느낀점
- 긴 문맥을 위한 데이터셋을 구하는 어려운 점을 ORPO 형태로 성능을 개선 시켰다.
- 짧은 문제에 대해서도 비슷한 효과로 성능이 증가할 거 같은데 실험하지 않은 이유가 궁금하다.
- 큰 70B 모델에 대해서도 비슷하게 성능 개선이 있는지 궁금하다.
Abstract
LLM의 발전은 긴 문맥을 처리하는데 진전을 이루었지만 여전히 긴 문맥을 완벽히 이해하는데 어려움을 겪고 있습니다
기존 접근법은 GPT-4와 같이 프론티어 모델의 출력을 활용한 합성데이터로 LLM을 미세 조정하는 방식으로 진행됩니다.
하지만 이러한 방식은 결과적으로 합성데이터의 한계를 가지게 됩니다.
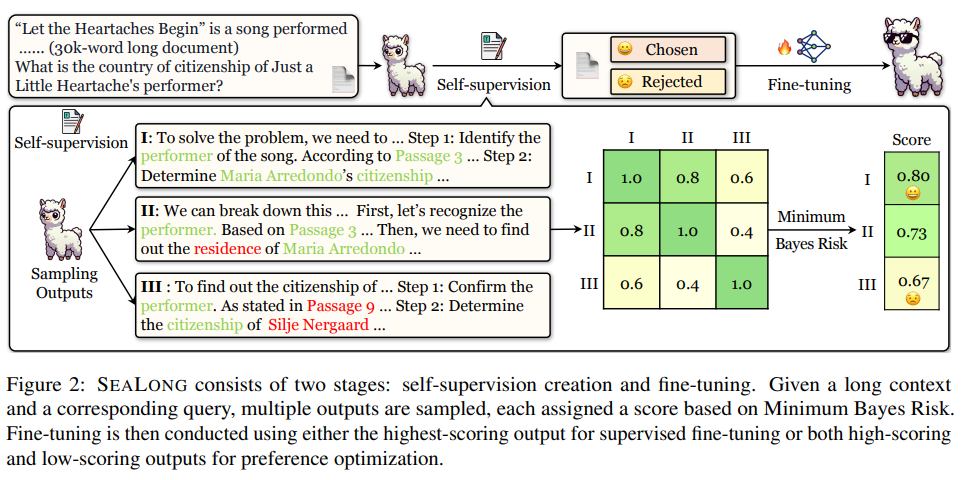
해당 문제를 해결하기 위해 긴 문맥 추론에서 스스로 개선점을 확인할 수 있도록 설계된 SEALONG을 제안합니다.
각 질문에 대해 여러 출력을 샘플링하고 Minimum Bayes Risk로 점수화한 뒤 해당 출력을 이용하여 fine-tuning 또는 preference optimization를 적용합니다.
여러 LLM을 활용하여 실험한 결과 성능 향상을 확인했습니다.
이러한 방식이 프론티어 모델을 활용한 합성데이터를 사용하는 것보다 더 뛰어난 성능을 발휘합니다.
Introduction
LLM이 긴 문맥에서 높은 품질의 대답을 출력하기 위해서는 긴 문맥에서 필수 세부 정보를 검색하고 추론 과정에서 분산된 정보를 통합할 수 있어야 합니다.
이러한 점을 테스트하기 위해 광범위한 텍스트에서 증거를 찾아내는 LIAH(건초에서 바늘찾기) 벤치마크에서는 거의 완벽한 정확도를 달성했지만, 여전히 응용 부분에서 긴 문맥을 잘 이해하지 못 하고 있습니다.
긴 문맥에 대한 성능을 개선하기 위해서 긴 문맥 데이터셋을 생성하는 것이 주요 과제로 떠오르고 있습니다.
크게 인간 주석과 프론티어 모델의 주석이 있습니다.
인간 주석의 경우 비용이 많이 드는 문제와 프론티어 모델 주석의 경우 고착화 되는 합성 데이터의 문제가 존재합니다.
