느낀점
- 뭔가 뭔가임
- 중요한 레시피는 모두 빠져있음(ex. 어떤 머지했는지, RL은 어떻게 했는지)
- smollm3가 있는 상황에서 주변 부분에 대한 얘기가 대부분임
- 제한된 컴퓨팅 자원에 대한 말을 많이 하지만 제한된 컴퓨팅 자원에 대한 설명이 없음(대외비 같음)
- smollm3까지 나와있는 상황에서 숨기는 게 많을 수록 의심만 많아지는 거 같음
Pre-training
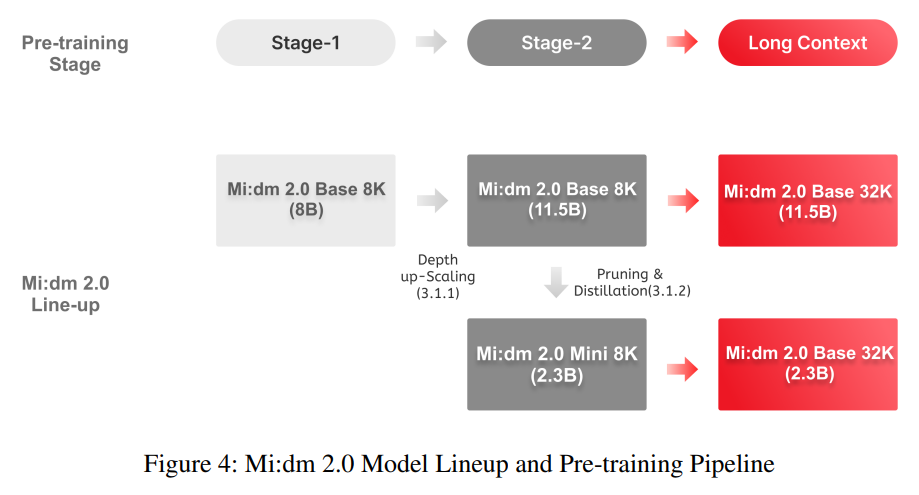
Mi:dm 2.0의 모델 라인업과 각 모델에 적용된 사전 학습 전략을 설명합니다.
Mi:dm 2.0은 제한된 컴퓨팅 자원을 활용하여 작지만 엄선된 한국어 데이터셋을 통해 효율적인 사전 학습과 뛰어난한국어 이해 및 생성 성능을 달성합니다.
자원 제약이 있는 환경에서도 경쟁력 있는 언어 모델을 개발할 수 있음을 보여줍니다.
각 모델의 사전 학습 방법론을 자세히 소개하기 위해, 3.1절에서는 모델 라인업 확장 과정에 대한 개요를 제공합니다.
각 모델 변형에 대한 사전 학습 기법을 다루는 하위 섹션들이 있습니다
3.1.1절은 Mi:dm 2.0 Base를, 3.1.2절은 Mi:dm 2.0 Mini를 다룹니다.
3.1.3절에서는 학습 중 적용된 시퀀스 길이 확장 기법을 제시합니다.
마지막으로 효율적인 대규모 학습을 가능하게 하는 컴퓨팅 비용 최적화 전략에 대해 자세히 설명합니다.
Model Architecture
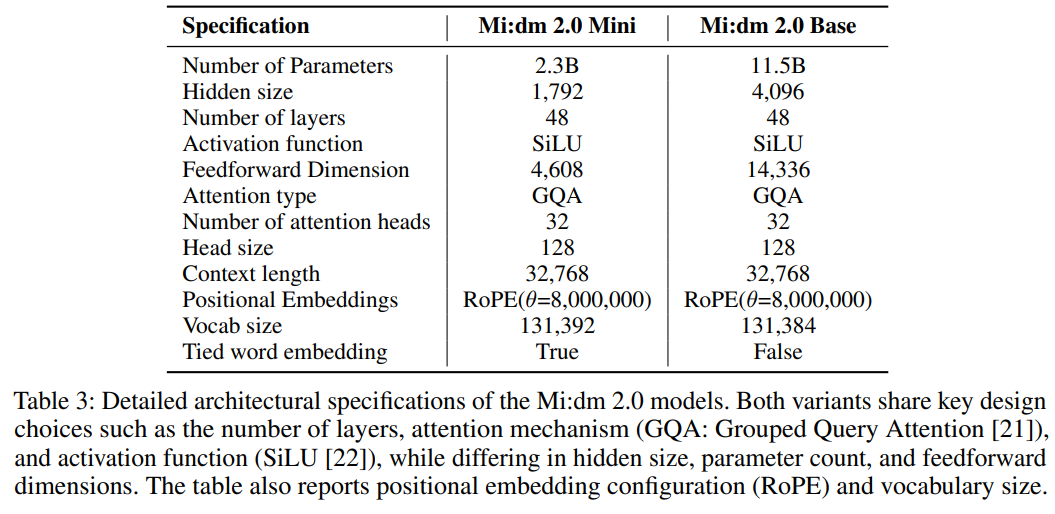
Mi:dm 2.0 모델 아키텍처는 Transformer 디코더 전용 아키텍처를 기반으로 하며 다양한 모델 크기 및 애플리케이션에서 훈련 효율성과 성능을 최적화하기 위해 레이어 수가 조정됩니다.
