인공지능이 만들어내는 환각은 사회에 크고 작은 문제를 발생하고 있습니다.
예를 들어, 지난 2월 AirCanada가 운영하는 챗봇이 잘못된 할인 정보를 제공해 이를 법원에서 인정해주는 일이 발생했습니다.
인공지능의 환각 현상을 예방하기 위해 다양한 방식이 제안되고 있지만 Nature에 발표된 새로운 연구는 환각 가능성이 있는 출력을 79%를 선탐지할 수 있다고 주장합니다.
자세한 논문 리뷰를 통해 어떻게 환각을 탐지할 수 있는지 확인해 보겠습니다.
Abstract
대형 언어 모델(LMMs) ChatGPT, Gemini등은 놀라울 정도로 추론 능력과 높은 질의응답을 보여주고 있습니다.
하지만 종종 환각(Hallucinate) 현상을 보이며 이상한 답변을 생성합니다.
이는 정확한 정보에 대한 혼란을 주어 다양한 분야에 피해를 입힐 수 있습니다.
환각을 줄이기 위한 강화 학습은 부분적으로는 성공적이였지만, 인간들도 대답할 수 없는 새로운 질문에 대한 LLM의 환각을 막기에는 부족했습니다.
본 논문에서는 통계 기반을 둔 entropy-based uncertainty estimators를 제안합니다.
특정 단어보다는 의미 수준에서 uncertainty를 계산하여 하나의 단어가 여러 가지 방식으로 표현될 수 있음을 해결합니다.
해당 방식은 사전 지식 없이 작업이 가능해 새로운 작업에도 견고하게 일반화됩니다.
Main
환각(Hallucinations)은 자연어 생성 task에서 중요한 문제입니다.
환각이 발생한 모델의 신뢰성을 판단할 수 없기 때문입니다.
LLMs의 출력 중 다양한 실패를 환각이라고 판단하고 있지만, 본 논문에서는 유창하게 잘못된 주장을 하는 혼동(confabulations)에 집중합니다.
예시
"Sotorasib(표적항암제의 일종)의 표적은 무엇인가요?"라는 의학적 질문에 대해 LLM이 때로는 KRASG12 'C'(정답)를, 때로는 KRASG12 'D'(오답)를 답변하는 경우가 있습니다.
LLMs의 임의적이고 근거 없는 답변을 생성할 가능성을 나타내는 정량적 측정을 개발함으로써 혼동을 감지하는 방법을 보여줍니다.
해당방식을 이용하게 된다면 LLM의 혼등을 일으킬 가능성이 높은 질문에 대한 답변을 회피하거나, 더 근거 있는 검색을 사용하여 보완할 수 있습니다.
혼동을 측정하기 위해서 LLMs 출력물의 ‘semantic’ entropy을 probabilistic tools을 사용합니다.
높은 엔트로피는 높은 불확실성을 나타내므로 ‘semantic’ entropy는 의미론적 불확실성을 추정하는 방법입니다.
자유롭게 텍스트를 생성할 수 있는 LLM에서 엔트로피를 측정하는 것은 어려운 문제입니다.
왜냐하면 같은 의미의 텍스트도 문법적으로나 어휘적으로 다르게 표현될 수 있기 때문입니다.
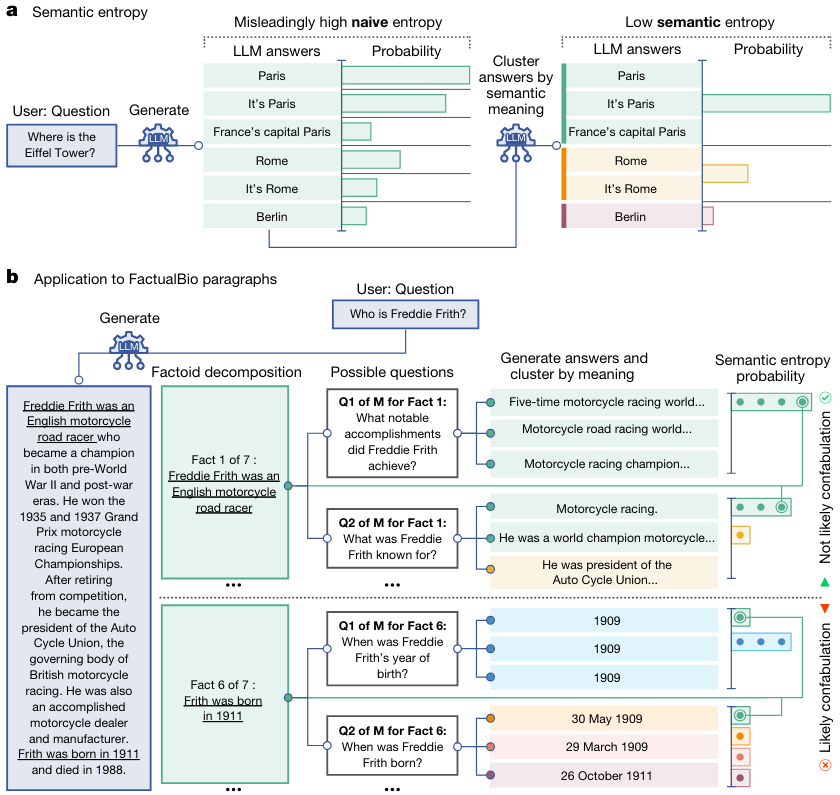
이러한 문제를 해결하기 위해 토큰 단위의 분포를 추정하는 대신 문장의 의문 분포의 엔트로피를 추정하는 방향을 제안합니다.
