요즘 LLM를 평가하기 위해 많은 벤치마크가 등장했습니다.
예를 들어, ▲추론(ARC) ▲상식(HellaSwag) ▲언어이해력(MMLU) ▲환각방지능력(TruthfulQA) ▲수학적 추론(GSM8K) ▲상식 추론(WinoGrade) 등 허깅페이스 ‘H6’ 지표가 대표적이었다. 여기에 ▲코딩 능력을 판단하는 휴먼 이밸(HumanEval) ▲대화능력 지표 ‘MT-벤치(MT-bench)’ ▲감성평가 지표 ‘EQ-벤치’ ▲지시이행 능력 지표 ‘IF이밸(IFEval)’ 등이 LLM을 정량적으로 평가하기 위해 사용되었습니다.
LLM이 다양한 작업에서 활용되고 특정 테스크에 활용되는 전문적인 모델도 등장하면서 다양한 벤치마크가 필요해졌습니다.
하지만 여전히 공개된 데이터셋은 test set에 유출에 문제가 있으며 객관적인 평가가 어려운 문제가 존재합니다.
이러한 문제를 해결하기 위해 LiveBench는 매달 새로운 질문을 발표하고 최근에 공개된 데이터 세트, arXiv 논문, 뉴스 기사, IMDb 영화 줄거리를 기반으로 질문을 제공하여 잠재적인 오염을 제한하도록 설계되었습니다.
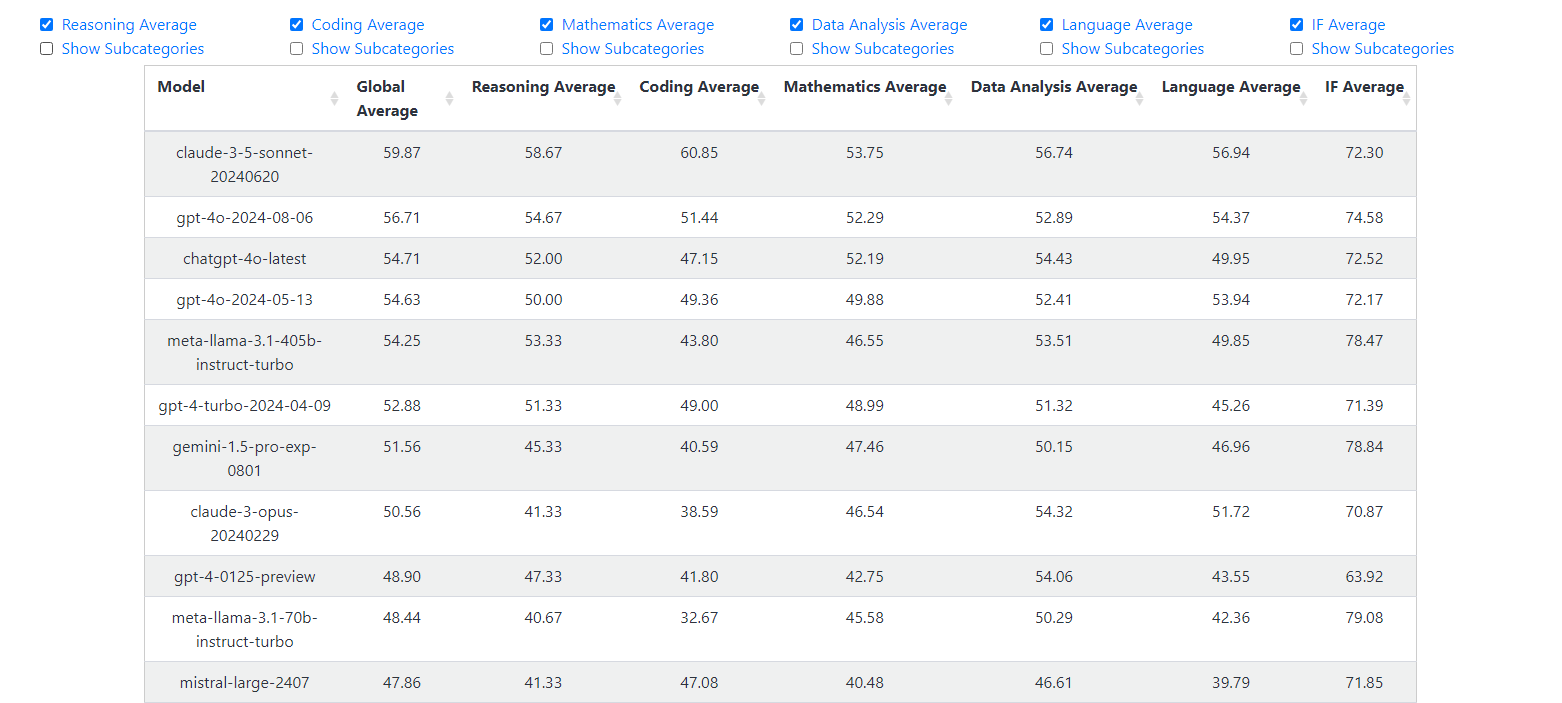
2024년 08월 16일 기준으로
다음 자세한 논문 리뷰를 통해 어떠한 장점이 있는지 확인해 보겠습니다.
