느낀점
- 언러닝을 이용해서 필요한 부분을 삭제하고자 하는 수요는 굉장히 많음
- 원하는 정보만 삭제하면서 모델의 성능을 유지하는 것은 아직 어려워 보임
- 다양한 시나리오를 적용하고 있지만 프라이버시 데이터 한계상 합성 데이터를 이용할 수 밖에 없음
- MU 이후 모델의 바뀐 정렬이 어떤 효과를 불러올지 알 수 없음
Abstract

Machine Unlearning(MU)은 멀티모달 언어 모델에서 특정 개인 정보나 위험 정보를 제거하여 프라이버시와 보안을 강화하는데 매우 중요합니다.
MU는 텍스트 및 시각적 모달리티에서 상당한 진전을 이우었지만 Multimodal Unlearning(MMU)은 미개척 분야로 남아있습니다.
이를 해결하기 위해 MMU 평가를 위한 새로운 벤치마크인 CLEAR를 소개합니다.
CLEAR에는 200명의 가상의 인물과 관련된 질문-답변 쌍과 연결된 3,700개의 이미지가 포함되어 있어 다양한 모달리티에 걸쳐 포괄적인 평가를 가능하게 합니다.
우리는 10개의 MU 방법을 평가하여 MMU에 적합하도록 조정하고 새로운 과제들을 강조합니다.
Introduction
LLM에 학습에는 방대한 데이터를 사용하고 해당 데이터에는 개인 정보, 비윤리적 정보, 블필요한 정보가 포함될 수 있습니다.
이러한 문제를 해결하기 위해 MU 방법이 개발되어 모델을 처음부터 학습시키지 않고도 불필요한 데이터를 제거할 수 있게 되었습니다.
현재 LLM에만 적합한 MU 기술이나 비전 모델에만 적용 되는 MU는 존재하지만 MLLM에서는 새로운 과제가 제기됩니다.
MMU를 평가하기 위한 벤치마크는 아직 존재하지 않습니다.
이러한 문제를 해결하기 위해 MMU를 위한 새로운 벤치마크 CLEAR를 제안하고 이는 잊혀질 권리 개념에 맞춘 개인 MU에 집중합니다.
일관된 이미지를 생성할 수 있는 전략을 이용하고 텍스트 언러닝 벤치마크인 TOFU의 작가 관련된 질문들과 연결시켰습니다.
제안된 데이터셋에는 200명의 가상의 작가, 3,770개의 비주얼 질문-답변 쌍, 4,000개의 텍스트 질문-답변 쌍이 포함되어 있어단일 및 멀티모달 언러닝 기법에 대한 포괄적인 평가가 가능합니다.
MU 및 MMU 방법을 평가하기 위한 벤치마크를 제안하고 최신 기법을 포함한 10가지 방법을 평가합니다.
전체 데이터셋을 사용해 모델을 미세 조정합니다
20명로 구성된 'Pocket Set'와 나머지 데이터로 구성된 'Retain Set'를 정의합니다.
언러닝 절차를 적용하여 포겟 세트에 해당하는 정보를 더 이상 "기억하지 않지만", 리테인 세트의 지식을 유지하는 새로운 모델을 생성합니다.
Unlearning 기법을 텍스트와 비전 모달리티에서 각각 평가한 후 멀티모달 언어-비전 모델(MLLM) 내에서 결합합니다.
언러닝 과정에서 LoRA 어댑터에 L1 정규화를 적용하면 성능이 크게 향상되며 retain set 정보의 망각을 방지하는 데 도움이 된다는 것을 보여줍니다.
총 3개의 기여를 제공합니다.
- 멀티모달 환경에서 언러닝을 평가하기 위한 새로운 벤치마크인 CLEAR를 제안합니다.
- 기존의 언러닝 방법들을 개별 도메인과 결합된 도메인에서 포괄적으로 평가합니다.
- LoRA 어댑터에 대한 L1 가중치 정규화가 언러닝 품질을 개선하는 데 크게 기여하며 망각을 효과적으로 방지한다는 것을 입증합니다.
Methodology
언러닝은 크게 두 가지 방식으로 표현할 수 있습니다.
엄격한 언러닝은 retain set만으로 훈련된 모델과 동일하게 동작하는 모델을 생성하는 것으로 forget seg의 지식이 전혀 남아 있지 않도록 보장하는 것입니다.
Inexact 언러닝의 목적은 forget set의 정보를 더 이상 포함하지 않는 모델을 생성하는 것이지만 forget set와 관련된 입력에 대해 모델이 어떻게 동작할지 보장할 수 없습니다.
원래 모델 f는 파라미터 θ를 가진 모델로, 훈련 데이터셋 𝐷에서 학습됩니다.
모델이 데이터셋의 일부인 "망각 집합" ()를 잊도록 만드는 것을 목표로 합니다.
