느낀점
- 진짜 open ai는 허깅페이스가 아닐까?
- 모델 학습 투명도과 굉장히 높음
- 모델 머지를 통해서 긴문장 이해능 해결하려고 했음
- 고품질 추론 데이터가 없어서 qwen 사용함 (qwen은 무슨 데이터가 있는 걸까?)
- APO가 왜 DPO보다 좋은지 논리적이지 않음
요약
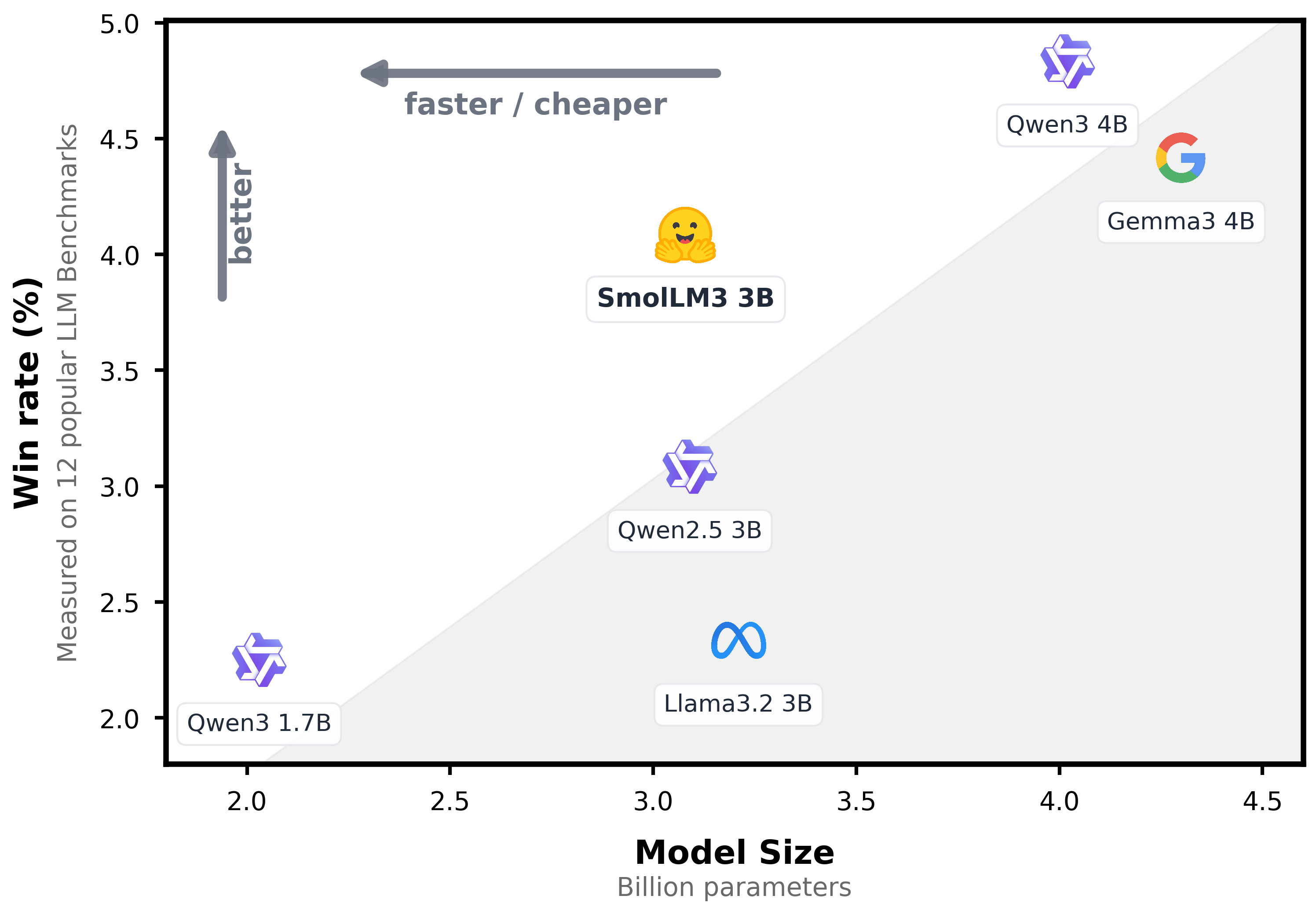
SmolLM3는 효율성이 매우 좋습니다.