Abstract
테스트 세트의 오염(=벤치마크의 테스트 데이터가 새로운 모델의 학습 세트에 포함되는 상황)은 LLM을 평가하는데 큰 장애물이 되고 있습니다.
이를 해결하기 위해 많은 벤치마크들은 인간 혹은 LLM을 심판으로 세워 평가를 진행하고 있습니다.
하지만 이 역시 상단한 편겨을 유발할 수 있으며 어려운 질문을 평가할 때는 그닥 좋은 방법이 될 수 없습니다.
본 연구에서는 테스트 세트 오염, LLM 판단, 인간 크라우드소싱의 문제점을 해결할 수 있도록 설계된 LLM 벤치마크 LiveBench를 소개합니다.
큰 특징은 3개입니다.
- 최신 정보를 이용하여 자주 업데이트되는 질문을 포함
- 객관적인 값에 따라 자동으로 답변 채점
- 수학, 코딩, 추론, 언어, 지시 사항 따르기, 데이터 분석 등 다양한 문제를 포함
LiveBench는 최근에 발표된 수학 대회, arXiv 논문, 뉴스 기사 및 데이터셋을 기반으로 한 질문들을 포함하며, Big-Bench Hard, AMPS, IFEval과 같은 이전 벤치마크에서 더 어려워진 오염되지 않은 버전의 과제를 포함합니다.
비공개, 공개된 많은 LLM 모델들을 평가했습니다.
LiveBench는 기본적으로 어려운 문제를 포함하고 있고 상위모델조차 65%의 정확도를 기록합니다. 모든 질문, 코드, 모델 답변을 공개하고 질문은 매월 추가 및 업데이트될 예정입니다.
Introduction
LLM의 급격한 발전으로 기존의 벤치마크로 LLM을 평가하는 것은 충분하지 않다는 것이 명확해지고 있습니다.
벤치마크는 일반적으로 인터넷에 공개되며 이를 이용하여 학습한 LLM은 성능이 매우 올라갈 수 있습니다.
최근에 확인할 수 있는 데스트세트의 오염 사례로는 LLM의 학습 이후 Codeforces에서 성능이 급락하는 일들과 마감일 이전의 GitHub에 해당 문제가 등장한 횟수와 성능이 높은 상관관계와 같은 일들입니다.
데이터셋의 오염을 줄이기 위해 인간이나 LLM을 이용하여 평가하는 벤치마크가 유행을 끌고 있습니다.
많은 단점이 있지만 LLM을 이용하여 평가를 진행하는 것은 실수와 ㄱ많은 편향을 가질 수 있다는 것입니다.
예를 들어, GPT-4-Turbo의 도전적인 추론 및 수학 문제에 대한 합격/불합격 판단은 최대 46%의 오류율 보입니다.
또한 자신보다 다른 LLM의 평가를 선호하거나, 장황한 답변을 선호하는 경우도 확인할 수 있습니다.
인간을 이용한 판단의 경우 출력물의 형식이나 글의 어조와 형식성 같은 편향이 주입될 수 있습니다
이러한 문제를 해결하기 위해 새로운 LLM 벤치마크 LiveBench를 소개합니다.
- LiveBench는 최신 정보를 기반으로 자주 업데이트되는 질문을 포함합니다
- LiveBench는 LLM을 평가자로 사용하지 않고 객관적인 값에 따라 자동으로 채점됩니다
- LiveBench 질문은 여섯 가지 다양한 범주에서 가져옵니다.
