느낌점
- 새로운 소형화 멀티모달 모델
- MoE 불신?이 있어서 16.4B 파라미터에 활성화 3B 정도
- Native-resolution을 입력 받을 수 있게 조정한 모습 인상적
- 한국어 테스트를 간단하게 해봤는데 nlp 단독으로는 역시 별로...
- 한국어 VL도 오픈소스로 누군가 해줬으면...
Abstract
Kimi-VL은 고급 다중 모드 추론, 긴 문맥 이해, 강력한 에이전트 기능을 제공하는 효율적인 MoE VLM입니다.
언어 디코더에서 단 28억 개의 파라미터만 활성화하는 Kimi-VL-A3B 모델을 제공합니다.
Kimi-VL은 다양한 어려운 영역에서 뛰어난 성능을 보여줍니다.
범용 VLM으로서 멀티턴 에이전트 작업에서 좋은 성능을 보입니다.
대학 수준의 이미지 및 비디오 이해, OCR, 수학적 추론, 다중 이미지 이해 등 다양한 비전-언어 작업에서 좋은 능력을 보여줍니다.
비교 평가에서 GPT-4omini, Qwen2.5-VL-7B, Gemma-3-12B-IT와 같은 최첨단 효율적인 VLM과 효과적으로 경쟁할만 하며 일부 주요 영역에서는 GPT-4o를 능가합니다.
Kimi-VL은 긴 문맥 처리 및 명확한 인식에서도 발전된 성능을 보여줍니다.
128K 확장 문맥 창을 통해 다양한 긴 입력을 처리할 수 있고 LongVideoBench에서 64.5점, MMLongBench-Doc에서 35.1점의 괜찮은 점수를 달성합니다.
네이티브 해상도 비전 인코더인 MoonViT는 초고해상도 입력을 보고 이해할 수 있고 일반적인 작업에서 낮은 계산 비용을 유지하면서 InfoVQA에서 83.2점, ScreenSpot-Pro에서 34.5점을 달성합니다.
Kimi-VL을 기반으로 고급 long term 사고 변형 모델인 Kimi-VL-Thinking을 소개합니다.
CoT, SFT, RL을 통해 개발된 이 모델은 강력한 long term think 능력을 보여줍니다.
28억 개의 활성화된 LLM 파라미터를 유지하면서 MMMU에서 61.7점, MathVision에서 36.8점, MathVista에서 71.3점을 달성하여 효율적이면서도 다중 모드 사고 모델의 새로운 기준을 제시합니다.
