Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.v1
느낀점
- 진짜 고민을 많이하고 전략이 체계적인 게 느껴짐
- 모델 사이즈와 추론 속도는 사용해볼만 하고 실질적인 대안을 제시하는 느낌
- 실체감은 qwen 보다 아래 sdxl보다 위라는 평가?
- 데이터 정제와 핸들링을 팀 단위? 회사 단위로 하는지 궁금함
Abstract
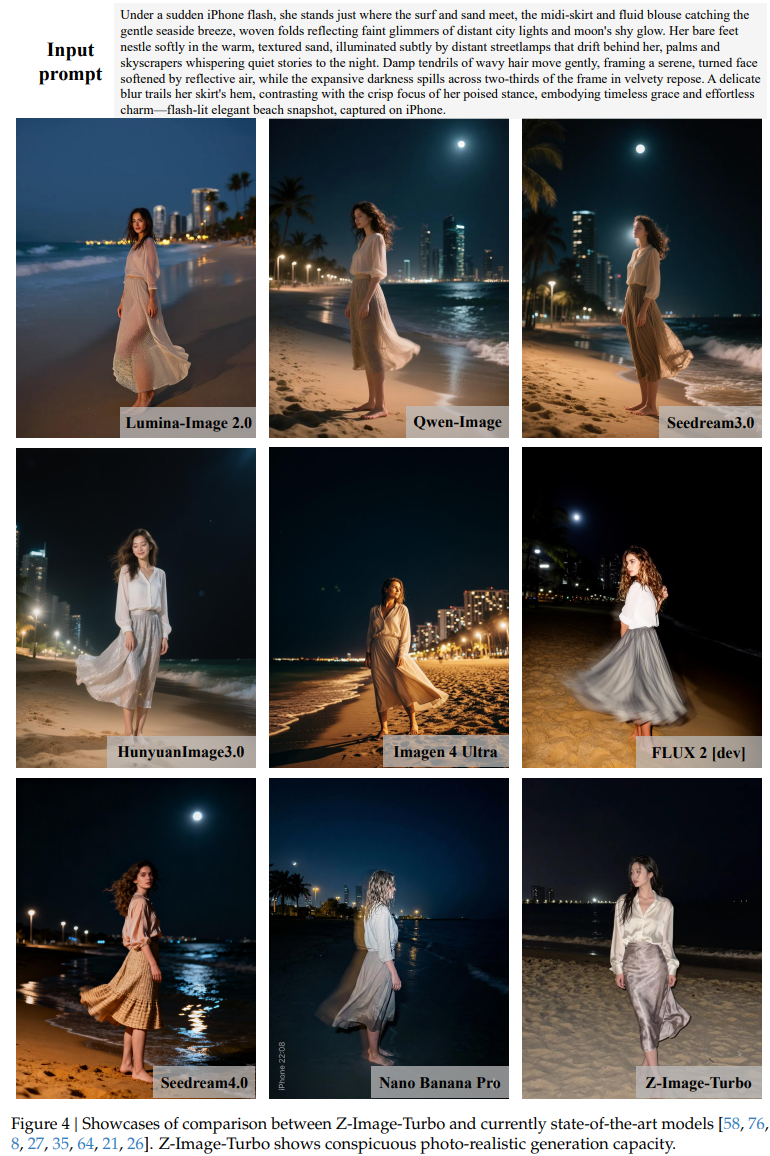
최근 이미지 생성 모델 시장은 양극화되어 있습니다.
Nano Banana Pro, Seedream 4.0과 같은 고성능 모델이 시장을 지배하거나 오픈소스 진영에서는 Qwen-Image, Hunyuan-Image-3.0, FLUX.2와 같이 20B~80B에 달하는 거대 모델들이 주류를 이루고 있습니다.
하지만 이러한 모델들은 일반 소비자용 GPU(Consumer-grade Hardware)에서 추론이나 파인튜닝을 수행하기엔 VRAM 및 연산 비용 측면에서 매우 비실용적입니다.