Mi:dm 2.0 모델의 확장은 3단계 훈련 절차를 사용합니다.
-
1단계: 초기 사전 훈련 (Stage-1)
- 8B 파라미터를 가진 Mi:dm 2.0 Base 모델을 처음부터 훈련합니다.
- KT가 아키텍처 설계부터 훈련까지 전적으로 자체 개발했으며 기존 오픈 소스 가중치를 활용하지 않습니다.
- 32개의 dense Transformer 디코더 레이어로 구성됩니다.
- 약 8,000 토큰까지 처리할 수 있습니다.
- 일반적인 언어 능력과 광범위한 도메인 지식을 습득하는 기반 모델을 구축하는 것
- 데이터셋은 광범위한 주제와 도메인을 다루도록 구성됩니다.
-
2단계: 모델 확장 (Stage-2)
- 1단계에서 훈련된 체크포인트를 사용하여 모델을 확장
- Depth up-Scaling (DuS) 기술을 적용하여 Transformer 디코더 레이어 수를 32개에서 48개로 늘립니다.
- 파라미터 수가 11.5B로 증가합니다.
- 훈련 데이터는 1단계보다 데이터 양은 적지만 고도로 정제된 초고품질 데이터로 구성되어 모델이 정교하고 작업별 응답을 생성하는 능력을 향상시킵니다.
- 최종적으로 Mi:dm 2.0 Base 모델이 됨
-
Mi:dm 2.0 Mini:
- 2단계 훈련을 마친 Mi:dm 2.0 Base를 기반으로 함
- Quantization를 통해 23B의 파라미터를 가진 소형 모델로 훈련됩니다
- Mi:dm 2.0 Base의 핵심 지식을 보존하면서 크기를 줄이기 위해 width-based pruning 기술과 multi-stage knowledge distillation를 사용합니다.
- 리소스가 제한된 환경에서 효율적인 추론을 가능하게 하는 on-device 배포에 최적화되어 있습니다.
-
최종 단계 Long-context training
- Mi:dm 2.0 Base와 Mi:dm 2.0 Mini 모두에 적용됩니다.
- Rotary Position Embedding (RoPE)의 base frequency를 확장하여 더 긴 입력 시퀀스를 처리
- 원래 Mi:dm 2.0 Base 및 Mi:dm 2.0 Mini는 약 8,000 토큰까지만 처리할 수 있었지만 Long-context training통해 입력 토큰 길이가 약 32,000 토큰으로 확장되어 긴 문서를 더 효과적으로 처리할 수 있게 됩니다.
Mi:dm 2.0 Base: Depth Up-Scaling
Mi:dm 2.0 Base를 제한된 컴퓨팅 자원 환경에서도 다양한 애플리케이션에 강력한 성능을 제공하도록 설계했습니다.
DuS(Depth Up-Scaling)라는 훈련 방법론을 통해 달성됩니다.
DuS는 기반 모델의 특정 계층을 체계적으로 복제하여 기존 계층 위에 쌓아 모델의 깊이를 늘리는 방식입니다.
DuS의 효과는 표현 능력이 뛰어난 계층을 전략적으로 선택하는 데 달려 있습니다.
표현 능력이 뛰어난 계층을 효과적으로 선택함으로써 DuS는 이점을 극대화하여 초기 훈련 단계의 자원을 효율적으로 재사용하면서 모델의 표현력과 성능을 향상시킵니다.
Mi:dm 2.0 Base의 경우 어떤 계층을 복제할지 결정하기 위해 정량적 방법론을 채택했습니다.
