
요즘 GPT에 이미지를 첨부하여 사용하는 경우가 많아지고 있습니다.
예를 들어 음식 이미지를 첨부하여 칼로리를 물어본다거나, 종이에 대충 그린 웹페이지 스케치를 이용하여 프론트엔드 구축하기 등이 있습니다.
하지만, text-to-text와는 다르게 image-to-text는 아직까지 성능이 부족한 것을 실제 사용을 통해 알 수 있습니다.
이러한 문제를 해결하기 위해 명령어 조정을 통해 멀티모달 성능을 향상시킨 LLaVA 논문에 대해 알아보려고 합니다.
Abstract
LLM에 instruction-tuning은 새로운 작업에서 zero-shot 성능을 향상시킨다는 것은 입증되었지만 multimodal 분야에서는 덜 탐구되었습니다.
본 논문에서는 GPT-4를 사용하여 multimodal(언어-이미지) 명령어를 따르는 데이터를 생성하려는 첫 시도입니다.
생성된 데이터를 이용하여 instruction-tuning을 진행한 LLaVA(Large Language and Vision Assistant)도 소개합니다.
visual-encoder와 LLM을 연결하여 일반적인 시각 및 언어 이해를 위한 Large multimodal입니다.
Introduction
인간은 시간와 글과 같은 여러 정보를 통해 세상과 상호작용합니다.
각 정보들은 특정 개념을 이해하고 소통하는데 고유한 이점을 가지고 있어 세상을 더 잘 이해하는데 도움이 됩니다.
실제 환경에서 여러 정보와 명령어를 효과적으로 따르고 인간을 의도에 맞춰 작업을 진행할 수 있는 어시스트를 개발하는 것은 중요한 과제입니다.
이를 위해 언어로 보간된 시각모델을 개발하는데 관심이 높아지고 있으면 여러 모델들이 출시되었습니다.
하지만 이전 연구들은 언어 이미지를 설명하는데만 사용합니다.
언어가 시각적 신호를 언어적 의미로 매핑하는데 중요한 역할을 할 수 있게 하지만, 결과적으로는 사용자 지시에 대한 상호작용성과 적응력이 제한된 모델을 만들뿐입니다.
본 논문에서는 visual instruction tuning을 제안합니다.
언어-이미지 멀티모달 공간으로 instruction tuning을 확장하려는 첫 번째 시도이고 4개의 기여가 있습니다.
- 멀티모달 데이터셋: 이미지-텍스트 쌍의 적절한 instuction을 따르기 위해 데이터를 재구성하고, 이를 위해 GPT-4를 사용합니다.
- 대형 멀티모달 모델: Clip과 Vicuna를 연결하여 대형 멀티모달 모델을 구축합니다.
- 멀티모달 벤치마크: 다양한 이미지와 상세한 주석을 갖춘 2가지 벤치마크를 제시합니다(LLaVA-Bench)
- 오픈 소소: 우리는 모든 자료를 오픈 소스로 제공합니다.
GPT-assisted Visual Instruction Data Generation
여러 정보와 다양한 답변이 출력되는 것을 확인할 수 있습니다.
멀티 모달을 데이터 양이 급증하고 있지만, instruction이 포함된 경우는 이용 가능한 양이 제한적입니다.
멀티모달 데이터를 만드는 것은 비용이 많이 걸리고 클라우드 소실을 고려할 때 명확히 정의되지 않기 때문입니다.
이를 해결하기 위해 GPT-4 기반으로 멀티 모달 instuction 데이터를 수집하는 방법은 제안합니다.
이미지()와 그에 연관된 캡션()이 주어졌을 때 이미지의 내용을 설명하도록 지시하는 질문()을 생성하는 것은 꽤나 명확합니다.
GPT-4에게 이러한 질문 목록을 작성하도록 요청합니다.
인간:
어시스턴트:
하지만 이런 간단한 버전은 지시와 응답에서 모두 다양성과 심층적 추론이 불가능한 형태입니다.
이를 해결하기 위해, GPT-4나 ChatGPT를 강력한 교사로 활용하여(둘 다 텍스트만 입력으로 받음), 시각적 콘텐츠가 포함된 지시-추종 데이터를 생성합니다.
텍스트 전용 GPT에 이미지를 시각적 특징으로 인코딩하기 위해, 두 가지 유형의 기호적 표현을 사용합니다.
