Inference and Deployment
추론 및 배포 과정에서 LLM이 long-context를 처리할 때는 많은 장애물들이 있습니다.
큰 장애물은 제한된 GPU 메모리 내에서 더 긴 시퀀스를 지원하는 모델을 배포하는 것, 연산량을 줄여 처리 속도를 높이는 것, 최적화한 이후에도 정확도를 유지하는 것입니다.
모델이 추론 시 훈련 길이의 4배 이상 긴 문맥을 지원할 수 있도록 하는 length extrapolation 방법을 제시합니다.
prefill 단계에서 4배 이상의 가속할 수 있는 sparse attention을 소개합니다.
마지막으로, 커널 및 시스템 수준에서의 최적화를 심층적으로 다루어 전반적은 추론 성능을 올리게 됩니다
Length Extrapolation
length extrapolation은 훈련 중 사용된 컨텍스트 길이보다 더 긴 입력을 처리할 때 모델 성능을 향상시키기 위한 추론 기법입니다.
본 논문에서는 두 가지 기법에서 length extrapolation을 달성합니다
Dual Chunk Attention(DCA)
RoPE 기반으로 구성된 현재 LLMs는 훈련 중 경험하지 못한 큰 상대적 위치 차이로 인해 훈련된 길이를 초과하는 시퀀스를 처리할 때 성능 저하를 겪는다.
DCA 방법은 전체 시퀀스를 여러 개의 청크로 나누고 상대적 위치를 더 작은 값으로 재매핑함으로써 이 문제를 해결하는 방식입니다.
이 방식을 사용하면 어떤 두 토큰 간의 거리도 사전에 훈련된 길이를 초과하지 않도록 보장할 수 있습니다.
DCA는 다양한 거리에서 토큰 간 상호작용을 효율적으로 관리하기 위해 세 가지 서로 다른 attention pattern을 활용한다.
-
Intra-Chunk Attention: 동일한 청크 내 토큰 간 어텐션을 처리하는 방법입니다. 두 토큰 간의 거리가 상대적으로 짧기 때문에 원래의 상대적 위치를 유지한다.
-
Inter-Chunk Attention: 서로 다른 청크에 속한 토큰 간 어텐션을 관리하는 방법. 최대 거리가 사전 훈련된 길이를 초과하지 않도록 반복되는 시퀀스를 이용해 상대적 위치를 재설정합니다.
-
Successive-Chunk Attention: 인접한 청크 간의 어텐션을 관리하여 짧은 범위의 상대적 위치 연속성을 보장하는 방법. 쿼리와 키 간의 거리가 로컬 윈도우 크기 내에 있으면 원래의 상대적 위치를 유지하며, 그렇지 않은 경우 Inter-Chunk Attention에서 사용된 방식을 적용하여 더 긴 거리를 처리한다.
패턴을 통합하여 DCA는 모델이 기존 훈련 길이보다 최대 4배 이상 긴 컨텍스트를 처리할 수 있습니다.
DCA는 flash attention과 통합되어 실제 배포 환경에서도 효율적으로 구현 가능합니다.
YaRN의 Attention Scaling in YaRN
매우 긴 시퀀스를 처리할 때 LLM의 어텐션 메커니즘이 분산되어 핵심 정보를 놓치는 문제가 발생하는 경우가 있습니다.
attention logits에 temperature parameter t를 도입함으로써 모델 성능을 단순하면서도 효과적으로 향상시킬 수 있음을 입증했습니다.
attention weights 계산은 다음과 같이 수정됩니다.
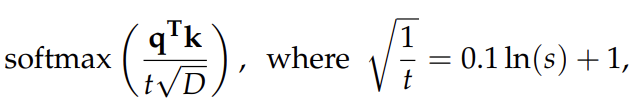
-
q와 k는 각각 쿼리와 키 벡터를 나타냅니다.
-
scaling factor (s)는 추론 시퀀스 길이와 훈련 시퀀스 길이의 비율입니다.
-
D는 각 어텐션 헤드의 차원을 의미합니다.
-
t는 다음과 같이 정의됩니다: .