LLM이 일반적인 긴 문맥 검색 및 추론에서 괜찮은 능력을 보인다는 증거를 바탕으로 LLM이 긴 문맥 추론에 대한 잠재력을 가지고 있다고 가정합니다.
선행 연구에서는 세밀한 프롬프트 전략이 기본적인 프롬프트 방법과 직접 요청하는 단순한 프롬프트보다 상당한 성능 개선이 있다는 것을 확인했습니다.
해당 선행 연구가 LLM이 충분한 잠재력을 가지고 있다는 것을 시사합니다.
이러한 관찰을 바탕으로 SEALONG(Self-improving method for rEAsoning over LONG)을 제안합니다.
LLM에서 여러 추론 경로를 샘플링한 다음 MBR(Minimum Bayes Risk)을 기반으로 샘플링된 답을 점수화시킵니다.
다수와 일치하지 않는 추론 경로가 환각일 가능성이 더 높다는 점을 고려할 때 직관적으로 생각할 수 있는 방법입니다.
더 높은 점수를 받은 출력을 활용하여 supervised training을 진행하거나, 출력된 점수를 이용한 DPO를 수행할 수 있습니다.
SEALONG을 활용하여 다양한 LLM에 활용하고 긴 문맥 추론 과제에 대한 평가를 진행했습니다.
결과적으로 LLM이 긴 문맥 추론에서 스스로 개선할 수 있음을 확인했습니다.
Understanding the Potential of LLMs in Long-context Reasoning
LongBench에서 제공하는 3가지 추론 중심 과제를 통해 LLM의 포텐셜을 실험적으로 탐구합니다.
HotpotQA, MuSiQue, 2WikiMQA
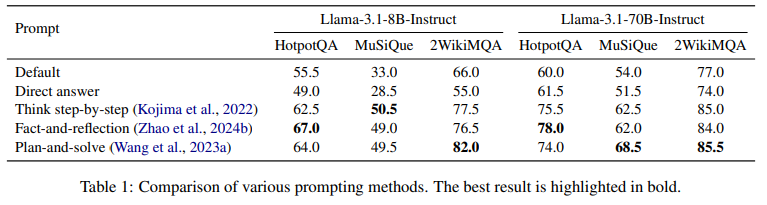
Prompting Strategies Matter (프롬프트 전략의 중요성)
긴 문맥 이해를 평가하는 벤치마크는 단순히 LLM에 긴 문맥을 기반으로 질의에 응답하도록 요청하여 평가를 합니다.
이러한 접근법은 복잡하고 깊은 추론이 필요한 질문에 대한 LLM의 잠재력을 과소평가할 수 있습니다.
이를 확인하기 위해 다양한 프롬프트 전략을 수행했습니다.
- Default (기본): 긴 문맥과 질문을 제공하여 LLM에 답변을 요청.
- Direct Answer (직접 답변): 긴 문맥을 기반으로 질문에 직접 답변하도록 요청.
- Think Step-by-step (단계별 사고): 문맥, 질문, 단계별 사고를 요청하는 지침을 제공.
- Fact-and-reflection (사실 및 반성): 긴 문맥, 질문, 먼저 관련 정보를 식별하고 이후 단계별로 추론하여 답변을 제공하도록 요청.
- Plan-and-solve (계획 후 해결): 긴 문맥, 질문, 문제 해결을 위한 계획을 세우고 이를 따라 단계별로 문제를 해결하도록 요청.
