느낀점
- LLM 벤치마크 유출에 대한 문제를 제기하는 사람이 많은데 이점을 지키기 위한 점이 인상 깊음
- LLM 학습에 사용하는 데이터 저작권이 궁금함, 저작권을 모두 지키면 데이터를 수집했는지 의문
- LLM 배포 관련 저작권 허들이 높아 해당 모델을 이용하여 어떠한 2차 창작물을 생성하기 어려움
- LLM 보안 관련 방법이 적혀 있지 않아 보안 성능이 의심스럽고 실제 prompt injection에 얼마만큼 대응이 가능한지 궁금함
Abstract
EXAONE 3.5 instruction-tuned language models이 출시되었습니다.
해당 언어 모델은 32B, 7.8B, 2.4B의 세 가지 구성으로 제공됩니다.
1)실제 환경에서 지시사항을 잘 따르고, 7개의 벤치마크에서 최고 점수를 기록합니다.
2) 뛰어난 long context 이해 능력으로 4개의 벤치마크에서 최고 성능 달성합니다.
3) 유사한 크기의 최신 오픈 모델들과 비교하여 9개의 일반 벤치마크에서 경쟁력 있는 결과를 보입니다.
Introduction
EXAONE 3.0 instruction-tuned large language model(7.8B 파라미터)은 한국어와 영어에서 뛰어난 언어 능력과 실제 환경에서의 우수한 성능, 지시 사항 수행 능력을 보여주었습니다.
출시 이후 학계와 산업계에서 다양한 피드백을 받았습니다.
예를 들어, 연구자들은 낮은 사양의 GPU에서 훈련 및 배포할 수 있는 작은 모델의 필요성을 요청했습니다.
산업계에서는 온디바이스에서 배포 가능한 작은 모델과 성능이 향상된 더 큰 모델에 대한 수요가 있음을 알려주었습니다.
또한 RAG에 대한 수요가 늘어나면서 긴 문맥을 이해하고 작업을 수행할 수 있는 모델 수요도 증가했습니다.
다양한 사용자 요구를 충족하기 위해 EXAONE 3.5 언어 모델을 소개합니다.
EXAONE 3.5 언어 모델은 2.4B에서 32B 파라미터까지 다양한 크기로 제공됩니다.
- 작은 또는 자원이 제한된 장치에 배포하기 위해 최적화된 2.4B 모델
- 이전 모델과 동일한 크기를 가지면서 성능이 향상된 7.8B 모델
- 높은 성능의 32B 모델
모델들은 최대 32K 토큰까지 long context 처리 기능을 지원하여 높은 성능을 기록합니다.
Model Training
본 장에서는 모델 구성, pre-training and post-training method, 훈련 단계의 데이터셋 구축 과정에 대한 자세한 정보를 설명합니다.
Model Configurations
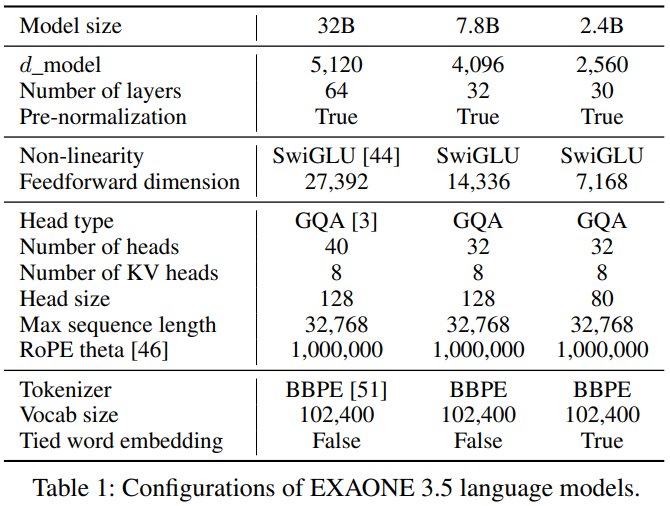
EXAONE 3.5은 Transformer 아키텍처를 기반으로 하며 자세한 구성은 표 1에 확인할 수 있습니다.
EXAONE 3.0 7.8B 모델과 구조가 동일하지만 size와 관련된 구성이 다릅니다.
특히, EXAONE 3.5 언어 모델은 long-context fine-tuning을 채택하여 EXAONE 3.0의 최대 문맥 길이를 4,096 토큰에서 32,768 토큰으로 확장한 것이 특징입니다.