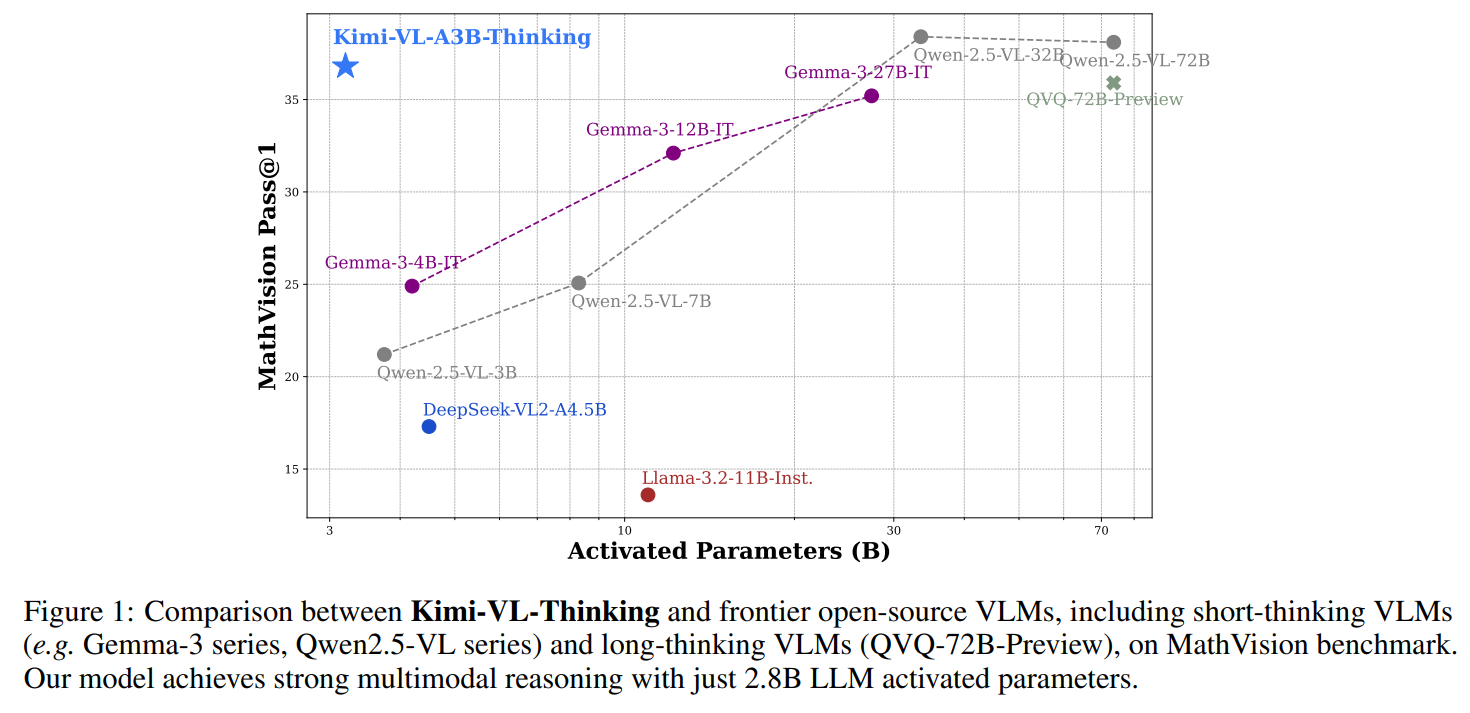
- 좌상단에 위치한 모습
- 활성화 파라미터가 경쟁력이 있는 모습
Introduction
인공지능의 발전과 함께 인간의 AI 어시스턴트에 대한 기대는 전통적인 언어 중심의 상호작용을 넘어 본질적인 multimodal 특성에 맞춰 증가하고 있습니다.
GPT4o, Google Gemini와 같은 새로운 세대의 네이티브 multimodal 모델들이 등장하여 언어 처리와 함께 시각적 입력을 인식하고 해석하는 능력을 갖추게 되었습니다.
OpenAI o1 시리즈, Kimi k1.5에 의해 개척된 고급 multimodal 모델들이 multimodal 입력에 대한 더 깊고 긴 추론을 통합함으로써 이러한 경계를 더욱 확장하여 multimodal 영역에서 더 복잡한 문제를 해결하고 있습니다.
그럼에도 불구하고 오픈 소스 커뮤니티에서 대규모 VLM의 개발은 특히 확장성, 계산 효율성 및 고급 추론 능력 측면에서 언어 전용 모델에 비해 상당히 뒤처져 있습니다.
NLP 전용 모델인 DeepSeek R1은 이미 효율적이고 확장 가능한 MoE 아키텍처를 활용하여 정교한 CoT 추론을 향상 시켰지만 Qwen2.5-VL, Gemma-3 와 같은 대부분의 최근 오픈 소스 VLM은 여전히 Dense architecture에 의존하며 긴 CoT 추론을 지원하지 않습니다.
DeepSeek-VL2, Aria와 같은 MoE 기반 VLM 모델에 대한 초기 연구는 다른 중요한 측면에서 한계를 보입니다.
아키텍처적으로 두 모델 모두 여전히 전통적인 고정 크기 시각 인코더를 채택하여 다양한 시각 입력에 대한 적응성을 저해합니다.
능력 측면에서 DeepSeek-VL2는 제한된 컨텍스트 길이(4K)만 지원하고, Aria는 세밀한 시각 작업에서 부족합니다.
둘 다 긴 사고 능력을 지원하지 않습니다.
구조적 혁신, 안정적인 기능 및 긴 사고를 통한 향상된 추론을 효과적으로 통합하는 오픈 소스 VLM에 대한 절실한 필요성이 남아 있습니다.
오픈 소스 커뮤니티를 위한 시각 언어 모델인 Kimi-VL을 제시합니다.