The Potential of LLMs for Correct Long-context Reasoning (LLM의 긴 문맥 추론 잠재력)
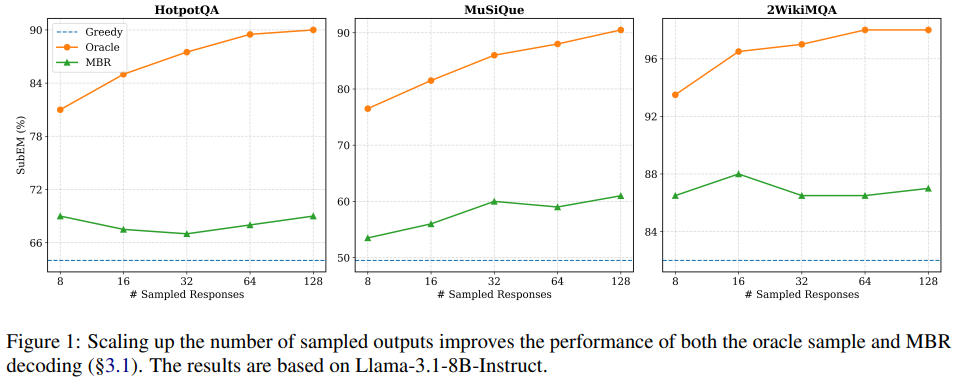
temperature sampling을 사용하여 각 질문당 여러 출력을 생성하고 SubEM으로 각각을 평가한 뒤 가장 높은 점수를 받은 출력을 oracle sample로 지정했습니다.
그림 1에서 확인할 수 있듯이 오라클 성능과 탐욕적 greedy search 성능 사이에는 8개의 출력만으로도 상당한 격차가 존재합니다.
즉 LLM이 정교한 프롬프트로 성능이 향상되었다는 것은 LLM이 충분한 포텐셜을 가지고 있다고 생각할 수 있습니다.
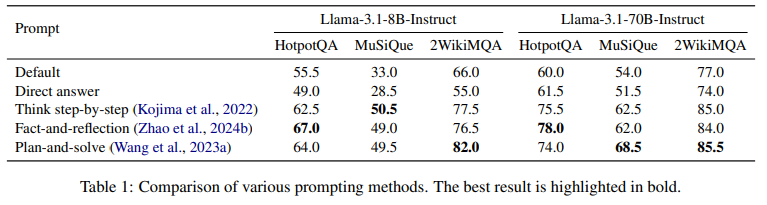
위의 테이블에서 볼 수 있듯이 라마 각각의 모델 모두 프롬프트의 디테일에 따라 성능이 달라지는 것을 확인할 수 있다.
SEALONG
LLM의 잠재력에 영감을 받아 SEALONG이라는 장기 맥락 추론을 위한 Self-improving 방법을 제안합니다.
self-supervision과 fine-tuning 두 단계를 포함합니다.
Self-supervision
plan-and-solve prompting을 활용하여 각 질문과 그에 해당하는 긴 컨텍스트에 대해 여러 개의 추론 경로를 샘플링하는 것에서 시작합니다.
근본적인 가정은 올바른 추론이 일반적으로 더 높은 의미적 일관성을 나타낸다는 점입니다.
유사한 단계를 따르고 긴 컨텍스트 내의 동일한 정보를 참조하는 경향이 있습니다.
즉 일관성이 낮은 출력물이 환각을 나타낼 가능성이 더 높고 잘못된 추론을 의미합니다.
위의 아이디어를 Minimum Bayes Risk(MBR)로 정의합니다.
여기서 는 출력 에 할당된 점수입니다.
는 긴 컨텍스트, 질문, 지시 사항을 포함하는 입력을
는 LLM의 정책 분포(policy distribution)
는 를 y^에 기반하여 평가하는 metric으로 나타냅니다.
위의 metric은 두 출력 간의 일관성을 측정합니다.
문장 임베딩 유사도(sentence embedding similarity)를 metric에 사용합니다.
우리는 가벼운 RoBERTa 기반 모델(Liu, 2019)을 사용하여 출력물을 임베딩하고 내적(inner product)을 통해 유사성을 측정합니다.
각 출력물 에 점수 를 할당할 수 있으며 가장 높은 점수를 가진 출력을 선택하는 것을 MBR 디코딩이라고 정의 합니다.
MBR 디코딩은 greedy search을 크게 능가하는 것을 확인했습니다.
이는 LLM이 인간이나 프론티어 모델이 없어도 스스로 개선할 수 있는 잠재력을 확인할 수 있습니다.
