느낀점
- 모두 deepseek에 빠져있어 Qwen-1M 리뷰하게 된 홍대병
- LLM 학습시에 데이터를 밀어넣는 순서도 섬세하게 하는 점이 이상 깊고, 항상 랜덤으로 넣는 내 자신에게 부끄러움
- 인간이 만든 글은 긴 글 지시사항에 도움이 되지 않아 직접 합성하는 것이 인상 깊음
- 점점 긴 문맥을 받을 수 있는 모델들이 출현하여 RAG에서 CAG로 대체가 될 수 있을 거 같다는 생각
- 딥시크가 나와서 약간 묻힌 감이 있으나 역시 알리바바 Qwen도 ai에서 잘하고 있는 모습
Abstract

1M로 확장한 모델에게 Passkey를 검색하는 테스트를 진행한 결과.
7b를 제외한 모델 모두 정확하게 숨겨진 패스키를 잘 찾는 것을 확인할 수 있다.
Qwen2.5-1M을 소개합니다.
Context-length를 100만 토큰으로 확장하는 Qwen2.5의 후속 시리즈입니다.
이전의 128K 버전에 비해 Qwen2.5-1M 시리즈는 더 긴 context pre-training and post-training을 통해 long-context의 성능을 크게 향상시켰습니다.
long data synthesis, progressive pre-training, multi-stage supervised fine-tuning과 같은 기술들이 long-context 성능을 효과적으로 향상시키고 훈련 비용을 절감하는 데 사용되었습니다.
long-context 모델을 더 많은 사용자들이 사용할 수 있도록 추론 프레임워크를 공개하고 오픈 소스로 제공합니다.
해당 프레임워크에는 추가 훈련 없이 모델 컨텍스트 길이를 최소 네 배 이상 확장할 수 있는 length extrapolation 방법이 포함되어 있습니다.
추론 비용을 줄이기 위해 chunked prefill optimization와 함께 sparse attention 방법을 제안하고 정확도를 개선하기 위한 sparsity refinement 방법을 도입했습니다
추론에서의 최적화 작업에는 kernel optimization, pipeline parallelism, scheduling optimization가 포함되어 있습니다.
최적화 작업이 전반적인 추론 성능을 크게 향상시키는 것을 확인했습니다.
Qwen2.5-1M 모델들은 100만 token의 context를 사용하는 시나리오에서 prefill 속도가 3배에서 7배 빨라졌습니다.
평가 결과 Qwen2.5-1M 모델은 long-context 작업에서 크게 향상되었으며 short-context 시나리오에서 성능이 저하되지 않았습니다.
Qwen2.5-14B-Instruct-1M 모델은 long-context 작업에서 GPT-4o-mini를 크게 능가하고 8배 더 긴 컨텍스트를 지원합니다.
Introduction
LLM은 자연어 처리에서 놀라운 능력 가지고 있습니다.
그러나 제한된 context 길이는 한 번에 처리할 수 있는 텍스트 양을 제한하여 단순한 작업에만 능숙하고, 복잡한 현실 시나리오에서는 방대한 정보 처리나 생성 작업을 수행하는 데 한계를 겪고 있습니다.
이러한 문제를 해결하기 위해 LLM의 context window을 확장하는 것이 LLM의 중요한 트렌드가 되었습니다. GPT 시리즈, LLama 시리즈, Qwen 시리즈는 모두 4k 또는 8k 토큰의 컨텍스트 창에서 128k 토큰으로 급격히 확장되어 서비스하고 있습니다.
Gemini, GLM-9B-Chat-1M, Gradient AI의 Llama-3-1M 모델 등과 같은 LLM의 컨텍스트 길이를 1M 토큰 또는 그 이상으로 확장하려는 탐구도 이루어지고 있습니다.
해당 페이퍼에서는 Qwen2.5의 1M 컨텍스트 길이 버전인 Qwen2.5-1M 시리즈를 소개합니다.
오픈 소스 모델로는 Qwen2.5-7B-Instruct-1M과 Qwen2.5-14B-Instruct-1M 두 개의 instruct-tuning 모델을 출시합니다.