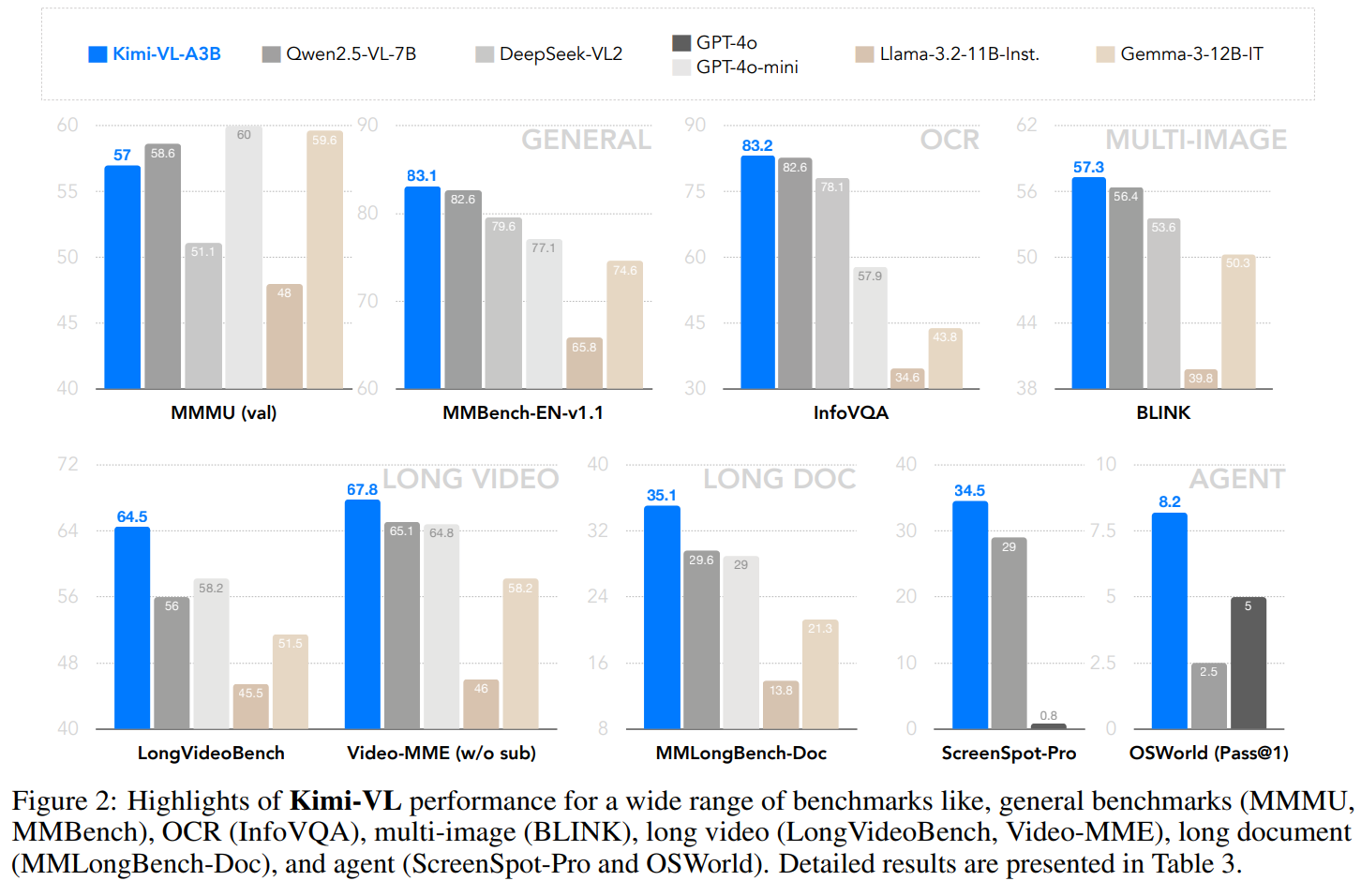
구조적으로 Kimi-VL은 28억 활성 파라미터(총 160억)를 가진 Moonlight MoE 언어 모델과 4억 네이티브 해상도 MoonViT 시각 인코더로 구성됩니다. 능력 측면에서 그림 2에서 볼 수 있듯이 Kimi-VL은 다양한 입력 형태(단일 이미지, 다중 이미지, 비디오, 긴 문서 등)에 걸쳐 다양한 작업(세밀한 인식, 수학, 대학 수준 문제, OCR, 에이전트 등)을 처리할 수 있습니다.
다음과 같은 흥미로운 능력을 제공합니다.
Kimi-VL은 똑똑합니다. 효율적인 순수 텍스트 LLM과 비교할 만한 텍스트 능력을 가지고 있습니다. 긴 사고 없이도 MMMU, MathVista, OSWorld와 같은 다중 모드 추론 및 다중 턴 에이전트 벤치마크에서 이미 경쟁력을 갖추고 있습니다.
