길이를 4K에서 32K로 확장합니다.
합성 추론 데이터 트레이닝
이 단계에서는 수학, 과학, 코딩 대회에 대한 합성 추론 콘텐츠를 추가합니다. 웹페이지와 책에서 추론 작업과 관련된 다수의 질문과 답변을 수집하고, 추론 모델을 사용하여 추론 과정을 합성합니다.
긴 맥락(Long-context) 및 에이전트 트레이닝
모델의 긴 맥락 성능을 더욱 향상시키기 위해, 학습 시퀀스 길이를 32K에서 128K로 확장하고, 사전 학습 말뭉치에서 긴 문서를 업샘플링합니다. 대규모 합성 에이전트 궤적(trajectories)도 이 단계에 통합됩니다.
