[논문 리뷰] A-Bench: Are LMMs Masters at Evaluating AI-generated Images?
Abstract
AI-generated images (AI 생성 이미지, AIGIs)를 정확하고 효율적으로 평과하는 것은 매우 중요한 과제입니다.
User study를 통해 평가하는 것은 높은 비용과 많은 시간이 소요되기 때문에 LLMs을 사용하여 평가하는 경우가 증가하고 있습니다.
하지만 이러한 접근 방식은 정확도와 타당성 측면에서 많은 의문점을 가지고 있습니다.
또한 대부부 자연을 촬영한 콘텐트를 사용하여 LLM의 능력을 평가하는 점은 다양한 문제를 가지고 올 가능성이 존재합니다.
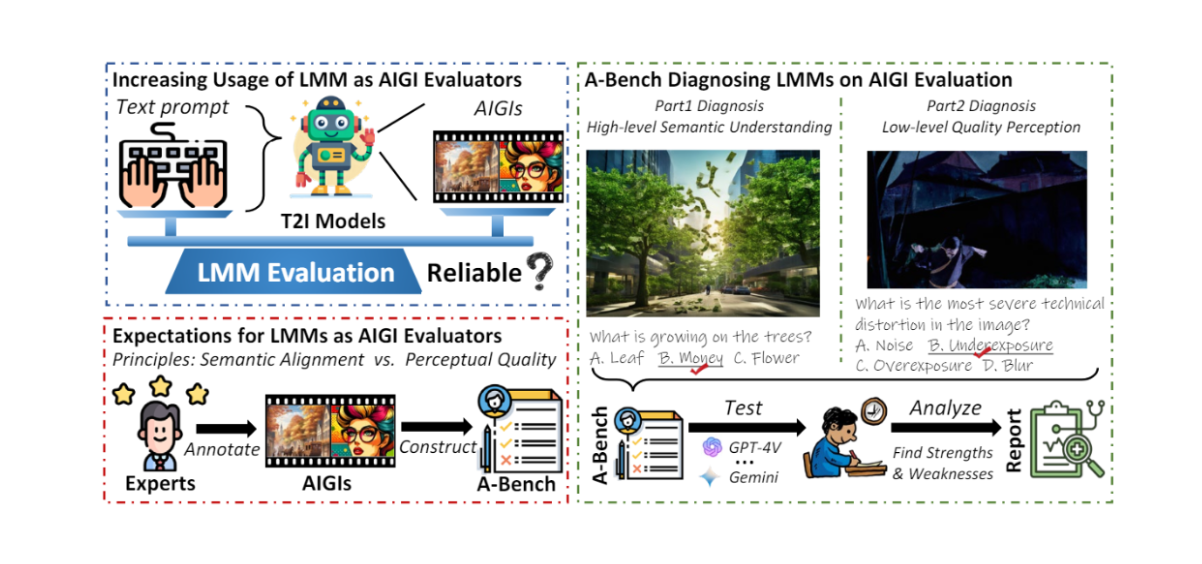
본 논문에서는 이러한 문제를 해결하기 위해 LLM이 AIGI의 평가 전문가인지 확인할 수 있는 벤치마크인 A-Bench를 소개합니다.
2가지 원칙을 따라 벤치마크가 구성됩니다.
- AIGI의 복잡한 요구를 충족시키 위해 high-level의 의미적 이해, low-levle의 시각적 품질 인식을 강조할 수 있어야 합니다.
- 다양한 생성 모델을 사용하여 AIGI를 생성하고, 다양한 LMM을 평가에 사용하여 포괄적인 검증 범위를 보장할 수 있어야 합니다.
Introduction
텍스트를 이미지로 변환하는 모델은 주어진 텍스트 프롬프트를 바탕으로 이미지를 생성하는 것에 중점을 둡니다.
이미지 생성 모델들은 고품질의 이미지를 생성하기 위해 발전하고 있으며 AlignDRAW, GAN, 최근의 stable-diffusion model과 같은 여러 혁신적인 접근 방식이 되입되었습니다.
여러 모델들이 발전했음에도 여전히 텍스트와 이미지의 일치성 문제와 이미지의 인식 품질 문제는 지속적으로 발생합니다.
생성 이미지를 평가하기 위해 여러 전문가들은 LLM을 활용하여 평가를 시도하고 있지만 여전히 몇 가지 문제점이 존재합니다.