Kimi-VL은 길게 처리합니다. 128K 컨텍스트 창 내에서 다양한 다중 모드 입력에 대한 긴 컨텍스트 이해를 효과적으로 처리하며, 긴 비디오 벤치마크 및 MMLongBench-Doc에서 유사한 규모의 경쟁자보다 훨씬 앞서 있습니다.
Kimi-VL은 명확하게 인식합니다. 다양한 시각 언어 시나리오(시각적 인식, 시각적 세계 지식, OCR, 고해상도 OS 스크린샷 등)에서 기존의 효율적인 밀집 및 MoE VLM에 비해 전반적으로 경쟁력 있는 능력을 보여줍니다.
또한, 긴 CoT 활성화 및 강화 학습(RL)을 통해 우리는 Kimi-VL의 긴 사고 버전인 Kimi-VL-Thinking을 도입하여 더욱 복잡한 다중 모드 추론 시나리오에서 성능을 크게 향상시킵니다. 작은 규모에도 불구하고 Kimi-VL-Thinking은 어려운 추론 벤치마크(예: MMMU, MathVision, MathVista)에서 강력한 성능을 제공하며, 훨씬 더 큰 규모의 많은 최첨단 VLM을 능가합니다.
- Kimi-VL is smart: 효율적인 순수 텍스트 LLM과 비교할 만한 텍스트 처리 능력을 가지고 있습니다. 긴 사고 없이도 MMMU, MathVista, OSWorld와 같은 multimodal 추론 및 다중 턴 에이전트 벤치마크에서 이미 경쟁력을 갖추고 있습니다.
- Kimi-VL processes long: 128K 컨텍스트 창 내에서 다양한 multimodal 입력에 대한 긴 컨텍스트 이해를 효과적으로 처리하며 긴 비디오 벤치마크 및 MMLongBench-Doc에서 유사한 규모의 모델보다 훨씬 앞서 있습니다
- Kimi-VL perceives clear: 다양한 VLM 시나리오(시각적 인식, 시각적 세계 지식, OCR, 고해상도 OS 스크린샷 등)에서 기존의 효율적인 밀집 및 MoE VLM에 비해 전반적으로 경쟁력 있는 능력을 보여줍니다.
긴 CoT 활성화 및 RL을 통해 Kimi-VL의 긴 사고 버전인 Kimi-VL-Thinking을 도입하여 더욱 복잡한 다중 모드 추론 시나리오에서 성능을 크게 향상시킵니다.