오늘 소개할 논문은 이러한 "Scale-at-all-costs" 패러다임에 도전장을 내민 Z-Image입니다.
단 6B 파라미터만으로 상용 모델 수준의 성능을 달성한 이 모델의 핵심 기술을 살펴보겠습니다.
1.Core Architecture: S3-DiT 기반의 효율성 극대화
Z-Image는 Scalable Single-Stream Diffusion Transformer (S3-DiT) 아키텍처를 기반으로 설계되었습니다. 핵심은 단순히 모델 사이즈를 줄인 것이 아니라, 전체 모델 라이프사이클을 최적화했다는 점입니다.
파라미터 수: 6B (기존 오픈소스 대비 약 1/4 ~ 1/10 수준)
훈련 비용: 314K H800 GPU hours (약 $630K). 이는 SOTA급 모델 훈련 비용 치고는 매우 경제적인 수치입니다.
최적화 전략: 정제된 데이터 인프라 구축부터 훈련 커리큘럼의 간소화까지 모델 학습의 전 과정을 체계적으로 최적화했습니다.
2.Z-Image-Turbo: Latency와 VRAM의 혁신
엔지니어 관점에서 가장 주목할 부분은 Z-Image-Turbo입니다.
Few-step Distillation & Reward Post-training: Reward Post-training과 결합된 Distillation 기법을 적용했습니다.
Inference Latency: H800 기준 Sub-second(1초 미만) 생성 속도를 자랑합니다.
Hardware Compatibility: 16GB VRAM 미만의 소비자용 GPU에서도 구동 가능합니다. 이는 로컬 환경에서의 개발 및 서비스 배포 용이성을 획기적으로 높여줍니다.
3.기능적 강점: Photorealism & Bilingual Text
논문에서는 정성적/정량적 평가 모두에서 경쟁 모델과 대등하거나 능가하는 결과를 보여준다고 주장합니다.
Photorealistic Generation: 실사 이미지 생성 능력에서 탁월한 성능을 보입니다.
Bilingual Text Rendering: 기존 모델들이 어려워하던 텍스트 렌더링, Bilingual 처리 능력이 Top-tier commercial models 수준에 도달했습니다.
Instruction Following (Z-Image-Edit): 'Omni-pre-training' 패러다임을 통해 단순히 이미지를 생성하는 것을 넘어 복잡한 지시사항을 따르는 Editing 모델로도 확장이 가능합니다.
4.Summary & Insight
이 논문의 의의는 명확합니다. "SOTA 성능을 위해 반드시 수백 억 개의 파라미터가 필요한가?" 라는 질문에 대해 효율적인 아키텍처와 최적화된 훈련 파이프라인으로 "아니오" 라고 답하고 있습니다.
코드와 Weights, 데모가 모두 공개될 예정이므로, 리소스가 제한적인 연구실이나 스타트업, 그리고 개인 개발자들에게 강력한 베이스 모델 옵션이 될 것으로 보입니다. 특히 <16GB VRAM 지원은 로컬 LLM/Diffusion 서빙을 준비하는 엔지니어들에게 매우 반가운 소식입니다.
Introduction
1.Problem Statement: 거대 모델과 합성 데이터의 한계
현재 T2I 연구 환경은 두 가지 큰 장벽에 부딪혀 있습니다.
- 컴퓨팅 비용의 폭증: 오픈 소스 모델들조차 20B~80B에 달하는 파라미터를 사용하며 막대한 학습/추론 비용을 요구합니다.
- 데이터 Homogenization: 상용 모델의 데이터를 증류하여 학습할 경우 학습 비용은 낮출 수 있으나 티쳐 모델의 한계를 벗어나지 못하고 에러가 누적되는 피드백 루프에 갇힐 위험이 있습니다.
