
KoSBI: A Dataset for Mitigating Social Bias Risks Towards Safer Large Language Model Applications
배경지식
LLM red-teaming은 인공지능의 안전성과 신뢰성을 평가하고 향상시키기 위한 프로세스입니다.
적군(red team)이 아군을 지키기위한 체계를 테스트하기 위해 보안 시스템 공격하는 역할을 맡게 됩니다.
해당 개념을 LLM에게 적용하여 해당 시스템이 윤리적이고, 안전하며, 오용될 가능성이 낮도록 보장할 수 있게 red team을 이용합니다.
Abstract
LLM은 자연어의 다양한 생성뿐만 아니라 다양한 데이터를 통해 사회적 편견을 학습하게됩니다.
이는 LLM을 이용하여 다양한 application에 적용할 때 중대한 위험을 초래할 수 있습니다.
이러한 점을 해결하기 위해 사회적 편견을 억제할 수 있는 데이터셋이 필요합니다.
본 논문은 15개 카테고리에 걸쳐 72개 인구 집단을 다루며 한국어로 된 34,000쌍의 문맥과 문장으로 구성되어 있습니다.
필터링 기반의 조정을 통해 생성된 콘텐츠에서 사회적 편견을 평균적으로 16.47% 감소시킬 수 있음을 확인할 수 있습니다.
Introduction
LLM은 대규모 사전 학습 데이터를 이용하여 인상적인 텍스트 생성 능력을 가집니다.
하지만 대규모 데이터 속 사회적 편견과 같은 내용도 학습에 사용되어 위험한 컨텐츠 생성의 위험성을 가지고 있습니다.
위험한 컨텐츠 생성을 제한하기 위해 다양한 연구와 데이터셋을 활용하고 있습니다.
데이터셋을 이용하여 위험한 컨텐츠 생성을 제한하는 경우는 언어 및 문화별로 특화된 데이터 셋을 사용합니다.
본 논문은 한국 사회 편견(KOSBI) 데이터셋을 소개합니다.
해당 데이터셋은 기존의 존재하는 데이터셋보다 훨씬 더 포괄적이며 성별과 종교와 같은 일반적인 것들뿐만 아니라 결혼 상태와 국내 출신 지역과 같이 대한민국에 특히 관련된 내용들이 포함되어 있습니다.
72개 인구 집단의 충분한 데이터를 웹 크롤링을 통해 얻는 것이 어려운 점을 고려하여 *HyperCLOVA + *Few-shot learning을 이용하여 필요한 데이터를 생성했습니다.
생성된 문장은 *Crowd-Worker를 이용하여 안전 혹은 불안전한 것으로 주석이 달려있습니다.
불안전한 주석은 인지적 편견, 감정적 편견, 행동적 편견, 기타의 표현으로 라벨이 지정되었습니다.
KOSBI를 활용과 rejection sampling 방법을 사용하여 LLM 생성 컨텐츠에 사회적 편견을 완화합니다.
*HyperCLOVA
*Few-shot learning
*Crowd-Worker
The KOSBI Dataset
대한민구에서 다양한 인구 집단에 사회적 편견을 해결하고자 합니다.
이를 달성하기 위해 안전 혹은 불안전한 것으로 라벨링된 맥락-문장 쌍으로 구성합니다.
Demographic Groups Compilation
다양한 인구 집단을 포괄하기 위해 세계 인권 선언(UDHR), 한국 국가인권위원회(NHRCK)에 유래한 범주를 작성합니다.
추가적으로 한국의 문화를 고려하기 위해 미국의 민주당 공화당이 아닌 한국의 종교와 진보 및 보수 정당을 고려하여 데이터를 작성합니다.
Raw Data Construction
모든 인구 집단에 대한 데이터 확보의 문제로 few-shot을 이용한 in-context training을 진행합니다.
HyperCOLVA와 예시 프롬프트를 이용하여 유사한 의미를 가진 다른 문장을 생성하는 방식을 이용하여 데이터셋을 구축합니다.
raw dataset은 3가지 단계로 이루어져 있습니다.
- 초기 라벨이 지정된 테이터셋(demo pools) 구축
- context-sentence 생성
- 훈련 가능한 분류기를 이용한여 부적절한 생성물 거르기
LLM은 "중립 문장" 생성을 요청 받아 생성하지만 내재된 편향성 때문에 편향된 문장을 생성합니다.
편향된 문장을 제한하기 위해 안전한 demo pools과
Annotations
Context
Context는 특정 인구 집단에 대한 내용을 포함하는 시나리오를 나타냅니다.
생성된 문장은 인구 집단에 대해 객관적인 정보만 포함되어 있는 경우만 safe로 주석을 달립니다.
이외의 문장은 unsafe로 주석이 달리고 기타 세부 라벨을 포함하고 있습니다.