작은 규모에도 불구하고 Kimi-VL-Thinking은 어려운 추론 벤치마크(MMMU, MathVision, MathVista)에서 강력한 성능을 제공하며 훨씬 더 큰 규모의 많은 최첨단 VLM을 능가합니다.
Approach
Model Architecture
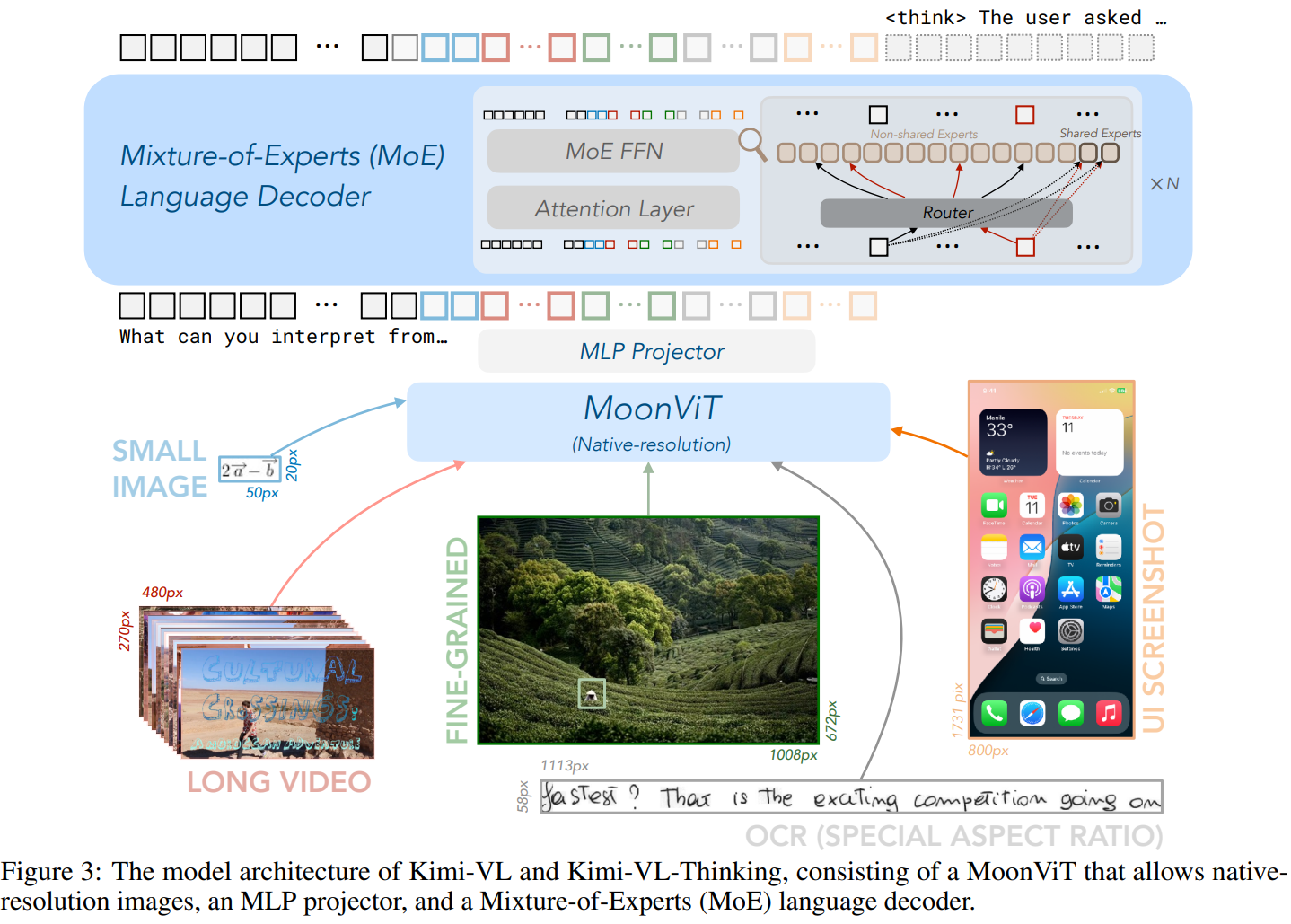
Kimi-VL의 아키텍처는 그림 3에서 볼 수 있듯이 네이티브 해상도 비전 인코더(MoonViT), MLP 프로젝터, MoE 언어 모델의 세 부분으로 구성됩니다.
각 부분을 이 섹션에서 소개합니다.
MoonViT: A Native-resolution Vision Encoder
Kimi-VL의 비전 인코더인 MoonViT는 다양한 해상도의 이미지를 네이티브 해상도로 처리하도록 설계되어 LLaVA-OneVision에서 사용된 복잡한 하위 이미지 분할 및 접합 작업을 제거합니다.
NaViT의 패킹 방법을 통합하여 이미지를 패치로 나누고 평탄화하여 1D 시퀀스로 순차적으로 연결합니다.
이러한 전처리 작업을 통해 MoonViT는 FlashAttention에서 지원하는 variable-length sequence attention mechanism과 같은 언어 모델과 동일한 핵심 계산 연산자 및 최적화를 공유하여 다양한 해상도의 이미지에 대해 손상되지 않은 학습 처리량을 보장합니다.
MoonViT는 학습 가능한 고정 크기 절대 위치 임베딩을 사용하여 공간 정보를 인코딩하는 SigLIP-SO-400M에서 초기화되고 지속적으로 사전 학습됩니다.
SigLIP의 기능을 더 잘 보존하기 위해 이러한 원래 위치 임베딩을 보간하지만 이미지 해상도가 증가함에 따라 이러한 보간된 임베딩은 점점 부적절해집니다.
이러한 제한을 해결하기 위해 높이 및 너비 차원에 걸쳐 2D 회전 위치 임베딩(RoPE)을 통합하여 고해상도 이미지에서 세밀한 위치 정보의 표현을 향상시킵니다.
이러한 두 가지 위치 임베딩 접근 방식은 함께 작동하여 모델의 공간 정보를 인코딩하고 평탄화 및 패킹 절차와 원활하게 통합됩니다.
이러한 통합을 통해 MoonViT는 동일한 배치 내에서 다양한 해상도의 이미지를 효율적으로 처리할 수 있습니다.