직관적으로 각 질문에 대해 여러 가능한 답변을 샘플링하고 의미가 유사한 답변으로 클러스터링을 진행합니다.
같은 클러스터 내의 변이 상호적으로 의미를 내포하는지 여부에 따라 결정됩니다.
‘semantic’ entropy는 이전의 도메인 지식없이도 다양한 언어 모델과 도메인에서 텍스트 생성을 혼동을 감지할 수 있습니다.
이전의 보지 못한 도메인서의 사용자 입력에 대한 반응은 학습이 필용한 다른 방법보다 견고한 메트릭입니다.
지도학습 기반으로 혼동을 학습하는 모델은 다른 출력이 학습된 데이터와 비슷한 패턴을 유지한다고 가정하지만, 새로운 상황이나 인간이 판단할 수 없는 혼동 상황에서는 종종 맞지 않습니다.
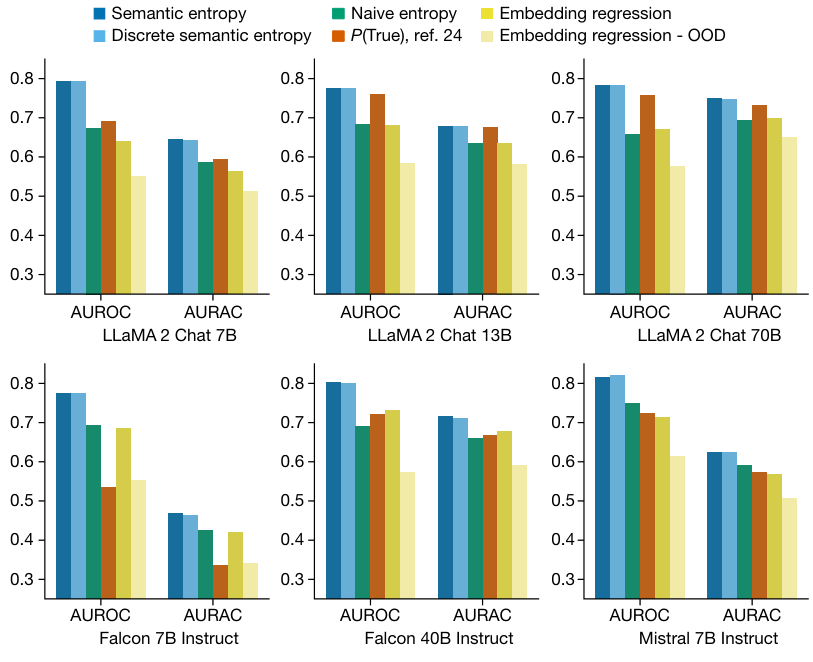
지도학습의 기준선으로 최종 임베딩을 기반으로 모델이 질문에 올바르게 답했는지 예측하도록 로지스틱 회귀 분류기를 훈련시킨 모델과 비교를 합니다.
주 답변과 '브레인스토밍'된 대안을 비교하는 몇 가지 샷으로 다음 토큰이 '참'이라고 예측하는 확률을 보는 P(True) 방법도 사용하여 비교합니다.
주어진 답변이 잘못되었다는 AUROC 영역입니다.
정밀도와 재현율을 모두 포함하며 0에서 1까지 범위로, 1은 완벽한 분류기, 0.5는 정보가 없는 분류기를 나타냅니다.
우리는 또한 '거부 정확도' 곡선(AURAC) 아래 영역이라는 새로운 측정치입니다.
혼동 감지 점수가 혼동을 일으킬 가능성이 가장 높은 질문에 답변을 거부하는 데 사용되는 경우를 판단합니다.
AURAC는 의미론적 엔트로피를 사용하여 가장 높은 엔트로피를 일으키는 질문을 걸러낼 때 사용자가 더 높은 정확도 향상을 파악할 수 있습니다.