- 캡션은 시각적 장면을 다양한 관점에서 설명하는 데 사용됩니다
- 바운딩 박스는 보통 장면에서 객체의 위치를 지정하며, 각 박스는 객체 개념과 공간적 위치를 인코딩합니다.
기호적 표현은 LLM이 인식할 수 있는 시퀀스로 인코딩할 수 있게 합니다.
COCO 이미지를 사용하여 세 가지 유형의 지시-추종 데이터를 생성합니다.
- 대화: 우리는 어시스턴트와 이 사진에 대해 질문하는 사람 간의 대화를 설계합니다. 답변은 어시스턴트가 이미지를 보고 질문에 답하는 것처럼 작성됩니다. 다양한 질문이 이미지의 시각적 콘텐츠에 대해 묻습니다. 여기에는 객체 유형, 객체 수 세기, 객체의 행동, 객체 위치, 객체 간의 상대적 위치 등이 포함됩니다
- 상세한 설명: 이미지에 대한 풍부하고 종합적인 설명을 포함하기 위해, 이러한 의도로 질문 목록을 작성합니다.
- 복잡한 추론: 위의 두 유형은 시각적 콘텐츠 자체에 초점을 맞추고 있으며, 이를 기반으로 우리는 추가적으로 심층적인 추론 질문을 생성합니다.
158,000개의 고유한 언어-이미지 지시-추종 샘플을 수집했으며, 여기에는 대화 58,000개, 상세한 설명 23,000개, 복잡한 추론 77,000개가 각각 포함되어 있습니다.
ChatGPT와 GPT-4의 사용을 비교해 보았으며, GPT-4가 공간 추론과 같은 더 높은 품질의 지시-추종 데이터를 일관되게 제공한다는 것을 발견했습니다.
Visual Instruction Tuning
Architecture
입력 이미지 에 대해 사전 학습된 CLIP 시간 인코더 ViT-L/14를 이용하여 visual feature인 를 형성합니다.
이미지 feature를 단어 임베딩 공간에 연결하기 위해 간단한 선형 레이어를 사용합니다.
학습 가능한 행렬 를 적용하여 를 언어 임베딩 토큰 로 변환합니다.
해당 토크은 LLM의 단어 임베딩 공간과 동일한 차원을 가집니다:
Training
각 이미지 에 대해 멀티턴 대화 를 생성합니다.
T는 총 턴 수입니다.
모든 답변을 어시스턴트의 응답으로 취급하여 시퀀스를 구성하며, 번째 턴에서의 지시 는 다음과 같습니다.
해당 방식을 이용하여 multimodal instruction-following sequence의 통일된 형식이 유질 될 수 있습니다.
auto-regressive를 통해 LLM의 다음 예측 토큰에 대해 튜닝을 진행합니다.
길이가 인 시퀀스에 대해 목표 답변 의 확률은 다음과 같이 계산합니다:
는 훈련 가능한 매개 변수이고 는 각각 현재 예측 토큰 이전의 모든 턴에서의 지시와 답변 토큰을 나타냅니다.
Stage 1: Pre-training for Feature Alignment.
a balance between concept coverage and training efficiency를 위해서 CC3M을 595k 이미지-텍스트 쌍으로 필터링하여 사용합니다.
입력 를 구성하기 위해 이미지 에 대해 질문 를 무작위 샘플링합니다.
실제 예측 답변 는 원래 캡션입니다.
훈련에서는 시각 인코더와 LLM 가중치를 모두 고정하고, 학습 가능한 매개 변수 만으로 likelihood를 최대화합니다.
Stage 2: Fine-tuning End-to-End.
visual encdoer를 고정하고 LLaVA의 layer와 LLM의 사전 훈련된 가중치를 계속 업데이트합니다.
즉 훈련 가능한 매개변수는 입니다.