모델 실험에서는 YaRN의 어텐션 스케일링을 항상 DCA와 함께 사용합니다.
이 두 가지 길이 외삽 방법은 짧은 시퀀스를 처리할 때 모델의 동작을 변경하지 않아 짧은 컨텍스트 성능에 영향을 주지 않습니다.
Effects of Length Extrapolation
Effects of Length Extrapolation의 효과를 입증하기 위해 Qwen2.5-1M 모델과 128k 버전을 100만 토큰의 컨텍스트 길이에서 RULER 평가를 진행했다.
- Passkey Retrieval
- NIAH(Needle in a Haystack) with multiple queries
- NIAH(Needle in a Haystack) with multiple values
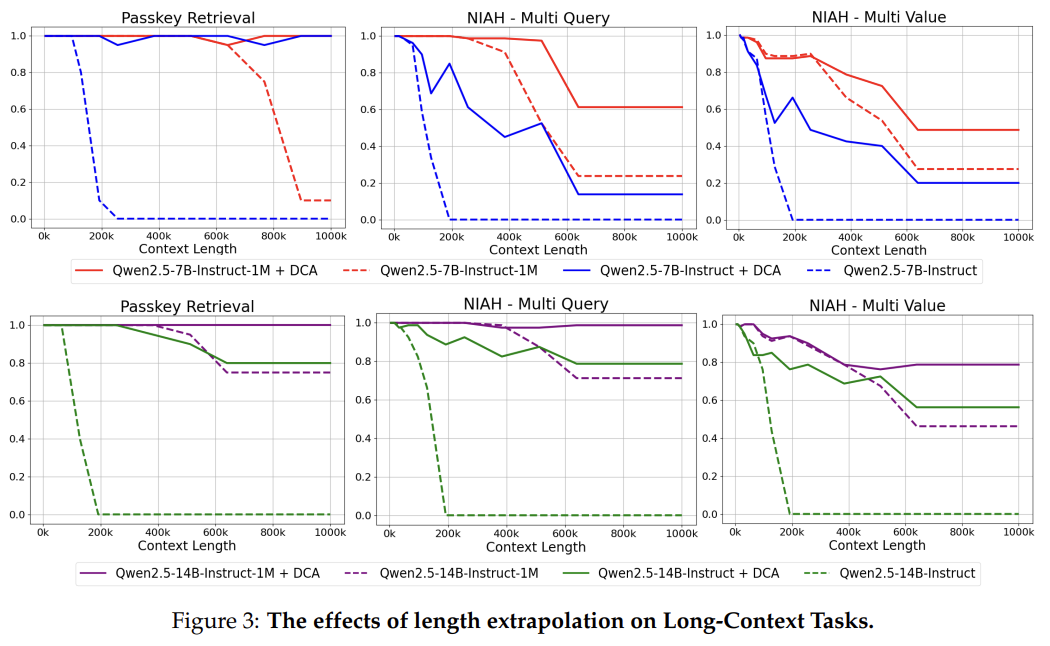
실험 결과, DCA는 컨텍스트 길이가 훈련 길이를 훨씬 초과하는 경우에도 모든 인스트럭션 모델의 성능을 크게 향상시키는 걸 확인할 수 있습니다.
Qwen2.5-7B-Instruct, Qwen2.5-14B-Instruct 모델이 32K 토큰 길이로 훈련되었음에도 불구하고, 100만 토큰 길이의 시퀀스에서 상대적으로 단순한 Passkey Retrieval 성능을 80% 이상의 정확도를 달성했다.
Qwen2.5-1M 모델과 128k 버전을 비교한 결과 더 긴 시퀀스(최대 256K)에서 훈련하는 것이 더 긴 컨텍스트에 대한 성능을 향상시킨다는 점을 확인할 수 있습니다.
Efficient Inference with Sparse Attention
long-context을 처리하는 LLM에서는 추론 속도가 매우 중요합니다.
기존의 어텐션 메커니즘은 입력 시퀀스 길이에 따라 계산 복잡도가 기하급수적으로 증가합니다.