LMM-based evaluators는 SRCC/PLCC 같은 지표를 사용하여 평가의 신뢰성을 측정하지만, evaluators의 강점과 약점을 충분히 설명하지 못합니다.
이러한 evaluators의 성능을 진단할 수 있는 새로운 벤치마크인 A-Bench를 제안합니다.
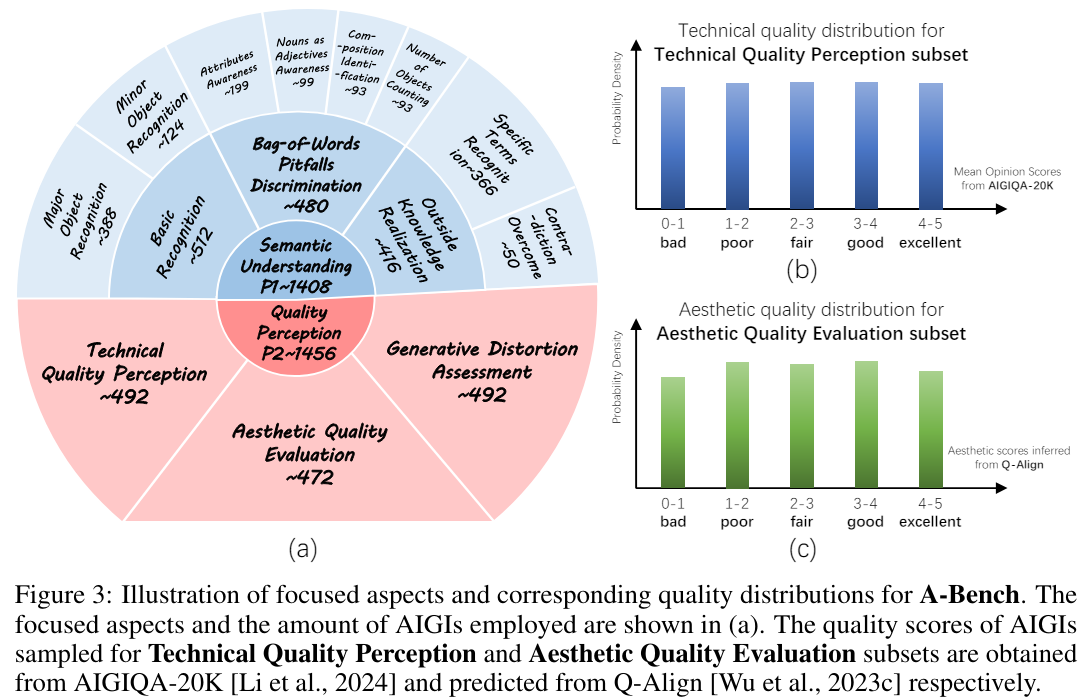
A-Bench는 LLM의 능력을 평가하기 위해 고수준, 저수준 인식을 중점으로 두 가지 주요 하위집단(A-BenchP1과 A-BenchP2)으로 나뉩니다.
- A-BenchP1 - high-level semantic understanding
- Basic Recognition (기본 인식)
- Bag-of-Words Pitfalls Discrimination (단어 모음 함정 구분)
- Outside Knowledge Realization (외부 지식 활용)
- A-BenchP2 - low-level semantic understanding
- Technical Quality Perception (기술적 품질 인식)
- Aesthetic Quality Evaluation (미적 품질 평가)
- Generative Distortion Assessment (생성 왜곡 평가)
A-Bench는 총 2,864개의 AIGI로 구성되어 있으며, 각 이미지에는 인간 전문가가 주석을 단 질문-답변 쌍으로 구성되어 있습니다.
이를 통해 18개의 주요 LMM을 테스트한 결과, 인간 평가자보다 LMM의 성능이 현저히 떨어지는 것을 확인할 수 있습니다.
Related Works
Large Multi-modal Models
대규모 언어 모델 (LLMs)는 대부분 일반적인 인간 지식 영역에서 높은 언어적 능력을 보입니다. GPT-4, LLaMa와 같은 모델들이 대표적입니다.
LLMs은 이미지 입력을 텍스트 입력과 통합하여 멀티모달 테스크를 수행하는 LMMs로 확장되었습니다.
