Quiet-STaR: Language Models Can Teach Themselves to
Think Before Speaking
논문 속 명언입니다.
Life can only be understood backwards; but it must be lived forwards.
인생은 거꾸로만 이해할 수 있지만, 앞으로 나아가야 합니다.
배경지식
기존의 언어 모델들은 복잡한 문제를 해결하는 방법에 초점을 맞추었고, 모델의 추론 과정을 통해 문제를 해결하는 방식을 훈련시켜왔습니다.
하지만 이러한 방식은 질문-답변이 존재하는 데이터셋에서만 작용할 수 있으며, 모델이 답변을 유사하게 출력할 수 있는지만 확인할 수 있는 문제가 존재한다.
인간의 추론 과정과 비슷한 학습을 하기 위해 추론 추적이나 추론과 유사한 데이터셋을 구축하여 학습시키는 방법이 제안됐습니다.
하지만 이 역시 주석 작업의 비용이 높으며 언어 모델이 생성할 법한 문장과 생성 분포가 다르다는 문제가 존재합니다.
이러한 문제를 해결하기 위해 self-play 방식 즉, 자신의 추론으로 반복 학습하여 점차 어려운 문제를 해결할 수 있는 방법이 제안되었습니다.
본 논문은 이러한 아이디어와 비슷한 self-taught resaoner 방식을 이용하여 추론 방식을 개선하고자 합니다.
STaR(Self-Taught Reasoner)
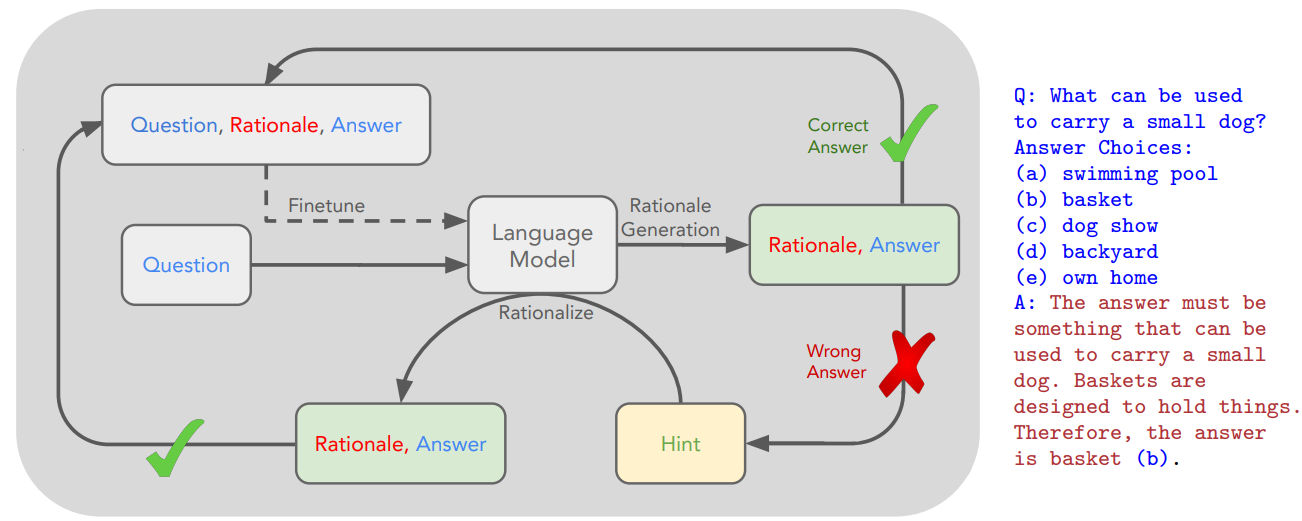
STaR(Self-Taught Reasoner)라는 논문의 백본이 되는 모델로 LM이 문제를 풀 때 답만 푸는것이 아니라 숨은 의미를 추론하여 다음 텍스트를 예측하는 것이 모델 성능 향상에 기여하는 것을 확인하였다.
Q. 작은 강아지를 담기 위해 필요한 것은?
A. 바구니
Rationale. 작은 강아지를 담기 위한 것이 정답이 되어야한다. 바구니는 담기 위해 만들어졌다.
이런 식의 답과 근거가 있는 데이터셋을 이용하여 LM 학습을 진행한다.
하지만 이런 방식은 고품질의 데이터셋이 필요하고 이는 고비용과 근거가 없는 데이터셋에 적용하기 어려운 점이 존재한다.
Abstract
사람은 글을 쓰거나 말할 때 잠깐 멈추며 생각을 정리하는데, 이는 추론의 한 형태입니다.