Pre-training

데이터 구성과 모델 훈련 방법은 두 단계로 이루어집니다
1) 다양한 출처에서 수집하고 처리된 대규모 훈련 코퍼스를 기반으로 사전 훈련을 수행하여 일반 도메인에서 성능을 높입니다.
2) 평가를 통해 강화를 필요로 하는 도메인의 데이터를 추가로 수집하여 두 번째 단계 사전 훈련을 진행합니다. 예를 들어, 두 번째 단계에서는 긴 문맥 이해 능력을 향상시키는 데 중점을 둡니다.
Context Length Extension
컨텍스트 길이를 확장하기 위해long-context fine-tuning 기법을 활용합니다.
첫 번째 사전 훈련 단계에서 학습한 내용을 모델이 잊어버리는 catastrophic forgetting 문제 를 줄이기 위해 리플레이 기반 방법을 적용합니다.
두 번째 단계 사전 훈련 동안 첫 번째 단계에서 사용한 데이터 일부를 재사용하는 방식으로 잊어버리는 문제를 완화합니다.
첫 번째 단계에서는 최대 컨텍스트 길이를 초과하는 문서를 더 작은 청크로 나누어 처리했지만, 두 번째 단계에서는 원본 코퍼스를 청크로 나누지 않고 학습시켜 모델의 컨텍스트 길이를 확장합니다.
Decontamination
광범위한 웹 크롤링의 특성상 테스트 세트의 예제가 훈련에 포함되는 일이 발생합니다.
이러한 데이터는 일반화 성능을 저하시킬 가능성이 높고 테스트 메트릭을 혼란스럽게 만들어 사용자에게 공정하지 못한 평가를 제시합니다.
EXAONE 3.5 언어 모델의 일반화 성능을 방해하지 않도록 모든 타겟 벤치마크 테스트 데이터에 대해 엄격한 디컨타미네이션 과정을 적용하고 오염된 예제를 훈련 파이프라인에서 제거합니다.
우리는 substring 매칭 기법을 더욱 엄격한 기준으로 활용합니다.
먼저 모든 테스트 세트에서 알파벳과 숫자를 제외한 모든 문자를 제거하여 정규화한 후 슬라이딩 윈도우 크기 S=50과 스트라이드 1로 모든 고유 서브스트링을 추출합니다.
훈련 예제가 오염되었는지 판단하기 위해 정규화된 훈련 예제에서 랜덤하게 N=10개의 서브스트링을 샘플링하고 이들이 서브스트링 풀에 존재하는지 확인합니다.
Training Cost
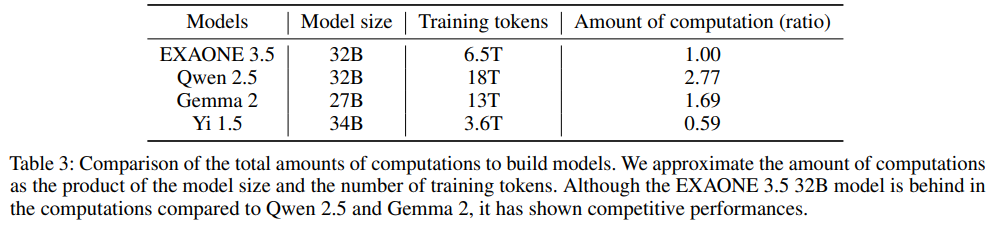
표 3은 EXAONE 3.5 32B와 유사한 크기의 다른 모델 간 사전 훈련에 필요한 전체 계산량을 비교합니다.
모델 크기와 훈련 토큰 수의 곱으로 전체 계산량을 단순히 추정했을 때 Qwen 2.5 32B는 EXAONE 3.5 32B보다 2.77배 더 많은 계산량을 요구합니다.
EXAONE 3.5은 낮은 비용으로 훈련 비용이지만 높은 성능을 보여주는 것을 확인할 수 있습니다.
Post-training
Pre-training 이후 지시를 따르는 능력을 강화하고 인간 선호도에 맞추기 위한 추가적인 과정을 거칩니다.