멀티모달 모델을 통해 이미지 캡션 생성, 이미지 질문 응답, 시각적 분석, 시각적 추론과 같은 다양한 멀티모달 작업을 수행할 수 있습니다.
Multi-modal Benchmarks
멀티모달 모델의 성능을 평가하기 위해 다양한 벤치마크가 개발되었습니다.
COCO Caption: 이미지에 대한 텍스트 설명 생성 능력을 평가.
Nocaps: 모델이 이미지에 대해 생성한 설명의 품질을 평가.
GQA: 시각적 질문 응답 능력을 평가.
OK-VQA: 시각적 인식 및 추론 능력을 평가.
TextVQA: OCR 작업을 포함한 텍스트 기반 시각적 질문 응답 평가.
ScienceQA: 상식적 추론 능력을 평가.
MME: 다양한 서브태스크에 대한 LMMs의 포괄적인 평가.
MMbench: 여러 서브태스크에 대한 평가 제공.
MMMU: 대학 수준의 지식과 복잡한 추론이 필요한 멀티디서플린 태스크 평가.
Q-Bench: 저수준 시각적 인식 능력을 평가.
다양한 멀티모달 벤치마크가 개발되었지만 AIGI 평가 능력을 체계적으로 평가하는 벤치마크는 부족합니다.
제안하는 A-Bench는 LMM의 의미 이해와 품질 인식 능력을 진단하고 평가하는데 중점을 둡니다.
Constructing the A-Bench
Key Principles
이미지 생성의 요구사항은 점점 엄격해지고 높아지고 있습니다.
LMM이 이러한 기준을 충족하는 AIGI를 평가할 수 있는지를 확인하기 위해, high-level과 low-level 인식 능력을 평가하는 것이 중요합니다.
다양한 AIGI 범위를 보장하기 위해 다양한 mainstream 텍스트-이미지(T2I) 생성 모델을 선택하여 AIGI를 생성합니다.
high-level의 의미 이해를 평가하기 위해 내용이 풍부한 프롬프트를 설계하여 생성된 이미지의 다양성을 보장합니다.
low-level의 품질 인식을 평가하기 위해, 시각적 품질과 해당 품질 분포를 포괄하는 uniform sampling을 사용했습니다.
또한 오픈소스와 영리목적의 이미지를 모두 포함하여 평가를 진행했습니다.

Major Object Recognition
질문: 사진의 왼쪽에 있는 사람의 머리 색깔은 무엇인가요?
답변 후보:
A: 검정 B: 은색 C: 분홍 D: 노랑
정답: B
Attributes Awareness
질문: 왼쪽에서 오른쪽으로 첫 번째 병은 무엇으로 만들어졌나요?
답변 후보:
A: 녹색 플라스틱 B: 파란 철강 C: 녹색 유리 D: 파란 유리
정답: C
Composition Identification
질문: 고고학자의 캠프에서 텐트는 어떻게 배열되어 있나요?
답변 후보:
A: 캠프 파이어 주변에 원형으로 배열됨 B: 캠프의 중앙에 위치 C: 캠프의 빈 공간에 배치
정답: C
Specific Terms Recognition
질문: 이미지에 표현된 그림 스타일은 무엇인가요?
답변 후보:
A: 추상 B: 초현실주의 C: 표현주의 D: 인상주의
정답: C
Focused Aspects
T2I를 평가하기 위해 high-level semantic understanding and low-level quality perception abilities와 나누어 평가하게 됩니다.
High-level Semantic Understanding
LMM이 이미지-텍스트 정렬을 효과적으로 평가할 수 있는지를 확인하기 위해 A-BenchP1을 구현했습니다.
1,408개의 어려운 멀티모달 질문-응답 쌍으로 구성되어 있으며, 고수준 의미 이해를 중점으로 합니다.
- Basic Recognition
- Major Object Recognition: 이미지의 주요 객체 인식, 예를 들어 전경에 있는 사람이나 물체.
- Minor Object Recognition: 이미지 덜 눈에 띄는 객체 인식, 예를 들어 배경 요소나 부수적 캐릭터.
- Bag-of-Words Pitfalls Discrimination
- Attributes Awareness: AIGI에서 객체의 속성을 정확히 식별하는 능력.
- Nouns as Adjectives Awareness: 사를 형용사로 잘못 해석하여 의도된 속성 대신 불필요한 객체를 생성하는 문제.
