느낀점
- Lightning Attention을 사용하여 연산량 많이 줄여 긴 토큰 입력 가능
- 중요도 샘플링(Importance Sampling)을 통해서 모든 토큰이 학습에 사용될 수 있게하여 기존의 업데이트 막는 클리핑에 비교하여 좋은 접근 같음
- Lightning Attention 자체는 원래 있던 거고 약간 학습하면 레시피 추가한 느낌
- 그래디언트는 가중치 클리핑으로 인해 약간 편향이라는 부분이 있는데 얼마나 어떻게 많이 편향되서 안 좋은 영향을 미치는지 알 수 없음
Abstract
대규모 hybrid-attention 추론 모델인 MiniMax-M1을 소개합니다.
MiniMax-M1은 하이브리드 MoE 아키텍처와 lightning attention 메커니즘을 기반으로 구성되어 있습니다.
이 모델은 이전에 발표된 MiniMax-Text-01 모델을 기반으로 개발되었으며 총 4,560억 개의 매개변수를 포함하고 토큰당 459억 개의 매개변수가 활성화됩니다.
M1 모델은 100만 토큰의 컨텍스트 길이를 기본으로 지원하며 DeepSeek R1의 컨텍스트 크기보다 8배 더 큽니다.
MiniMax-M1의 lightning attention 메커니즘은 test-time compute을 효율적으로 확장할 수 있도록 합니다.
DeepSeek R1과 비교했을 때 M1은 10만 토큰 생성 시 FLOPs를 25%만 소비합니다.
이러한 특성 덕분에 M1은 긴 입력을 처리하고 광범위하게 사고해야 하는 복잡한 작업에 특히 적합합니다.
MiniMax-M1은 다양한 문제에 대한 대규모 강화학습을 사용하여 훈련되었습니다.
강화학습에서 lightning attention의 본질적인 효율성 이점 외에도 강화학습 효율성을 더욱 향상시키기 위해 새로운 RL 알고리즘인 CISPO를 제안합니다.
CISPO는 토큰 업데이트 대신 중요도 샘플링 가중치를 clipping하여 다른 경쟁 RL 변형보다 뛰어난 성능을 보입니다.
하이브리드 어텐션과 CISPO의 조합 덕분에 MiniMax-M1의 전체 RL 훈련은 512개의 H800 GPU에서 3주 만에 완료되었으며 임대 비용은 534,700달러에 불과했습니다.
4만, 8만 thinking budgets을 가진 두 가지 버전의 MiniMax-M1 모델을 출시했습니다.
벤치마크 실험 결과 모델은 오리지널 DeepSeek-R1 및 Qwen3-235B와 같은 강력한 오픈 웨이트 모델과 비교하여 동등하거나 우수한 성능을 보였으며, 특히 복잡한 소프트웨어 엔지니어링, 도구 활용 및 긴 컨텍스트 작업에서 강점을 나타냈습니다.
테스트 시 계산의 효율적인 확장을 통해 MiniMax-M1은 차세대 언어 모델 에이전트가 실제 문제를 추론하고 해결하기 위한 강력한 기반이 될 것입니다.
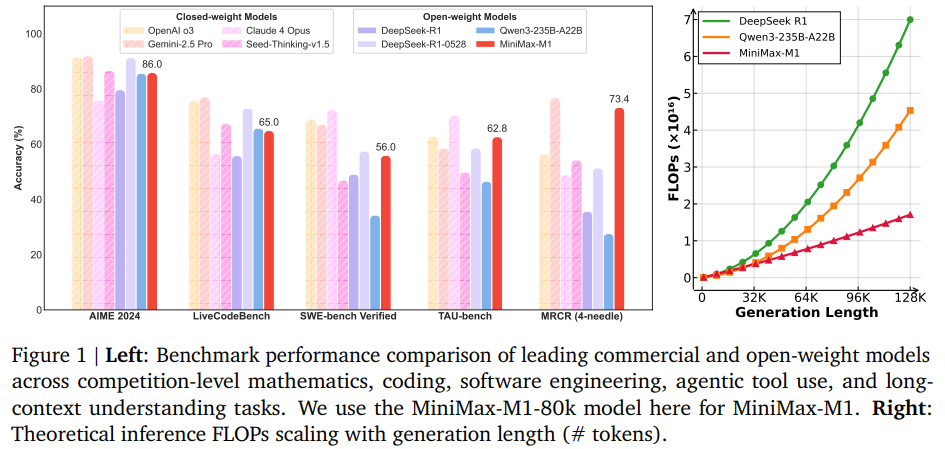
테스트 시 적은 flops로 높은 성능을 보여주고 있음
length가 길어져도 기하급수적으로 flops가 커지지 않는 모습
Introduction
기존 트랜스포머 아키텍처 내에서 추론 프로세스를 계속 확장하는 것은 quadratic computational complexity of the softmax attention mechanism으로 인해 어렵습니다.