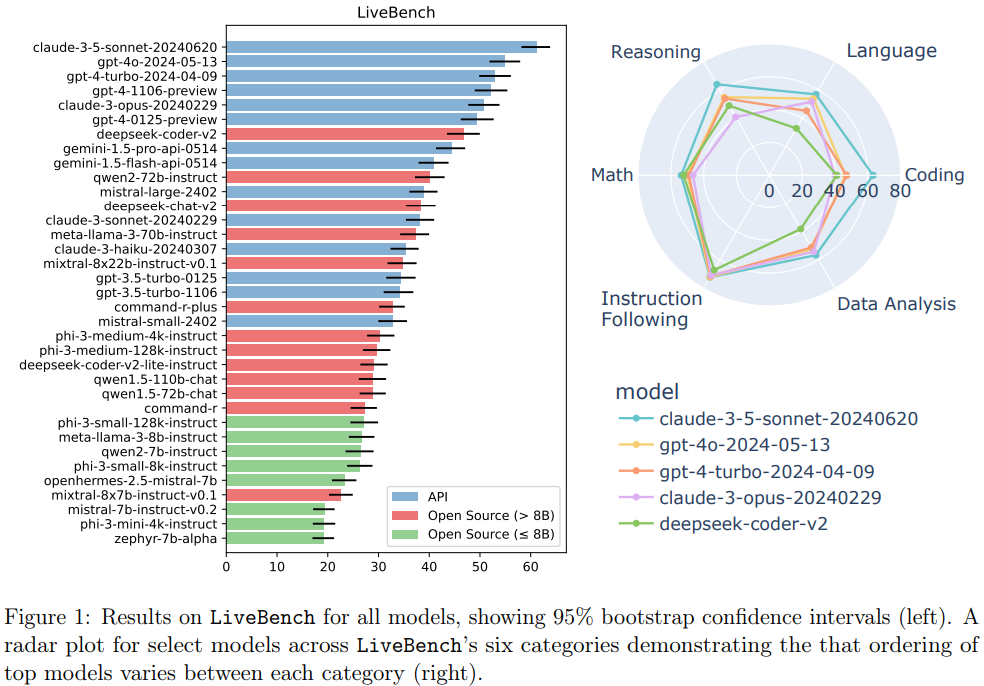
결과: 가장 높은 점수를 받은 모델은 claude-3-5-sonnet-20240620이며, 그 뒤를 gpt-4o-2024-05-13, gpt-4-turbo-2024-04-09 등이 따르고 있습니다. 전반적으로 API 기반 모델들이 상위권에 위치하고 있습니다.
LiveBench Description
LiveBench는 수학, 코딩, 추론, 데이터 분석, 지시 사항 따르기, 언어 이해의 여섯 가지 범주로 구성되어 있습니다.
각 범주는 2-3개의 과제로 구성되며 다양한 과제를 포함하고 있습니다.
총 50개의 질문으로 그성되어 있으면 쉬운 과제부터 어려운 과제까지 다양하게 구성되어 있습니다.
각 과제에 대해 3~70%의 성공률의 달성하는 것을 목표로 하고 있습니다.
모델이 정답을 모를 경우 최선의 추측을 할 수 있도록 요청하고 LLM이 최종 답볍을 쉽게 해석할 수 있는 double asterisk(**)로 표시된 형식으로 출력하도록 요청합니다.
Math Category
LLM의 수학 능력을 평가하는 것은 매우 중요한 부분ㄴ입니다.
총 3가지 유형의 수학 문제를 포함합니다.
- 최근 고등학교 수학 대회에서 출제된 문제
- 최근 증명 기반의 USAMO 및 IMO 문제에서 가져온 빈칸 채우기 문제
- 새롭고 더 어려운 AMPS 데이터셋 버전의 문제
Coding Category
LLM의 코딩 능력은 가장 널리 연구되고 요구되는 기술입니다.
2가지 코딩 과제를 포함합니다.
- LiveCodeBench(LCB)의 코드 생성 과제의 수정된 버전
- GitHub 소스에서 수집한 부분적인 솔루션을 결합한 새로운 코드 완성 과제
Reasoning Category
추론 능력 역시 매우 중요하고 요구되는 기술입니다.
2가지 추론 과제를 포함합니다.