두 가지 지표 모두 위의 이미지에서 볼 수 있듯이 제안한 방식이 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
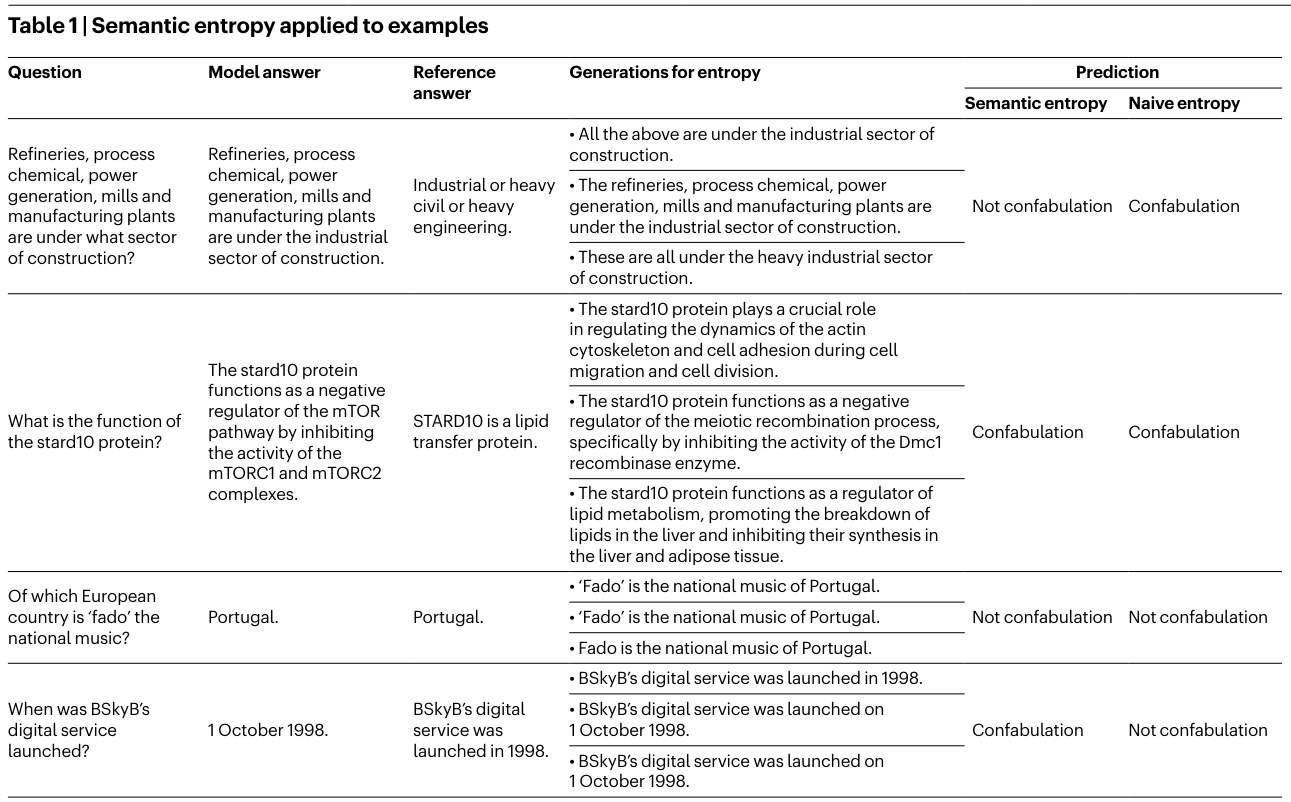
표 1
- 첫 번째 행은 naive entropy가 잘못 예측하는 경우도 semantic entropy가 혼동을 정확하게 예측할 수 있음을 보여주는 표입니다.
- 두 번째 행은 둘 다 정확하게 혼동을 예측하는 예제입니다.
- 이는 생성 경과가 어휘적으로 다를 뿐만 아니라 의미도 다르기 때문입니다.
- 세 번째 행은 모두 혼동 없음을 예측하는 예제입니다.
- 이는 생성물이 거의 어휘적으로 동일하기 때문입니다.
- 네 번째 행은 semantic entropy가 잘못 예측하고 naive entropy가 예측에 성공한 경우입니다.
- 이는 semantic entropy의 클러스팅에서 맥락의 중요성을 확인할 수 있습니다.
결론
모델의 환각, 혼동을 감지하는 것은 중요한 문제이며 이를 해결하는 것은 LLM 발전에 중요한 문제입니다.
semantic entropy를 이용하여 혼동을 감지하는 것은 다른 도메인 지식이 필요 없어 다양한 분야에 적용될 수 있습니다.
오류 감지에서는 LLM이 모르는 것을 아는 능력이 semantic entropy 이용하는 것이 연구를 통해 더 낫다는 것을 확인했습니다.
다만 LLM이 자신이 모르는 것을 알고 있다는 것을 모를 뿐입니다.
