느낀점
- 이미지 워터마킹은 많이 들어봤지만 텍스트 워터마킹에 대한 새로운 접근
- 텍스트에 워터마킹을 어떤 식으로 넣든 퀄리티 저하는 막을 수 없을 거 같음
- 짧은 문장을 생성하거나 생성된 문장을 후처리하는 경우가 많아 실질적으로 효용이 있을지 의무
- 워터마킹이 된 텍스트를 통해 저작권을 주장할 수 있지만 결국 의심 수준으로 감지되는 수준
- 많은 나라 언어에서 모두 적용 가능한 방식인지 의문
Abstract
LLM 고품질의 텍스트를 생성할 수 있으며 이는 정보 생태계의 큰 영향을 미칠 수 있습니다.
워터마킹은 합성된 텍스트를 식별하고 악용을 제한하는 데 도움이 될 수 있지만, 품질, 감지 가능성 및 계산 효율성 요구 사항 만족시키기 어려워 텍스트에 워터마킹을 적용하기 어렵습니다.
본 논문에서는 텍스트 품질을 유지하고 높은 탐지 정확도를 제공하는 텍스트 워터마킹 방식인 SynthID-Text를 소개합니다.
SynthID-Text는 LLM 훈련 단계에 영향을 미치지 않고 오직 샘플링 단계에만 적용됩니다.
텍스트 워터마킹을 가능하게 하기 위해서 speculative sampling과 워터마킹을 통합하는 알고리즘을 개발했습니다.
여러 테스트 결과 SynthID-Text는 감지 가능성을 개선하며 표준 벤치마크 및 인간의 평가에서도 LLM 기능에 변화가 없음을 확인했습니다.
워터마킹의 실현 가능성을 보여주기 위해 약 2천만 개의 Gemini 응답에 대한 피드백을 평가하는 실시간 실험을 진행했고, 텍스트 품질의 유지가 확인했습니다.
우리는 SynthID-Text의 활용이 워터마킹의 발전과 LLM 시스템의 책임 있는 사용을 촉진할 것이라고 기대합니다.
Introduction
LLM은 언어 기반 다양한 작업의 도구로 널리 사용되고 있습니다.
LLM이 품질, 일관성, 전문성이 발전함에 따라 합성된 텍스트와 사람에 의해 작성되는 텍스트를 구분하기 어려워질 수 있습니다.
LLM의 광범위한 사용을 고려할 때 LLM이 생성된 결과를 탐지하는 것은 매우 중요합니다.
생성된 텍스트를 탐지하기 위한 여러 전략들이 등장했습니다.
예를 들어, 생성된 텍스트 기록을 저장하고 저장된 텍스트와 대조하여 일치하는 텍스트를 찾아냐는 검색 기반 접근입니다.
하지만 모든 LLM의 생성 결과를 저장하고 액세스해야 하므로 개인 정보 문제와 밀접하게 연관되어 있습니다.
또 다른 방법은 통계적 특성 및 분류기를 사용하여 사람의 글과 인공지능이 생성한 텍스트를 탐지하는 방법입니다.
해당 방법 역시 계산 비용이 많이 들고 성능이 일관되지 않아 실사용에 제한이 있습니다. 다른 도메인 외 데이터에서 성능이 낮고 특정 그룹에서는 더 높은 False rate를 보입니다.
마지막 방법은 워터마크 기반입니다.
텍스트 워터마킹은 생성된 텍스트에 식별할 수 있는 텍스트를 추가하여 표시하는 방법입니다.
-
텍스트 워터마킹은 생성 과정에서 워터마킹을 추가하는 워터마킹
-
이미 생성된 텍스트를 수정하여 워터마크를 추가하는 워터마킹
- 생성된 텍스트를 수정하는 워터마킹은 동의어 치환이나 특수한 유니코드 문자를 삽입하는 등의 규칙 기반 변환을 사용합니다.
- LLM의 훈련 데이터를 변경하여 워터마크를 추가하는 워터마킹 등이 있습니다.
- 데이터 기반 워터마킹은 특정 트리거 문구에 대해 LLM을 훈련시키는 방식입니다. 데이터 기반 워터마킹은 모델이 특정 트리거 문구로 요청받을 때만 워터마크가 삽입됩니다.
2,3번 방법은 모두 텍스트에 눈에 띄는 인위적인 흔적을 남길 수 있습니다.