Experiment

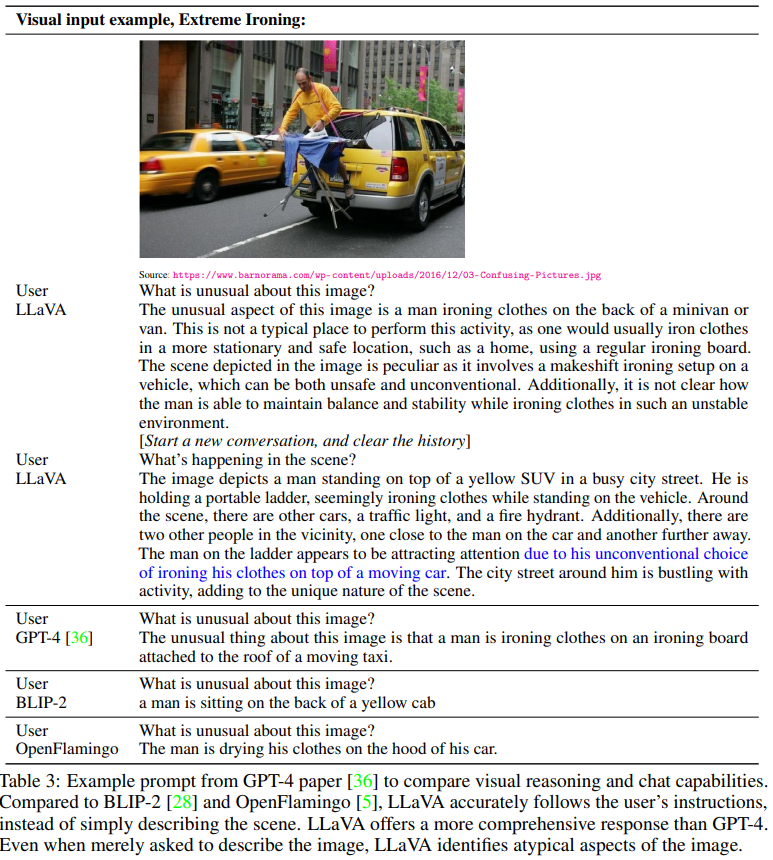
도심의 한 거리에서 노란색 SUV 또는 미니밴 위에 다리미질을 하고 있는 남자가 보입니다. 이 장면은 도로 한복판에서 비정상적이고 불안정한 상태로 다리미질을 하는 매우 비정상적인 상황을 묘사하고 있습니다.
첫 번째 질문: "이 이미지의 특이한 점은 무엇인가요?"
LLaVA: 이 이미지의 특이한 점은 남자가 미니밴 또는 SUV의 뒤에서 다리미질을 하고 있다는 것입니다. 일반적으로 다리미질은 집처럼 안정적이고 안전한 장소에서 하며, 차량 뒤에서 하는 것은 비정상적입니다. 이 장면은 안전하지 않고 일반적이지 않기 때문에 특이합니다.다.
GPT-4: 이 이미지에서 특이한 점은 남자가 이동 중인 택시의 지붕에 부착된 다리미판에서 다리미질을 하고 있다는 것입니다.
BLIP-2: 남자가 노란색 택시의 뒤쪽에 앉아 있습니다.
OpenFlamingo: 남자가 자신의 차 보닛에서 옷을 말리고 있습니다.
두 번째 질문: "장면에서 무슨 일이 일어나고 있나요?"
LLaVA: 이미지에서는 노란색 SUV 위에 서 있는 남자가 도로 한복판에서 다리미질을 하고 있는 모습이 보입니다.
이미지+Annotation+VLM
이 레스토랑의 이름은 무엇입니까?
답변: ICHIRAN.
이 사진을 자세히 설명해 주세요.
답변: 사진의 다양한 요소들을 포함하여 상세하게 설명해야 합니다.
블루베리 맛 요거트의 브랜드는 무엇입니까?
답변: Fage 블루베리 요거트.
이 사진에 대해 자세히 설명해 주세요.
답변: 냉장고 내부의 다양한 항목과 그 위치, 브랜드, 그리고 각각의 배치를 포함한 상세한 설명이 필요합니다.
Conclusion
visual instruction tuning의 효과를 입증했습니다.
언어-이미지-instuction-following 데이터를 생성하기 위한 자동화된 파이프라인을 제시했습니다.
ScienceQA 데이터셋에서 미세 조정했을 때 새로운 SoTA(최고 성능) 정확도를 달성했으며, 다중 모달 챗 데이터로 미세 조정했을 때 뛰어난 시각적 채팅 기능을 보여주었습니다.
언어-이미지-instuction-following bench를 제시했습니다.