결과적인 연속 이미지 특징은 MLP 프로젝터로 전달되고 최종적으로 후속 학습 단계를 위해 MoE 언어 모델로 전달됩니다.
MLP Projector
비전 인코더(MoonViT)와 LLM을 연결하기 위해 2계층 MLP를 사용합니다.
픽셀 셔플 연산을 사용하여 MoonViT에서 추출한 이미지 특징의 공간 차원을 압축하고 공간 영역에서 2×2 다운샘플링을 수행하고 그에 따라 채널 차원을 확장합니다.
픽셀 셔플된 특징을 2계층 MLP에 연결하여 LLM 임베딩의 차원으로 투영합니다.
Mixture-of-Experts (MoE) Language Model
Kimi-VL의 언어 모델은 2.8B 활성화 파라미터 16B 총 파라미터 및 DeepSeek-V3와 유사한 아키텍처를 가진 MoE 언어 모델인 Moonlight 모델을 사용합니다.
구현을 위해 Moonlight의 pre-training stage의 intermediate checkpoint에서 초기화합니다.
이 체크포인트는 5.2T 토큰의 순수 텍스트 데이터를 처리하고 8192 토큰(8K) 컨텍스트 길이를 활성화했습니다.
총 2.3T 토큰의 멀티모달 및 텍스트 전용 데이터의 결합된 레시피를 사용하여 계속 사전 학습합니다.
Muon Optimizer
모델 최적화를 위해 향상된 Muon 옵티마이저를 사용합니다.
original Muon 옵티마이저에 weight decay를 추가하고 파라미터별 업데이트 스케일을 조정합니다.
ZeRO-1 최적화 전략에 따라 Muon의 분산 구현을 개발하여 알고리즘의 수학적 속성을 유지하면서 최적의 메모리 효율성과 감소된 통신 오버헤드를 달성합니다.
향상된 Muon 옵티마이저는 비전 인코더, 프로젝터, 언어 모델을 포함한 모든 모델 파라미터를 최적화하기 위해 전체 학습 프로세스에서 사용됩니다.
Pre-Training Stages
그림 4와 표 1에서 볼 수 있듯이 중간 언어 모델을 로드한 후 Kimi-VL의 사전 학습은 총 4.4T 토큰을 소비하는 총 4단계로 구성됩니다.
네이티브 해상도 시각 인코더를 설정하기 위한 독립형 ViT 학습이 이어지고 모델의 언어 및 멀티모달 기능을 동시에 향상시키는 세 가지 결합된 학습 단계(pre-training, cooldown, and long-context activation)가 이어집니다.
ViT Training Stages
MoonViT는 이미지-텍스트, 합성 캡션, grounding bboxes, OCR 텍스트와 같은 다양한 대상으로 구성된 텍스트 구성 요소가 있는 이미지-텍스트 쌍에서 학습됩니다.
학습에는 두 가지 목표가 통합됩니다.
SigLIP loss, Lsiglip 및 입력 이미지에 조건화된 캡션 생성을 위한 교차 엔트로피 손실 Lcaption입니다.
CoCa의 접근 방식을 따라 최종 손실 함수는 L = Lsiglip + λLcaption으로 공식화됩니다. λ = 2입니다.
구체적으로 이미지 및 텍스트 인코더는 대조 손실을 계산하고 텍스트 디코더는 이미지 인코더의 특징에 조건화된 다음 토큰 예측(NTP)을 수행합니다.
학습 속도를 높이기 위해 두 인코더를 SigLIP SO-400M 가중치로 초기화하고 점진적인 해상도 샘플링 전략을 구현하여 점차적으로 더 큰 크기를 허용합니다.
텍스트 디코더는 작은 디코더 전용 언어 모델에서 초기화됩니다.
학습 중에 OCR 데이터를 확장하는 동안 캡션 loss의 출현을 관찰하여 텍스트 디코더가 일부 OCR 기능을 개발했음을 나타냅니다.
2T 토큰으로 CoCa와 유사한 단계에서 ViT를 학습한 후 MoonViT와 MLP 프로젝터만 업데이트되는 0.1T 토큰을 사용하여 MoonViT를 MoE 언어 모델에 정렬합니다.
이 정렬 단계는 언어 모델에서 MoonViT 임베딩의 초기 퍼플렉시티를 크게 줄여 다음과 같은 보다 원활한 결합 사전 학습 단계를 가능하게 합니다.