128K 버전과 비교하여 해당 모델들은 긴 컨텍스트 처리 능력이 크게 향상되었습니다.
또한, Mixture of Experts(MoE) 기반의 API인 Qwen2.5-Turbo도 제공합니다.
GPT-4o-mini와 비슷한 성능을 제공하면서 더 긴 컨텍스트와 더 낮은 가격으로 API를 제공합니다.
모델 외에도 긴 컨텍스트 처리를 최적화한 추론 프레임워크를 오픈 소스로 제공하여 개발자들이 Qwen2.5-1M 모델을 더 비용 효율적으로 배포할 수 있게 합니다.
Qwen2.5-1M의 주요 방법론 두 가지를 설명합니다:
Efficient Long-Context Training:
Qwen2.5-1M의 pre-traing은 long-range dependencies을 emphasizing하는 합성 데이터를 포함하고 비용을 절감하고 효율성을 높이기 위해 progressive length extension strategy을 사용합니다. Post-training은 long-instruction datasets의 부족을 해결하기 위해 agent-generated large-scale instruction data를 사용합니다. multi-stage Supervised Fine-Tuning 및 강화 학습(RL)을 통해 짧은 시퀀스와 긴 시퀀스에서의 성능 균형을 맞추고 인간의 선호에 맞게 최적화합니다.
Efficient Inference and Deployment:
추론 프레임워크는 세 가지 핵심 구성 요소로 구성되어 있습니다:
(1) 추가 훈련 없이 256k 컨텍스트 길이로 훈련된 모델을 1M 컨텍스트로 원활하게 확장할 수 있는 훈련 없는 길이 extrapolation 방법;
(2) 추론 비용을 줄이기 위한 sparse attention mechanism으로, GPU 메모리 효율성을 향상시키고 길이 extrapolation 방법과 통합되며 정확도를 높이기 위한 sparsity configurations 최적화;
(3) engine-level optimizations(kernel improvements, pipeline parallelism, enhanced scheduling). 추론 프레임워크는 1M 컨텍스트 시나리오에서 prefill 속도를 3배에서 7배 향상시킵니다.
Architecture

Qwen2.5-1M 시리즈는 Qwen2.5 모델을 기반으로 개발되었으며, 최대 100만 토큰의 context-length를 지원합니다.
Qwen2.5-1M 모델은 Qwen2.5와 동일한 Transformer 기반 아키텍처를 유지하여 추론 시 호환성을 보장합니다.
특히, 이 아키텍처는 효율적인 KV 캐시 활용을 위한 Grouped Query Attention(GQA), non-linear transformations인 SwiGLU activation function, 위치 정보를 인코딩하는 Rotary Positional Embeddings(RoPE), attention mechanism 내 QKV bias, 안정적인 학습을 보장하는 pre-normalization 방식의 RMSNorm을 포함하고 있습니다.
Pre-training
Long-context pre-training은 비용이 많이 들 수 있습니다.
학습 효율성을 높이고 비용을 절감하기 위해 Qwen2.5-1M 모델의 사전 학습 과정에서 데이터 효율성을 최적화하고 학습 전략을 개선하는 데 중점을 두었습니다.
Natural and Synthetic Data
사전 학습 단계에서 다양한 도메인을 포함한 방대한 자연어 장문 데이터를 수집하여 Qwen2.5-1M 모델이 다양한 언어 패턴과 문맥을 학습할 수 있도록 하였습니다.
자연어 코퍼스는 long-distance associations이 약하여 모델이 먼 거리의 토큰 간 관계를 효과적으로 학습하는 데 어려움을 겪습니다.
자연어 텍스트가 일반적으로 local coherence을 우선시하여 모델이 장거리 의존성(먼거리 텍스트를 알지 못하여도) 없이도 쉽게 다음 토큰을 예측할 수 있기 때문입니다.
장거리 의존성을 더 잘 이해하고 생성할 수 있도록 합성 데이터를 추가하였습니다.
합성 데이터 생성 과정에서는 모델의 순차적 관계 이해와 문맥 파악 능력을 강화하는 다양한 작업을 수행하였습니다.