LLM에 워터마킹을 적용할 때는 텍스트 품질과 사용자 경험에 미치는 영향을 고려하는 것이 중요합니다.
또한 최소한의 계산 비용으로 워터마킹을 삽입할 수 있어야 합니다.
본 연구에서는 워터마크를 삽입하면서 품질에 미치는 영향을 적게하며, 낮은 계산 비용을 유지할 수 있도록 했습니다.
Watermarking with SynthID-Text
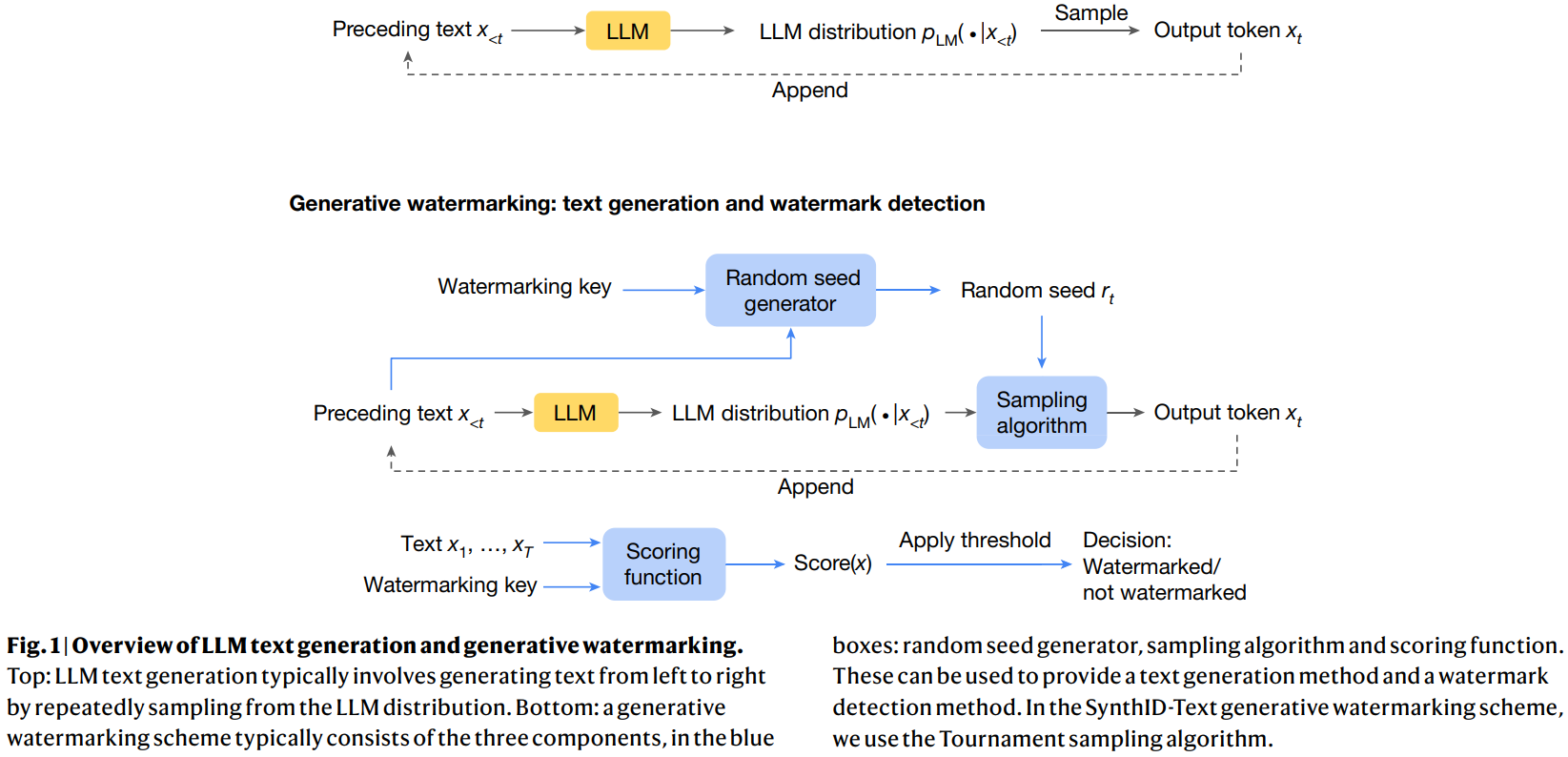
LLMs는 이전의 텍스트를 바탕으로 다음 텍스트를 생성합니다.