Joint Pre-training Stage
Joint Pre-training Stage에서 초기 언어 모델과 동일한 분포에서 샘플링된 순수 텍스트 데이터와 다양한 멀티모달 데이터의 조합으로 모델을 학습합니다.
동일한 학습률 스케줄러를 사용하여 로드된 LLM 체크포인트에서 계속 학습하며 추가로 1.4T 토큰을 소비합니다.
초기 단계에서는 언어 데이터만 사용하고 그 후 멀티모달 데이터의 비율이 점차적으로 증가합니다.
이러한 점진적인 접근 방식과 이전 정렬 단계를 통해 시각적 이해 능력을 성공적으로 통합하면서 모델의 언어 능력을 유지하는 것을 관찰합니다.
Joint Cooldown Stage
사전 학습 단계 다음 단계는 모델의 뛰어난 성능을 보장하기 위해 고품질 언어 및 멀티모달 데이터 세트로 모델을 계속 학습하는 멀티모달 Cooldown 단계입니다.
언어 부분의 경우 경험적 조사를 통해 Cooldown 단계에서 합성 데이터를 통합하면 특히 수학적 추론, 지식 기반 작업 및 코드 생성에서 상당한 성능 향상을 얻을 수 있음을 관찰할 수 있습니다.
냉각 데이터 세트의 일반 텍스트 구성 요소는 사전 학습 코퍼스의 고충실도 하위 집합에서 선별됩니다.
수학, 지식 및 코드 도메인의 경우 선택된 사전 학습 하위 집합을 활용하면서 합성 생성 콘텐츠로 보강하는 하이브리드 접근 방식을 사용합니다.
구체적으로 기존 수학 지식 및 코드 코퍼스를 소스 자료로 활용하여 품질 표준을 유지하기 위해 거부 샘플링 기술을 구현하는 독점 언어 모델을 통해 질문-답변(QA) 쌍을 생성합니다.
합성된 QA 쌍은 냉각 데이터 세트에 통합되기 전에 포괄적인 검증을 거칩니다.
멀티모달 부분의 경우 텍스트 냉각 데이터 준비에서 사용된 두 가지 전략, 즉 질문-답변 합성 및 고품질 하위 집합 재생 외에도 보다 포괄적인 시각 중심 인식 및 이해를 허용하기 위해 다양한 학술 시각 또는 시각-언어 데이터 소스를 QA 쌍으로 필터링하고 다시 작성합니다.
post 학습 단계와 달리 냉각 단계의 이러한 언어 및 멀티모달 QA 쌍은 특정 능력을 활성화하고 고품질 데이터 학습을 촉진하기 위해서만 포함되므로 이러한 QA 패턴의 과적합을 방지하기 위해 비율을 낮은 부분으로 유지합니다.
Joint Long-context Activation Stage
사전 학습 단계에서 RoP 임베딩의 역 주파수가 50,000에서 800,000으로 재설정된 상태에서 모델의 컨텍스트 길이를 8192(8K)에서 131072(128K)로 확장합니다.
결합 장기 컨텍스트 단계는 두 개의 하위 단계로 수행되며 각 하위 단계는 모델의 컨텍스트 길이를 4배 확장합니다.
데이터 구성의 경우 각 하위 단계에서 긴 데이터의 비율을 25%로 필터링하고 업샘플링하고 나머지 75% 토큰을 사용하여 이전 단계에서 짧은 데이터를 재생합니다.
탐색을 통해 이러한 구성이 모델이 짧은 컨텍스트 능력을 유지하면서 긴 컨텍스트 이해를 효과적으로 학습할 수 있음을 확인합니다.
모델이 순수 텍스트 및 멀티모달 입력 모두에서 장기 컨텍스트 능력을 활성화할 수 있도록 Kimi-VL의 장기 컨텍스트 활성화에 사용되는 긴 데이터는 긴 텍스트뿐만 아니라 긴 인터리브 데이터, 긴 비디오 및 긴 문서를 포함한 긴 멀티모달 데이터로 구성됩니다.
ColdDown 데이터와 유사하게 장기 컨텍스트 활성화의 학습 효율성을 높이기 위해 소량의 QA 쌍을 합성합니다.
장기 컨텍스트 활성화 후 모델은 긴 순수 텍스트 또는 긴 비디오 NIAH 평가를 통과하여 다재다능한 장기 컨텍스트 능력을 증명할 수 있습니다.
