Abstract
Instruction tuning은 LLMs가 사용자의 지시를 효과적으로 따를 수 있도록 합니다.
이러한 Instruction tuning은 명령에 데이터셋 크기의 의존적인 경우가 존재합니다.
최근에는 LLM에 다양한 고품질 Instruction dataset을 합성하여 경제적인 문제를 해결하고자 합니다.
하지만 기존 접근법은 더 크거나 더 강력한 모델이 교사라고 판단하고 이러한 모델을 따라 가도록 설계됩니다.
본 논문에서는 일반적으로 채택된 이 가정을 반박합니다.
5개의 기본 모델과 20개의 교사 모델을 통한 광범위한 실험을 통해 더 크고 강력한 모델이 작은 모델의 좋은 교사가 되는 것은 아님을 밝혔습니다.
우리는 이를 Larger Models’ Paradox로 부르기로 했습니다.
또한 새로운 Compatibility-Adjusted Reward(CAR)이라는 새로운 지표를 만들어 생성기의 효과를 측정합니다.
5개의 기본 모델을 대상으로 한 실험에서는 CAR은 모든 기존 기준을 능가하는 성능을 보여줍니다.
Introduction
Instruction tuning은 LLM의 특정 작업 및 사용자의 의도에 맞게 튜닝하기 위해 사용되고 있습니다.
명령어와 대응하는 응답을 쌍으로 이루는 샘플로 구성된 명령어 데이터셋을 활용합니다.
명령어 튜닝의 성공 여부는 고품질 명령어 데이터셋의 가용성에 크게 의존합니다.
이러한 데이터셋을 구축하기 위해 명령어-응답 쌍을 생성하고 정제하는데 많은 노력이 필요합니다.
고비용 데이터셋 의존도를 줄이기 위해 LLM이 생성한 합성 데이터셋이 실질적인 해결책으로 떠오르고 있습니다.
일반적인 접근법은 벤치마크에서 높은 성능을 보이는 상위 모델을 Instruction tuning한 후 응답 생성기로 사용하는 것입니다.
예를 들어, Llama-3.2-3B-Instruct는 Llama-3.1-405B-Instruct가 생성한 응답을 사용하여 명령어 튜닝을 수행합니다.
하지만 이러한 과정에서 질문이 생깁니다.
더 크거나 강력한 모델을 교사 모델로 사용하는 것이 항상 더 나을까요?
본 논문에서는 합성 데이터셋 생성 중 응답을 생성하는 교사 모델이 명령어 튜닝된 LLM의 명령어 수행 성능에 미치는 영향을 조사합니다.
명령어 튜닝을 위해 가장 효과적인 응답 생성기는 무엇인가?
우리는 5개의 기본 모델을 대상으로 20개의 응답 생성기와 7개 모델 계열(Qwen2, Qwen2.5, Llama 3, Llama 3.1, Gemma 2, Phi-3, GPT-4)을 사용하여 광범위한 실험을 수행했습니다.
결과적으로 기존의 일반적인 가정을 반박하는 놀라운 결과를 발견했습니다.
Larger Models’ Paradox는 더 큰 응답 생성기(e.g., Llama-3.1-405B-Instruct)가 동일 계열의 더 작은 모델(e.g., Llama-3.1-70B-Instruct)보다 기본 모델의 명령어 수행 능력을 항상 더 잘 향상시키지는 않는다는 사실을 밝혔습니다.
추가적으로 Gemma-2-9b-it 및 Qwen2.5-72B-Instruct와 같은 오픈소스 모델이 응답 생성기로서 GPT-4를 능가하는 경우도 발견했습니다.
명령어 튜닝 없이 특정 기본 모델에 가장 효과적인 응답 생성기를 어떻게 결정할 수 있는가?
해당 질문이 중요한 이유는 다양한 응답 생성기에서 생성된 여러 데이터셋을 대상으로 명령어 튜닝을 수행하는 데 드는 상당한 계산 비용 때문입니다.
본 논문에서는 기본 모델과 응답 생성기 간의 호환성을 고려하지 못하기 때문에 더 Larger Models’ Paradox을 설명할 수 없다는 것을 밝혔습니다.
효과적인 응답 생성기를 찾는 작업을 위험-수익 문제로 치환했습니다.
호환성을 위험 요소로 활용한 Compatibility-Adjusted Reward(CAR)을 계산했습니다.
호환성은 튜닝 대상 기본 모델에서 응답의 평균 손실로 정량화되고 평균 손실이 높을수록 호환성이 낮아지고 위험이 높아진다는 것을 의미합니다.
Which Models are the most effective teachers for instruction tuning?
Preliminaries
Instruction Datasets.
명령어 데이터셋은 로 표현됩니다.
각 샘플 은 명령어 와 그에 상응하는 응답 로 구성됩니다.
본 논문에서는 응답 생성기 이 에서 데이터셋 로 fine-tuning된 모델의 명령어 수행 능력에 어떻게 영향을 미치는지 조사합니다.
Supervised Fine-Tuning (SFT).
SFT는 LLM의 명령어 수행 능력을 강화하기 위해 사용됩니다.