더 정확히 말하면 길이가 t-1인 입력 텍스트 시퀀스 x<t = x1, …, xt−1을 주어진 경우 LLM은 x<t가 주어졌을 때 다음 토큰 xt의 확률 분포 pLM(⋅∣x<t)를 계산합니다.
전체 응답을 생성하기 위해 xt는 pLM(⋅∣x<t)에서 샘플링됩니다.
이 과정은 최대 길이에 도달하거나 종료 토큰이 생성될 때까지 반복됩니다.
이 과정은 그림 1 (상단)에서 설명됩니다.
생성된 워터마킹 기법은 일반적으로 세 가지 구성 요소로 이루어집니다.
Random seed generator, sampling algorithm. scoring function.
1. Random seed generator는 각 생성 단계 t에서 랜덤 시드 rt를 제공합니다.
2. Sampling algorithm은 rt를 사용하여 pLM(⋅∣x<t)에서 다음 토큰 xt를 샘플링합니다. 중요한 점은 Sampling algorithm이 rt와 xt 사이에 상관관계를 도입한다는 것입니다.
3. Scoring function: 워터마크 검출 시 이러한 상관관계를 스코어링 함수로 측정합니다.
텍스트와 워터마킹 키가 주어졌을 때, 스코어링 함수는 상관관계를 나타내는 점수를 제공합니다.
이 점수는 임계값과 비교하여 텍스트가 워터마킹된 LLM에서 생성된 것인지를 결정하는 데 사용됩니다.
본 연구에서는 샘플링 알고리즘으로 Tournament sampling을 제시합니다.
Random seed generator는 기존의 슬라이딩 윈도우 방법을 사용합니다.
이 방법에서는 랜덤 시드가 가장 최근 H개의 토큰(xt−H, …, xt−1)의 해시값과 워터마킹 키를 결합하여 생성됩니다.
SynthID-Text’s Tournament sampling approach
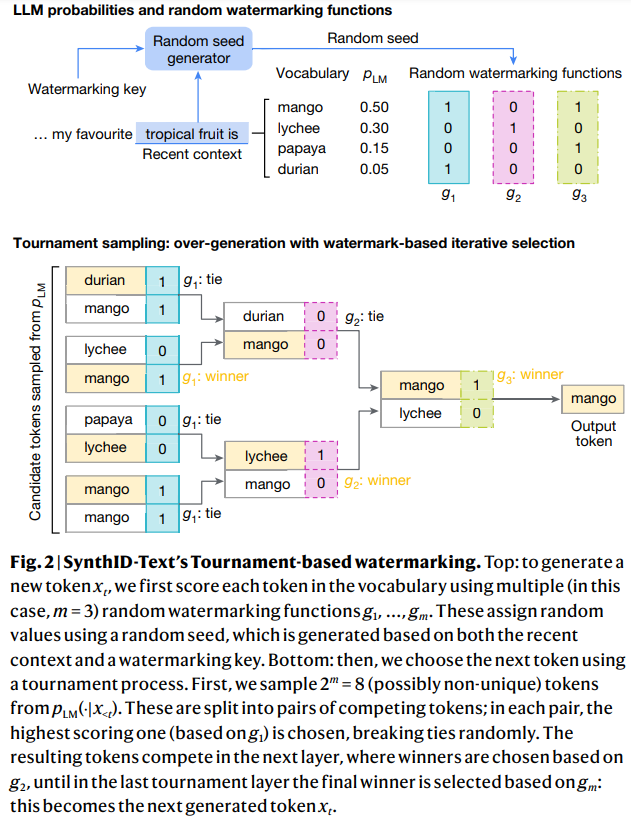
1단계
문맥이 주어졌을 때("my favourite tropical fruit is") 언어 모델(LLM)은 다음 어휘(Vocabulary)에 대해 확률 분포(𝑝𝐿𝑀)를 계산합니다.
mango: 0.50
lychee: 0.30
papaya: 0.15
durian: 0.05
2단계
랜덤 워터마킹 함수는 주어진 문맥과 워터마킹 키를 기반으로 각 단어에 대해 랜덤한 값을 할당하는 방식으로 작동합니다.