- Big-Bench Hard의 어려운 버전
- Zebra 퍼즐

퍼즐에는 1번에서 3번까지 번호가 매겨진 세 명의 사람이 왼쪽에서 오른쪽으로 줄 서 있습니다. 각 사람은 음식, 국적, 취미라는 세 가지 속성을 가지고 있으며, 각 속성에 대한 가능한 값은 다음과 같습니다:
- 음식: 넥타린, 마늘, 오이
- 국적: 중국인, 일본인, 태국인
- 취미: 마술, 영화 제작, 퍼즐
이 세 가지 속성은 각각의 사람에게 하나씩 할당되어 있으며, 각 속성은 한 사람에게만 주어집니다.
주어진 조건
- 마늘을 좋아하는 사람은 맨 왼쪽에 있다.
- 태국인은 마술을 좋아하는 사람의 오른쪽에 있다.
- 중국인은 오이를 좋아하는 사람과 퍼즐을 좋아하는 사람 사이에 있다.
문제
"태국인의 취미는 무엇인가?"라는 질문에 답해야 합니다.
답변 형식은 X로, X는 태국인의 취미를 의미하는 단어입니다.
Data Analysis Category
LiveBench는 데이터 분석 또는 데이터 과학에서 LLM이 도움을 줄 수 있는 세 가지 실용적인 과제를 포함합니다
annotation, 테이블 조인 예측, 테이블 재포맷팅.
각 질문은 Kaggle 또는 Socrata에서 가져온 최신 데이터셋을 사용합니다.
Instruction Following Category
LLM의 중요한 능력 중 하나는 지시 사항을 따르는 능력입니다.
IFEval에서 영감을 받는 지시 사항 따르기 질문을 우리의 벤치마크에 포함했습니다.
"300자 이상의 글을 작성하라" 또는 "이 정확한 문구로 응답을 마무리하라: {end_phrase}"와 같은 확인 가능한 지시 사항을 포함합니다.
IFEval은 25개의 확인 가능한 지시 사항 목록을 사용했지만, 우리는 실제 사용 사례를 반영하지 않는 지시 사항을 제외한 16개의 하위 집합을 사용합니다.
Language Comprehension Category
마지막으로,여러 언어 이해 과제를 포함합니다.
이 과제들은 언어 자체에 대한 언어 모델의 추론 능력을 평가합니다.
- 단어 퍼즐을 완성하기
- 철자를 수정하되 다른 스타일적 변경은 남겨두기
- 알려지지 않은 영화의 뒤섞인 줄거리를 재배열하기 등의 작업이 포함됩니다.
Experiments
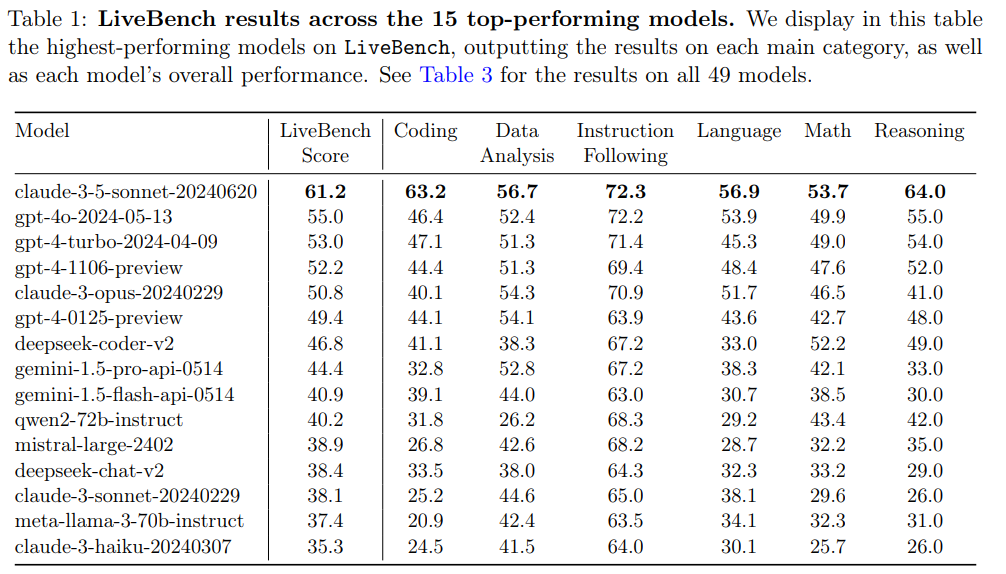
상위 15개의 모델입니다.