대부분의 논문들이 추론을 질문에 답하거나 어떠한 작업을 수행하는 행위로 정의하고 있지만, 증명의 과정에서 생략된 부분 혹은 대화 이면의 내용과 같이 모든 글들은 추론을 포함하고 있습니다.
기존의 Self-Taught Reasoner(STaR)는 질의응답의 소수 예시로부터 근거를 추론하고 정답으로 이어지는 사고 방식을 학습할 수 있도록 설계되어 있습니다.
하지만 이는 제한된 설정으로, 임의의 텍스트로부터 명시되지 않은 임의의 근거를 추론할 수 없습니다.
본 논문은 Quiet-STaR 모델을 제안합니다. 해당 모델은 각 토큰마다 이후 텍스트를 설명하는 것을 학습하여 예측을 개선합니다.
이를 통해 모델의 생성 계산 비용, 내적 사고, 다음 토큰의 예측성을 개선합니다.
사고의 시작과 끝을 학습 가능한 토큰 단위 병렬 샘플링 알고리즘과 extended teacher-forcing 기법을 이용하여 해결하고자 합니다.
이러한 방법으로 언어 모델은 대답하기 어려운 질문에 대한 성능을 향상시키게 됩니다.
Introduction
텍스트 안에는 많은 숨은 의미가 있습니다.
숨은 의미를 추론하여 다음 텍스트를 예측하는 것은 여러 작업의 Language Model(LM)의 서능을 향상시키는 것으로 나타났지만, 자신의 추론으로부터 학습할 수 있도록 하는 방법은 개별 작업이나 미리 정의된 작업을 해결하는데 초점을 맞추었습니다.
이러한 접근 방식은 데이터셋에 의존적이며 추론 자체를 제공한다는 한계가 있습니다.
모든 문장에 추론이 내재되어 있다면 추론을 가르치기 위해 언어 모델링 작업을 활용해야 합니다.
Self-Taught Reasoner(STaR) 방식은 답에 근거를 샘플링하고, 정답으로 이어지는 근거를 학습한 후 점차 어려운 문제를 해결할 수 있다는 것을 확인하였습니다.
Question-Answer 형태의 데이터셋으로 학습하는 것은 일반화 가능성을 제한하고 고품질의 데이터셋이 요구되는 한계가 있습니다.
문제를 해결하기 위해 대규모 인터넷 텍스트 코퍼스에서 추론을 생성 학습을 할 수 있도록 합니다.
이런 방법은 언어에 있는 다양한 작업을 학습할 수 있도록 합니다.
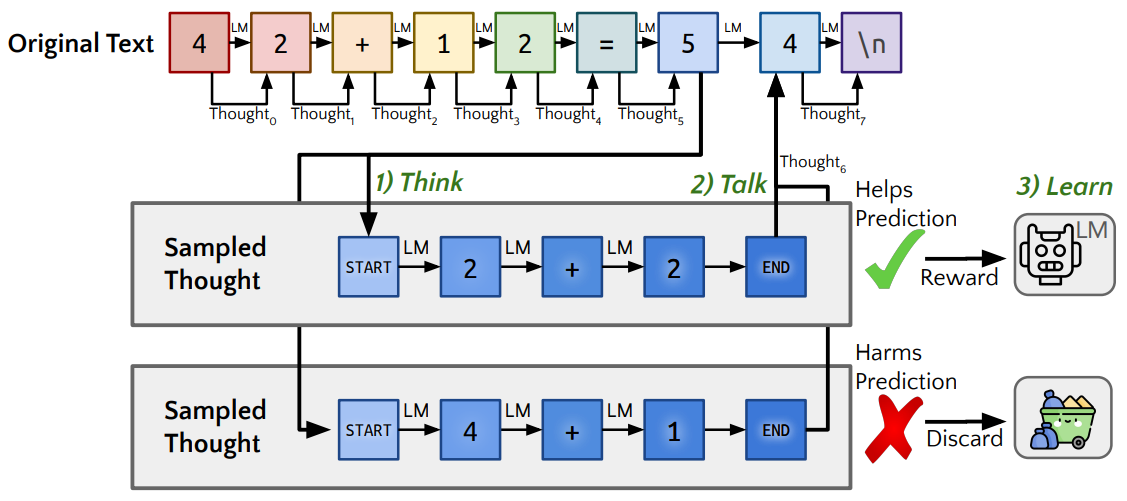
본 논문에서 제안한 Quiet-STaR 기법은 말하기전 잠깐 생각하는 인간의 추론 과정을 모방하여 학습시키는 것으로 이해할 수 있습니다. 텍스트를 설명하기 위해 토큰 귀에 근거를 생성하는 think, 근거가 있는 경우와 없는 경우의 텍스트 예측을 혼합한 talk, 강화학습을 사용하여 더 나은 근거를 생성하도록 하는 learn으로 구성되어 있습니다.