- Composition Identification: 방향, 가림, 크기 비교, 공간 배치를 포함한 구성 관계를 정확히 이해하는 능력.
- Number of Objects Counting: 프롬프트의 수에 맞게 객체의 수를 정확히 세는 능력.
- Outside Knowledge Realization
- Specific Terms Recognition: 지리, 스포츠, 과학, 재료, 음식, 일상 생활, 생물, 브랜드 및 스타일 등 특정 도메인과 관련된 장면 및 객체 식별.
- Contradiction Overcome: 논쟁적인 프롬프트에서 생성된 AIGI를 평가할 때 중요한 기존 세계 지식과 모순되는 내용을 올바르게 해석하는 능력.
Low-level Quality Perception
이미지 품질에 대한 능력을 평가하기 위해 A-BenchP2를 설계합니다.
- Technical Quality Perception
- 블러, 노이즈, 노출 등 이미지 품질을 직접 저하시킬 수 있는 저수준 특성을 나타냅니다
- Aesthetic Quality Evaluation
- 색상, 조명 등 AIGIs의 미적 매력에 영향을 미치고 다양한 인간의 감정을 불러일으키는 속성을 나타냅니다.
- Generative Distortion Assessment
- generative blur caused by low completion, confusing geometry structure, unnaturalness 등 예기치 않은 AIGI 특정 왜곡을 나타냅니다.
Question Collection
-
Question Type
- 예-아니오 질문과 What questions이 포함된 두 가지 유형의 질문 형식을 사용합니다.
-
Human Expert Annotation
- AIGI 평가 전문가 15명이 한 팀을 구성합니다. 통제된 환경에서 AIGI의 하위 범주에 특정한 질문을 설계하는 임무를 맡고, 각 질문의 내용과 형식을 결정하기 위해 광범위한 지식을 활용합니다.
-
Question Response
- LLMs에 대한 예시 입력 쿼리는 아래의 이미지와 같습니다.
#사용자: 이미지에 표현된 그림 스타일은 무엇인가요?
A. 추상 B. 초현실주의 C. 표현주의 D. 인상주의
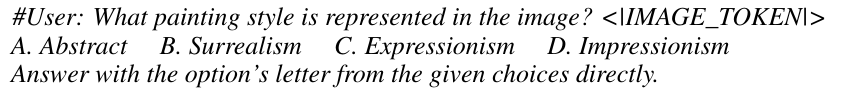
Experiment Results
Benchmark Candidates
비공개 모델 Gemini 1.5 Pro, GPT-4v, GPT-4o, Qwen-VL-Max
오픈 소스 LMMs에는 CogVLM2-19B (Llama3-8B), IDEFICS-2 (Mistral7B-Instruct-v0.2) , DeepSeek-VL-7B, InternLM-XComposer2-VL, LLaVA-NeXT (Llama3-8B), LLaVA-NeXT (Qwen-72B), LLaVA-NeXT (Qwen-110B), mPLUG-Owl2 (LLaMA-7B), LLaVA-v1.5 (Vicunav1.5-7B), LLaVA-v1.5 (Vicuna-v1.5-13B), CogVLM-17B (Vicuna-v1.5-7B), Qwen-VL (Qwen-7B), BakLLava (Mistral-7B), Fuyu-8B (Persimmon-8B).
모든 LMMs는 제로 샷 설정으로 테스트됩니다.
A-Bench에서 인간 능력을 평가하기 위해 다섯 명의 일반 사람들과 통제괸 환경 속에서 user-study를 진행합니다.
LMMs가 진행하는 조건과 동일하게 진행하여 일관성을 유지하도록 합니다.