SmolLM3-3B 모델은 Llama-3.2-3B와 Qwen2.5-3B를 능가하면서도 더 큰 4B 대안들(Qwen3 & Gemma3)과 경쟁력 있는 성능입니다.
성능 숫자 외에도 공개 데이터셋과 훈련 프레임워크를 사용하여 어떻게 만들었는지 정확히 공유합니다.
Model summary:
- 3B 모델은 11T 토큰으로 훈련되었으며 3B 규모에서 SoTA를 달성하고 4B 모델과 비교해도 경쟁력 있음
- dual 모드(think/no_think) 모드 지원함
- 6개 언어(영어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어)에 대한 다국어 지원, 한국어 없음
- 128k까지의 긴 컨텍스트 지원 NoPE와 YaRN 사용
The complete recipe:
아키텍처 세부 사항, 3단계 사전 학습 접근 방식을 통해 도메인 간 성능을 점진적으로 향상시키는 방법을 보여주는 정확한 데이터 혼합, 하이브리드 추론 모델을 구축하는 방법론이 포함되어 있습니다.
보통 이러한 결과를 달성하려면 몇 달 동안 역공학이 필요합니다.
이와 다르게 전체 방법론을 제공합니다.
Pretraining

Architecture and training details
SmolLM3는 SmolLM2와 유사한 연결된 임베딩을 가진 트랜스포머 디코더 아키텍처를 따르며 + Llama 아키텍처를 기반입니다.
효율성과 긴 컨텍스트 성능을 최적화하기 위한 몇 가지 주요 변경 사항을 적용했습니다.
GQA:
4개 그룹을 사용하여 multi-head attention-> GQA로 대체했습니다.
FineWeb-Edu(100B 토큰) 데이터셋으로 훈련된 3B 모델에 대한 ablation study에서 GQA는 멀티헤드 주의의 성능을 일치시키면서 추론 시 KV 캐시 크기를 크게 줄일 수 있었습니다.
NoPE:
"RoPE to NoRoPE and Back Again: A New Hybrid Attention Strategy"에서 구현한 NoPE는 every 4th layer마다 rotary position embeddings을 선택적으로 제거합니다.
이 접근 방식은 ablations study으로 확인된 것처럼 긴 컨텍스트 성능을 향상시키면서 짧은 컨텍스트 능력에는 영향을 주지 않습니다.
Intra-Document Masking:
훈련 중에는 attention masking을 사용하여 동일한 훈련 시퀀스에 있는 다른 문서의 토큰들이 서로 주의를 기울이지 않도록 합니다. Llama 3와 유사하게 이는 더 빠르고 안정적인 긴 컨텍스트 훈련을 돕고 짧은 컨텍스트 성능을 유지하는 데 도움이 됩니다.
Training Stability:
OLMo2 이후 임베딩 레이어에서 weight decay를 제거하여 훈련 안정성을 개선했습니다.
해당 수정으로 훈련이 더 안정적이게 되었으며 embedding norms이 훈련 중 자연스럽게 안정화되었습니다.
모든 변경 사항은 FineWeb-Edu(100B 토큰) 데이터셋으로 훈련된 3B 모델에 대한 ablation study에서 각 수정 사항이 성능을 향상시키거나 유지하면서 다른 이점을 제공함을 확인했습니다.
Training Configuration:
global batch size of 2.36M tokens 기준 sequence length를 4096, learning rate을 2e-4, AdamW optimizer (beta1: 0.9, beta2: 0.95)를 사용, weight decay를 0.1, gradient clipping을 1로 설정했습니다.