해당 방식은 미세조정 없이도 Quiet-STaR가 제로샷 추론 능력을 일관되게 향상키는 것을 확인하였습니다.
또한 내부 사고에 사용되는 토큰 수가 증가함에 따라 일관적으로 성능이 증가하는 것을 발견하였습니다.
문제 정의
관찰된 시퀀스의 각 토큰 쌍 사이에 보조 'rationale, 근거' 변수를 활용합니다. 그 후 근거를 생성할 수 있는 능력을 가진 매개변수 θ를 이용하여 모델을 최적화합니다.
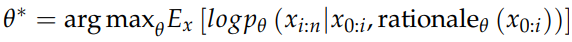
위의 식은, 입력 시퀀스: x0:i와 이를 기반으로 생성된 근거: rationaleθ (x0:i)가 주어졌을 때 xi:n 할당하는 확률 분포를 나타냅니다.
따라서 입력 시퀀스와 그에 대한 근거를 고려하여, 이후의 토큰 시퀀스에 대한 예측 확률을 최대화하도록 학습됩니다.
Quiet-STaR
Overview
Quiet-STaR는 3가지 주요 단계로 작동합니다.
-
병렬 근거 생성 (Parallel Generaton, think): x0:n의 n개 토큰 xi에 걸쳐 병렬로, 우리는 길이 t의 r개 근거를 생성합니다. ci = (ci1, ..., cit), 그 결과 n × r 개의 근거 후보가 생성되고 <|startofthought|> 및 <|endofthought|> 토큰을 삽입하여 각 근거의 시작과 끝을 표시합니다.
-
근거 후 예측과 기본 예측 혼합 (Mixing post-rationale and base predictions, talk): 각각의 rationale 후의 hidden state에서 mixing head를 학습시킵니다. 기본 언어 모델의 예측 확률과 rationale 후 예측된 다음 토큰 확률과 비교하여 얼마나 통합해야 하는지를 결정하는 MLP로 구성되어 있습니다.
-
근거 생성 최적화 (Optimizing rationale generation, learn): 생성 문장의 근거 가능성을 높이기 위해 생성 매개변수를 최적화합니다. 강화학습을 기반하여 학습 신호를 제공합니다. 또한 모델의 분산을 줄이기 위해 teacher-forcing trick 사용하여 사고 후 토큰뿐만 아니라 토큰을 예측하는 가능성도 loss에 포함시킵니다.
Parallel Generation (Think)
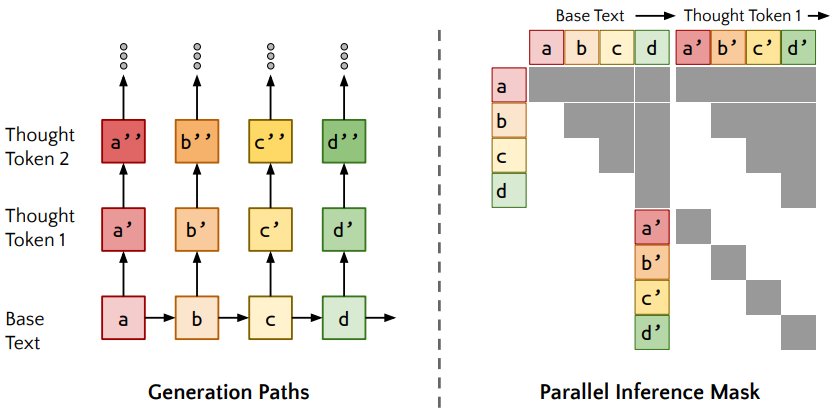
모든 토큰은 다음 출력의 확률을 가지고 있습니다.
base text에 해당되는 토큰은 각각의 starofthought-endofthought로 구성된 thought token으로 구성되어 있습니다.
thought token은 base text와는 다르게 단 방향으로 구성되어 있고 있는 계산의 한계라고 볼 수 있습니다.
각 순방향 전달을 캐시하고 이전 어텐션 마스크에 대각선 어텐션 마스크를 연결합니다.
이제 각 생성된 토큰은 해당 토큰을 생성하는 데 사용된 모든 토큰과 자기 자신에 주의를 기울이지만, 다른 "반사실적" 경로의 토큰에는 주의를 기울이지 않도록 유지할 수 있습니다.
Mixing post-rationale and base predictions (Talk)
PLM으로 본 논문에서 제안한 추론을 적용할 경우 원하는 추론 분포를 벗어나 모델 성능의 저하시킬 수 있습니다.