각 단어에 대해 , , 와 같은 세 개의 워터마킹 함수가 있을 때, 각 함수는 0 또는 1의 랜덤 값을 반환합니다. 예를 들어, 주어진 단어들에 대해 생성된 랜덤 워터마킹 값들은 다음과 같습니다.
mango:
, ,
lychee:
, ,
papaya:
, ,
durian:
, ,
3단계
토너먼트 과정:
후보 토큰은 두 개씩 쌍(pair)으로 묶여 경쟁합니다.
각 쌍에서 해당 레이어의 워터마킹 함수 () 값에 따라 높은 점수를 받은 토큰이 승자가 됩니다. 동점일 경우 랜덤으로 승자를 선택합니다.
1라운드 예시 ( 기준):
"durian"(1) vs. "mango"(1): "durian" 승리 (tie-breaking)
"lychee"(0) vs. "mango"(1): "mango" 승리
"papaya"(0) vs. "lychee"(0): "lychee" 승리 (tie-breaking)
"mango"(1) vs. "durian"(1): "mango" 승리 (tie-breaking)
2라운드 예시 ( 기준):
"durian"(0) vs. "mango"(0): "mango" 승리 (tie-breaking)
"lychee"(1) vs. "mango"(0): "lychee" 승리
최종 라운드 ( 기준):
"mango"(1) vs. "lychee"(0): "mango" 최종 승리
출력 토큰:
최종적으로 선택된 토큰 "mango"가 새로운 텍스트의 로 출력됩니다.
Watermark detection
토너먼트 샘플링은 랜덤 워터마킹 함수 g1(⋅, rt), ..., gm(⋅, rt) 하에서 높은 점수를 받을 가능성이 있는 LLM 분포에서 토큰을 선택합니다.
텍스트 x = x1, …, xT가 워터마킹되었는지 여부를 감지하기 위해 우리는 이 함수들에 대해 x가 얼마나 높은 점수를 받는지 측정합니다.
감지 성능에 영향을 미치는 두 가지 주요 요소가 있습니다.
첫 번째는 텍스트 x의 길이입니다.
더 긴 텍스트는 더 많은 워터마킹 증거를 포함하여 더 많은 통계적 확실성을 제공합니다.
두 번째는 LLM 분포에서 워터마킹된 텍스트 x가 생성될 때의 엔트로피 양입니다.
예를 들어, LLM 분포가 매우 낮은 엔트로피를 가진다면 즉 주어진 프롬프트에 대해 거의 항상 동일한 응답을 반환하게되고 토너먼트 샘플링은 g 함수 하에서 더 높은 점수를 받는 토큰을 선택할 수 없습니다.
토너먼트 샘플링은 LLM 분포에서 엔트로피가 많을 때 더 잘 수행되며 엔트로피가 적을 때는 효과가 줄어듭니다.
Preserving the quality of generative text
Weakest version의 Non-distortion 정의는 single token Non-distortion으로 워터마킹 샘플링 알고리즘에 의해 생성된 출력 토큰 와 평균적으로 같다는 것을 의미합니다.
Non-distortion의 Strongest version 정의는 하나 이상의 텍스트 시퀀스로 확장하여 평균적으로 워터마킹 기법이 특정 텍스트나 텍스트 시퀀스를 생성할 확률이 원래 LLM과 같도록 합니다.
토너먼트 샘플링이 대회에서 토너먼트마다 정확히 두 개의 '경쟁자'가 있을 때 토너먼트 샘플링이 single token Non-distortion임을 보여줍니다.
더 약한 수준의 Non-distortion은 텍스트 품질과 다양성을 감소시킬 수 있으며 더 강한 수준의 Non-distortion은 탐지 가능성을 줄이고 계산 복잡도를 증가시킬 수 있습니다.
우리의 실험에서는 SynthID-Text를 단일 시퀀스 Non-distortion으로 구성하여 텍스트 품질을 보존하고 탐지 가능성을 잘 유지하면서도 일부 응답 간 다양성을 줄였습니다.
이를 우리는 'Non-distortion SynthID-Text'라고 부릅니다.
강한 워터마크 탐지가 필요한 경우 SynthID-Text는 품질 손실을 감수하고 더 높은 탐지 가능성을 제공하는 왜곡적 구성을 취할 수 있습니다.
이 토너먼트 샘플링 구성에서는 각 경기에서 두 명 이상의 경쟁자가 있습니다.
우리는 이 경우 토너먼트 샘플링이 토큰 수준에서 distortion됨을 보여줍니다.