Findings of A-Bench
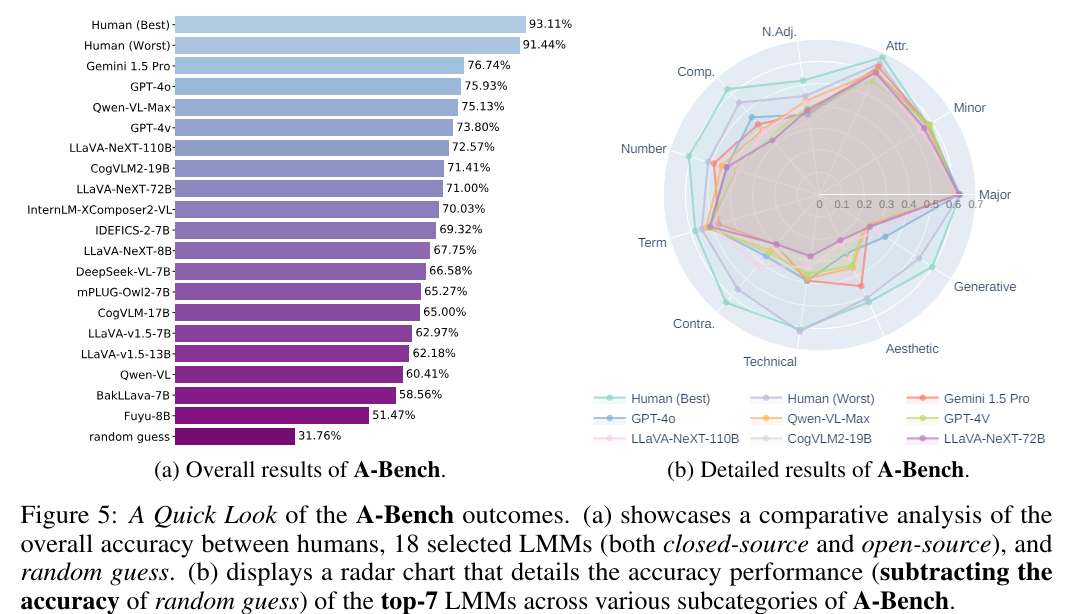
위의 이미지인 Fig.5에서 제공된 A-Bench 결과를 통해 몇 가지 사실을 발견할 수 있습니다.
- 모든 LMMs는 랜덤 추측을 크게 능가하며, AIGI 평가를 처리하는 데 있어 능력을 가지고 있으며, Gemini 1.5 Pro가 선두에 있으며, GPT-4o 및 Qwen-VL-Max가 그 뒤를 이었습니다.
주목할 만한 점은 접근성과 수정 가능성 때문에 AIGI 평가에 선호되는 오픈 소스 LMMs 중에서 LLaVA-NeXT (Qwen-110B)가 두드러지지만, 여전히 비공개 소스 경쟁자들보다 상당히 뒤처집니다. - 가장 낮은 성과를 낸 인간조차도 모든 LMMs를 능가하며, 최고 성과 LMM인 Gemini 1.5 Pro와 비교하여 14.70%의 차이가 나타나 LMMs가 인간처럼 AIGI 평가를 적절하게 수행하기에 아직 멀었음을 나타냅니다.
- Fig. 5 (b)의 차트를 자세히 살펴보면, 상위 LMMs는 다양한 하위 범주에서 다양한 성과를 보여주어 강건성이 부족함을 시사하는 반면, 인간은 이러한 범주 전반에 걸쳐 더 일관되고 균형 잡힌 성과를 보여주어 LMMs가 더 개선해야 할 영역을 강조합니다.
Findings of A-BenchP1
LMMs는 기본 인식 작업에서 뛰어나지만 미묘한 의미 이해에는 덜 효과적입니다.
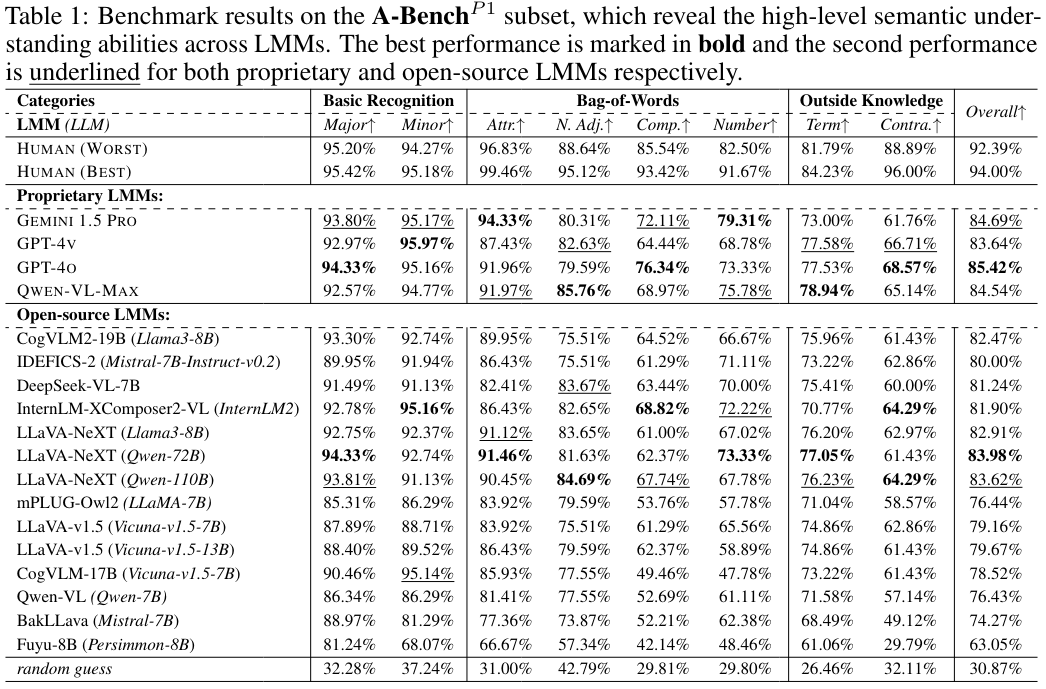
- 거의 모든 LMMs는 기본 인식에서 좋은 성능을 보이며, 이는 AIGIs에서 전경 및 배경 객체를 인식하는 것을 포함하여 기본적인 의미 이해에 능숙합니다.