입력 길이가 100만 토큰에 도달하면 어텐션 메커니즘에 소요되는 시간이 전체 순전파 시간의 90% 이상을 차지할 수도 있습니다.
따라서 long-context 모델을 성공적으로 배포하려면 sparse attention 메커니즘을 도입하는 것이 필수적입니다.
MInference

prefill 단계를 가속화하기 위해 MInference를 기반으로 한 sparse attention 메커니즘을 구현합니다.
chunked prefill과 통합하여 메모리 사용량을 최적화, length extrapolation 기법을 결합, 긴 시퀀스에서 발생할 수 있는 정확도 저하를 해결하기 위한 sparse refinement 방법을 도입했습니다.
Jiang et al.(2024b)는 어텐션 계산에 중요한 토큰만 식별하고 활용하는 기법을 개발하여 전체 어텐션 메커니즘을 사용할 때와 거의 동일한 성능을 달성했습니다.
이러한 중요한 토큰은 모든 샘플에서 명확한 패턴을 보이며 어텐션 맵에서 수직선 및 대각선 형태로 나타납니다.
이러한 패턴을 "Vertical-Slash" 패턴이라고 하며, 그림 4(a)에 설명되어 있습니다.
MInference는 먼저 최적의 sparsification configuration을 결정하는 오프라인 검색을 수행합니다.
이 구성은 각 어텐션 헤드가 몇 개의 수직 및 대각선 라인을 유지해야 하는지를 지정합니다.
추론 중에는 last query tokens과 모든 키 토큰 간의 어텐션을 계산한 후, 사전 결정된 구성에 따라 "Vertical-Slash" 패턴을 따르는 중요한 토큰을 동적으로 선택하여 최종으로 선택된 중요한 토큰에 대해서만 어텐션을 수행합니다.
이 방식은 계산 및 메모리 접근 비용을 약 10배 줄이면서도 정확도 손실을 최소화할 수 있습니다.
Integrating with Chunked prefill
MInference에서는 전체 시퀀스를 한 번에 인코딩하므로 activation values의 VRAM 사용량이 입력 길이에 선형적으로 증가합니다.
예를 들어, 입력 길이가 100만 토큰에 도달하면 Qwen2.5-7B 모델의 단일 MLP 계층에서 활성화 값이 차지하는 VRAM이 71GB까지 증가할 수 있어 이는 모델 가중치 및 KV cache의 메모리 사용량을 훨씬 초과합니다.
이 문제는 추론 중 chunked prefill을 사용하여 VRAM 소비를 줄일 수 있습니다.
청크 길이를 32,768 토큰으로 설정하면 활성화 VRAM 사용량을 96.7%까지 감소시킬 수 있습니다.
또한, 여러 요청을 처리할 때 긴 prefill 연산으로 인해 디코딩이 병목 현상을 겪는 것을 방지하는 데도 도움이 됩니다.
MInference에 chunked prefill을 통합하기 위해 각 청크에서 중요한 토큰을 선택하는 전략도 제안합니다(그림 4(b) 참조).
입력 시퀀스를 여러 청크로 나눈 후 모델이 이를 순차적으로 처리합니다.
어텐션 레이어에서는 전체 입력 시퀀스의 마지막 토큰을 고려하는 대신 각 청크 내에서 마지막 64개의 토큰을 활용하여 중요한 토큰을 식별합니다.
각 청크에서 수직선 및 대각선 형태의 중요한 토큰을 선택하는 패턴을 유지하면서도 큰 정확도 손실 없이 효과적으로 동작합니다.
Chunked prefill을 MInference와 결합함으로써 제한된 VRAM 내에서 지원 가능한 최대 시퀀스 길이를 크게 증가시킬 수 있습니다.