Supervised Fine-tuning
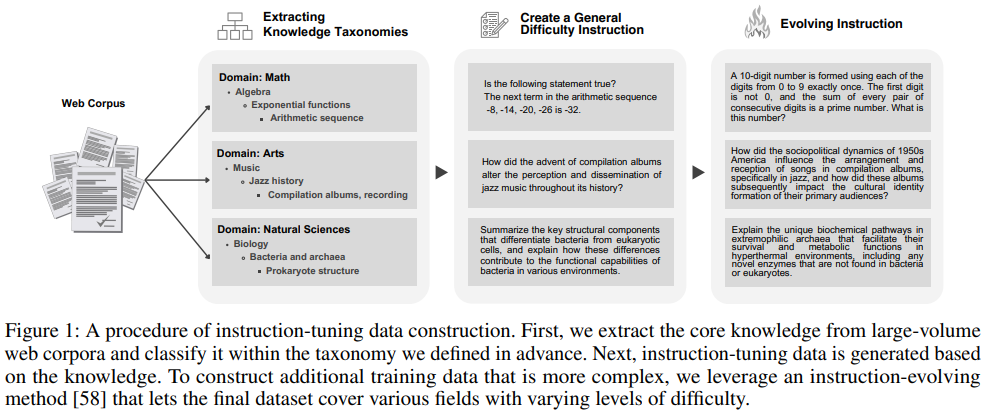
새로운 지시나 이전에 보지 못한 지시를 잘 수행하기 위해 모델은 서로 다른 도메인에서 다양한 난이도를 가진 지시-응답 데이터셋으로 훈련되어야 합니다.
다양한 분야를 아우르는 훈련 데이터를 구축하기 위해 그림 1에 나타난 바와 같이 분류 체계를 사용하여 8M 웹 코퍼스에서 핵심 지식을 추출합니다.
추출된 데이터를 기반으로 지시 튜닝 데이터셋을 생성합니다.
마지막으로 지시 진화 기법을 활용하여 복잡성과 난이도가 다양한 지시를 생성할 수 있도록 난이도 수준을 다변화합니다.
Preference Optimization
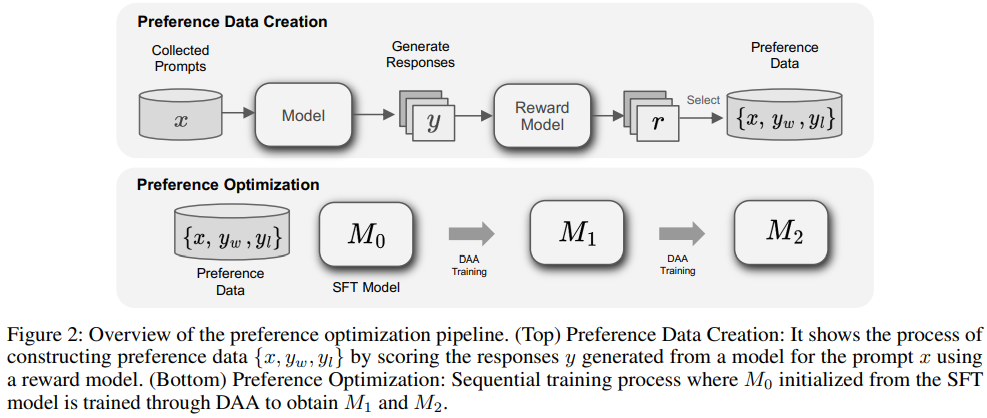
DPO와 SimPO와 같은 Direct Alignment Algorithms(DAAs)은 Supervised Fine-tuning 후 모델을 인간의 선호도에 맞추기 위해 사용됩니다.
훈련에 사용할 선호도 데이터는 합성 데이터와 사전 수집된 데이터를 통해 생성됩니다.
응답 생성 과정에서는 선호도 데이터에서 도출된 프롬프트 x에 대해 여러 모델에서 N개의 응답을 샘플링한 후 보상 모델의 점수를 기준으로 가장 좋은 응답 yw와 가장 나쁜 응답 yl을 선택하여 선호도 데이터 {x, yw, yl}를 생성합니다.
선호도 데이터를 검증하기 위해 추가적인 보상 모델을 사용하여 두 보상 모델의 순위에 기반한 일치도를 계산하고 일치도가 기준치에 미치지 못하는 데이터를 필터링합니다.
우리의 선호도 최적화는 다단계로 구성되 있고 DAA를 통해 M1과 M2 모델을 순차적으로 훈련하는 방식으로 진행됩니다.
M0 모델은 SFT 모델에서 초기화됩니다.
다단계 파이프라인은 DAA 훈련 과정에서 발생할 수 있는 과도한 최적화(over-optimization) 문제를 완화할 수 있습니다.