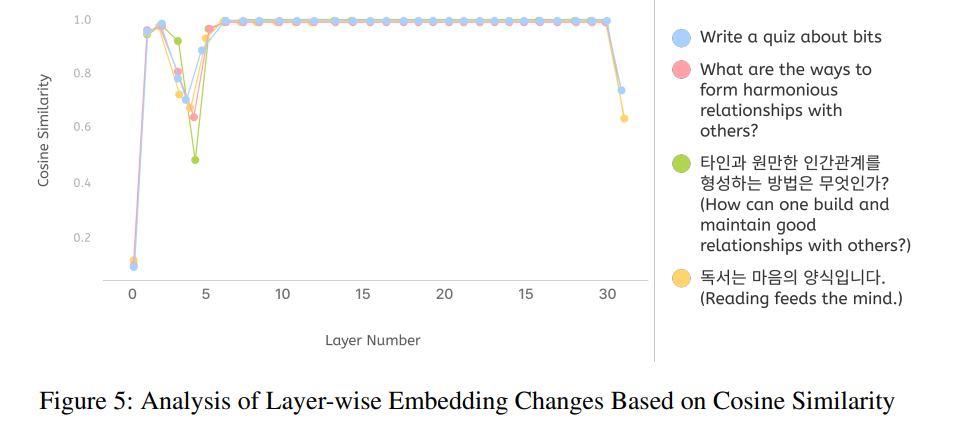
각 계층의 전후 임베딩 표현의 변화를 코사인 유사도를 계산하여 측정합니다.
코사인 유사도 점수가 높을수록 입력 정보가 훈련 중에 최소한의 손실로 안정적으로 보존된다는 가정하에 복제 대상으로 선택됩니다.
이 방법을 적용하여 Mi:dm 2.0 Base 확장에 사용된 초기 8B 규모 모델의 모든 계층에 걸쳐 임베딩 변화를 분석했습니다.
그림 5에 나타났듯이 입력 문장의 각 토큰에 대해 계층 전후 임베딩 간의 코사인 유사도를 계산한 다음 계층별로 점수를 평균화했습니다.
임베딩 변화가 5번째 계층 이후 안정화되며 7번째에서 29번째 계층 사이에서는 거의 완벽한 유사도(1.0에 가까움)를 보여 정보 손실이 거의 없음을 나타냅니다.
저희는 그림 5와 유사한 아키텍처를 가진 다른 언어 모델에 대한 추가 내부 실험을 통해 이러한 결과를 확인했습니다.
층 수를 48개로 확장하기 위해 7번째부터 29번째까지의 연속적인 계층을 복제 대상으로 선택했습니다.
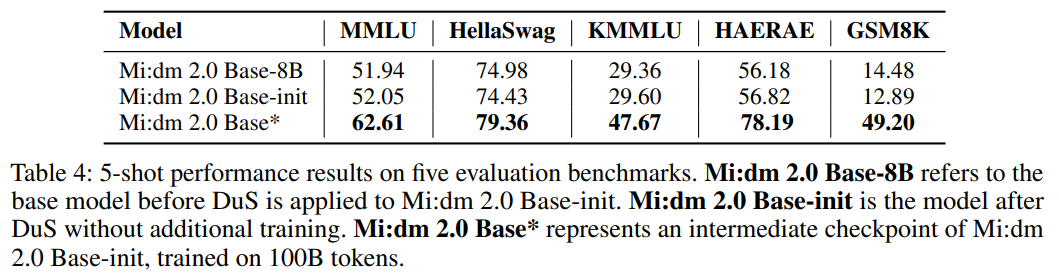
이러한 아키텍처 확장의 효과를 검증하기 위해 확장된 모델의 초기 상태 성능을 평가했습니다.
표 4에 나타난 바와 같이 구조가 확장되었지만 아직 훈련되지 않은 Base-init 모델이 원본 Mi:dm 2.0 Base-8B와 비슷한 벤치마크 성능을 보여주었습니다.
이는 코사인 유사도 기반의 계층 선택 방법이 효과적인 구조적 확장을 성공적으로 달성했음을 시사합니다.
계층 확장 단계 이후, Mi:dm 2.0 Base는 언어적 표현력과 일반 도메인 이해도를 더욱 향상시키기 위해 철저히 정제된 고품질 데이터로 지속적인 사전 학습을 거칩니다.
사전 학습은 두 단계로 구성됩니다.
첫 번째 단계는 확장 직후 안정적인 수렴을 보장하는 것을 목표로 하며 두 번째 단계는 선별된 한국어 데이터와 맞춤형으로 생성된 합성 데이터를 사용하여 한국어 및 STEM(과학, 기술, 공학, 수학) 도메인을 강화하는 데 중점을 둡니다.
