느낌점
- GRPO와 같은 강화학습을 언급만 하고 왜 요번 버전에 사용하지 않는지 궁금
- 1.58비트 양자화의 근거? 삼항 양자화를 선택했는데 그 이유가 명확하지 않은 거 같음
- 활성화 함수를 SwiGLU 대신 ReLU^2 쓰는 게 1.58비트 모델에서 좋은 이유? ablation 연구 필요할 듯
- 첫 번째 풀 트레이닝 양자화 모델이라 다음 버전도 궁금
Abstarct
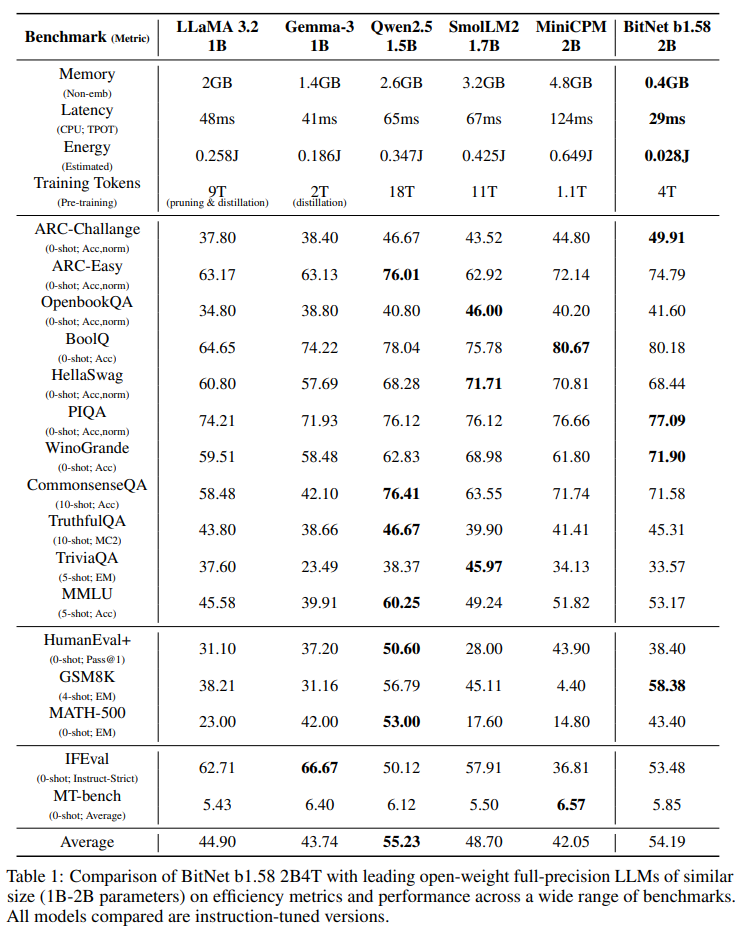
20억 매개변수 규모에서 최초의 오픈소스 네이티브 1비트 거대 LLM인 BitNet b1.58 2B4T를 소개합니다.
4조 토큰으로 학습된 이 모델은 언어 이해, 수학적 추론, 코딩 능력, 대화 능력 등 다양한 벤치마크를 통해 평가되었습니다.
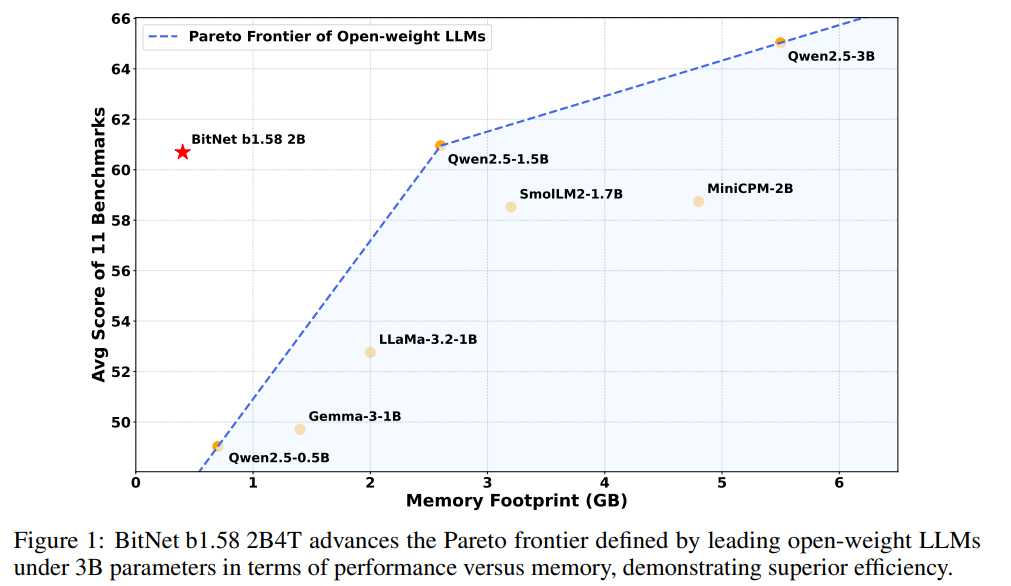
BitNet b1.58 2B4T가 유사한 크기의open-weight, full-precision LLM과 동등한 성능을 달성하면서도 메모리 사용량, 에너지 소비, 디코딩 지연 시간의 상당한 감소를 포함하여 상당한 계산 효율성 이점을 제공한다는 것을 보여줍니다.