이전 연구에서는 sparse attention, linear attention, linear attention with delta decay, state space models, linear RNNs과 같은 다양한 기술을 제안했지만 대두분 대규모 추론 모델에서 완전히 검증되지 않았습니다.
현재까지 거의 모든 경쟁력 있는 LRM은 여전히 전통적인 어텐션 설계를 사용합니다.
예외는 Mamba 아키텍처를 사용하는 Hunyuan-T1 모델(Tencent AI Lab, 2025)이지만 이 모델은 오픈소스가 아니며 세부 정보가 거의 공개되지 않았습니다.
이 연구에서는 테스트 시간 연산을 효율적으로 확장하고 최신 추론 모델과 경쟁할 수 있는 대규모 추론 모델을 구축하고 오픈소스화하는 것을 목표로 합니다.
Mixture-of-Experts 아키텍처와 I/O-aware implementation of a linear attention 변형인 Lightning Attention을 특징으로 하는 추론 모델인 MiniMax-M1을 소개합니다.
MiniMax-M1은 이전 MiniMax-Text-01 모델을 기반으로 개발되었으며 총 4560억 개의 매개변수와 459억 개의 활성화, 32개의 전문가를 포함합니다.
어텐션 설계에서는 Lightning Attention이 적용된 7개의 transnormer 블록 다음에 소프트맥스 어텐션이 적용된 트랜스포머 블록이 뒤따릅니다.
이 설계는 그림 1(오른쪽)에 나타난 것처럼 추론 길이를 수십만 토큰으로 효율적으로 확장할 수 있도록 지원합니다.
DeepSeek R1과 비교할 때 M1은 64K 토큰의 생성 길이에서 FLOP의 50% 미만을 소비하고 100K 토큰 길이에서는 약 25%를 소비합니다.
상당한 연산 비용 절감은 M1을 추론과 대규모 RL 훈련 모두에서 훨씬 더 효율적으로 만듭니다.
Lightning Attention 메커니즘 덕분에 MiniMax-Text-01과 마찬가지로 M1 모델은 최대 100만 토큰의 컨텍스트 길이를 기본적으로 지원합니다.
DeepSeek R1의 컨텍스트 크기의 8배이 현재까지 사용 가능한 모든 오픈소스 LRM보다 한 자릿수 더 큽니다.
M1 모델을 개발하기 위해 먼저 신중하게 선별된 추론 집약적 코퍼스에서 MiniMax-Text-01을 7.5T 토큰으로 사전 훈련을 계속했습니다.
CoT 패턴을 주입하기 위해 SFT을 수행하여 M1 개발의 핵심 단계인 강화 학습을 위한 강력한 기반을 마련했습니다.
M1을 사용한 RL 스케일링은 두 가지 핵심 관점에서의 혁신을 통해 효율적으로 이루어졌습니다.
(1) 신뢰 영역 제약을 포기하고 훈련을 안정화하기 위해 중요도 샘플링 가중치를 클리핑하는 새로운 RL 알고리즘인 CISPO를 제안합니다. 이 접근 방식은 항상 모든 토큰을 그래디언트 계산에 활용하여 GRPO, DAPO에 비해 경험적으로 향상된 효율성을 달성합니다. Qwen2.5-32B 모델을 기반으로 한 제어 연구에서 CISPO는 DAPO에 비해 2배 빠른 속도를 달성합니다.