남은 데이터셋 부분은 "보존 집합"이라고 하며 에서 모델의 성능을 유지하는 것을 목표로 합니다.
"홀드아웃 집합" 를 사용하여 모델이 망각 과정 이후 에서 기대하는 동작을 설정합니다.
홀드아웃 집합은 훈련에 사용되지 않았으며 을 보장합니다.
: 모델이 잊어야 할 샘플들을 포함하며 망각의 효과를 직접 측정하는 데 사용됩니다.
: 모델이 기억해야 하고 좋은 성능을 유지해야 하는 샘플들을 포함하여 모델의 보존된 지식을 나타냅니다.
: 모델이 훈련에서 본 적 없는 샘플들을 포함하며 훈련 과정에 포함되지 않은 데이터에 대한 모델의 동작을 참조하는 역할을 합니다.
를 업데이트 하여 망각된 모델 를 만드는 방식으로 수행됩니다.
학습의 목표는 망각된 모델 를 만들어 를 잘 잊으면서 데 대한 성능을 만큼 잘 유지하는 것입니다.
여기서 𝜆는 망각-보존 trade-off 하이퍼파라미터이고,
𝛼는 학습률이며,
𝐿은 손실 함수(예: 음의 로그 우도)입니다.
𝑥는 입력이며, 텍스트, 이미지, 또는 VLLM의 경우일 수 있습니다.
Clear
MU와 MMU 벤치마크는 책, 게임, 영화 등과 같은 외부 출처에서 얻을 수 있는 잘 알려진 정보를 망각 대상으로 삼지 않아야 합니다.
보존 및 망각에 대한 모델 성능의 보다 신뢰할 수 있는 평가를 위해 필수적인 요소입니다.
이에 따라, 프라이버시와 얼굴 이미지 개인 음성 추가와 같은 새로운 모달리티로 응용이 가능한 TOFU 데이터셋을 활용합니다.
Dataset Generation Process
TOFU 데이터셋의 200명의 저자에 대해 원래 데이터셋에 있는 정보를 바탕으로 이름, 나이, 인종을 추출했습니다.
StyleGAN2를 사용하여 2,000개의 얼굴을 생성했습니다.
생성된 얼굴들은 사전 훈련된 CNN을 사용하여 나이, 성별, 인종 점수를 부여받습니다.
각 저자에 대해 얼굴을 매칭한 후, Diffusion 모델을 사용하여 주어진 얼굴과 텍스트 프롬프트에 맞는 이미지를 생성했습니다.
Splits

평가를 위해 다음 네 가지 데이터 분할을 사용했습니다.
- 망각 집합 (Forget): Maini et al. (2024)의 방법론을 따라 전체 데이터셋 D의 1%, 5%, 10%에 해당하는 2, 10, 20명의 데이터를 망각 집합 로 구성했습니다.
모델은 이 데이터를 망각해야 합니다. - 보존 집합 (Retain): 나머지 데이터로 구성된 보존 집합에서는 모델의 성능을 계속 유지해야 합니다.
- Real Faces: 모델이 보존 데이터셋에 없는 얼굴 개념을 계속 기억하도록 MillionCelebs 데이터을 사용해 평가했습니다.
이 데이터셋은 유명인 얼굴-이름 쌍을 포함하며 사전 훈련 중 모델이 접했을 가능성이 높은 유명인을 포함하도록 설계했습니다. - Real World: 모델의 전체 시각적 능력을 평가하기 위해 Visual Question Answering (VQA) 샘플을 사용했습니다.
Evaluation Metrics
텍스트, 시각, 그리고 텍스트-시각 도메인에서 망각 성능을 종합적으로 평가하기 위해 다음과 같은 지표를 사용했습니다.
- ROUGE-L:
모델 예측과 정답 간의 ROUGE-L 점수를 계산해 모델이 기억하는 내용을 평가합니다.
하지만 이 점수는 항상 모델의 내적 지식을 대표하지 않기 때문에 추가 지표가 필요합니다. - 확률 점수 (Probability Score):
모델의 로그잇을 통해 내적 지식을 노출시킵니다. 입력 𝑥와 정답 𝑦에 대해 조건부 확률 p(y∣x)를 정의하며 정답의 확률을 계산합니다.
점수가 낮을수록 모델이 해당 내용을 생성할 때 덜 확신함을 의미합니다. - 진실 비율 (Truth Ratio):
예측이 정답과 얼마나 잘 일치하는지를 수치화합니다. 이 비율은 정답의 패러프레이즈된 버전과 여러 형식이 유사한 잘못된 답변의 평균 확률을 비교합니다. 높은 값은 망각 알고리즘의 효과성을 나타냅니다. - 망각 품질 (Forget Quality):
망각 품질을 측정하는 것이 어렵기 때문에 방식인 U-LIRA 점수를 사용해 측정합니다.