Fine-tuning
self-provided supervision을 활용하여 supervised fine-tuning을 수행하거나 preference optimization을 적용할 수 있습니다.
Supervised Fine-tuning, SFT
여기서 는 MBR 디코딩 출력을 나타냅니다.
는 주어진 입력 와 이전 출력 조건에서 가 생성될 확률을 의미합니다.
Preference Optimization
ORPO는 선호되는 출력물 와 덜 선호되는 출력물 간의 음의 로그 승산 비율(odds ratio)을 최소화하는 승산 비율 손실(odds ratio loss)을 도입합니다:
여기서 는 시그모이드 함수(sigmoid function)를 나타냅니다.
는 가 생성될 가능성과 생성되지 않을 가능성의 비율을 측정합니다:
최종 ORPO 목표 함수
ORPO에서 최종 목표는 SFT 손실과 OR 손실을 결합하며, 상대적 중요도를 조절하는 하이퍼파라미터 를 포함합니다
MBR 디코딩 출력물을 로 사용하며, 임의로 선택한 낮은 점수를 받은 출력물을 로 설정합니다.
방법은 높은 점수를 받은 출력물에 대한 선호를 학습하는 동시에 낮은 점수를 받은 출력물을 억제하여 모델 성능을 향상시킵니다.
Experiments
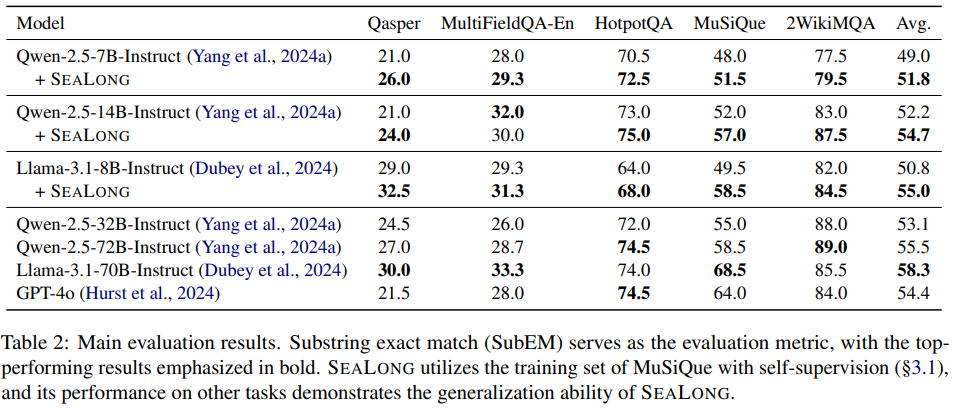
Qwen 7B, Qwen 14B, Llama 8B 모델에 SEALONG을 적용했을 때 모든 벤치마크에서 성능이 증가함을 확인할 수 있다.
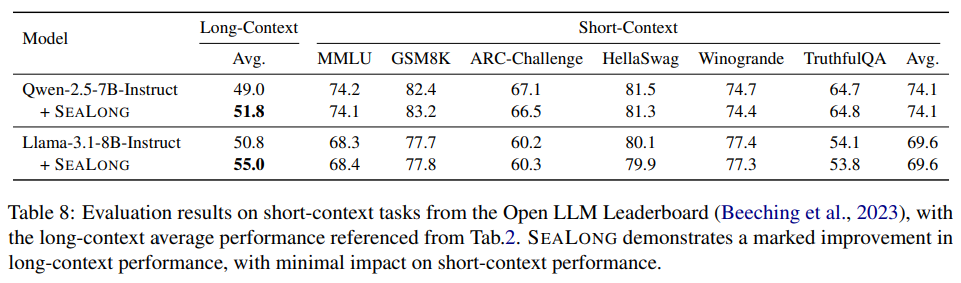
논문을 읽다가 궁금했던 일반화 성능에 감소 부분에 대한 결과이다.
전반적으로 비슷하거나 약간 감소된 부분이 있는데 아마 긴 문맥에 내용에 커스텀 되면서 발생하는 부분으로 파악된다.