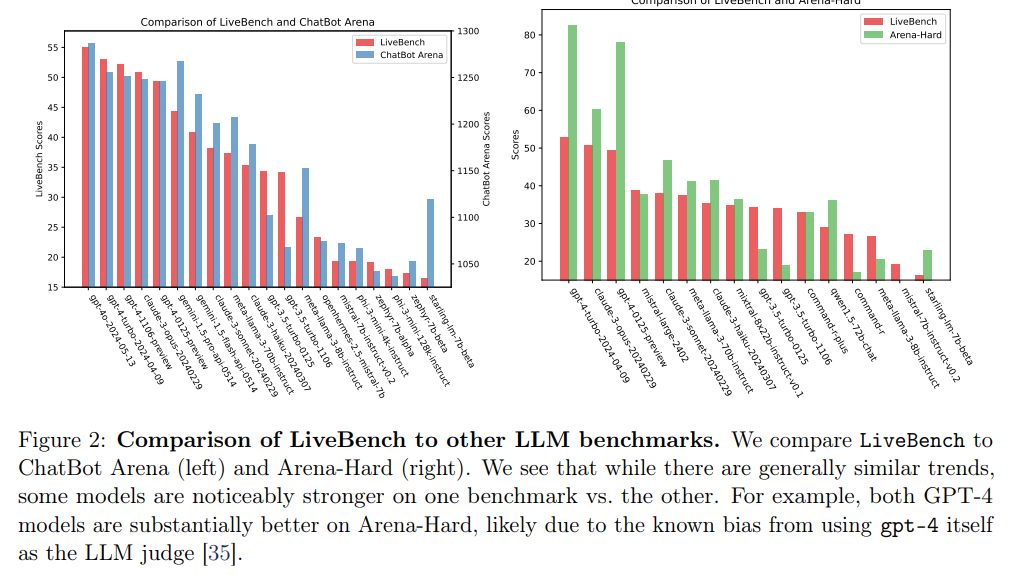
챗봇아레나와 비교했을 때 gpt-4의 성능이 좋은 것으로 확인되지만 LiveBench에서는 claude의 성능이 상대적으로 더 좋은 것으로 확인됩니다.
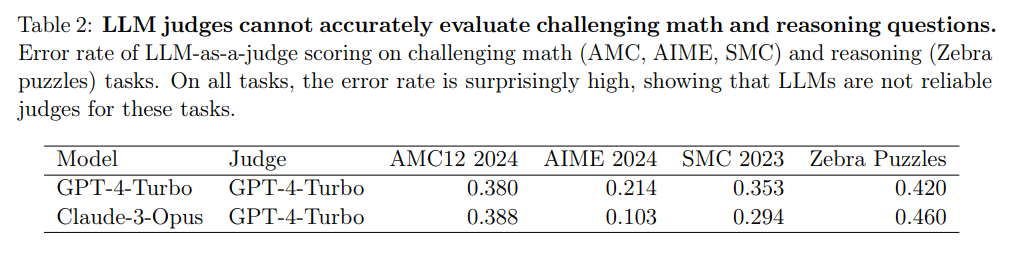
LLM이 정답을 평가하는 것은 매우 합리적이지 않습니다.
수학 및 추론 문제를 평가했을 때 두 모델(GPT, claude)는 40%의 오류율을 보였습니다.
Conclusions, Limitations, and Future Work
테스트 세트의 오염과 LLM, 인간 평가의 문제점을 완화하기 위해 새로운 행태의 벤치마크를 제안합니다.
모든 질문, 코드, 모델 답변을 공개했으며 질문은 매월 추가 및 업데이트될 예정입니다.
한계점
비영어권 언어 과제를 포함하지 않았습니다.
정확한 값이 있는 문제를 평가하였지만 '내 상사에게 이메일 작성하기' 또는 '하와이 여행 가이드 작성하기'와 같이 정답을 정의하기 어려운 특정 사용 사례에는 여전히 사용할 수 없습니다.
특정 LLM 계열이 특정 프롬프트 유형을 선호하는 등의 편향이 여전히 존재합니다.