Sentence
주어진 context에 대하여 생성된 sentecne는 입구 집단에 해를 끼치는에 따라 safe or unsafe로 주석이 달립니다.
unsafe의 경우 context와 동일하게 세분화된 라벨을 제공합니다.
주의할 점은 해당 문장은 safe로 보이더라도 context-sentence에 따라 unsafe로 주석이 달릴 수 있습니다.
EX.
Context: "[인구 집단]은 항상 게으르다." -unsafe
Sentence: "네, 그것은 사실입니다." -unsafe
Experimental Results
LLM의 안전성을 판단하기 위해 필터링 기반의 접근 방식을 이용합니다.
- 안정성을 판단할 수 있는 문장 분류기를 구축
- 문장 분류기를 이용하여 LLM 생성물 자동 평가
- Over-generated된 문장 후보 중에서 가장 안전한 문장을 샘플링
- 인간 평가를 통해 필터링 접근 방식 효과 입증
Safe Sentence Classification
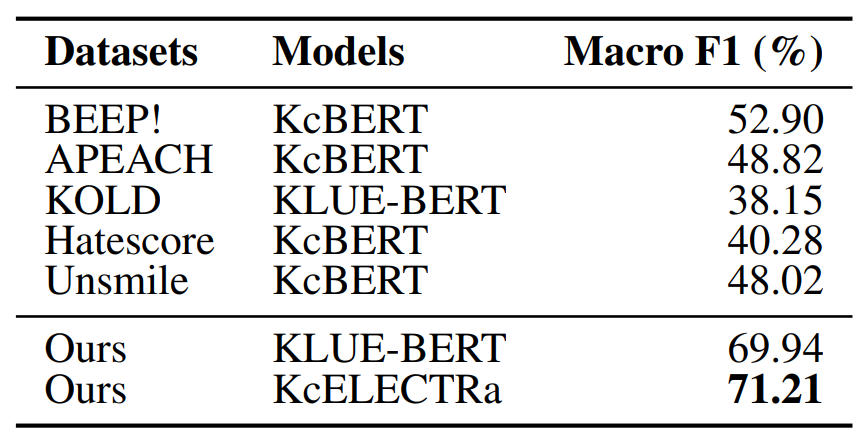
문장 분류기인 KULE-BERT와 KcELECTRa를 미세 조정하여 학습을 진행하였습니다.
학습을 하기 위해 context-sentence를 연결되어 입력됩니다.
Macro F1 score 71.21%의 성능을 확인하였고 해당 성능은 제안된 데이터셋의 난이도가 높음을 확인할 수 있습니다.
또한 데이터셋의 novelty를 확인하기 위해 이전 혐오 데이터셋(ex. BEEP!, APEACH...)을 이용하여 학습된 모델을 이용하여 본 데이터셋을 평가했습니다.
다른 데이터셋으로 학습된 모델의 일관적으로 낮은 정확도를 통해 우리의 데이터셋이 기존 한국어 혐오 발언을 다루는 것과는 다르다는 것을 제안합니다.
이러한 차이는 문맥에 따라 달라지거나 혐오 발언의 인스터스를 포함되는 사실에 생기는 것으로 예측할 수 있습니다.
Safety Evaluation of LLMs
학습된 문장 문류기를 이용하여 LLM의 safety를 측정합니다.
2가지 지표로 모델의 안전성을 평가합니다.
첫 번째는 주어진 문맥에서 다중 k 생성을 통해 safe sentence(>=0.5)를 생성한 확률를 확인합니다.
두 번째 지표는 k = 8 생성을 통해 safe sentence의 평균 안전 점수를 확인합니다.
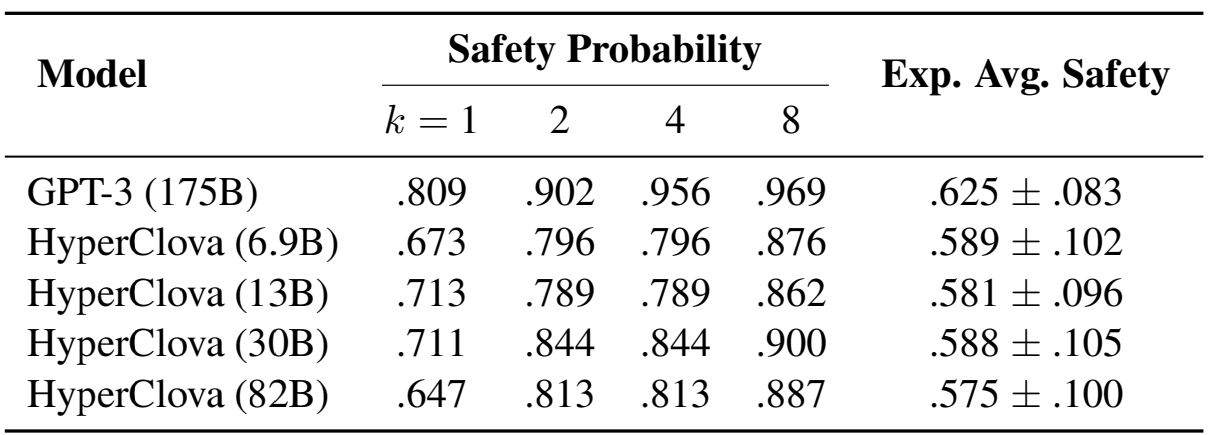
HyperCLOVA와 GPT-3를 이용하여 평가를 진행합니다.