WSD(Warmup-Stable-Decay) 스케줄러를 사용하며, 2000 단계의 워밍업 후 최종 훈련 단계의 10%에서 선형적으로 0으로 감소합니다.
훈련에는 nanotron 프레임워크를 사용했으며, 데이터 처리에는 datatrove를, 평가에는 lighteval을 사용했습니다.
모델은 384개의 H100 GPU에서 24일간 훈련되었습니다.

| 항목 | 내용 |
|---|---|
| 노드 수 | 48 |
| GPU 수 | 384 (8 × 48) |
| 총 학습 시간 | 24일, 220,000 GPUh |
| 병렬 전략 | Tensor Parallelism (TP=2), Data Parallelism (DP=192) |
| 체크포인팅 저장 위치 | S3 |
| 로깅 플랫폼 | W&B |
| 평가 처리 방식 | 비동기 |
Data mixture and training stages
SmolLM2의 다단계 접근 방식을 따라 웹, 수학, 코드 데이터를 점진적으로 변화하는 비율로 혼합한 11.2T 토큰을 사용하여 SmolLM3를 세 단계의 학습 전략으로 훈련했습니다.
50B에서 100B 토큰으로 훈련된 3B 모델에 대한 광범위한 ablation 실험을 통해 데이터 혼합 및 비율을 결정했습니다.

Stage 1: Stable phase (0T → 8T tokens) 기초 단계에서는 핵심 데이터셋 혼합으로 강력한 일반 능력을 구축합니다:
- Web: 85% (12% multilingual) - FineWeb-Edu, DCLM, FineWeb2 and FineWeb2-HQ
- Code: 12% - The Stack v2 (16 programming languages), StarCoder2 pull requests, Jupyter and Kaggle notebooks, GitHub issues, and StackExchange.
- Math: 3% - FineMath3+ and InfiWebMath3+
Stage 2: Stable phase (8T → 10T tokens) 좋은 웹 커버리지를 유지하면서 더 높은 품질의 수학 및 코드 데이터셋을 도입합니다:
- Web: 75% (12% Multilingual)
- Code: 15% - Adding Stack-Edu
- Math: 10% - Introducing FineMath4+, InfiWebMath4+, and MegaMath (including Qwen Q&A, Pro synthetic rewrites, and text-code interleaved blocks)
Stage 3: Decay Phase (10T → 11.1T tokens) 최종 단계에서는 수학 및 코드 데이터를 추가로 업샘플링합니다:
- Web: 63% (12% Multilingual)
- Code: 24% - upsampling of high-quality code data
- Math: 13% - upsampling math data and introducing instruction and reasoning datasets such as OpenMathReasoning
이러한 단계와 혼합을 통해 기본 모델에 매우 경쟁적인 성능을 달성했습니다.
정확한 데이터 가중치를 가진 nanotron 훈련 설정은 여기에서 찾을 수 있습니다.
주요 사전 학습 후 긴 맥락과 추론을 위해 중간 학습 단계에서 모델을 개선했습니다.
Mid-training
긴 컨텍스트 적응과 추론 적응을 "Mid-training"이라고 부릅니다.
사전 훈련보다 훨씬 짧지만 여전히 어느 정도 일반적이며 두 영역에서 모델을 개선하는 데 목적이 있습니다.