추가 연구 및 채택을 용이하게 하기 위해 모델 가중치는 GPU 및 CPU 아키텍처 모두에 대한 오픈소스 추론 구현과 함께 허깅 페이스를 통해 공개됩니다.
Introduction
LLM은 고급 AI 기능 다양한 분야에서 연구를 가능하게 하는 데 중추적인 역할을 해왔습니다.
모델들의 공개는 광범위한 실험과 적용을 가능하게 합니다.
하지만 높은 장벽이 선택을 저해하고 있는데 바로 배포 및 추론에 필요한 막대한 컴퓨팅 자원입니다.
최첨단 오픈 LLM은 일반적으로 큰 메모리 공간 요구, 상당한 에너지를 소비, 추론 지연 시간을 보입니다.
많은 장치에 자원 제약적인 환경 및 실시간 애플리케이션에는 비실용적입니다.
가중치와 잠재적으로 활성화를 이진 {-1, +1} 또는 삼진 {-1, 0, +1}으로 제한하는 극단적이면서도 유망한 형태의 모델 양자화인 1비트 LLM은 효율성 문제에 대한 매력적인 해결책을 제시합니다.
가중치를 저장하는 데 필요한 메모리를 대폭 줄이고 고효율 비트 단위 연산을 가능하게 함으로써, 배포 비용을 크게 낮추고, 에너지 소비를 줄이며, 추론 속도를 가속화할 잠재력이 있습니다.
이전 연구에서는 1비트 모델을 탐구했하여 두 가지 범주로 나눌 수 있습니다.
1) 사전 훈련된 전체 정밀도 모델에 적용되는 사후 훈련 양자화 방법은 상당한 성능 저하를 초래할 수 있다
2) 비교적 작은 규모로 개발되었고 아직 더 큰 규모의 전체 정밀도 모델의 성능에 미치지 못할 수 있는 네이티브 1비트 모델만 존재.
효율성과 성능 사이의 이러한 격차를 해소하기 위해 처음부터 훈련된 최초의 오픈소스 네이티브 1비트 LLM인 BitNet b1.58 2B4T를 소개합니다.
20억 개의 파라미터로 구성된 이 모델은 4조 개의 토큰으로 이루어진 방대한 데이터셋으로 훈련되었으며 1비트 패러다임에 특화된 아키텍처 및 훈련 혁신을 활용했습니다.
본 연구의 핵심 기여는 대규모로 효과적으로 훈련된 네이티브 1비트 LLM이 광범위한 작업에서 유사한 크기의 주요 오픈 가중치, 전체 정밀도 모델과 견줄 만한 성능을 달성할 수 있음을 입증하는 것입니다.
Architecture
BitNet b1.58 2B4T의 구조는 표준 트랜스포머 모델에서 파생되었으며 BitNet 프레임워크를 기반으로 많은 수정이 이루어졌습니다.
모델은 처음부터 완전히 학습되었습니다.
핵심적인 구조적 혁신은 standard full-precision linear layers(torch.nn.Linear)를 BitLinear 레이어로 대체한 것입니다.
BitNet 접근 방식의 기반을 구성합니다.