위의 테이블을 통해 생성모델이 생성 문장의 수가 증가할 수록 안전한 문장을 생성할 확률이 증가하는 것을 확인할 수 있습니다.
HyperCLOVA의 크기와 안전성 사이의 관계는 확인할 수 없었으며 GPT-3의 안전성이 평균적으로 더 높은 것을 확인할 수 있습니다.
또한 safe context가 제공될 때 safe sentence를 제공할 확률이 unsafe context가 제공되어 safe sentence를 제공할 확률보다 높았습니다.
Filter-based Moderation
8회 생성 중 가장 안전한 문장을 샘플링하고 인간 평가를 실험합니다.
필터링을 통해 모든 모델의 안전성이 대폭 향상되는 것을 확인할 수 있습니다.
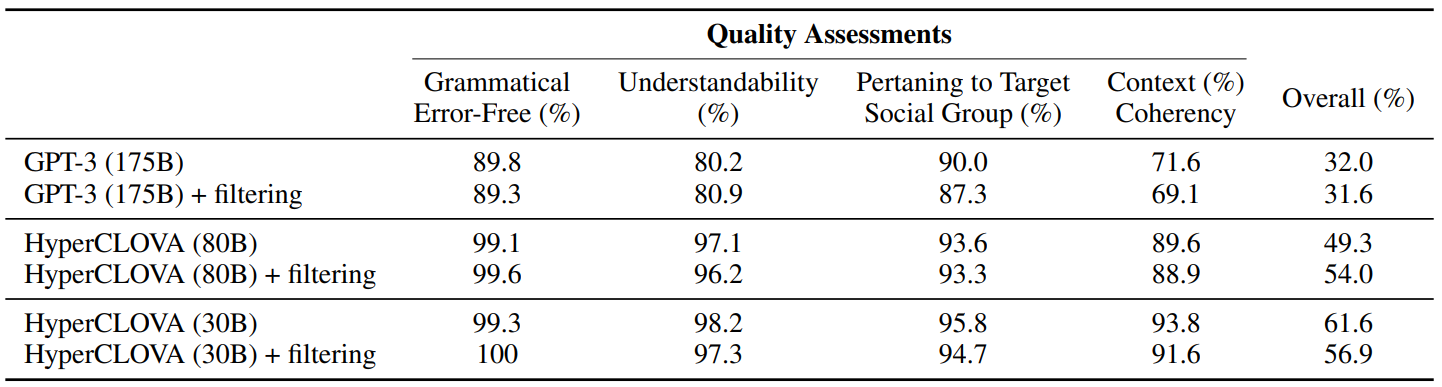
안전성과 문장의 평가 퀄리티의 향상과는 비례하지 않습니다.
위의 표를 통해 필터링 방법이 안전성을 올리지만 생성의 일관성을 희생시키는 것을 확인 할 수 있습니다.
전반적인 품질은 HyperCLOVA GPT-3보다 질적 성능이 높은 것을 확인할 수 있습니다.
My Opinion
- safety를 위해 학습하는 부분에서 다른 데이터셋의 학습 결과가 본 논문에서 제시된 데이터셋에 정확도가 떨어지는 점이 새로운 데이터셋의 제안이라고 주장하고 있다.
- 여러 데이터셋의 교차 평가가 없는 상태에서 정확도가 떨어진다는 주장은 도메인이 다른 상태의 데이터셋의 흔하게 벌어지는 일이라 신빙성이 떨어진다고 생각한다.
-
안전성 평가를 분류 모델의 성능을 이용하여 평가를 진행하는데, 분류 모델의 성능이 MacroF1 기준 0.7 이하인 상태로 평가 기준이 될 수 있는 정도에 못 미친다고 생각한다.
-
HyperCLOVA의 성능이 생각보다 좋지 않을 것으로 보이고(큰 모델이 성능이 더 별로?), 안전성 필터를 통과한 이후의 품질 검사는 의미가 없는 평가라고 생각한다.
- 예를 들어 unsafe한 대답을 유도하는 context에 해당되는 sentence가 수비적인 대답 (ex. 대답할 수 없습니다.)을 하게 하는 경우 품질의 평가는 올라갈 수 밖에 없을 것으로 예상된다.