Long Context extension
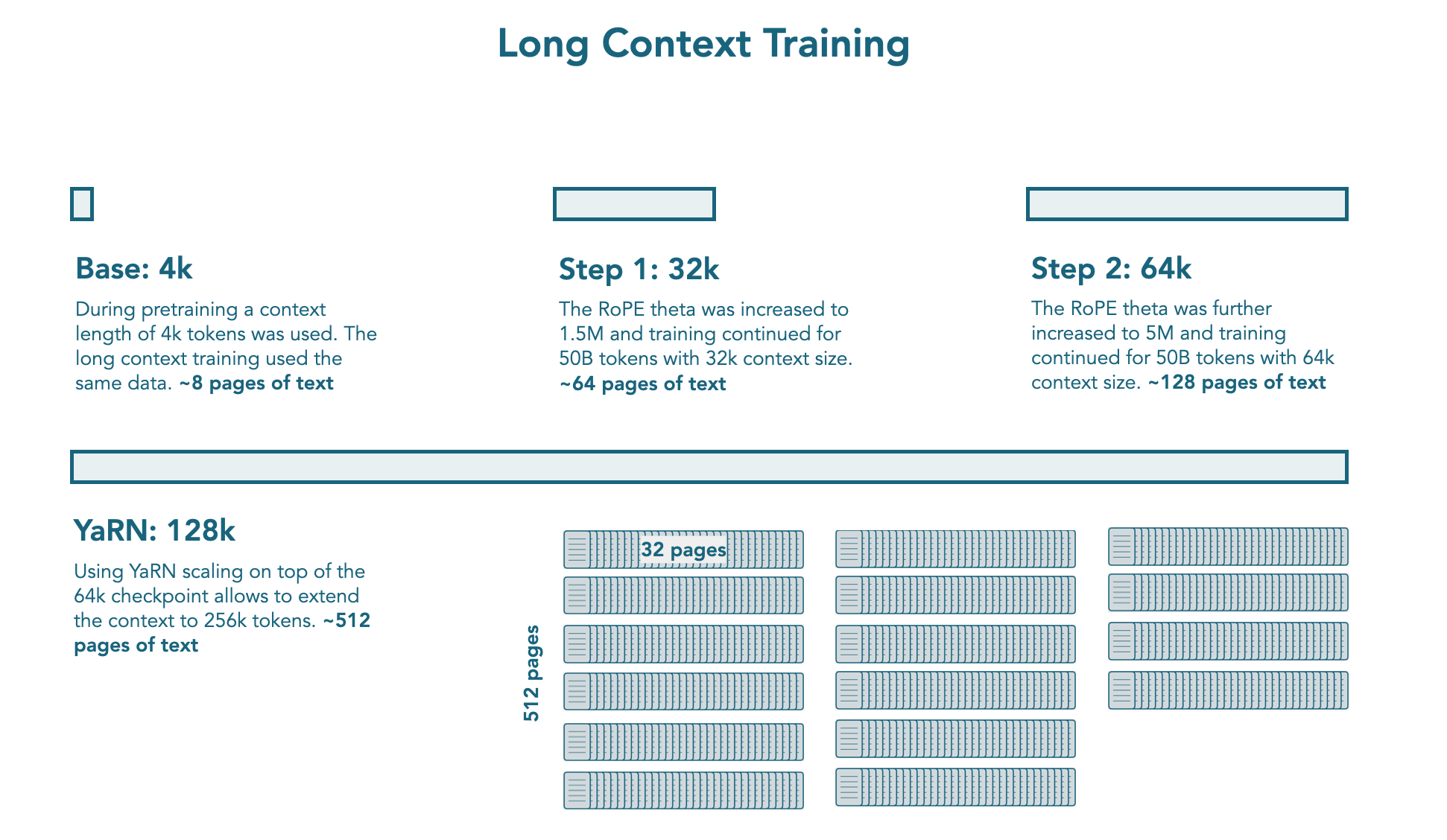
사전 학습 후 SmolLM3에 추가로 100B 토큰으로 학습하여 컨텍스트 길이를 확장했습니다.
50B 토큰씩 두 단계에 걸쳐 컨텍스트 윈도우를 순차적으로 확장했습니다.
처음에는 RoPE theta를 1.5M로 증가시키며 4k에서 32k 컨텍스트로 전환한 다음 RoPE theta를 5M로 증가시키며 32k에서 64k 컨텍스트로 전환했습니다.
두 단계 모두 수학, 코드, 추론 데이터를 업샘플링했습니다.