- 추론을 적용하기 위해서는 추론이 적용되지 않은 LM과 추론을을 포함한 LM의 보간을 사용합니다.
- 추론의 끝을 표현하는 endofthougth token의 hidden state + 원래 텍스트 토큰의 hidden state가 주어지면 mixing head는 post-thought prediction logits이 사용될 정도를 결정하는 가중치를 출력합니다.
- mixing head는 shallow multi-layer perceptron을 사용하며, 각 토큰에 대해 스칼라 값을 출력합니다.
Optimizing rationale generation (Learn)
<|startofthought|> 토큰의 표현(representation)을 최적화하는 것은 중요합니다
두 토큰은 em dash("−−−")에 해당하는 임베딩으로 초기화하여 pause 즉 잠깐 고민과 같은 동작으로 멈추게 되고 이는 언어 모델의 기존 지식을 활용하는 것입니다.
직관적으로 보면 startofthought token은 사고 모드, endofthought token은 사고가 끝났음을 알리는 것과 비슷한 것으로 이해할 수 있습니다.
Distribution of changes in log probability.
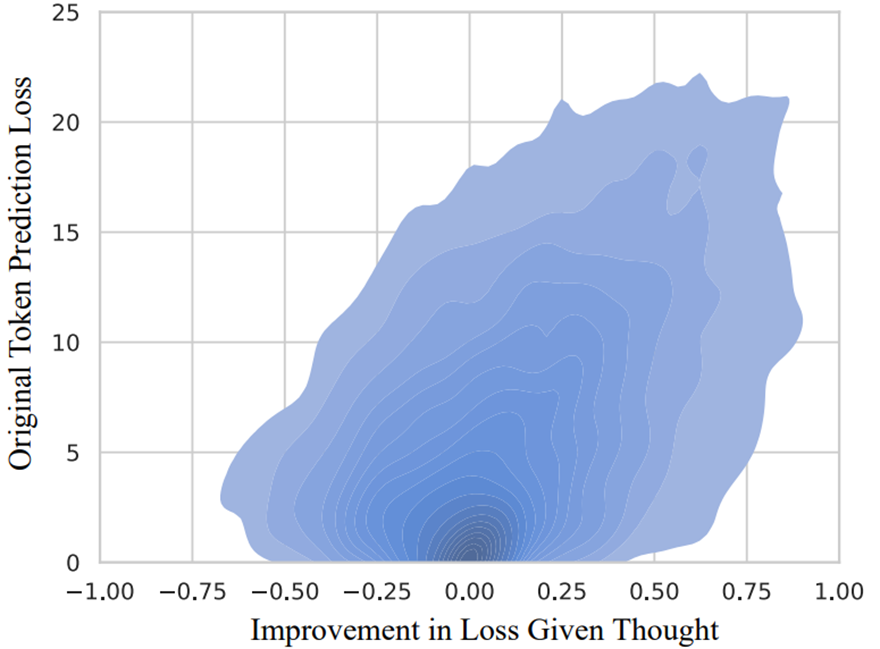
LM without thought와 비교하여 로그 확률 밀도 변화 시각화한 그림입니다.
분포는 굉장히 비대칭적으로 몰려있습니다
대부분 토큰은 생각이라는 것에 영향 받지 않습니다.
소수의 어려운 토큰이 생각으로부터 개선됩니다.
일반적인 텍스트에서 대부분 많은 추론이 필요하지 않습니다
실험
- 모든 토큰이 동일한 생각 필요하지 않음
Ex. “The person is run-” ing 이외의 확률이 있지만 맥락없는 문장으로 개선 가능성 낮음 - 온라인 크롤링 데이터는 사고 개선이 어려움
- Quiet-STaR는 모든 토큰이 동일한 효과 x
- 추론이 필요한 데이터셋에서 성능, 생각 토큰의 영향 파악
- Mistral 7B basic model
- 추론의 난이도가 있는 OpenWebMath 실험 수행
- 대부분의 평가에서 성능이 증가 (zero-shot)
- CommonsenseQA 10%↑, GSM8K 5% ↑
한계
- 단순한 아이디어와 복잡한 구체화
- 기존의 모델의 representation 성능에 기대는 부분
- 다양한 모델에 대한 검증 부족
- 생성할 때 근거를 생성하는 것은 많은 연산
- 생성과 종료 토큰의 불명확한 설명
- Bad reward process 근거 빈약
결론
- 추론이라는 추상적인 개념을 도입
- Down stream task에 추론 성능 향상
- 언어 모델의 추론 효율성을 예측한다면 더 나은 모델
- 인간과 유사한 추론 능력 격차를 줄일 수 있을 것으로 예상