Integrating with DCA
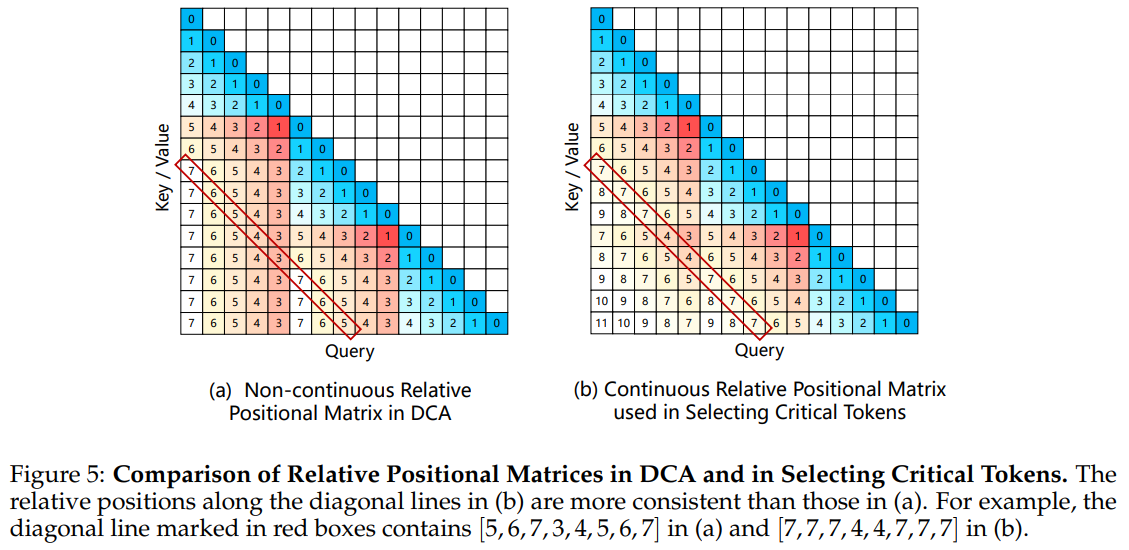
MInference는 DCA(Dynamic Context Attention)와 쉽게 통합할 수 있지만 length extrapolation이 필요한 특정 상황에서 성능 저하가 발생하는 것을 발견했습니다.
DCA에서 relative positions의 불연속성이 "slash" 패턴을 방해하여 중요한 토큰 선택의 정확도를 떨어뜨릴 수 있다고 생각했습니다.
이를 해결하기 위해 연속적인 상대적 위치를 복원하는 방법을 제안합니다.
이 과정에서는 대각선 라인을 따라 상대적 위치의 일관성을 최대한 유지하면서 후속 청크 및 청크 간 어텐션에서 중요한 토큰을 선택합니다(그림 5 참조).
이러한 연속적 상대적 위치는 중요한 토큰을 선택하는 단계에서만 적용되며 최종 어텐션 가중치 계산에서는 여전히 DCA의 불연속 위치 임베딩을 사용합니다.
Sparsity refinement on 1M sequences
MInference는 배포 전에 각 어텐션 헤드에 대한 최적의 sparsification configuration을 결정하기 위해 오프라인 검색을 수행합니다.
전체 어텐션 행렬의 계산량이 이차적으로 증가하기 때문에 일반적인 검색은 32k 토큰 이하의 짧은 시퀀스에서 수행되어 100만 토큰과 같은 긴 시퀀스에서의 성능이 최적이 아닐 가능성이 있습니다.
이 제한을 해결하기 위해, 우리는 최대 100만 토큰 길이의 시퀀스에 대한 sparsification configuration을 refinement하는 방법을 개발했습니다.
이를 위해, Flash Attention의 효율적인 구현을 활용하여 softmax log-sum-exp(softmax lse)를 계산합니다.