훈련 단계에서는 Warmup-Stable-Decay 스케줄러를 사용하며, 최고 학습률은 3e-4이고 훈련 마지막 10% 동안 선형적으로 0.0으로 감소합니다.
Mi:dm 2.0 Mini: Pruning and Distillation
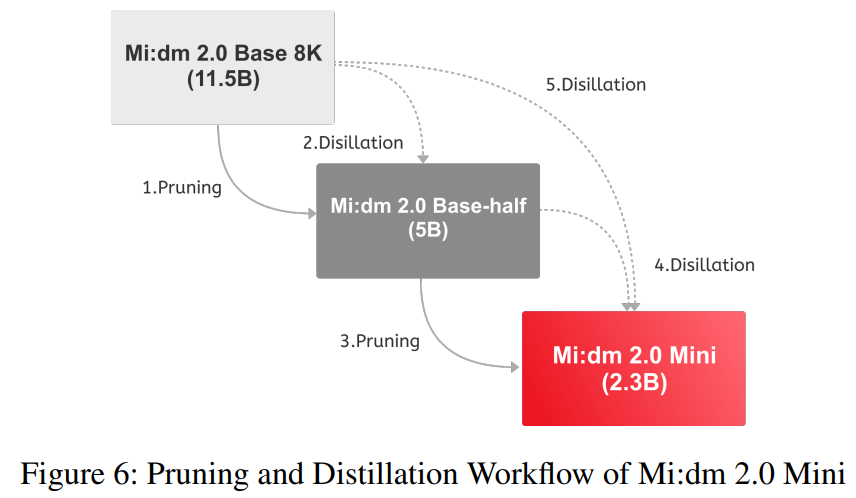
Mi:dm 2.0 Mini는 Mi:dm 2.0 Base에서 파생된 경량 모델로 온디바이스 배포 또는 저사양 GPU와 같은 저자원 환경에서 실행되도록 설계되었습니다.
Mi:dm 2.0 Base가 습득한 지식을 유지하면서 모델 크기를 줄이기 위해 Mi:dm 2.0 Mini는 그림 6에 설명된 대로 두 단계의 pruning과 distillation를 거칩니다.
첫 번째 단계에서는 Mi:dm 2.0 Base에 width pruning을 적용하여 약 50억 개의 매개변수를 가진 Mi:dm 2.0 Base-half을 생성합니다.
이 중간 모델은 Mi:dm 2.0 Base를 eacher model로 사용하여 지식 증류를 거치며 student model이 교사 모델의 출력을 모방하도록 안내합니다.
두 번째 단계에서는 중간 모델에 추가적인 width pruning을 적용합니다.
Mi:dm 2.0 Mini의 최종 아키텍처를 완성하기 위해 단어 임베딩에 weight-sharing 구조를 채택합니다.
두 번째 증류 단계에서는 Mi:dm 2.0 Base-half와 Mi:dm 2.0 Base를 모두 교사 모델로 사용하여 학생 모델이 이들의 출력을 모방하도록 순차적으로 훈련합니다.
multi-stage knowledge distillation 접근 방식은 Mi:dm 2.0 Base와 Mi:dm 2.0 Mini 사이에 큰 용량 차이가 있을 때 발생하는 문제를 해결합니다.
교사 모델과 학생 모델의 크기 차이가 클 경우 단일 단계 증류는 지식을 효과적으로 전달하지 못하고 훈련 과정을 불안정하게 만들 수 있습니다.
큰 교사 모델에 반복적으로 의존하면 전체 계산 비용이 증가합니다.
이러한 문제를 완화하고 성능과 효율성 사이의 균형을 맞추기 위해 width pruning 파이프라인에 Mi:dm 2.0 Base 크기의 약 절반인 assistant teacher model을 중간 단계로 도입합니다.
중간 크기 모델은 학습 성능과 계산 효율성을 모두 최적화하면서 보다 안정적이고 효과적인 지식 전달을 가능하게 하는 중요한 중개자 역할을 합니다.
width pruning 전략은 Mi:dm 2.0 Base 구축 시에 의해 도입된 깊이를 보존하면서 전체 매개변수 수를 효과적으로 줄입니다.
이어지는 지식 증류 과정에서 학생 모델의 초기화 및 구조적 설계는 교사로부터 지식을 효과적으로 흡수하는 데 중요합니다.