사전 학습된 언어 모델의 파라미터 를 업데이트하여 명령어 데이터셋 에 대해 NLL을 최소화합니다.
SFT 손실 함수는 다음과 같이 수식으로 표현됩니다:
Experimental Setup
Base Models.
다양한 크기의 서로 다른 5개 기본 LLM을 학생 모델로 사용합니다:
- Qwen2-1.5B
- Gemma-2-2b
- Llama3.2-3B
- Qwen2.5-3B
- Llama-3.1-Minitron-4B-Width-Base
Empirical Evaluation
다양한 응답 생성기가 생성한 데이터셋으로 fine-tuning된 모델의 명령어 수행 능력을 평가합니다.
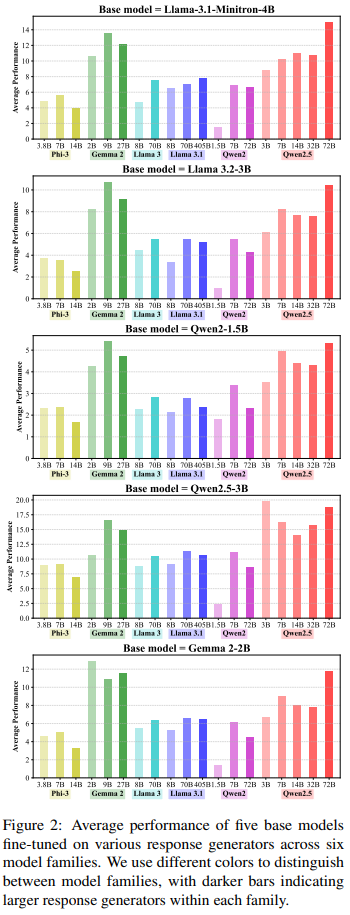
Finding 1: [Larger Models Paradox]
응답 생성기의 크기를 증가시키는 것이 기본 모델의 명령어 수행 능력을 반드시 향상시키는 것은 아닙니다.
- Gemma-2-9b-it은 더 큰 Gemma-2-27bit보다 거의 모든 기본 모델에 대해 SFT 성능이 더 우수했습니다.
- 유사한 경향은 다른 모델 쌍에서도 관찰되었습니다:
- Phi-3-Small > Phi-3-Medium
- Llama-3.1-70B-Instruct > Llama-3.1-405B-Instruct
- Qwen2-7B-Instruct > Qwen2-72B-Instruct
- Qwen2.5-7B-Instruct > Qwen2.5-32B-Instruct
설명: 응답 생성기와 기본 모델 간의 호환성에 의해 설명될 수 있습니다.
예를 들어, 대학생을 위해 작성된 고품질 교재(대규모 생성기 응답)는 초등학생(작은 모델)에게는 지나치게 어려울 수 있습니다.
Finding 2: [Family’s Help]
동일 모델 계열 내 응답 생성기를 학습하는 경우 더 높은 성능을 보입니다.
- Qwen2-1.5B, Qwen2.5-3B, Gemma-2-2B 기본 모델에서 intra-family 응답 생성기가 더 높은 AP를 기록했습니다.
- Self-Tuning: 기본 모델이 자신의 instruction-tuned 버전의 응답으로 fine-tuning되면 성능이 대폭 향상됩니다.
- Gemma-2-2B 모델은 Gemma-2-2b-it 응답으로 fine-tuning할 때 최고 성능을 기록했습니다.
이 두 가지 결과는 기본 모델과 응답 생성기 간의 호환성이 중요함을 강조합니다.
- Gemma-2-2B 모델은 Gemma-2-2b-it 응답으로 fine-tuning할 때 최고 성능을 기록했습니다.
Finding 3: [Open-Source > Close-Source]
오픈소스 LLM은 폐쇄형 LLM보다 우수한 응답 생성 성능을 보일 수 있습니다.
- 오픈소스 LLM이 GPT-4를 능가했습니다.
- 가설: GPT-4의 응답 길이가 오픈소스 LLM보다 짧아 평가자가 덜 선호했기 때문으로 보입니다.
비용 효율적인 오픈소스 LLM을 명령어 학습의 합성 데이터 생성에 사용할 가능성을 시사합니다.
- 가설: GPT-4의 응답 길이가 오픈소스 LLM보다 짧아 평가자가 덜 선호했기 때문으로 보입니다.
Finding 4: [Higher Temperature and Top-p]
높은 temperature와 top-p는 명령어 수행 능력을 향상시킬 수 있습니다.
높은 temperature와 top-p 값은 더 다양하고 맥락적으로 풍부한 출력을 생성하여 성능 향상을 이끌었습니다.
Finding 5: [Reject Sampling]
Reject sampling은 명령어 학습 성능을 약간 증가시킵니다.
- Gemma-2-9b-it 모델로 5개의 응답을 생성(temperature T = 0.8)하고, 평가 모델(ArmoRM-Llama3-8B-v0.1)을 사용해 최고/최저 점수 응답을 선택한 두 데이터셋(Best-of-N, Worst-of-N)을 비교합니다.
- 결과적으로 reject sampling은 기존 샘플링 기술 대비 성능을 약간 향상시켰습니다.