Ablation 실험 중, code repositories, 책, 긴 웹 페이지와 같은 특정 긴 컨텍스트 데이터를 업샘플링하는 것이 RULER와 HELMET 벤치마크에서 성능을 더욱 향상시키지는 않았습니다.
NoPE를 사용하고 긴 시퀀스와 증가된 RoPE theta 값으로 감쇠 혼합을 학습하는 것이 64k까지 경쟁적인 긴 컨텍스트 성능을 달성하기에 충분했습니다.
Qwen2.5 이후로는 YARN을 사용하면 훈련 컨텍스트 길이를 초월도 가능하게 합니다.
Reasoning Mid-training
모델의 컨텍스트 길이를 확장한 후 중간 학습 단계에서 추론 능력을 통합하기 위해 모델을 학습시켰습니다.
중간 학습 단계와 사전 및 사후 학습 단계의 주요 차이점은 아직 특정 도메인에 집중하기 전에 일반적인 능력을 목표로 한다는 점입니다.
특정 도메인(예: 수학 또는 컴퓨터 코드)을 목표로 하지 않고 모델을 추론 능력을 가지도록 학습시키고자 했습니다.
중간 학습 데이터셋은 Open Thought의 OpenThoughts3-1.2M과 NVIDIA의 Llama-Nemotron-Post-Training-Dataset-v1.1의 하위 집합에서 R1의 추론 흔적을 포함한 35B 토큰을 제공했습니다.
ChatML 채팅 템플릿을 사용하고 패킹을 래핑하여 모델에 너무 많은 구조를 제공하지 않도록 했습니다.
모델을 4 (~140B 토큰) 에포크 동안 학습시키고 이후 SFT 단계에 체크포인트를 사용했습니다.
Post-training
DeepSeek R1과 Qwen3 같은 추론 모델의 출시는 모델이 명시적인 추론을 수행할 수 있을 때 나타나는 강력한 능력을 보여주었습니다.
그러나 추론과 비추론 모드를 모두 지원하는 이중 지시 모델을 구축하기 위한 완전히 개방된 레시피와 공개 데이터셋이 부족합니다.
대부분의 기존 접근 방식은 복잡한 강화 학습 과정과 독점적 데이터셋을 사용하므로 연구자들이 이러한 결과를 재현하고 발전시키기 어렵습니다.
이러한 도전 과제를 어떻게 해결했는지 설명하고 이중 지시 모델을 구축하는 데 사용한 완전한 레시피를 공유합니다.
추론 및 비추론 모드 간의 성능을 균형을 맞추는 방법을 상세히 설명하, 일반 추론 능력을 포함한 중간 훈련, 합성 데이터 생성을 통한 지도 미세 튜닝, 그리고 최근의 DPO 변형인 Anchored Preference Optimization (APO)를 사용한 정렬을 포함한 신중하게 설계된 훈련 파이프라인을 사용합니다.
Building the Chat Template
훈련 방법론으로 들어가기 전에 사용자가 우리의 이중 모드 모델과 어떻게 상호작용하는지 이해하는 것이 중요합니다.
채팅 템플릿은 추론 모드와 비추론 모드 간의 원활한 전환을 가능하게 하는 인터페이스로서 그 설계는 우리의 훈련 데이터 형식과 모델 동작에 직접 영향을 미칩니다.
SmolLM3의 채팅 템플릿은 사용자가 대화 중 추론 모드를 제어할 수 있도록 합니다.
사용자는 /think 과 /no_think 플래그를 각각 시스템 프롬프트에 포함하여 추론 모드 또는 비추론 모드를 활성화할 수 있습니다.
비추론 모드에서는 Qwen3과 유사하게 모델의 응답을 빈 생각 블록으로 미리 채워서 명시적인 추론 없이 직접적인 답변을 보장합니다.
SmolLM3는 도구 호출을 지원하며 채팅 템플릿은 도구 설명을 위한 두 가지 구별된 섹션을 포함합니다: XML 도구와 파이썬 도구.