Z-Image는 314K H800 GPU hours(약 628,000달러)라는 비교적 저렴한 예산으로 전 과정을 완료하며 효율적인 설계가 Brute-force scaling을 압도할 수 있음을 증명했습니다.
2.Efficient Data Infrastructure
데이터의 양보다 단위 시간당 지식 습득량에 집중했습니다.
이를 위해 4가지 모듈을 구축했습니다.
- Data Profiling Engine: 다차원 특성 추출을 통한 데이터 정밀 분석.
- Cross-modal Vector Engine: 시맨틱 중복 제거 및 타겟팅된 데이터 검색.
- World Knowledge Topological Graph: 개념 간의 구조적 관계 조직화.
- Active Curation Engine: 폐쇄 루프 기반의 데이터 정제.
이 시스템을 통해 적절한 데이터를 모델 발전의 적절한 단계에 투입함으로써 저품질 데이터로 인한 연산 낭비를 최소화했습니다.
3.S3-DiT (Scalable Single-Stream Multi-Modal DiT)
Z-Image의 핵심 아키텍처는 Single-Stream 설계입니다.
- Dense Interaction: 텍스트와 이미지 모달리티를 분리해서 처리하는 Dual-stream 방식과 달리 모든 레이어에서 모달리티 간의 밀접한 상호작용을 유도합니다.
- Unified Tokenization: 텍스트 토큰, VAE 토큰, 시맨틱 토큰을 동일한 프레임워크 내에서 처리하여 T2I뿐만 아니라 Image Editing 작업까지 자연스럽게 통합했습니다.
- Prompt Enhancer (PE): 6B라는 비교적 작은 파라미터의 한계를 극복하기 위해 복잡한 세계 지식과 프롬프트 이해력을 보완하는 모듈을 도입했습니다.
4.Three-Phase Progressive Training
학습 전략 또한 단계별 효율화를 꾀했습니다.
- Low-resolution Pre-training: 해상도에서 기초적인 시각-언어 Alignment 습득.
- Omni-pretraining: 임의의 해상도 생성, T2I, Image-to-Image 수정을 하나의 단계에서 통합 학습하여 리소스 소모를 분할 상환함.
- PE-aware SFT: 강화된 프롬프트(PE-enhanced captions)를 활용한 미세 조정 단계로 별도의 LLM 학습 비용 없이 디퓨전 백본과의 시너지를 극대화함.
5.Inference & Optimization (Z-Image-Turbo)
추론 속도와 품질의 트레이드오프를 해결하기 위해 Z-Image-Turbo를 선보였습니다.
- Decoupled DMD (Distribution Matching Distillation): 품질 향상과 학습 안정화 역할을 분리하여 증류 효율 극대화.
- DMDR: RL을 도입하여 분포 매칭 항을 정규화 요소로 사용.
- Result: 단 8 NFEs(Number of Function Evaluations) 만에 고해상도 이미지를 생성하며 16GB 미만의 VRAM을 가진 소비자용 GPU에서도 구동 가능합니다.
6.Conclusion: 무엇을 시사하는가?
Z-Image는 단순히 성능 좋은 모델을 하나 더 추가한 것이 아닙니다.
- Efficiency as a Priority: 아키텍처, 데이터 정제, 학습 전략 전반에 걸친 원칙 있는 설계가 수백억 개의 파라미터보다 강력할 수 있음을 보여주었습니다.
- Real-world Data Power: 합성 데이터 없이도 정교한 큐레이션을 통해 최고 수준의 시각적 품질과 텍스트 렌더링(Chinese/English)이 가능함을 입증했습니다.
Data Profiling Engine: 다차원 정량 분석의 기초
단순 필터링을 넘어 데이터의 복잡도와 품질을 수치화하여 Curriculum Learning의 신호로 활용합니다.