(2) M1의 하이브리드 어텐션 설계는 효율적인 RL 스케일링을 허용하지만 이 아키텍처로 RL을 스케일링할 때 고유한 문제가 발생합니다. 아키텍처의 훈련 및 추론 커널 간의 정밀도 불일치로 인해 RL 훈련 중 보상 증가가 방지되는 것을 발견했습니다. 이러한 문제를 해결하고 이 하이브리드 아키텍처로 RL을 성공적으로 확장하기 위한 맞춤형 솔루션을 개발합니다. 효율적인 RL 프레임워크를 통해 512개의 H800 GPU를 사용하여 3주 이내에 MiniMax-M1의 전체 RL 실행을 완료할 수 있었으며 이는 약 0.53M USD의 임대 비용에 해당합니다.
방법론적 혁신 외에도 RL 훈련을 위해 다양한 문제 및 환경 세트를 큐레이팅했습니다.
데이터는 검증 가능한 문제와 검증 불가능한 문제를 모두 포함합니다. 추론 학습에 일반적으로 중요하다고 간주되는 검증 가능한 문제의 경우 관련 연구에서 일반적으로 사용되는 수학적 추론 및 경쟁 프로그래밍 문제를 포함할 뿐만 아니라 이전 데이터 합성 프레임워크인 SynLogic을 활용하여 41가지 고유한 작업에 걸쳐 다양한 논리 추론 문제를 생성합니다.
SWE-bench에서 파생된 복잡한 소프트웨어 엔지니어링 환경을 위한 샌드박스를 구축하고 실행 기반 보상을 통해 실제 SE 문제에 대해 RL을 수행하여 어려운 SE 시나리오에서 M1의 성능을 향상시킵니다.
Preparation for Scalable RL: Continual Pretraining and SFT
Minimax-Text-01의 추론 능력을 향상시키기 위해 강화 학습의 규모를 확장하는 데 중점을 둡니다.
확장 가능한 RL 훈련을 용이하게 하기 위해 기본 모델의 내재된 추론 능력을 강화하기 위해 지속적인 사전 학습을 수행합니다.
모델에 특정 추론 패턴을 주입하기 위해 cold-start SFT 단계를 수행하여 후속 RL 단계에 더 강력한 기반을 제공합니다.
Continual Pre-Training: Foundation for RL Scaling
다양성을 보장하면서 기반 모델의 추론 및 긴 문맥 처리 능력을 향상시키기 위해 MiniMax-Text-01 모델을 최적화된 데이터 품질과 혼합으로 7.5조 개의 추가 토큰으로 계속 훈련합니다.
Training Data
웹, PDF 구문 분석 메커니즘을 개선하고 수학 및 코드 관련 데이터에 대한 높은 회수율을 보장하기 위해 heuristic cleaning rules을 강화합니다.
웹페이지, 포럼, 교과서를 포함한 다양한 출처에서 자연스러운 QA 쌍을 추출하는 것을 우선시하며 합성 데이터의 사용은 엄격히 피합니다.
QA 데이터의 다양성과 고유성을 유지하기 위해 의미론적 중복 제거를 수행합니다.
STEM, 코드, 서적 및 추론 관련 데이터의 비율을 70%로 늘립니다.
이는 다른 일반적인 기능을 손상시키지 않으면서 기반 모델이 복잡한 작업을 처리하는 능력을 크게 향상시킵니다.
Training Recipe
MoE auxiliary loss의 계수를 줄이고 더 큰 훈련 마이크로 배치 크기를 지원하도록 병렬 훈련 전략을 조정하여 auxiliary loss가 전체 모델 성능에 미치는 해로운 영향을 완화합니다.
MiniMax-Text-01을 기반으로 8e-5의 일정한 learning rate로 2.5조 개의 토큰을 계속 훈련한 다음 5조 개의 토큰에 걸쳐 8e-6으로 감소시키는 스케줄을 따릅니다.
Long Context Extension.
수렴 복잡성이 높은 하이브리드-라이트닝 아키텍처 모델의 경우 훈련 길이의 지나치게 공격적인 확장이 훈련 과정에서 갑작스러운 경사 폭발로 이어질 수 있음을 확인했습니다.
이는 최적화 과정을 극도로 어렵게 만듭니다.
초기 계층의 파라미터 최적화가 후기 계층의 변화를 따라가지 못하기 때문이라고 생각합니다.