- 그러나 명사로서의 형용사 인식, 구성 식별 및 객체 수 세기와 같은 복잡한 작업에서는 효과가 감소합니다.
이러한 영역은 더 깊은 의미 이해와 추론이 필요하며, 사용자가 이러한 미묘한 요소를 포함하는 복잡한 프롬프트를 자주 사용하므로 중요합니다.
여기서 LMMs의 저조한 성과는 사용자 프롬프트와 AIGIs를 정확하게 맞추는 데 있어 잠재적인 어려움을 나타냅니다. - 또한 Outside Knowledge는 LMMs가 일반적으로 상식에 반하는 내용을 포함하는 AIGIs에 대해 올바르게 응답하기 위해 사전 지식을 무시해야 하는 Contradiction Overcome 하위 범주에서 낮은 성능을 보입니다.
Specific Terms 하위 범주는 LMMs의 지식 기반을 테스트하며, 독점 LMMs는 일반적으로 더 최근의 광범위한 데이터셋으로 훈련되었기 때문에 더 나은 성과를 보입니다.
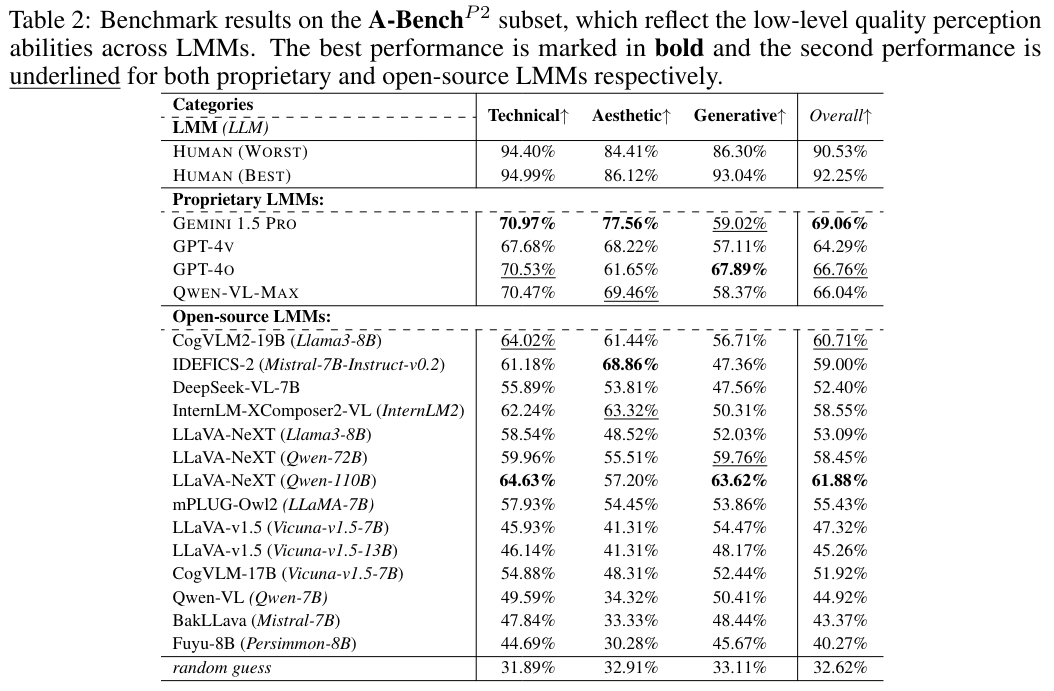
Findings of A-BenchP2
- 최상위 LMMs와 인간 평가자 사이에 약 20%의 성과 차이가 있으며, 이는 LMMs가 품질 인식에서 상당히 뒤처져 있으며 AIGIs의 품질을 정확하게 평가하는 큰 어려움을 겪고 있음을 알 수 있습니다.