-
Technical Quality Assessment: 해상도, pHash를 이용한 중복 제거는 기본이며 BPP(Bytes-Per-Pixel)를 Complexity의 프록시로 활용하여 Low-entropy 이미지를 걸러냅니다. 또한 자체 학습된 모델로 압축 아티팩트 및 시각적 열화(Blur, Noise 등)를 스코어링합니다.
-
AIGC Content Detection: 모델 붕괴(Model Collapse)를 막기 위해 AI 생성 콘텐츠를 감지하는 전용 분류기를 가동합니다.
-
High-Level Semantic Tagging: 일반적인 VLM을 고도화하여 객체, 인간의 속성뿐 아니라 문화적 특수 개념까지 태깅합니다. OCR과 워터마크 감지를 별도 모듈이 아닌 VLM의 내재적 능력으로 통합 처리하여 파이프라인을 단순화합니다.
Cross-modal Vector Engine
Stable Diffusion 3(SD3)에서 제안된 중복 제거 방식을 한 단계 발전시켜 Scalability 문제를 해결했습니다.
-
Graph-based Community Detection: 기존의 range_search가 가진 병목을 해결하기 위해 k-NN Search 기반의 근접 그래프를 구축하고 커뮤니티 탐지 알고리즘을 적용했습니다.
-
성능: 8대의 H800 GPU로 10억 개의 아이템을 8시간 만에 인덱싱 및 쿼리할 수 있는 가속 파이프라인을 구축했습니다. 이는 단순 중복 제거뿐 아니라, 모델이 Failure cases의 데이터 클러스터를 역추적해 Pruning하는 모델 Remediation 도구로도 활용됩니다.
World Knowledge Topological Graph
데이터의 개념적 Breadth를 보장하기 위해 지식 그래프를 도입했습니다.
-
구축 공정: Wikipedia 엔티티를 베이스로 하며 VLM을 이용해 시각화 불가능한 추상 개념을 쳐내는 Visual Generatability Filtering을 거칩니다. 이후 내부 데이터의 캡션 임베딩을 계층적으로 구조화하여 통합합니다.
-
Balanced Sampling: 단순히 데이터가 많은 것을 보여주는 것이 아니라 그래프 내 노드 간의 관계와 BM25 스코어를 결합하여 샘플링 가중치를 동적으로 조절합니다. 이를 통해 데이터 분포의 편향을 해결하고 정교한 학습 제어가 가능해집니다.
Active Curation Engine
인프라를 정적인 저장소가 아닌 스스로 진화하는 Dynamic Engine으로 만듭니다.
-
Hard Case Mining: 모델이 성능을 내지 못하는 영역을 자동 샘플링하여 탐사합니다.
-
Human-in-the-loop (HITL): Reward Model과 Captioner가Pseudo-label을 부여하면 인간과 AI 검수자가 이를 검증하고 수정하는 피드백 루프를 가집니다. 이 과정을 통해 고품질의 주석 데이터가 다시 모델 학습에 투입되는 선순환 구조를 완성합니다.
Z-Image-Edit을 위한 특화 파이프라인
이미지 편집 모델 학습을 위해 "편집 전 후 Pair" 데이터를 생성하는 기법이 매우 효율적입니다.
- Mixed Editing: 한 쌍의 이미지에 여러 편집 동작을 통합하여 학습 효율을 높입니다.
- Graphical Representation: 하나의 원본 이미지에서 개의 편집본을 생성한 뒤 이를 조합하여 개의 학습 쌍을 생성하는 전략을 취합니다. 이는 데이터 양을 기하급수적으로 늘릴 뿐 아니라 Inverse pairs 학습에도 효과적입니다.
- Video-based Pairs: 비디오 프레임 간의 자연스러운 변화(Pose, Background 등)를 편집 데이터로 활용하여 다양성을 확보합니다.
- Text Rendering System: 텍스트 Typography을 위해 폰트, 색상, 위치가 정밀하게 제어된 렌더링 데이터를 합성하여 활용합니다.