이 특정 분류는 실험에서 모델이 각 형식의 도구 정의를 정확하게 해석하는 데 유리함이 입증되었습니다.
채팅 템플릿은 추론 모드의 두 가지 모두에 대한 기본 시스템 메시지를 제공하며, 날짜, 지식 절단 날짜, 현재 추론 모드를 포함하는 메타데이터 섹션을 포함합니다.
사용자는 system 역할을 가진 하나를 제공하여 기본 시스템 메시지를 바꿀 수 있습니다.
메타데이터 섹션은 시스템 프롬프트에서 /system_override 플래그를 사용하여 제외할 수 있으며, 특정 사용 사례에 대한 유연성을 제공합니다.
Supervised Finetuning
추론 중간 단계 이후 일반 추론 데이터 140B 토큰에 대한 모델을 훈련한 후, SFT을 진행하여 수학, 코드, 일반 추론, 지시 사항 따르기, 다국어, 도구 호출 모두에 걸쳐 추론 및 비추론 모드의 기능을 통합합니다.
이중 모드 모델을 훈련하는 것은 모든 대상 도메인에 걸쳐 모두 두 모드에서 강력한 성능을 유지하도록 데이터 혼합을 신중하게 조정해야 합니다.
SmolLM3의 훈련 중 성능을 평가하기 위해 다음 도메인을 추적했습니다: 수학, 코드, 일반 추론, 지시 사항 따르기, 다국어.
추론 모드 데이터셋을 구축할 때 마주한 주요 도전 과제는 특정 도메인에 대한 추론 추적이 포함된 데이터셋의 부족이었습니다.
이 격차를 해결하기 위해 기존의 비추론 데이터셋에서 유래한 프롬프트로 Qwen3-32B를 추론 모드로 프롬프팅하여 합성 데이터를 생성했습니다.
이를 통해 모델이 추론 모드에서 처음에는 어려움을 겪었던 도메인에서 성능을 개선할 수 있었습니다. 예를 들어 다중 턴 대화, 다국어성, 일상 대화 등이 있습니다
최종 데이터 혼합은 추론과 비추론 토큰의 최적 비율 및 각 모드 내 구성을 탐구하는 광범위한 절차 ablation를 통해 얻은 결과였습니다.
생성된 SFT 데이터셋에는 18억 토큰이 포함되어 있으며, 비추론 모드에 10억 토큰과 추론 모드에 8억 토큰으로 구성되어 있으며, 12개의 비추론 데이터셋과 추론 trace을 가진 10개의 데이터셋으로 구성됩니다.
BFD(가장 적합한 감소) 패킹을 사용하여 사용자 턴(user turns)에 손실을 마스크(mask)하고 도구 호출(tool calls)의 결과를 사용하여 4 에포크(~80억 토큰) 동안 훈련했습니다.
우리는 이 데이터 혼합과 전체 훈련 스크립트를 공개하여 커뮤니티가 우리의 연구를 재현하고 발전시킬 수 있도록 지원할 것입니다.
Off-policy model alignment with Anchored Preference Optimization (APO)
SFT 단계 이후 비논리 모드용 Tulu3 선호도 데이터셋과 논리 모드용 새로운 합성 선호도 쌍의 조합을 사용하여 모델 정렬을 한 둘러 돌렸습니다.
선호도 쌍은 Qwen3-32B와 Qwen3-0.6B에서 생성했습니다.
비생각 데이터셋의 모든 도메인을 완전히 포함하기 위해 보충적인 생각 모드 선호도 쌍을 생성했습니다.
정렬을 위해 Anchored Preference Optimization과 함께 Qwen3-32B의 생성물을 "선택됨"으로, Qwen3-0.6B의 응답을 "거부됨"으로 선택했습니다.
Anchored Preference Optimization (APO)은 Direct Preference Optimization (DPO)의 변형으로, 더 안정적인 최적화 목표를 제공합니다.