Impact of Sparse Attention on Accuracy
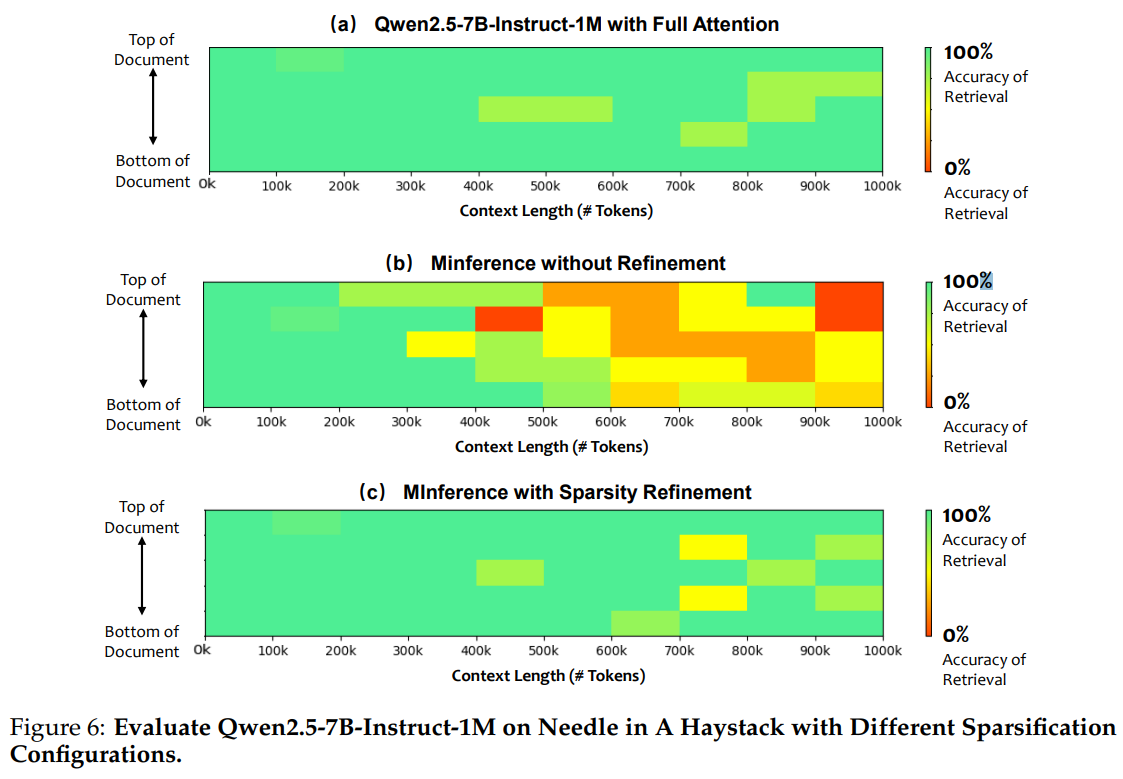
DCA 및 Sparsity refinement 방법을 통합하는 것이 얼마나 중요한지 입증하기 위해 Qwen2.5-7B-Instruct-1M 모델을 "Needle in a Haystack"을 통해 평가했습니다.
작은 모델일수록 Sparse Attention으로 인한 정보 손실이 크기 때문에 개선된 방법의 효과가 더욱 두드러집니다.
그림 6에서 볼 수 있듯이, Qwen2.5-7B-Instruct-1M 모델이 전체 어텐션을 사용할 경우 100만 토큰 컨텍스트에서도 높은 검색 정확도를 유지했습니다.
그러나 기존 MInference 방법을 사용할 경우, 컨텍스트 길이가 40만 토큰을 초과하면 검색 정확도가 60% 이하로 떨어졌습니다.
연속적 상대적 위치를 활용한 중요한 토큰 선택과 sparsification configuration refinement를 추가한 후에는 대부분의 성능이 회복되었고 prefill 단계에서도 약 4배의 속도 향상을 유지할 수 있었습니다.
Inference Engine
알고리즘 발전과 더불어 추론 엔진을 최적화하는 것도 LLM이 긴 시퀀스를 효과적으로 처리할 수 있도록 하는 데 필수입니다.
Qwen2.5-1M 모델의 API 서비스는 Alibaba PAI Engine 팀이 개발한 고성능 추론 엔진인 BladeLLM을 기반으로 합니다.
BladeLLM은 커널 성능, 파이프라인 병렬 처리, 스케줄링 알고리즘의 향상을 통해 긴 시퀀스의 프리필 및 디코딩을 최적화하도록 설계되었습니다.
오픈 소스 커뮤니티가 확장된 컨텍스트 길이를 가진 Qwen 모델을 효율적으로 배포할 수 있도록 이러한 최적화 중 일부가 오픈 소스로 제공되었으며, vLLM에 통합될 예정입니다.