라이트닝 어텐션의 경우 초기 및 후기 계층은 다른 감쇠율을 가지므로 초기 계층이 지역 정보에 더 집중합니다.
32K 문맥 창 길이부터 시작하여 궁극적으로 훈련 문맥을 1M 토큰으로 확장하는 4단계에 걸쳐 더 부드러운 문맥 길이 확장을 적용하여 이 문제를 완화합니다.
Supervised Fine-Tuning: Focused Alignment for Efficient RL
지속적인 사전 학습 후 고품질 예제를 사용하여 리플렉션 기반 CoT 추론과 같은 원하는 행동을 주입하기 위해 SFT을 수행하여 다음 단계에서 더 효율적이고 안정적인 RL을 위한 강력한 시작점을 만듭니다.
긴 CoT 응답을 포함하는 데이터 샘플을 큐레이션합니다.
이 데이터 샘플은 수학, 코딩, STEM, 글쓰기, 질의응답 및 다중 턴 채팅과 같은 다양한 도메인을 다룹니다. 수학 및 코딩 샘플은 전체 데이터의 약 60%를 차지합니다.
Efficient RL Scaling: Algorithms and Lightning Attention
그림 1 (우측)에서 볼 수 있듯이 M1 아키텍처는 추론 시 효율성 이점을 보여줍니다.
더 긴 응답이 생성되는 효율적인 RL 스케일링을 이점이 있습니다.
하이브리드 아키텍처로 RL을 확장하는 첫 번째로서 독특한 문제에 직면하며 다양한 문제로 인해 RL 절차가 불안정해지거나 실패할 수도 있습니다.
어려움을 해결하기 위해 M1에 대한 RL 훈련을 성공적으로 확장할 수 있도록 맞춤형 솔루션을 개발합니다.
기존 방법과 비교하여 더 큰 RL 효율성을 달성하는 새로운 RL 알고리즘을 제안합니다.
Efficient RL Scaling with CISPO
Background
그림 1 (우측)에서 볼 수 있듯이, M1 아키텍처는 추론 시 분명한 효율성 이점을 보여줍니다. 이는 점점 더 긴 응답이 생성되는 효율적인 RL 스케일링을 자연스럽게 촉진합니다. 그러나 이 하이브리드 아키텍처로 RL을 확장하는 선구자로서, 우리는 이 과정에서 독특한 문제에 직면하며, 다양한 문제로 인해 RL 절차가 불안정해지거나 심지어 실패할 수도 있습니다. 이러한 어려움을 해결하기 위해 M1에 대한 RL 훈련을 성공적으로 확장할 수 있도록 맞춤형 솔루션을 개발합니다. 또한, 기존 방법과 비교하여 더 큰 RL 효율성을 달성하는 새로운 RL 알고리즘을 제안합니다. 이러한 두 가지 기여는 M1 훈련을 위한 효율적이고 확장 가능한 RL 프레임워크를 제공하며, 전체 훈련 주기는 512 H800 GPU에서 3주가 소요되며, 이는 약 0.53M USD의 임대 비용에 해당합니다. 이 섹션에서는 먼저 RL에 대한 일반적인 맥락을 제공하고 새로운 RL 알고리즘을 제시한 다음, 하이브리드 아키텍처에서 직면하는 특정 문제와 이를 극복하기 위해 고안한 솔루션에 대해 설명합니다.
3.1. CISPO를 사용한 효율적인 RL 스케일링
배경.
데이터셋 D의 질문 에 대해 로 매개변수화된 정책 모델을 로 정책에 의해 생성된 응답을 로 나타냅니다.
PPO는 예상 리턴을 최대화하기 위해 정책을 최적화하기 위해 다음 목표를 채택하고 훈련을 안정화하기 위해 클리핑 작업이 적용됩니다.
여기서 는 중요도 샘플링 가중치이며 오프라인 정책 업데이트 중에 분포를 수정하는 데 사용됩니다.
왜냐하면 방식으로 여러 단계를 통해 정책을 업데이트하기 위해 를 사용하여 trajectorie를 수집하기 때문입니다.
PPO는 advantage 를 계산하기 위해 별도의 가치 모델이 필요하지만 GRPO는 가치 모델을 제거하고 이점을 그룹의 다른 응답에 대한 출력 보상으로 정의합니다.