그러나 이 방식은 LLM에 대해 계산 비용이 높습니다.
이를 해결하기 위해 두 모델 (망각된 모델과 골드 모델)의 출력에 대해 Kolmogorov-Smirnov 테스트를 수행합니다.
높은 p-값은 효과적인 망각을 나타내며 낮은 p-값은 프라이버시 유출 가능성을 시사합니다.
Experiments
텍스트, 이미지, 텍스트-이미지에대한 망각 테스트를 진행합니다.
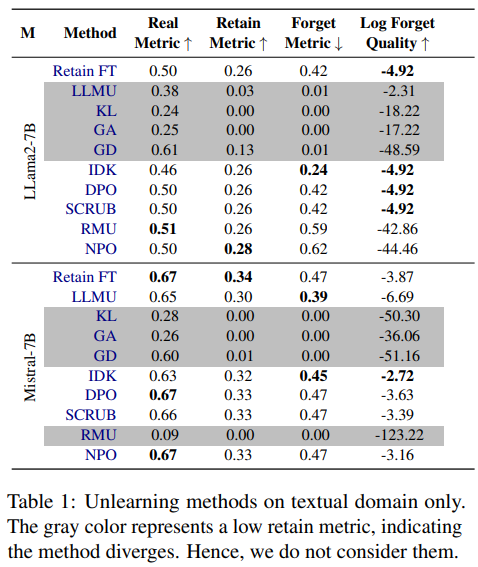
텍스트
RMU, KL, GD, GA 방법들은 망각 집합을 효과적으로 망각할 수 있습니다.
그러나 이들은 보존 데이터에서 심각한 망각 문제를 겪으며(보존 메트릭도 0으로 떨어짐) 전체 성능이 감소합니다.
나머지 방법들은 보존 집합에서의 성능을 유지하지만(보존 메트릭이 대체로 동일하게 유지됨) 망각 품질은 떨어집니다.
망각 메트릭이 Retain FT에서 달성된 수준과 비슷하게 나타나는 것이 특징입니다.
망각과 보존 사이의 균형을 맞추는 최적의 방법을 찾는 것은 어렵습니다.
이미지
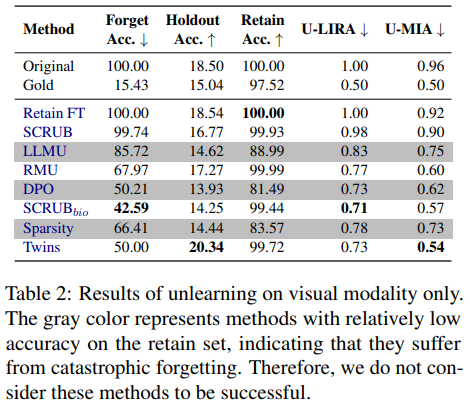
망각 집합에서 높은 정확도를 달성하고 U-LIRA와 U-MIA에서도 경쟁력 있는 점수를 확인했습니다.
멀티모달
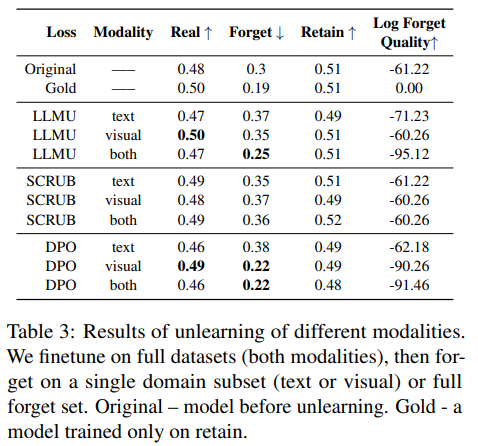
두 모달리티를 모두 망각하는 것이 텍스트만 망각하는 것보다 더 나은 결과를 가져온다는 것을 보여줍니다.
텍스트 도메인에서 망각 메트릭이 0.37에서 두 도메인을 모두 망각할 때 0.25로 감소하면서 보존 및 실제 메트릭은 안정적으로 유지됩니다.
Results
텍스트 및 시각적 요소를 포함한 멀티모달 환경에서 기계 망각을 평가하기 위한 첫 번째 오픈 소스 벤치마크인 CLEAR를 소개했습니다.
도메인 전반에 걸쳐 기존 망각 기법을 평가한 결과, 멀티모달 망각이 이전에 예상했던 것보다 더 어려운 과제임을 확인하였습니다.
Limitations
합성 데이터에 의존한다는 점
손실 함수를 사용하는 파인튜닝 기반 망각 기법을 평가하며 기계적 접근과 같은 더 광범위한 망각 기술을 탐구하지 않았다는 점
망각 방법의 확장성