-
Fill in the Middle(FIM): FIM 작업은 주어진 텍스트에서 누락된 부분을 예측하도록 요구합니다. 다양한 위치와 길이에 공백을 삽입하여 모델이 공백 주변의 먼 문맥 정보를 통합하도록 유도합니다.
-
Keyword-Based and Position-Based Retrieval: 특정 키워드를 기반으로 관련 단락을 검색하거나 지정된 위치의 앞뒤 단락을 기억하도록 합니다. 이는 텍스트의 서로 다른 부분에서 관련 정보를 식별하고 연결하는 능력을 향상시키며, 순서 관계 이해도 강화합니다.
-
Paragraph Reordering: 단락을 임의로 섞은 후 원래 순서로 복원하도록 합니다. 이 과정은 논리적 흐름과 구조적 응집력을 인식하는 능력을 키워서 체계적이고 일관된 텍스트 생성을 가능하게 합니다.
합성 데이터 작업을 사전 학습 과정에 통합함으로써 모델이 장거리 정보를 효과적으로 포착할 수 있도록 하였습니다.
이 접근 방식은 데이터 효율성을 향상시키는 동시에 학습 과정을 가속화하여, 높은 성능을 달성하기 위해 필요한 반복 횟수를 줄임으로써 전체적인 계산 비용도 절감합니다.
Training Strategy
긴 문맥을 활용한 학습은 상당한 GPU 메모리를 요구하므로 학습 비용과 시간이 크게 증가하는 문제가 있습니다.
학습 효율성을 개선하기 위해 Qwen2.5-1M progressive context length expansion strategy을 채택하였습니다.
다섯 개의 단계로 구성됩니다.
초기 두 단계는 기존 Qwen2.5 모델과 유사합니다.
Qwen2.5 Base 모델의 중간 버전을 활용하여 긴 문맥 학습을 진행합니다.
먼저 4096 토큰의 문맥 길이로 모델을 훈련한 후 32768 토큰으로 확장하여 학습을 이어갑니다.
이 과정에서 Adaptive Base Frequency(ABF) 기법을 사용하여 RoPE의 기본 frequency를 10,000에서 1,000,000으로 조정합니다.
이후 세 단계에서는 문맥 길이를 65,536 토큰, 131,072 토큰, 262,144 토큰으로 점진적으로 확장하며, RoPE의 기본 frequency를 각각 1,000,000, 5,000,000, 10,000,000으로 설정합니다.
이 단계에서는 학습 데이터의 75%를 현재 최대 문맥 길이의 시퀀스로 구성하고 나머지 25%는 더 짧은 시퀀스로 유지하여 모델이 긴 문맥에 적응하면서도 다양한 길이의 시퀀스를 처리하고 일반화 성능을 유지할 수 있게 합니다..
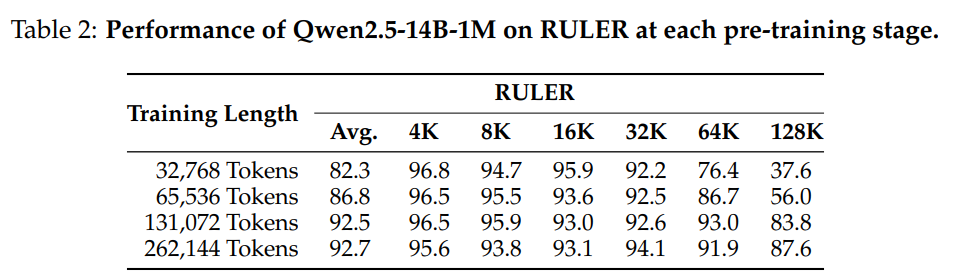
진행 중인 학습의 성능 변화를 모니터링하기 위해 매 학습 단계가 끝날 때 RULER 벤치마크를 활용하여 Qwen2.5-14B-1M 모델을 평가하였습니다. 표 2(Table 2)에 확인할 수 있듯이 점진적으로 긴 시퀀스를 학습하는 방식은 해당 시퀀스 길이에 대한 모델의 이해 능력을 꾸준히 향상시켰습니다.