여기서 는 응답의 보상이며, 각 질문에 대해 개의 응답 가 샘플링됩니다. 보상은 수학 문제 해결에서와 같이 규칙 기반 검증자에서 나오거나 보상 모델에서 나옵니다.
Issues of Token Clipping
Zero-RL 설정에서 하이브리드 아키텍처를 사용한 초기 실험에서 GRPO 알고리즘이 훈련 성능에 부정적인 영향을 미치고 긴 CoT 추론 행동의 출현을 효과적으로 촉진하지 못하는 것을 관찰했습니다.
일련의 통제된 ablation studie를 통해 원래 PPO/GRPO 손실의 바람직하지 않은 클리핑 작업이 학습 성능 저하의 주요 요인임을 확인했습니다.
reflective behavior(예: However, Recheck, Wait, Aha)과 관련된 토큰이 추론 경로에서 "“forks" 역할을 하는 경우가 많으며 기본 모델에 의해 일반적으로 낮은 확률이 할당된다는 것을 발견했습니다.
정책 업데이트 중에 이러한 토큰은 높은 값을 나타낼 가능성이 높았습니다.
이러한 토큰은 첫 번째 on-policy 업데이트 후에 클립되어 후속
off-policy 그라디언트 업데이트에 기여하지 못하게 됩니다.
이 문제는 하이브리드 아키텍처 모델에서 두드러졌으며 강화 학습의 확장성을 더욱 저해했습니다.
그러나 낮은 확률 토큰은 종종 엔트로피를 안정화하고 확장 가능한 RL을 촉진하는 데 중요합니다.
DAPO는 상한 클리핑 경계를 증가시켜 이 문제를 완화하려고 시도하지만 이 접근 방식이 생성 배치당 16라운드의 off-policy 업데이트를 포함하는 우리 설정에서는 덜 효과적이라는 것을 발견했습니다.
The CISPO Algorithm.
큰 업데이트와 관련된 토큰조차도 드롭하는 것을 명시적으로 피하면서도 안정적인 탐색을 보장하기 위해 엔트로피를 합리적인 범위 내에서 내재적으로 유지하는 새로운 알고리즘을 제안합니다.
첫째 오프라인 업데이트에 대해 수정된 분포를 사용한 바닐라 REINFORCE 목표는 다음과 같습니다.
는 stop-gradient 연산을 나타냅니다.
PPO/GRPO에서처럼 토큰 업데이트를 클리핑하는 대신 훈련을 안정화하기 위해 중요도 샘플링 가중치를 클리핑합니다.
이 접근 방식을 CISPO (Clipped IS-weight Policy Optimization)라고 명명합니다.
GRPO의 그룹 상대 이점과 토큰 수준 손실을 채택하여 CISPO는 다음 목표를 최적화합니다.
(4)
여기서 는 클립된 IS 가중치입니다.
(5)
가중치 클리핑이 없으면 는 표준 정책 그래디언트 목표로 감소합니다.
를 큰 값으로 설정하여 IS 가중치에 하한을 부과하지 않았습니다.
만 튜닝했습니다.
Eq. 4의 그래디언트는 가중치 클리핑으로 인해 약간 편향되지만 이 접근 방식은 모든 토큰 특히 긴 응답의 그래디언트 기여를 보존합니다.
CISPO는 우리의 실험에서 효과적임이 입증되었으며 분산을 줄이고 RL 훈련을 안정화하는 데 도움이 됩니다.
동적 샘플링 및 길이 페널티 기법을 활용합니다.
다른 최근 연구와 유사하게 CISPO에는 KL 페널티 항이 없습니다.
A General Formulation.
CISPO를 채택했지만 여기서는 CISPO 목표에 토큰 단위 마스크를 도입하여 통합된 공식화를 제시합니다.
특정 토큰의 그래디언트가 드롭되어야 하는지 여부와 어떤 조건에서 드롭되어야 하는지를 제어하기 위한 하이퍼파라미터 튜닝을 허용합니다.
(6)
마스크 는 equivalent to the mask implicitly defined in the PPO trust region:
(7)
통합된 손실 공식은 공통 프레임워크 내에서 다양한 클리핑 전략을 유연하게 나타낼 수 있습니다.
Empirical Validation of CISPO.