학생 초기화를 위해 교사 모델을 직접 가지치기하면 원래 아키텍처에 과도하게 의존하게 되어 generalization를 제한할 수 있습니다.
동일한 매개변수 예산에 대해 더 깊은 모델이 일반적으로 더 넓은 모델보다 성능이 우수하다는 것을 보여주었습니다.
중간 및 최종 모델 아키텍처를 정의할 때 깊이보다는 너비를 줄이는 전략을 채택합니다.
Mi:dm 2.0 Mini에 대한 가지치기-증류 전략의 효과를 검증하기 위해 proxy model 실험을 수행합니다.
Mi:dm 2.0 Base와 동일한 아키텍처를 공유하는 18억 매개변수 모델을 프록시로 사용합니다.
Table 5에 나타난 대로, 1.8B-scratch과 가지치기 및 증류된 버전(1.8B-distill)을 주요 벤치마크에서 비교했습니다.
결과는 증류된 모델이 대부분의 벤치마크에서 우수한 성능을 달성하면서,처음부터 훈련된 기준 모델에 비해 계산 비용을 약 4.5배 낮췄음을 보여줍니다.
두 가지치기 단계 모두에서 너비 가지치기는 주로 모델의 hidden dimensions과 MLP 차원을 대상으로 합니다.
가지치기 후 calibration을 위해 Mi:dm 2.0 Base의 Stage-2 사전 훈련 데이터에서 1,024개의 예시를 샘플링합니다.
지식 증류 데이터셋을 구성하기 위해 동일한 샘플링 접근 방식이 적용됩니다.
증류 훈련은 설명된 세부 사항에 따라 warm-up 및 cosine decay 스케줄링과 함께 1e-4의 최대 학습률을 사용합니다.
Long-context Extension
Mi:dm 2.0이 긴 입력 시퀀스를 처리할 수 있도록 하기 위해 사전 훈련의 마지막 단계에서 추가적인 Long-context 훈련 단계를 도입합니다.
이 단계는 모델의 최대 입력 문맥 길이를 8,192 토큰에서 32,768 토큰으로 확장합니다.
위치 인코딩의 base frequency in positional encoding and context length에 대한 관계에 대해 Mi:dm 2.0의 base frequency를 10,000에서 8백만으로 조정했습니다.
32K 토큰의 문맥 길이를 목표로 할 때 더 긴 시퀀스로 훈련하는 것이 성능을 향상시킵니다.
Long-context 훈련은 최대 약 65,000 토큰의 입력 길이를 가진 데이터를 사용합니다.
Long-context 학습을 위한 데이터 혼합 전략을 검증하고 입력 길이가 증가함에 따라 발생하는 catastrophic forgetting을 완화하기 위한 실험을 수행합니다.
훈련 데이터셋은 주로 최대 65,000 토큰 길이의 시퀀스로 구성되며 이 길이에 맞추기 위해 소량의 더 짧은 데이터도 함께 포함됩니다. Long-context 훈련은 별도의 warm-up 단계 없이 고정 학습률 1e-5를 사용하여 2,000단계 동안 수행됩니다.
Training Costs

Mi:dm 2.0의 대규모 사전 학습은 Microsoft Azure CycleCloud로 구축된 고성능 GPU 클러스터에서 진행됩니다.
이 인프라는 언어 모델 학습에 필요한 대규모 계산에 최적화되어 있으며 장기적인 사전 학습을 지원하기 위한 효율적인 자원 관리와 유연한 확장성을 제공합니다.
각 모델의 학습 단계별 계산 비용은 표 6에 요약되어 있습니다.
모든 지표는 NVIDIA H100 GPU 클러스터 기준으로 보고됩니다.
FLOPs는 모델 매개변수, 시퀀스 길이, 학습 단계, 배치 크기를 기반으로 계산됩니다.

제미나이 예상
Post-training
Overview
사전 학습된 LLM은 방대한 텍스트 코퍼스를 기반으로 광범위한 언어 이해 및 생성 능력을 가지고 있습니다.
하지만 실제 애플리케이션에 필요한 신뢰도, 즉 정확한 지시 수행, 논리적 추론, 최신 정보 활용, 도구 사용, 안전성, 긴 맥락 처리 등의 수준에 도달하기 위해서는 추가적인 미세 조정이 필수적입니다.
Mi:dm 2.0의 포스트 트레이닝 과정은 실제 서비스 환경에서 유용성과 신뢰성을 극대화하기 위해 중요한 다음 여섯 가지 핵심 역량을 체계적으로 강화하도록 설계되었습니다.