최종 사전 학습 단계(262,144 토큰 시퀀스)에서도 128K 샘플에서 뛰어난 성능 향상이 확인되었습니다.
모델이 상대적으로 짧은 작업에서 최대한의 성능을 발휘하려면 더 긴 시퀀스로 학습하는 것이 필수적이라는 것을 알 수 있습니다.
Post-Training
Post-Training의 목표는 long-context 작업에서 모델의 성능을 효과적으로 향상시키면서도 short tasks에서의 성능 저하를 방지하는 것이다.
Synthesizing Long Instruction Data
long-context tasks에서는 human annotation은 비용이 많이 들고 신뢰성이 낮을 수 있다.
이를 해결하기 위해 학습 데이터에는 상당한 비율의 합성된 장문 질문-응답 쌍이 포함되어 있다.
사전 학습 코퍼스에서 긴 문서를 선택하고 Qwen2.5를 사용하여 각 문서에서 무작위로 추출한 부분을 기반으로 쿼리를 생성하도록 프롬프트를 제공하였다.
그 후, Qwen-Agent 프레임워크를 활용하여 전체 문서를 기반으로 고품질 응답을 생성한다.
이 프레임워크는 retrieval-augmented generation, chunk-by-chunk reading, step-by-step reasoning과 같은 기법을 적용하여 문서의 전체 내용을 종합적으로 반영한 응답을 생성할 수 있도록 합니다.
마지막으로, 전체 문서, 모델이 생성한 쿼리, 에이전트 기반 응답을 합성 훈련 데이터로 활용한다.
Two-stage Supervised Fine-tuning
모델이 long-context tasks에서의 성능을 향상시키면서도 단문 작업 성능을 유지할 수 있도록 2단계 훈련 방식을 적용하였습니다.
첫 번째 단계에서는 Qwen2.5 모델과 유사하게 최대 32,768 토큰을 포함하는 단문 지시 데이터만을 사용하여 학습하고 동일한 수의 학습 단계를 유지합니다.
이 단계에서는 단문 작업을 처리하는 능력을 유지하는 데 중점을 둡니다.
두 번째 단계에서는 최대 32,768토큰에서 262,144토큰까지 길이가 다양한 단문 및 장문 데이터가 혼합된 데이터셋을 도입합니.
이때, 모델이 첫 번째 단계에서 습득한 기술을 잊지 않도록 단문과 장문의 데이터 비율을 신중하게 조정하였다.
Reinforcement Learning
모델이 인간의 선호도에 더 잘 맞추기 위해, Direct Preference Optimization(DPO)과 유사한 오프라인 강화 학습(offline RL)을 적용하였다.
다른 Qwen2.5 모델의 오프라인 RL 단계에서 사용된 학습 쌍을 활용했으며 해당 데이터는 최대 8,192토큰의 짧은 샘플로만 구성되어 있었다.
실험 결과, 이러한 단문 샘플만을 사용한 훈련이 모델의 인간 선호도 정렬(alignment) 향상에 충분했으며 이를 long-context tasks으로도 효과적으로 일반화할 수 있음을 확인하였다.
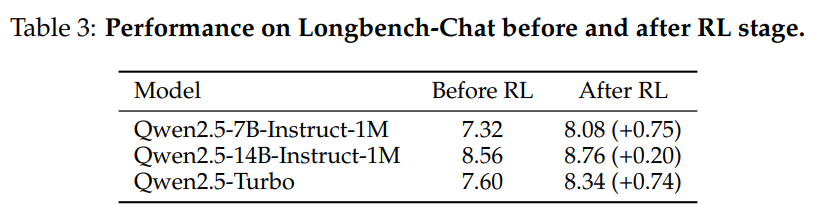
이를 입증하기 위해 RL 적용 전후의 모델을 longbench-chat 벤치마크에서 평가하였습니다.
Table 3에 제시된 결과와 같이 RL 단계가 모든 모델에서 상당한 성능 향상을 가져왔음을 확인할 수 있었습니다.
이는 짧은 맥락에서의 RL이 장문 맥락 작업으로도 효과적으로 일반화될 수 있음을 보여줍니다.