CISPO의 효과를 검증하기 위해 zero-RL 훈련 설정에서 DAPO 및 GRPO와 경험적으로 비교합니다.
수학적 추론 데이터셋에 Qwen2.5-32B-base 모델을 훈련하기 위해 다른 RL 알고리즘을 적용하고 AIME 2024 벤치마크에서 성능을 보고합니다.
그림 2에서 볼 수 있듯이 CISPO는 동일한 훈련 단계에서 DAPO와 GRPO를 모두 크게 능가합니다.
CISPO는 다른 접근 방식보다 우수한 훈련 효율성을 보여줍니다.
Efficient RL Scaling with Lightning Attention – Challenges and Recipes
그림 1 (우측)에서 볼 수 있듯 하이브리드 어텐션은 롤아웃 계산 및 지연 시간이 RL 훈련의 주요 병목 현상인 경우가 많기 때문에 기존 어텐션 설계보다 본질적으로 더 효율적인 RL 스케일링을 가능하게 한다는 것을 강조합니다.
새로운 아키텍처로 대규모 RL 실험을 수행하는 선구자로서 독특한 문제에 직면했으며 아래에서 설명할 맞춤형 솔루션을 개발했습니다.
Computational Precision Mismatch in Generation and Training.
RL 훈련은 계산 정밀도에 매우 민감합니다.
RL 훈련 중에 그림 3 (좌측)에서 볼 수 있듯이 훈련 모드와 추론 모드 간에 롤아웃된 토큰의 확률에 상당한 불일치가 있음을 관찰했습니다.
이 불일치는 훈련 및 추론 커널 간의 정밀도 불일치로 인해 발생했습니다.
이 문제는 치명적이었고 실험에서 보상 성장을 방해했습니다.
흥미롭게도 이 문제는 소프트맥스 어텐션을 사용하는 더 작고 밀집된 모델에서는 나타나지 않았습니다.
계층별 분석을 통해 우리는 LM 헤드의 출력 계층에서 높은 크기의 활성화가 오류의 주요 원인임을 확인했습니다.
이를 해결하기 위해 LM 출력 헤드의 정밀도를 FP32로 높여 이론적으로 동일한 두 확률을 재정렬했습니다.
이는 그림 3 (우측)에 나와 있습니다. 이 조정은 훈련 및 추론 확률 간의 상관 관계를 약 0.9x에서 0.99x로 향상시켰습니다. 특히, 이 상관 관계 메트릭은 훈련 내내 안정적으로 유지되어 성공적인 보상 증가를 가능하게 했습니다.
Optimizer Hyperparameter Sensitivity.
AdamW 옵티마이저를 사용하며 , , 및 의 부적절한 구성은 훈련 중 비수렴으로 이어질 수 있습니다.
예를 들어 , 인 VeRL의 기본 구성을 사용하면 이러한 문제가 발생할 수 있습니다.
MiniMax-M1 훈련에서 그래디언트 크기가 1e-18에서 1e-5까지 넓은 범위를 가지며 대부분의 그래디언트가 1e-14보다 작다는 것을 관찰했습니다.
인접한 반복의 그래디언트 간의 상관 관계가 약합니다.
이를 바탕으로 , , 그리고 로 설정했습니다.
Early Truncation via Repetition Detection.
RL 훈련 중에 복잡한 프롬프트가 병적으로 길고 반복적인 응답을 유발할 수 있으며 이러한 응답의 큰 그래디언트가 모델 안정성을 위협한다는 것을 발견했습니다.
목표는 이미 반복적인 텍스트에 페널티를 부과하기보다 이러한 생성 루프를 미리 종료하는 것이었습니다.
단순한 문자열 일치로는 다양한 반복 패턴에 효과적이지 않으므로 토큰 확률을 기반으로 하는 휴리스틱을 개발했습니다.
모델이 반복 주기에 들어가면 각 토큰의 확률이 급증한다는 것을 관찰했습니다.
Early Truncation 규칙을 구현했습니다.
3,000개의 연속 토큰 각각의 확률이 0.99를 초과하면 생성이 중단됩니다.
이 방법은 모델 불안정성을 성공적으로 방지하고 이러한 병적인 롱테일 사례를 제거하여 생성 처리량을 향상시킵니다.