BitLinear 레이어 특징
- Weight Quantization: 모델 가중치는 순방향 패스 동안 1.58비트로 양자화됩니다. 이는 가중치를 삼항 값 {-1, 0, +1}에 매핑하는 절대 평균(absmean) 양자화 방식을 사용하여 달성됩니다. 모델 크기를 크게 줄이고 효율적인 수학적 연산을 가능하게 합니다.
- Activation Quantization: linear projection을 통과하는 활성화는 8비트 정수로 양자화됩니다. 이는 토큰별로 적용되는 absmax(절대 최대) 양자화 전략을 사용합니다.
- Normalization: 양자화된 학습 체계에서 특히 유익할 수 있는 학습 안정성을 더욱 향상시키기 위해 subln 정규화를 통합합니다.
BitLinear 레이어 외에도 성능과 안정성을 향상시키기 위해 몇 가지 LLM 기술이 적용되었습니다.
- Activation Function (FFN): feed-forward network(FFN) 서브 레이어 내에서 일반적으로 사용되는 SwiGLU 활성화 대신 BitNet b1.58 2B4T는 제곱 ReLU^2를 사용합니다. 1비트 컨텍스트 내에서 모델 희소성과 계산적 특성을 향상시킬 수 있는 잠재력 향상 시킬 수 있는 있습니다.
- Positional Embeddings: RoPE는 위치 정보를 입력하는데 사용됩니다.
- Bias Removal: LLaMA와 같은 아키텍처와 일관되게 네트워크 전체의 선형 레이어와 정규화 레이어에서 모든 BIAS 항이 제거되어 파라미터 수를 줄이고 잠재적으로 양자화를 단순화합니다.
토큰화의 경우 LLaMA 3을 위해 개발된 토크나이저를 채택합니다.
이 토크나이저는 128,256개의 토큰 어휘 크기를 가진 byte-level Byte-Pair Encoding(BPE) 체계를 구현합니다.
이 선택은 다양한 텍스트와 코드를 강력하게 처리하고 널리 채택되어 기존 오픈 소스 툴링 및 생태계와의 직접적인 통합을 용이하게 합니다.
Training
BitNet b1.58 2B4T의 훈련 과정은 대규모 사전 학습, SFT, DPO의 세 가지 뚜렷한 단계로 구성되었습니다.
Proximal Policy Optimization(PPO), Group Relative Policy Optimization(GRPO)와 같은 고급 기술은 수학 및 연쇄적 사고 능력과 같은 기능을 더욱 향상시킬 수 있지만 현재 버전의 BitNet b1.58 2B4T는 오직 사전 학습, SFT, DPO에만 의존합니다.
강화 학습 방법의 탐구는 향후 연구 방향으로 남아 있습니다.
Pre-training
사전 학습 단계는 모델에 광범위한 세계 지식과 기본적인 언어 능력을 부여하는 것을 목표로 했습니다.
우리는 확립된 LLM 관행에서 일반적인 훈련 전략을 채택했으며 1비트 아키텍처에 맞게 특정 조정을 가했습니다.
Learning Rate Schedule
두 단계의 학습률 스케줄이 사용되었습니다.
- Stage 1 (High Learning Rate): 초기 단계에서는 표준 cosine decay schedule을 사용했지만 비교적 높은 피크 학습률로 시작했습니다. 이러한 선택은 1비트 모델이 종종 전체 정밀도 모델에 비해 더 큰 훈련 안정성을 나타내므로 더욱 적극적인 초기 학습 단계를 허용한다는 관찰에 기반했습니다.
- Stage 2 (Cooldown): 계획된 훈련 토큰 수의 대략 중간 지점에서 학습률이 갑자기 감소되었고 이후 상당히 낮은 피크 값을 갖는 코사인 스케줄을 통해 유지되었습니다. "Cooldown" 단계는 모델이 더 높은 품질의 데이터에 대한 표현을 세밀하게 조정할 수 있도록 합니다.
Weight Decay Schedule
학습률 조정과 함께 두 단계의 Weight Decay 전략이 구현되었습니다.
- Stage 1: 첫 번째 훈련 단계 동안 Weight Decay Schedule는 cosine schedule을 따랐으며 최대값 0.1에 도달했습니다. 정규화는 초기 높은 학습률 단계 동안 과적합을 방지하는 데 도움이 됩니다.
- Stage 2: 두 번째 단계에서는 Weight Decay가 효과적으로 비활성화되었습니다(0으로 설정). 이를 통해 모델 파라미터는 더 낮은 학습률과 선별된 데이터에 의해 유도되는 더 세밀한 최적점으로 수렴할 수 있습니다.