DPO에서는 보상 함수 r_θ(x,y)가 훈련 중 시퀀스의 확률과 훈련 시작 시 모델의 확률의 로그 비율을 측정합니다.
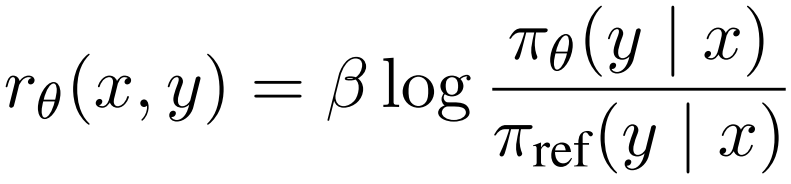
여기서 β는 최적화 중인 모델이 참조 모델에 대해 얼마나 변할 수 있는지를 조절합니다. DPO 손실은 훈련 x, 선택된 y_w 및 거부된 y_l 응답의 삼중체를 최적화합니다:
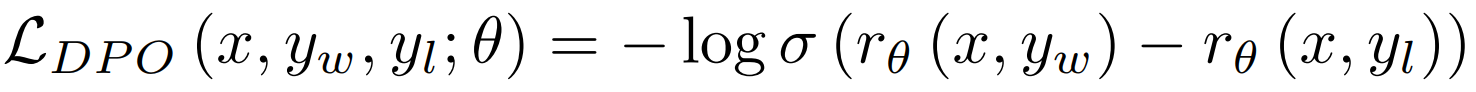
APO 목표는 더 안정적임이 입증되었으며 내부 실험 중에도 하위 성능이 더 높은 것을 관찰했습니다.
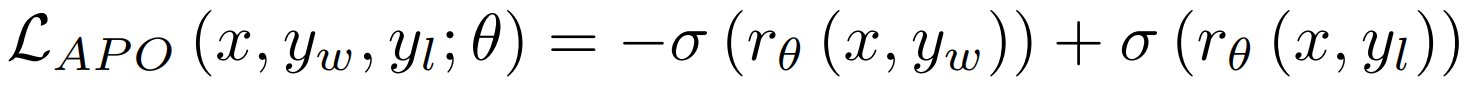
다운스트림 평가에서 수학, 과학, 지시 따르기, 코딩, 채팅, 다국어 작업 등 여러 분야에서 개선이 나타났지만, RULER와 같은 긴 컨텍스트 벤치마크에서 성능 저하를 관찰했습니다.
성능 저하는 추론 중간 단계에서 추론 능력에 대한 집중이 긴 컨텍스트 성능에 영향을 미쳤다고 추적했습니다.
APO 훈련 데이터는 우리의 추론 데이터셋의 대부분이 이 길이보다 짧기 때문에 24k 토큰으로 제한되었습니다.
이러한 성능 하락을 완화하기 위해 모델 병합을 해결책으로 탐색했습니다.
Model Merging
모델 병합은 다양한 모델의 강점을 결합할 수 있는 인기 있는 강력한 기술이며 앙상블의 계산 부담이나 추가 훈련이 필요 없습니다.
MergeKit 라이브러리를 사용하여 모델 병합을 수행했습니다.
이는 선형 및 비선형 병합을 포함한 여러 병합 방법을 포함하고 있습니다.
우리의 병합 레시피는 두 단계로 구성됩니다:
1 각 APO 체크포인트를 가져와 모델 "soup"를 만듭니다.
2. 모델 soup와 중간 훈련 체크포인트를 결합합니다. 중간 훈련 체크포인트는 강력한 장문 성능을 가지고 있습니다. APO 모델 스튜와 중간 훈련 체크포인트에 대해 각각 0.9와 0.1의 가중치를 사용하는 선형 병합이 최고의 성능을 달성했습니다. 우리는 기본 모델의 RULER 점수를 128k 토큰까지의 맥락에서 복원할 수 있었습니다.