- 대부분의 LMMs는 Generative Distortion Assessment 하위 범주에서 가장 약한 성능을 보여주어, 비자연스러운 외관 및 잘못된 기하학적 구조와 같은 예상치 못한 생성 왜곡을 식별하는 데 비효율적임을 시사합니다.
- 흥미롭게도 인간은 일반적으로 기술적 품질 인식에서 미적 품질 평가보다 더 나은 성과를 보이는 반면, LMMs는 두 하위 범주에서 유사한 성과 수준을 보입니다.
이러한 차이는 기술적 품질 평가의 더 객관적인 특성에서 비롯된 것으로 보이며, 이는 인간 사이에서 더 일관된 평가를 이끌어내는 반면, 미적 품질은 더 주관적이어서 의견의 범위가 더 넓어지고 결과적으로 낮은 성과 점수를 초래합니다.
Human vs. Proprietary LMMs
비공개 LMMs는 인간 인식과 밀접하게 유사하며, 특히 AIGI 평가에서 제로 샷 설정에서 뛰어난 성과를 보여줍니다.
- 비공개 LMMs는 기본 인식에서 인간 수준의 성과를 달성하며, 프롬프트가 간단할 때 AIGI 비교적 정확하게 평가할 수 있는 능력을 보여줍니다.
- LMMs는 구성 식별 및 객체 수 세기에서 특히 어려움을 겪으며, 이는 복잡한 구성 관계 및 특정 객체 수를 처리하는 데 있어 한계를 있음을 확인할 수 있습니다..
- Outside Knowledge 영역에서 비공개 LMMs는 Specific Terms에서 인간과 비교하여 약간의 성과 차이를 보이며, 특정 용어에 대한 포괄적인 사전 지식을 보여주지만 논란의 여지가 있는 내용을 식별하는 데 현저히 뒤처집니다.
인간은 모순된 요소를 쉽게 인식할 수 있는 반면, 비공개 LMMs는 상식에 의존하여 정확한 응답을 어렵게 만듭니다.
결론적으로, Table 1에 표시된 결과에 따르면, 비공개 LMMs는 AIGI에서 단순 프롬프트에 대한 평가자로서 유능하지만, AIGI 콘텐츠와 관련된 더 복잡한 프롬프트에서는 추가적인 개선이 필요합니다. - 반면에, Table 2는 인간과 비교하여 LMMs가 저수준 품질 인식에서 상당한 결점을 가지고 있으며, 다양한 품질 차원에서 불균형한 성과를 보임을 나타냅니다.
놀랍게도 GPT-4o는 다른 비공개 LMMs보다 생성 왜곡을 인식하는 데 있어 뚜렷한 이점을 보여주며, 이 영역에서 뛰어난 능력을 시사합니다.
그러나 비공개 LMMs와 인간 간의 품질 인식의 전반적인 큰 차이는 이러한 모델이 현재 AIGI의 시각적 품질을 평가하는 데 적합하지 않음을 강조합니다.
Conclusion
생성된 이미지를 평가함에 있어 LMMs를 사용하는 것은 상당한 결함이 있다는 사실을 A-Bench를 통해 확인했습니다.
해당 벤치마크는 LMMs의 핵심 역량을 파악하여 고수준, 저수준 인식과 같은 근복적인 질문을 정확하게 해결하는 능력에 초점을 맞췄습니다.
A-Bench의 결과는 LMMs가 AIGI 평가에서 직면하는 분명한 한계를 분명하게 상기시켜줍니다.
LMMs가 높은 통찰력이 있음을 확인할 수 있지만 깊은 이해와 세부적인 품질 평가에 현저히 낮은 능력을 보여줍니다.