Pre-training Data
사전 학습 코퍼스는 DCLM과 같은 대규모 웹 크롤링 데이터와 FineWeb-EDU와 같은 교육용 웹 페이지를 포함한 공개적으로 사용 가능한 텍스트 및 코드 데이터셋의 혼합으로 구성되었습니다.
수학적 추론 능력을 향상시키기 위해 합성적으로 생성된 수학 데이터도 통합했습니다.
데이터 제시 전략은 2단계 훈련과 일치했습니다.
일반적인 웹 데이터의 대부분은 1단계 동안 처리되었고 더 높은 품질의 선별된 데이터셋은 학습률이 감소한 2단계 쿨다운 단계 동안 강조되었습니다.
Supervised Fine-tuning (SFT)
사전 학습 후 모델은 명령어 추종 능력을 향상시키고 대화형 상호 작용 형식에서의 성능을 개선하기 위해 지도 학습 미세 조정을 거쳤습니다.
SFT Data
SFT 단계에서는 WildChat, LMSYS-Chat1M, WizardLM Evol-Instruct, SlimOrca를 포함하되 이에 국한되지 않는 다양한 공개적으로 사용 가능한 명령어 추종 및 대화형 데이터셋을 활용했습니다.
특히 추론 및 복잡한 명령어 준수 능력을 더욱 강화하기 위해 GLAN, MathScale과 같은 방법론을 사용하여 생성된 합성 데이터셋을 추가했습니다.
Chat Template
<|begin_of_text|>System: {system_message}<|eot_id|>
User: {user_message_1}<|eot_id|>
Assistant: {assistant_message_1}<|eot_id|>
User: {user_message_2}<|eot_id|>
Assistant: {assistant_message_2}<|eot_id|>...Optimization Details
- Loss Aggregation: 배치 내 토큰에 대한 교차 엔트로피 손실을 평균화하는 대신, 합산을 사용했습니다. 경험적으로 손실을 합산하는 것이 이 모델의 수렴을 개선하고 최종 성능을 향상시키는 것으로 관찰되었습니다.
- Hyperparameter Tuning: 학습률과 훈련 에포크 수를 신중하게 튜닝했습니다. 사전 학습 결과와 일관되게 1비트 모델은 일반적인 전체 정밀도 모델 미세 조정에 비해 SFT 동안 상대적으로 더 큰 학습률의 이점을 얻었습니다. 또한 최적의 수렴을 달성하려면 유사한 크기의 전체 정밀도 모델보다 더 많은 epoch에 걸쳐 미세 조정 기간을 연장해야 했습니다.
Direct Preference Optimization (DPO)
도움이 되는 정도와 안전성에 대한 인간 선호도에 따라 모델의 행동을 더욱 조정하기 위해 SFT 단계 이후에DPO를 적용했습니다.
DPO는 선호도 데이터를 사용하여 언어 모델을 직접 최적화함으로써 기존의 RLHF에 대한 효율적인 대안을 제공하여 별도의 보상 모델을 훈련할 필요성을 우회합니다.
DPO 단계는 모델의 대화 능숙도와 실제 사용 사례에서 원하는 상호 작용 패턴과의 전반적인 일치도를 개선하는 역할을 했습니다.
Training Data
DPO 훈련에 사용된 선호도 데이터셋은 모델 출력에 대한 다양한 인간 판단을 포착하는 것으로 인정받는 공개적으로 사용 가능한 리소스의 조합으로 구성되었습니다.
UltraFeedback과 MagPie를 활용했습니다.
모델이 인간의 기대에 더 부합하는 응답을 생성하도록 유도했습니다.
Training Details
DPO 훈련 단계는 2 epoch 동안 진행되었습니다. 학습률은 2×10^−7로 설정하고 기준 정책으로부터의 발산을 제어하는 DPO 베타 파라미터는 0.1로 설정했습니다.
이 단계 동안 훈련 효율성을 향상시키기 위해 Liger Kernel 라이브러리의 최적화된 커널을 통합했습니다.
질적으로 우리의 관찰에 따르면 DPO 프로세스는 사전 학습 및 SFT 동안 확립된 핵심 기능의 상당한 저하 없이 모델을 선호하는 응답 스타일로 효과적으로 유도했습니다.
실험