-
Instruction-Following, IF: 지시 수행은 지시를 정확하게 해석하고 요청된 내용 유형, 형식, 길이 및 구조에 맞는 응답을 생성하는 능력을 말합니다. 실제 시나리오에서 사용자 질의와 요구 사항은 매우 다양하므로 적절한 정보 전달과 서비스 품질을 보장하기 위해서는 지시를 엄격하게 따르는 것이 필수적입니다.
-
Reasoning: 추론은 다단계 연산을 포함한 논리적, 수학적 사고를 통해 복잡한 문제를 해결하는 능력을 말합니다. 이러한 능력은 실제 애플리케이션에 필수적이며 실제 작업에서 모델의 유용성을 결정합니다.
-
Retrieval-Augmented Generation, RAG: RAG는 실시간으로 외부 지식, 문서 또는 데이터베이스를 검색하고 정확하고 최신 정보에 기반하여 응답을 생성하는 능력을 말합니다. hallucination을 최소화하고 전문적인 환경에서 신뢰할 수 있는 의사 결정을 지원합니다.
-
Agent Ability: 에이전트 능력은 지정된 인터페이스를 통해 다양한 도구나 API를 호출하여 실제 작업을 수행하는 능력을 말합니다. 단순한 Q&A를 넘어 일정 관리나 코드 실행과 같은 복잡한 시나리오를 처리하는 서비스 지향 AI의 핵심 역량입니다.
-
Safety: 안전은 무해성, 편향 완화, 개인 정보 보호를 포함한 사회적, 윤리적 책임을 보장하는 능력을 말합니다. 이 영역의 강화는 배포 과정에서 유해한 콘텐츠, 잘못된 정보 또는 데이터 유출로부터 사용자와 조직을 보호하는 데 필수적입니다.
-
Long Context Handling: 긴 맥락 처리는 긴 문서, 대화 또는 코드에서 중요한 정보를 유지하고 일관성 있게 참조하는 능력을 말합니다. 이는 긴 자료 요약과 같은 복잡한 작업에서 일관되고 정확한 응답을 보장합니다.
Mi:dm 2.0의 포스트 트레이닝은 실제 서비스 요구 사항을 충족하기 위한 구조화된 정렬 및 전문화 전략으로 구성됩니다. 전체 포스트 트레이닝 과정은 다음 단계로 이루어집니다.
-
SFT (Supervised Fine-Tuning): 이 단계는 모델이 일반성과 특수성의 균형을 유지하도록 훈련하여 사용자 질의에 폭넓게 응답할 수 있도록 하는 데 중점을 둡니다.
-
Weight Merging: 이 단계는 가중치 병합을 통해 여러 SFT 모델의 강점과 특징을 통합하여, 서로 다른 데이터와 훈련 전략을 통해 습득한 다양한 능력을 하나의 모델로 통합할 수 있게 합니다.
-
Reinforcement Learning, RL: 이 단계는 사람 또는 AI 선호도에 기반한 온라인/오프라인 강화 학습을 통해 모델을 개선하여, 내용과 형식 모두에서 바람직한 품질에 더 잘 부합하는 응답을 생성할 수 있도록 합니다.
사전 학습과 달리 포스트 트레이닝은 실제 서비스 환경 요구 사항을 충족하는 데이터 구조를 통합해야 합니다.
사전 학습은 일반적으로 비정형 또는 단일 턴 코퍼스를 사용하지만 실제 대화 서비스는 다중 턴 상호 작용과 역할 기반 대화를 요구합니다.
Mi:dm 2.0은 포스트 트레이닝 동안 다중 턴 상호 작용과 역할 구분을 반영하기 위해 LLaMA 4에서 사용된 것과 동일한 채팅 템플릿 형식을 채택합니다.
각 발화는 시스템, 사용자, 어시스턴트 또는 도구와 같은 역할로 명확하게 표시됩니다.
데이터는 단순한 코퍼스가 아닌 구조화된 다중 턴 대화로 저장되며, 이 구조는 훈련 및 추론 전반에 걸쳐 유지됩니다.
이러한 구조적 접근 방식은 모델이 현실적인 대화 시나리오를 학습하고, 사용자 의도를 이해하고, 시스템 지시를 따르며, 각 맥락 상황에 맞는 적절한 도구를 호출하도록 장려합니다. 또한 각 역할에 따라 일관성을 유지하고, 정보를 추적하며, 맥락을 참조하는 모델의 능력을 향상시킵니다.
